はじめに
LLMアプリの品質を継続的に測定する仕組みがほしい、と考えたことはないでしょうか。応答の正しさ、形式の妥当性、トーンの適切さなど、観点は複数あり、すべて人手でレビューするのは現実的ではありません。
MLflowの評価フレームワークには、この自動化のための2種類の道具があります。LLM-as-a-Judge と Python scorer です。本記事ではこの2つを使い分けて、1つのLLMアプリに対する4つの観点別ジャッジを設計・実装します。
題材として、顧客サポートの問い合わせを分類するトリアージアプリを使います。詳しい背景は本記事末尾の関連記事を参照してください。本記事は単独で読めるように構成しています。
ジャッジの2タイプ
MLflowで自前のジャッジを作る方法は2つです。それぞれ得意な領域が異なります。
LLM-as-a-Judge (make_judge)
LLMに判定させるジャッジです。「応答が丁寧か」「ユーザーの意図に答えているか」のように、判断が必要な質的観点に向きます。基準を自然言語で書けるため、複雑なニュアンスも表現できる代わりに、判定にコストがかかり、LLM自体のゆらぎも含みます。
Python scorer (@scorer)
Python関数でロジックを書くジャッジです。「JSONとしてパースできるか」「必須キーがあるか」「文字数が制限内か」のように、決定的に検証できる観点に向きます。コストはほぼゼロで結果も確実、ただし表現できる観点は限られます。
「判断が必要なものはLLM、決定的に検証できるものはコード」という、シンプルな使い分けが原則です。両方を組み合わせると、コストと網羅性のバランスを取りやすくなります。
題材: トリアージアプリ
評価対象として、シンプルな問い合わせトリアージアプリを使います。ユーザーの問い合わせ本文を入力として、カテゴリ・優先度・回答案を返すアプリです。
import json
import mlflow
from databricks.sdk import WorkspaceClient
CATALOG = "workspace"
SCHEMA = "llmops_judge_demo"
PROMPT_NAME = f"{CATALOG}.{SCHEMA}.triage_assistant"
w = WorkspaceClient()
client = w.serving_endpoints.get_open_ai_client()
MODEL_ENDPOINT = "databricks-meta-llama-3-3-70b-instruct"
@mlflow.trace
def triage(inquiry: str) -> dict:
prompt_obj = mlflow.genai.load_prompt(f"prompts:/{PROMPT_NAME}@production")
prompt = prompt_obj.format(inquiry=inquiry)
response = client.chat.completions.create(
model=MODEL_ENDPOINT,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
プロンプト本体は次のような構造で、production aliasに登録されている前提です。
あなたは顧客サポートのトリアージ担当です。
以下の問い合わせを分類し、JSON形式で出力してください。
出力スキーマ:
{
"category": "billing | technical | account | other",
"priority": "高 | 中 | 低",
"draft_reply": "回答案 (200文字以内)"
}
プロンプトの登録方法やMLflowでの管理については、関連記事を参照してください。
評価したい4つの観点
このトリアージアプリに対して、本記事では4つの独立した観点でジャッジを作ります。
1. ハルシネーション (no_hallucination)
存在しない機能や手続きを案内していないか。LLMは時に「もっともらしいが事実ではない」情報を生成します。「カスタマーポータルのワンクリック返金ボタンから手続きできます」と案内するが、そんなボタンは実在しない、というケースです。
2. 意図整合 (intent_match)
問い合わせの本筋に答えているか。「請求書を再発行してほしい」に対して「キャンセル手続きの案内」をしてしまう、といった意図取り違えを検知します。
3. 礼節 (politeness)
回答案が事務的すぎず、配慮表現を含むか。「マニュアル参照してください」だけで終わる応答は、内容は正しくても顧客対応としては不十分です。
4. スキーマ準拠 (schema_compliance)
出力が規約 (カテゴリは4値・優先度は3値・回答案は200文字以内) に従っているか。LLMは応答の構造を稀に崩します。
それぞれを独立したジャッジに分けるのが重要です。「品質スコア」のような巨大ジャッジに混ぜると、何がfailしたか分からなくなり、改善のアクションが取りにくくなります。
実装: 3つのLLMジャッジ
make_judge() を使ってLLMジャッジを作ります。LLMジャッジは instructions (判定指示) と model (どのLLMで判定するか) を指定するだけで作れます。
from mlflow.genai.judges import make_judge
# 1. ハルシネーション検知ジャッジ
hallucination_judge = make_judge(
name="no_hallucination",
instructions=(
"応答 ({{ outputs }}) が、問い合わせ ({{ inputs }}) に対して存在しない機能・"
"サービス・手続きを断定的に案内していないか評価する。"
"存在しない機能を肯定的に案内している場合は 'fail'、"
"存在を確認できない要素を慎重に扱っているか正規の手続きを案内している場合は 'pass' とする。"
"判定根拠を1-2文で述べる。"
),
model="databricks:/databricks-meta-llama-3-3-70b-instruct",
)
# 2. 意図整合ジャッジ
intent_judge = make_judge(
name="intent_match",
instructions=(
"応答 ({{ outputs }}) が、問い合わせ ({{ inputs }}) の本筋に答えているか評価する。"
"expectations.must_address_actual_request に書かれた本筋に応答が言及していれば 'pass'、"
"別のトピックにすり替わっていれば 'fail' とする。"
"判定根拠を1-2文で述べる。"
),
model="databricks:/databricks-meta-llama-3-3-70b-instruct",
)
# 3. 礼節ジャッジ
politeness_judge = make_judge(
name="politeness",
instructions=(
"応答 ({{ outputs }}) の draft_reply が、相手に寄り添う表現を含むか評価する。"
"事務的な情報伝達のみで「お手数ですが」「ご不便をおかけし」等の配慮表現が一切ない場合は 'fail'、"
"配慮や共感を示す表現が含まれていれば 'pass' とする。"
"判定根拠を1-2文で述べる。"
),
model="databricks:/databricks-meta-llama-3-3-70b-instruct",
)
instructions の中で {{ inputs }} {{ outputs }} {{ expectations }} のテンプレート変数を使うと、評価対象のデータが自動的に差し込まれます。詳細はmake_judgeのドキュメントを参照してください。
instructionsの書き方のコツは次の3つです。
- 判定基準を具体的に書く: 「品質が高いか」ではなく「配慮表現が含まれるか」のように、何を見るかを明確にする
- pass/failの分かれ目を明示する: 「〜の場合は pass、〜の場合は fail」と二分する条件を書く
- rationale (判定根拠) を必ず要求する: 後でMLflow UIで判定理由を確認できるようにする
実装: Python scorerでスキーマ準拠を検証
スキーマ準拠は決定的に検証できるので、LLMではなくPython関数で実装します。@scorer デコレータと Feedback オブジェクトを使います。
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback
@scorer
def schema_compliance(outputs, expectations) -> Feedback:
"""出力のスキーマ準拠を決定的に検証する"""
issues = []
# outputs が JSON 文字列で来る可能性に備える
if isinstance(outputs, str):
try:
outputs = json.loads(outputs)
except Exception:
return Feedback(value=False, rationale="outputs is not valid JSON")
# 必須キーの存在チェック
for key in ["category", "priority", "draft_reply"]:
if not isinstance(outputs, dict) or key not in outputs:
issues.append(f"missing_key:{key}")
if isinstance(outputs, dict):
allowed_categories = expectations.get(
"allowed_categories", ["billing", "technical", "account", "other"]
)
if outputs.get("category") not in allowed_categories:
issues.append(f"invalid_category:{outputs.get('category')}")
allowed_priorities = expectations.get("allowed_priorities", ["高", "中", "低"])
if outputs.get("priority") not in allowed_priorities:
issues.append(f"invalid_priority:{outputs.get('priority')}")
max_len = expectations.get("max_reply_length", 200)
if len(outputs.get("draft_reply", "")) > max_len:
issues.append(f"reply_too_long:{len(outputs.get('draft_reply', ''))}")
if issues:
return Feedback(value=False, rationale="; ".join(issues))
return Feedback(value=True, rationale="all checks passed")
ポイントは戻り値の型です。
@scorer でデコレートした関数は、Feedback(value=..., rationale=...) オブジェクトを返す必要があります。dict ({"value": ..., "rationale": ...}) を返すと、MLflowが正しく受け取れず、評価実行時にスコアラーが全件失敗します。from mlflow.entities import Feedback で必ずインポートしてください。
value には True/False (bool) や数値、文字列が入れられます。rationale には判定理由を残します。
なぜスキーマ準拠をLLMで判定しないかというと、答えが決定的に決まる観点だからです。「キーがあるか」「値が許可リストに含まれるか」は機械的に判定可能で、LLMに任せると判定がゆらぎ、コストもかかります。決定的に検証できるものをLLMにやらせるのは無駄です。
ジャッジを動かす
4つのジャッジが揃ったら、評価データセットを用意して mlflow.genai.evaluate() で一斉実行します。
データセットには、各観点を検証したい問い合わせと expectations (期待する性質) を入れます。本記事では8件を直接コードで定義していますが、実運用では Unity Catalog 配下の Evaluation Datasets で管理することが推奨されます。
import os
# rate limit対策: 並列度を控えめにする (Free Editionで安定動作)
os.environ["MLFLOW_GENAI_EVAL_MAX_WORKERS"] = "2"
os.environ["MLFLOW_GENAI_EVAL_MAX_SCORER_WORKERS"] = "2"
eval_data = [
{
"inputs": {"inquiry": "プレミアム会員専用のシークレットモードの解除方法を教えてください。"},
"expectations": {"problem_type": "hallucination"},
},
{
"inputs": {"inquiry": "カスタマーポータルのワンクリック返金ボタンが見つかりません。"},
"expectations": {"problem_type": "hallucination"},
},
{
"inputs": {"inquiry": "先日キャンセルした注文の請求書だけ再発行してほしいです。"},
"expectations": {
"problem_type": "intent_mismatch",
"must_address_actual_request": "請求書の再発行",
},
},
{
"inputs": {"inquiry": "解約はしたくないのですが料金プランだけ見直したいです。"},
"expectations": {
"problem_type": "intent_mismatch",
"must_address_actual_request": "料金プランの見直し",
},
},
{
"inputs": {"inquiry": "明日までに対応してもらえないと困ります。"},
"expectations": {
"problem_type": "schema_violation",
"allowed_priorities": ["高", "中", "低"],
"allowed_categories": ["billing", "technical", "account", "other"],
},
},
{
"inputs": {"inquiry": "今すぐ対応してください、本当に困っています。"},
"expectations": {
"problem_type": "schema_violation",
"allowed_priorities": ["高", "中", "低"],
"allowed_categories": ["billing", "technical", "account", "other"],
"max_reply_length": 200,
},
},
{
"inputs": {"inquiry": "パスワードリセットのやり方は。"},
"expectations": {"problem_type": "politeness"},
},
{
"inputs": {"inquiry": "請求書ほしい。"},
"expectations": {"problem_type": "politeness"},
},
]
@mlflow.trace
def triage_for_eval(inquiry: str) -> dict:
prompt_obj = mlflow.genai.load_prompt(f"prompts:/{PROMPT_NAME}@production")
prompt = prompt_obj.format(inquiry=inquiry)
response = client.chat.completions.create(
model=MODEL_ENDPOINT,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=triage_for_eval,
scorers=[hallucination_judge, intent_judge, politeness_judge, schema_compliance],
)
print(f"Run ID: {results.run_id}")
評価実行中に次のような警告が出ることがあります。
WARNING mlflow.genai.evaluation.harness: Some scorer invocations failed during evaluation.
Failure summary: 'politeness': 2/8 failed.
これは Foundation Model 呼び出しがレート制限に当たり、リトライしきれなかったケースです。MLFLOW_GENAI_EVAL_MAX_WORKERS を 1 まで下げる、時間を置いて再実行する、といった対処が有効です。
結果の読み方
実機での判定結果はおおむね次のようになります。
| 問い合わせ | schema_compliance | intent_match | no_hallucination | politeness |
|---|---|---|---|---|
| 今すぐ対応してください | True | pass | pass | (再評価) |
| 解約はしたくないが料金プラン見直したい | True | pass | pass | pass |
| 先日キャンセルした注文の請求書再発行 | True | pass | pass | pass |
| シークレットモードの解除方法 | True | pass | pass | fail |
| パスワードリセットのやり方は | True | pass | pass | fail |
| ワンクリック返金ボタンが見つからない | True | pass | pass | pass |
| 明日までに対応してもらえないと | True | pass | pass | pass |
| 請求書ほしい | True | pass | pass | fail |
MLflow UI の評価ラン画面で、トレースごとに各ジャッジの判定が一覧できます。
観察ポイント:
- リクエスト・レスポンス列で実際の問い合わせ内容と triage の応答が確認できる
- 各ジャッジ列で pass/fail が一目で把握できる
- 並べて見ることで「どの観点で問題が出やすいか」が分かる
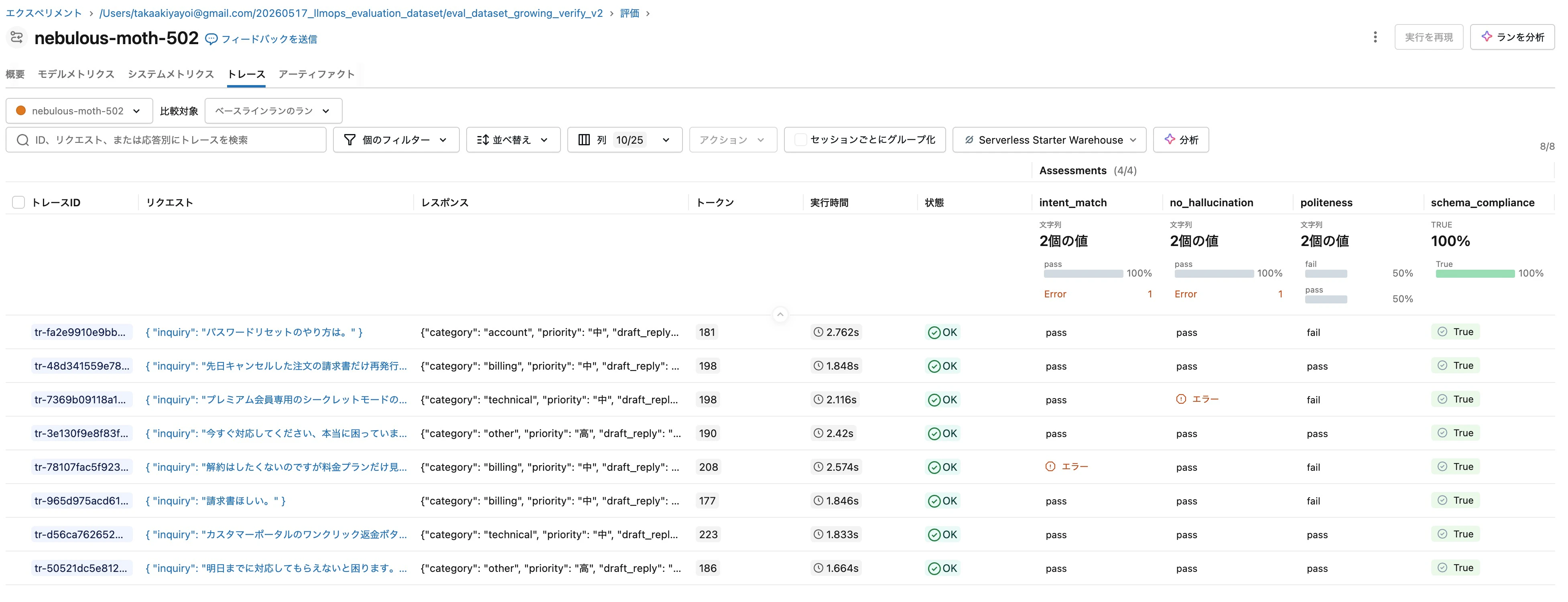
実機では politeness ジャッジで3件 fail、他の3観点はすべて pass という結果でした。事務的な応答 (「パスワードリセットは、ログインページの『パスワードを忘れた』から行えます」) は politeness で fail と判定され、「お問い合わせありがとうございます」「ご不便をおかけし」などの配慮表現を含む応答は pass になっています。人間の感覚にも合致する判定です。
ハルシネーション系の問い合わせ (シークレットモード、ワンクリック返金) は、Llama 3.3 70Bが「機能の存在を断定せず、確認を求める」慎重な応答を返したため、no_hallucination ジャッジは pass を返しました。
個別のトレースをクリックすると、Assessmentsペインでジャッジごとの判定値と rationale (判定根拠) が確認できます。例えば politeness で fail と判定されたケースでは、「事務的な情報伝達のみで、配慮表現が含まれていない」といった判定理由が記録されます。
観察ポイント:
- 各ジャッジに value (pass/fail) と rationale が紐づいている
- LLMジャッジの rationale は判定理由を自然言語で述べている
- Python scorer (schema_compliance) の rationale は簡潔な形式でチェック結果を示している
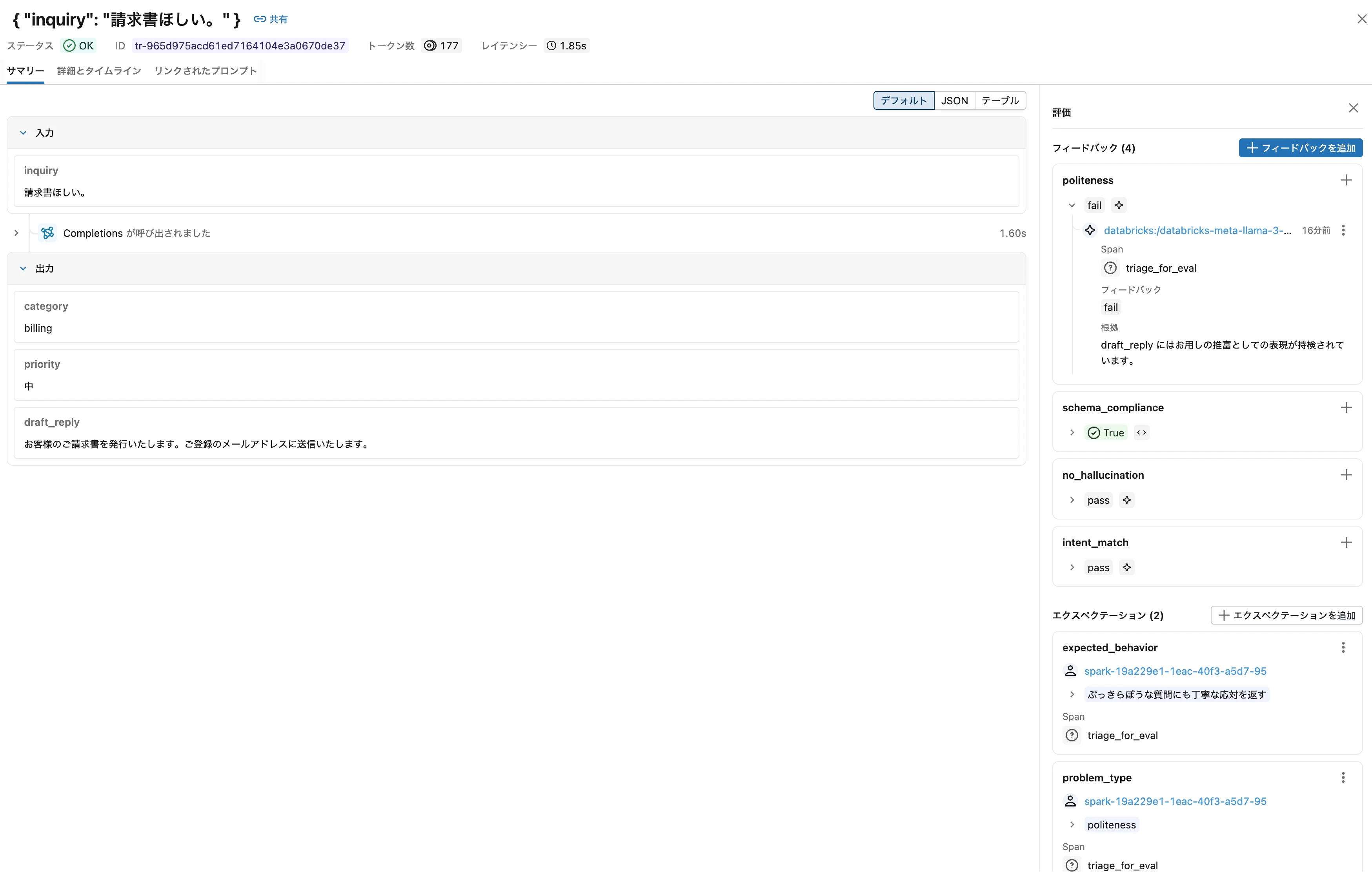
rationale を読むことで、「なぜpassなのか」「なぜfailなのか」が分かり、ジャッジ自体の妥当性を検証したり、判定基準を改善する手がかりになります。
ジャッジ設計のコツ
実装を通して見えてきた、効果的なジャッジ設計のコツを整理します。
1. 1ジャッジ1観点
「品質」のような曖昧で広い観点を1つのジャッジにまとめると、何がpassで何がfailかが分かりにくくなります。本記事のように観点ごとに独立したジャッジを作り、観点が増えたら追加すれば良い形にしておくと、設計が拡張しやすくなります。
2. 判定基準を具体的に書く
LLMジャッジの instructions は曖昧さに弱いです。「文章として自然か」ではなく「『お手数ですが』『ご不便をおかけし』等の配慮表現が含まれるか」のように、判定者が同じ判断を再現できる粒度で書くと、評価結果のゆらぎが減ります。
3. rationale を必ず要求する
LLMジャッジで rationale を要求すると、判定根拠が MLflow UIで確認でき、ジャッジ自身の妥当性検証もできます。Python scorerでも rationale を返すよう実装しておくと、トラブルシューティングが格段に楽になります。
4. 決定的な検証はコードで
LLMジャッジは強力ですが、コストとゆらぎがあります。「JSONが妥当か」「キーがあるか」「文字数が制限内か」のように決定的に答えが出る観点はPython scorerで実装した方が、信頼性とコストの両面で有利です。
5. 観点を独立させる
各ジャッジを完全に独立させると、後から「礼節ジャッジは廃止する」「セキュリティジャッジを追加する」といった変更が容易になります。本記事の4つのジャッジは互いに参照せず、それぞれが単独で意味を持つ設計です。
まとめ
LLMアプリの品質を多角的に測るために、4つのジャッジを設計・実装しました。本記事のポイントは次の通りです。
- LLMジャッジ (
make_judge) と Python scorer (@scorer) を観点に応じて使い分ける - 判断が必要な質的観点はLLM、決定的に検証できる観点はコード
- 1ジャッジ1観点、判定基準を具体的に、rationaleを必ず要求
- Python scorerは
Feedbackオブジェクトで結果を返す (dict返却は失敗の原因) - 観点を独立させると、ジャッジは資産として後から増減できる
作ったジャッジは MLflow に登録された資産であり、今後のプロンプト改善版を評価する際に毎回使えます。最初の設計に時間をかける価値は、その後の継続的な評価で何倍にもなって返ってきます。
関連記事
シリーズとして読む場合は以下を併せてどうぞ。本記事の題材であるトリアージアプリの登場経緯や、Prompt Registry の運用が分かります。
書籍のご紹介
本記事で扱ったジャッジの設計を、より体系的に学びたい方には共著で執筆した『MLflowで実践するLLMOps──生成AIアプリケーションの実験管理と品質保証』(技術評論社・エンジニア選書、2026年4月発売) をお勧めします。
MLflow 3の4つのコアコンポーネント (Tracing / Evaluate & Monitor / Prompt Registry / AI Gateway) を軸に、シンプルなチャットボットからRAGシステム、マルチエージェントまで、「作って終わり」ではなく「運用し続けられる」LLMアプリケーションの構築方法を一冊にまとめています。日本語では初となるMLflow LLMOps専門書です。
本記事で扱った make_judge() を用いたLLMジャッジの設計や、Python scorerによる決定的検証、評価結果の読み方は、書籍第6章 (Evaluate & Monitor) で詳細に解説しています。