はじめに
Google ColabやJupyter Notebookを使ったことがある方がDatabricksを学ぶための推奨ステップをまとめました。
Databricksのノートブックは、Jupyterと似た操作感を持ちながら、分散処理やデータガバナンスなどエンタープライズ向けの機能が充実しています。既存のスキルを活かしながら、効率的にDatabricksを習得していきましょう。
あなたの悩みとDatabricksの解決策
| よくある悩み | Databricksの機能 | 活用方法 |
|---|---|---|
| データが大きすぎてメモリに入らない | Apache Spark / PySpark | 分散処理で大規模データを並列処理 |
| チームでコードを共有しにくい | リアルタイム共同編集 | 同じノートブックを複数人で同時編集 |
| 本番環境へのデプロイが面倒 | Jobs / Workflows | ノートブックをそのままスケジュール実行 |
| データのバージョン管理が困難 | Delta Lake | テーブルの履歴管理・タイムトラベル |
| MLモデルの実験管理が煩雑 | MLflow | 実験トラッキング・モデルレジストリ |
| データアクセス権限の管理 | Unity Catalog | 細かい粒度でのアクセス制御 |
Jupyter/Colabとの違い
Databricksのノートブックは、使い方においてはJupyter Notebookと大きな違いはありません。ただし、以下の点が異なります。
- 計算資源: Google Colabでは使用を許可されているスペックのみですが、Databricksの場合はクラウドアカウントのクォータの範囲内で自由に計算資源を構成・利用可能
- 分散処理: Sparkによる分散処理が標準で利用可能
- ガバナンス: Unity Catalogによるデータガバナンスが統合されている
- 共同編集: リアルタイムでの共同編集機能が標準搭載
Step 1: 環境セットアップ(1日目)
Databricks Free Editionでアカウント作成
Databricksでは学習目的で無料で利用できるFree Editionが提供されています。クレジットカードの登録も不要で、すぐに始められます。
サインアップ手順:
-
Databricks Free Edition サインアップページ にアクセス

- 希望のサインアップ方法を選択
- 新しいワークスペースが自動的に作成される

Free Editionはサーバーレス環境なので、クラスター設定不要ですぐに開始できます。ノートブック、パイプライン、SQLアナリティクス、AIアシスタンスを含む機能が利用可能です。
注意: Free Editionには利用クォータがあり、超過するとその日の残りはコンピュートが利用できなくなります。ただし、データと設定は削除されません。
参考: Databricks入門:データとAIを統合する次世代プラットフォーム - Qiita
Step 2: ノートブックの基本操作(2-3日目)
サイドメニューの + 新規 > ノートブックを選択することでノートブックを作成できます。


Jupyterとの対応関係
| Jupyter/Colab | Databricks |
|---|---|
| カーネル再起動 | 新しいセッションの開始(Detach and re-attach) |
!pip install |
%pip install(マジックコマンド) |
| .ipynbファイル | そのままインポート・エクスポート可能 |
| matplotlib/seaborn | そのまま使用可 + Databricks組み込み可視化 |
マジックコマンドによる言語切り替え
Databricksノートブックでは、Python、SQL、Scala、Rを同じノートブック内で切り替えて使用できます。
# Pythonセル
df = spark.read.table("samples.nyctaxi.trips")
display(df.limit(10))
displayはデータフレームを操作しやすい形で表示してくれます。さらには + > 可視化 を選択することで、簡単にグラフを作成することもできます。

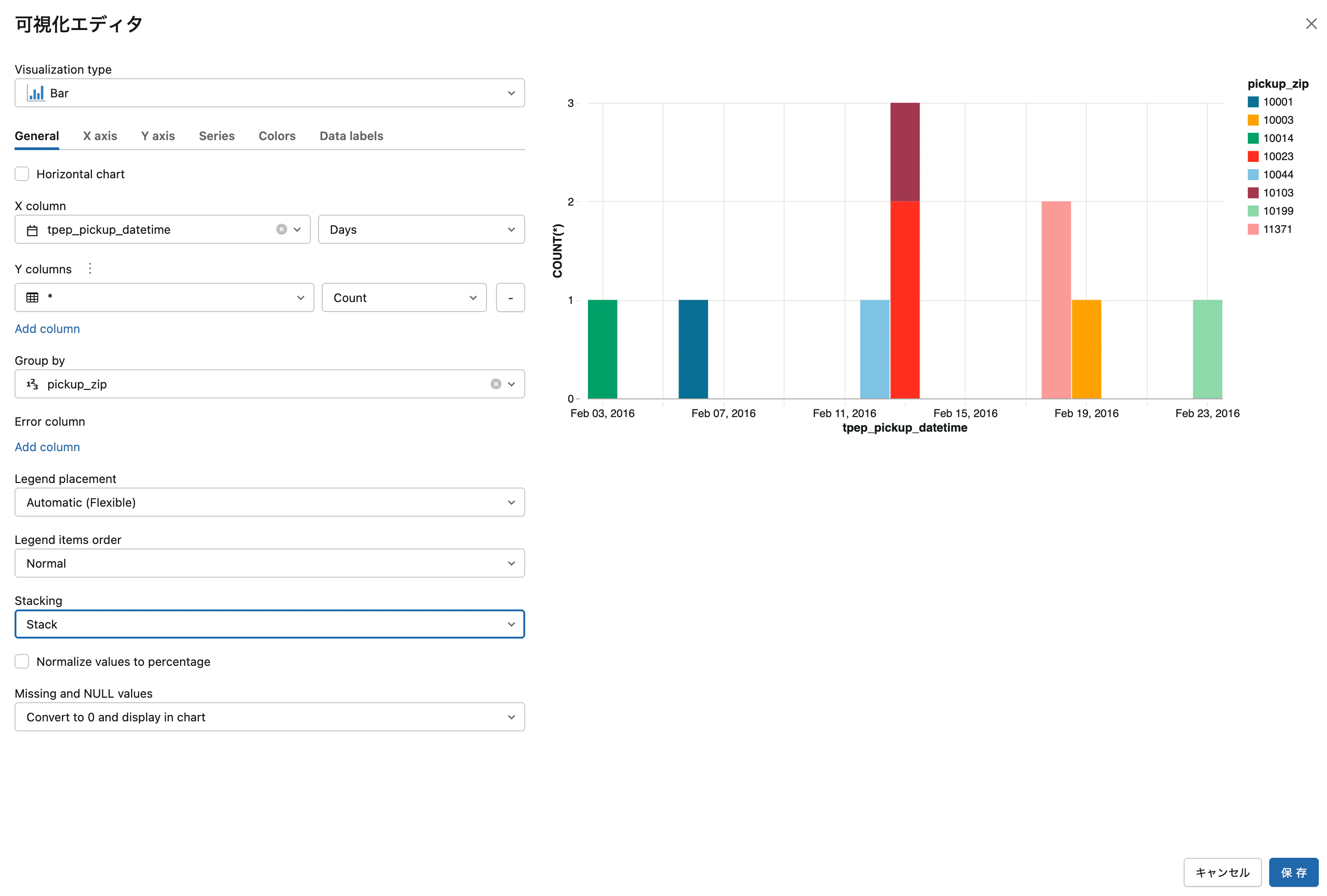

セルの先頭に%sqlを記述することで、SQLを直接取り扱うことができます。処理に合わせて言語を切り替えることができるのもDatabricksノートブックの特徴です。
%sql
-- SQLセル
SELECT * FROM samples.nyctaxi.trips LIMIT 10

Databricksアシスタントの活用
わからないことがあれば、Databricksアシスタントに日本語で質問できます。画面右上の十字星をクリックすることでアシスタントを呼び出すことができます。
-
/explain- コードの説明 -
/fix- エラーの修正 -
/optimize- コードの最適化 -
/findTables- テーブルの検索
注意 回答が英語の場合には、日本語で「説明して」と指示してみてください。

参考: Databricks初心者のための完全学習ガイド - Qiita
Step 3: PySpark基礎(1週間)
pandasとPySparkの違い
簡単に言うと、pandasはシングルマシンでオペレーションを実行し、PySparkは複数台のマシンで処理を実行します。より大きなデータセットを取り扱う場合、pandasよりもはるかに高速(100倍)にオペレーションを実行できます。
| 特徴 | pandas | PySpark |
|---|---|---|
| 処理方式 | シングルマシン | 分散処理 |
| データフレーム | 可変(mutable) | 不変(immutable) |
| 評価方式 | 即時評価 | 遅延評価 |
| 大規模データ | メモリ制限あり | クラスターでスケール |
参考: サンプルを通じたPandasとPySparkデータフレームの比較 - Qiita
pandas → PySpark の移行例
# === pandas での書き方 ===
import pandas as pd
df = pd.read_csv('data.csv')
df['new_col'] = df['col1'] + df['col2']
result = df[df['amount'] > 100]
# === PySpark での書き方 ===
from pyspark.sql.functions import col
df = spark.read.csv('data.csv', header=True, inferSchema=True)
df = df.withColumn('new_col', col('col1') + col('col2'))
result = df.filter(col('amount') > 100)
PySparkではselectメソッドでカラムを選択し、withColumnメソッドで新しいカラムを作成します。また、col関数を使用してカラムを指定します。
参考: データ処理の始めの一歩:Pandas と PySpark の違いと実践コーディング - Qiita
Pandas API on Spark(おすすめ!)
pandasのAPIをそのまま使いながら、裏側でSparkが分散処理を行う機能があります。pandasに慣れているがApache Sparkには慣れていないデータサイエンティストにとっては理想的な選択肢です。
# Pandas API on Spark を使う場合
import pyspark.pandas as ps
# ほぼ pandas と同じ書き方で分散処理!
df = ps.read_csv('data.csv')
df['new_col'] = df['col1'] + df['col2']
result = df[df['amount'] > 100]
参考: Python開発者向けDatabricksのご紹介 - Qiita
3種類のDataFrameの使い分け
Databricks(PySpark)では、以下の3種類のDataFrameが使えます。
| 種類 | 特徴 | 用途 |
|---|---|---|
pandas.DataFrame |
いつものDataFrame | 小規模データ、既存コードの再利用 |
pyspark.sql.DataFrame |
PySparkのDataFrame | 大規模分散処理、SQL連携 |
pyspark.pandas.DataFrame |
Sparkで動くpandas風DataFrame | pandasユーザーの移行に最適 |
参考: PySpark (Databricks) で使える3種類の DataFrame を相互変換する - Qiita
Step 4: Delta Lake を理解する(1週間)
Delta Lakeは、データレイクの柔軟性とデータウェアハウスの性能を併せ持つレイクハウスアーキテクチャの基盤です。
Delta Lakeの主な機能
- ACIDトランザクション: データの整合性を保証
- タイムトラベル: 過去のバージョンにアクセス可能
- スキーマ強制: データ品質を維持
- MERGE操作: UPDATEやDELETEが可能
# Delta形式でテーブルを作成(デフォルト)
df.write.saveAsTable("my_catalog.my_schema.my_table")
# タイムトラベル(過去のバージョンを参照)
df_old = spark.read.option("versionAsOf", 5).table("my_table")
# MERGE操作(Upsert)
from delta.tables import DeltaTable
deltaTable = DeltaTable.forName(spark, "my_catalog.my_schema.my_table")
deltaTable.merge(
source_df,
"target.id = source.id"
).whenMatchedUpdate(set={"status": "source.status"}).whenNotMatchedInsert(values={"id": "source.id", "status": "source.status"}).execute()
参考: はじめてDatabricksをさわってみて - Qiita
Step 5: Unity Catalog(データガバナンス)(2週間目)
Unity Catalogは、Databricksにおける統一的なデータガバナンスソリューションです。
3階層の名前空間
catalog.schema.table
↓ ↓ ↓
main.default.people_10m
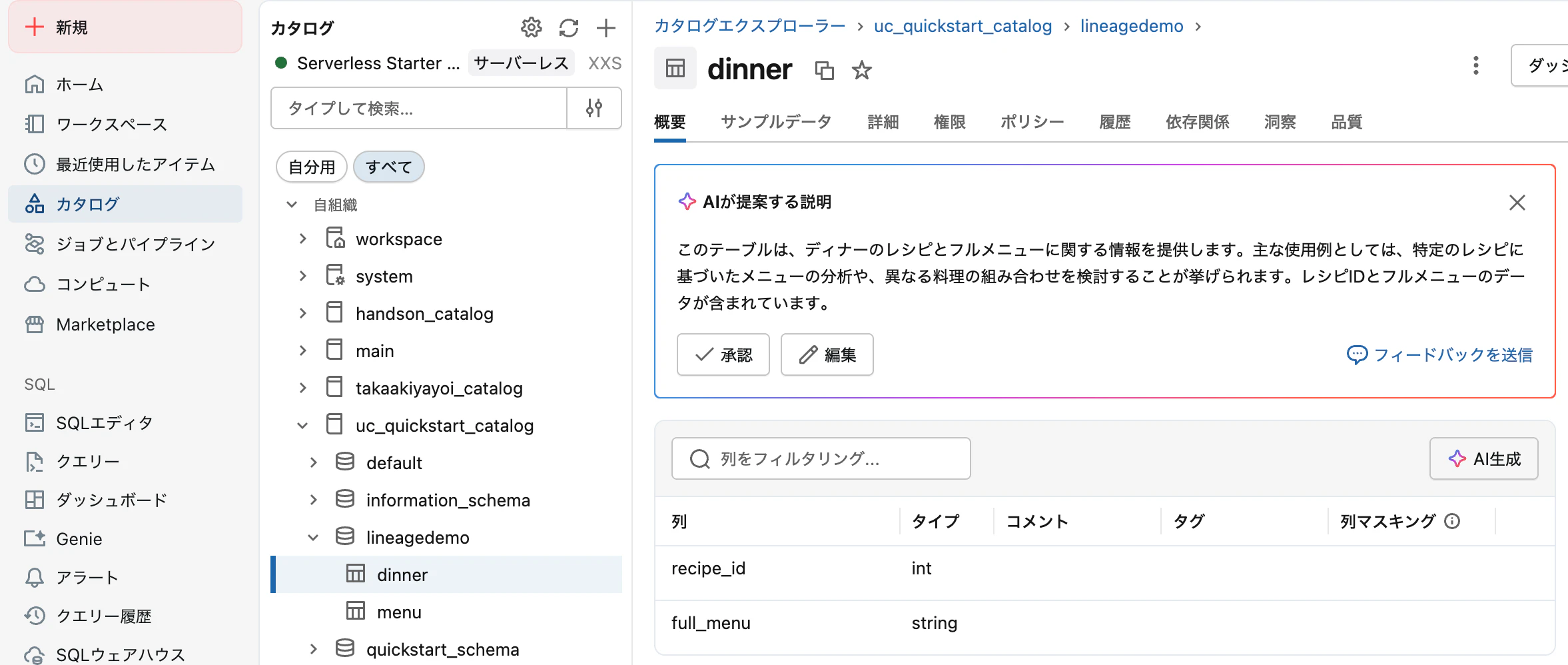
3階層の名前空間で管理されるテーブル

自動で捕捉されるテーブルの依存関係(リネージ)
-- Unity Catalogを使ったデータアクセス
SELECT * FROM main.default.people_10m
# PythonからUnity Catalogのテーブルにアクセス
df = spark.table("main.default.people_10m")
参考: データブリックスのUnity Catalogで実現する真のデータガバナンス #Databricks - Qiita
Step 6: 生成AI機能の活用(3週間目)
2025年現在、最も需要が高く、ビジネス価値が高いスキルです。
AI Playgroundでノーコード体験
コードを書かずにLLMを体験できます。様々なLLMモデルを試せます。

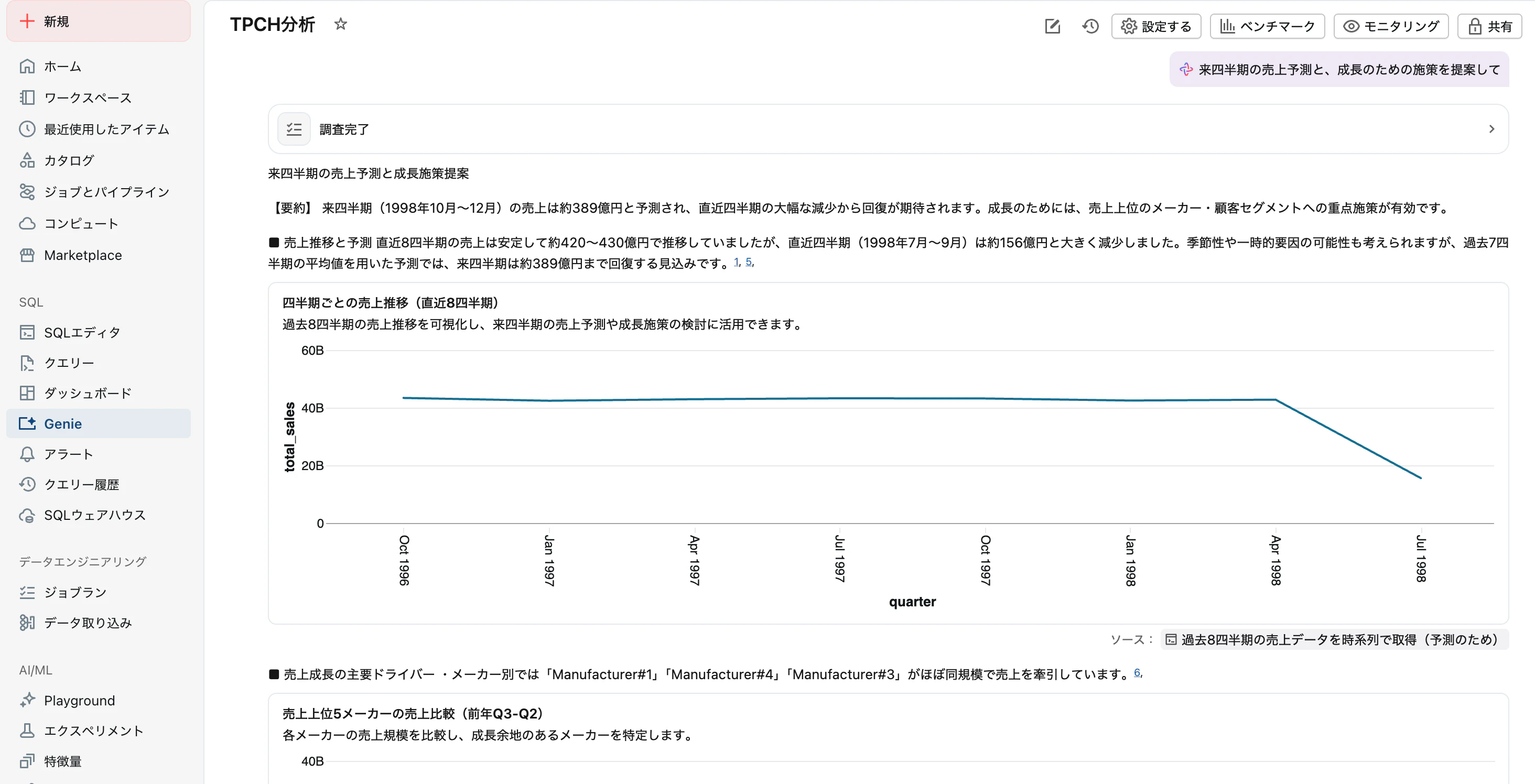
Genie
日本語指示によるデータ分析を体験しましょう。
AI関数(SQL内でLLMを呼び出し)
-- SQLから直接LLMを呼び出し
SELECT ai_query(
'databricks-meta-llama-3-1-70b-instruct',
'このレビューの感情を分析してください: ' || review_text
) as sentiment
FROM reviews
参考: Databricks初心者のための完全学習ガイド - Qiita
4週間学習プラン
| 週 | 学習内容 | 目標 |
|---|---|---|
| Week 1 | 環境構築 + ノートブック基本 | Jupyterコードを移行して動かす |
| Week 2 | PySpark + Delta Lake | 大規模データ処理の基礎を習得 |
| Week 3 | Unity Catalog + SQLクエリ | データガバナンスとSQL分析 |
| Week 4 | MLflow + Jobs + 生成AI | MLワークフローと自動化 |
おすすめ学習リソース
公式リソース
| リソース | URL |
|---|---|
| Free Edition サインアップ | https://login.databricks.com/signup?provider=DB_FREE_TIER |
| 公式ドキュメント(日本語) | https://docs.databricks.com/ja/ |
| Databricks Academy | https://www.databricks.com/learn |
日本語Qiita記事(おすすめ)
| 記事 | 対象レベル |
|---|---|
| はじめてのDatabricks | 入門 |
| Databricks入門:データとAIを統合する次世代プラットフォーム | 入門 |
| Databricks初心者のための完全学習ガイド | 入門〜中級 |
| PySparkことはじめ | 入門 |
| pandasの常識を捨てよう:PySparkで求められる思考法シフト | 中級 |
| Databricks記事のまとめページ | 全レベル |
書籍
-
データブリックス クイックスタートガイド(Kindle版 99円)
- 浅く広く知るためにおすすめ
- 同じ内容がQiitaにも無料で掲載されていますが、Kindle版は1つにまとまっており読みやすい
参考: 新卒・業界未経験エンジニアが約3週間でDatabricks Certified Data Engineer Associateを取得した学習履歴 - Qiita
学習のコツ
-
まずは全体像を把握する: 最初から全てを理解しようとせず、大まかに理解してから詳細に踏み込む
-
実際に触ってみる: Databricksを触れる環境がある場合は、チュートリアルを進めることで理解が深まる
-
公式ドキュメントに立ち返る: わからない部分は公式ドキュメントに立ち返るのが結局一番の近道
-
AIアシスタントを活用: Databricksアシスタントに日本語で質問できるので、積極的に活用する
おわりに
Databricksは、データ分析から最新の生成AIまで、幅広いニーズに対応できるプラットフォームです。
特に以下のような方におすすめです:
- データ分析初心者: AIアシスタントが日本語でサポート
- エンジニア: 統合環境で効率的な開発が可能
- ビジネスユーザー: プログラミング不要でデータ分析
- データサイエンティスト: 最新のAI/ML機能を活用
まずはFree Editionで、Databricksの世界を体験してみてください!
参考文献
- はじめてのDatabricks - Qiita
- Databricks入門:データとAIを統合する次世代プラットフォーム - Qiita
- Databricks初心者のための完全学習ガイド - Qiita
- PySparkことはじめ - Qiita
- サンプルを通じたPandasとPySparkデータフレームの比較 - Qiita
- pandasの常識を捨てよう:PySparkで求められる思考法シフト - Qiita
- データ処理の始めの一歩:Pandas と PySpark の違いと実践コーディング - Qiita
- Python開発者向けDatabricksのご紹介 - Qiita
- PySpark (Databricks) で使える3種類の DataFrame を相互変換する - Qiita
- 新卒・業界未経験エンジニアが約3週間でDatabricks Certified Data Engineer Associateを取得した学習履歴 - Qiita
- はじめてDatabricksをさわってみて - Qiita
- Databricks記事のまとめページ - Qiita