こちらの記事に触発されて自分でもやってみました。
無料のCommunity Editionへのサインアップの手順についてはこちらを参考にしてください。また、フルバージョンのDatabricksとの違いに関しては、こちらを参照ください。
以下の手順では、すでにワークスペースへのログインまで完了していることを前提としています。
Databricks AutoMLとは
AutoMLとはAutomated machine learningの略であり、現実世界の問題に対して機械学習を適用する際のタスクを自動化するプロセスのことを意味します。
Databricks AutoMLを活用することで、データセットに対して自動で機械学習を適用することができます。モデルのトレーニングのためにデータセットを準備し、一連の実験を実施、記録し、複数のモデルに対して、作成、チューニング、評価を行います。結果の表示に加えて、中身を確認し、再現、修正できるようにそれぞれの実験のソースコードをPythonノートブック形式で提供します。また、AutoMLはデータセットの統計情報を計算し、後ほど確認できるようにノートブックの中に情報を記録します。
AutoMLはハイパーパラメーターチューニングのトライアルを自動でクラスターのワーカーノードに分散します。
それぞれのモデルは、scikit-learnやXGBoostなどのオープンソースコンポーネントから構築され、容易に修正でき、既存の機械学習パイプラインに組み込むことができます。回帰、分類、予測問題に対してDatabricks AutoMLを活用できます。scikit-learn、xgboost、LightGBMパッケージのアルゴリズムに基づきモデルを評価します。
UIあるいはPython APIでAutoMLを実行することができます。
注意
Community EditionではPythonノートブックからのAutoMLの実行は可能ですが、GUIでのAutoMLはサポートされていません。GUIでのAutoMLのウォークスルーに関しては、こちらを参照ください。
ノートブックとクラスターを準備する
AutoMLで分類問題を解くノートブックは以下のURLに置いてあります。これをインポートして実行します。
-
サイドメニューが日本語になっていない場合は、こちらを参考に言語を日本語に設定してください。
-
サイドメニューからワークスペースを選択します。
-
ホームボタンをクリックして、自分のホームディレクトリに移動します。
-
自分のメールアドレスの右にある下向き矢印のアイコンをクリックしてメニューを展開します。
-
インポートを選択します。インポートダイアログが表示されます。このダイアログからノートブックをインポートすることができます。
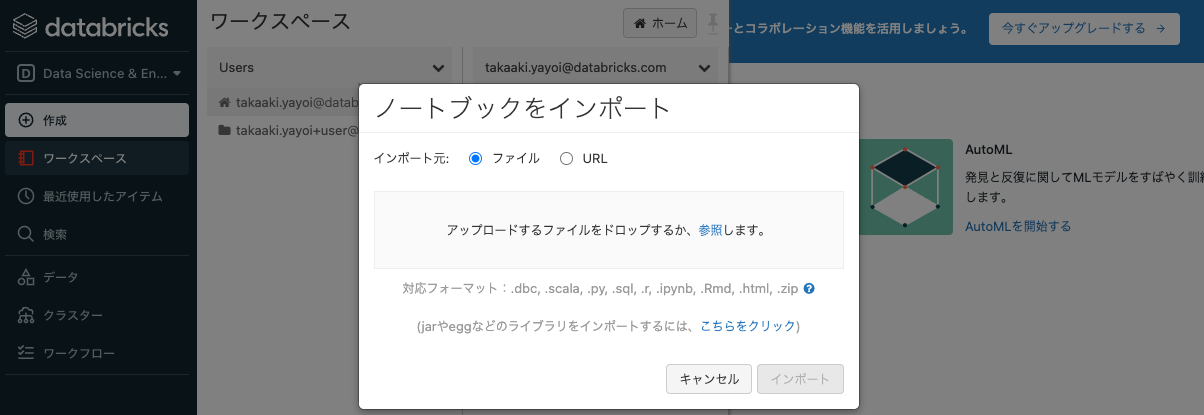
-
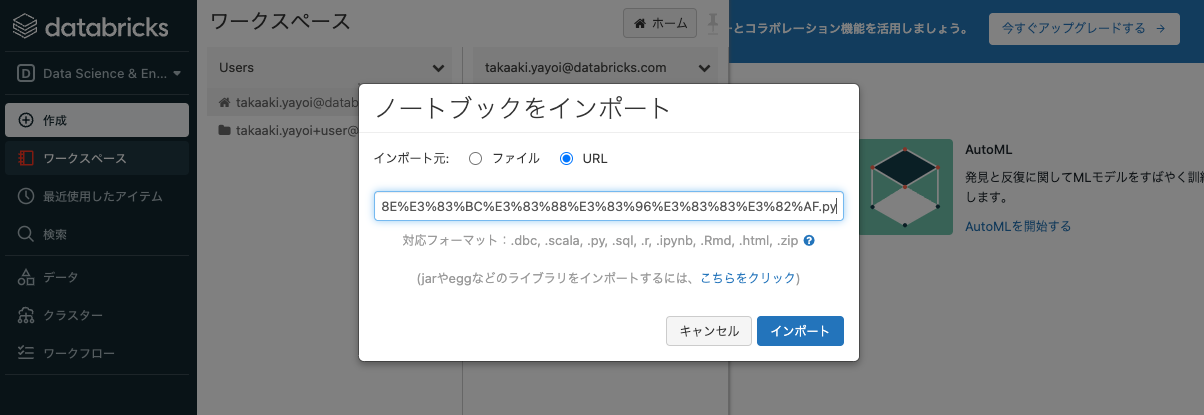
URLを選択します。
-
ボックスに以下のURLを貼り付けます。
https://raw.githubusercontent.com/taka-yayoi/public_repo/main/AutoML_classification/Databricks%20AutoML%E5%88%86%E9%A1%9E%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB%E3%83%8E%E3%83%BC%E3%83%88%E3%83%96%E3%83%83%E3%82%AF.py -
インポートをクリックすると、ノートブックがインポートされます。
-
左上のアタッチされていませんと表示されているドロップダウンリストを展開し、クラスターを作成するをクリックします。
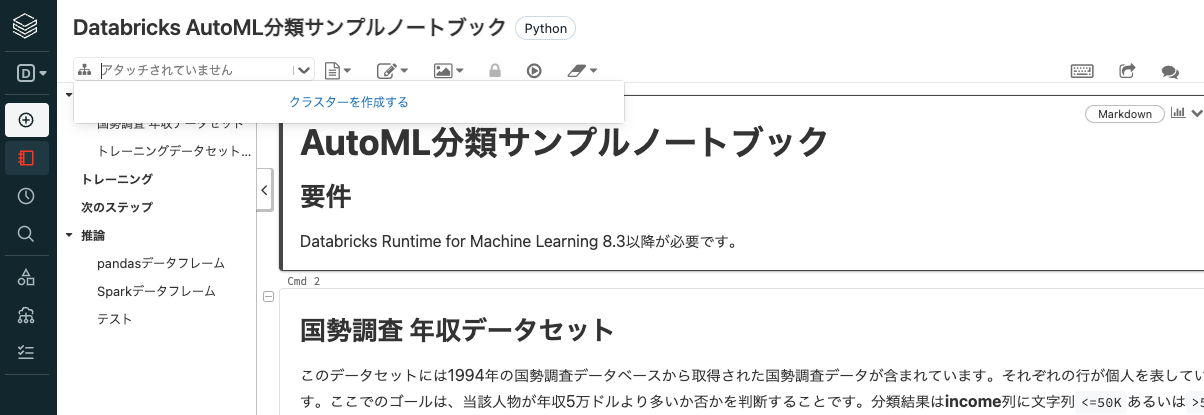
-
クラスター作成画面に遷移します。クラスターとはDatabricksにおける計算資源です。ノートブックの処理を実行するにはクラスターが必要となります。なお、ノートブックの編集の際にはクラスターは不要です。
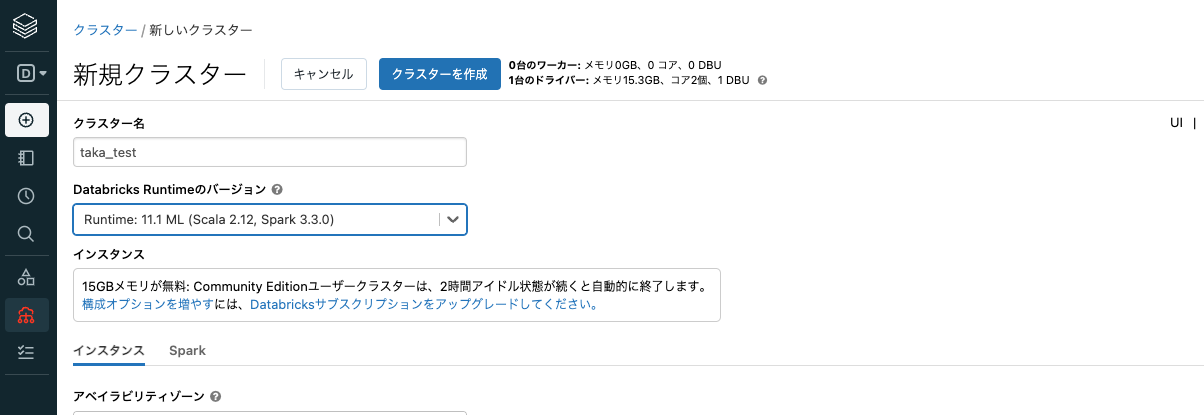
- クラスター名にわかりやすい名前をつけます。
-
Databricks Runtimeのバージョンで、
Runtime: 11.1MLを選択します。ランタイムとはクラスターに自動でインストールされるソフトウェアパッケージです。
-
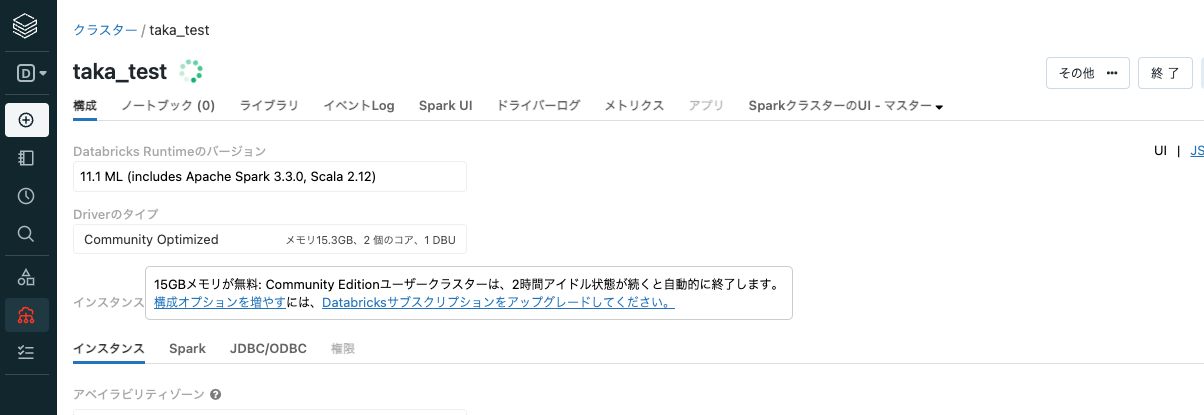
クラスターを作成をクリックします。クラスター名の右側のインジケーターが回転し、クラスターの作成が開始します。数分時間を要しますのでお待ちください。
-
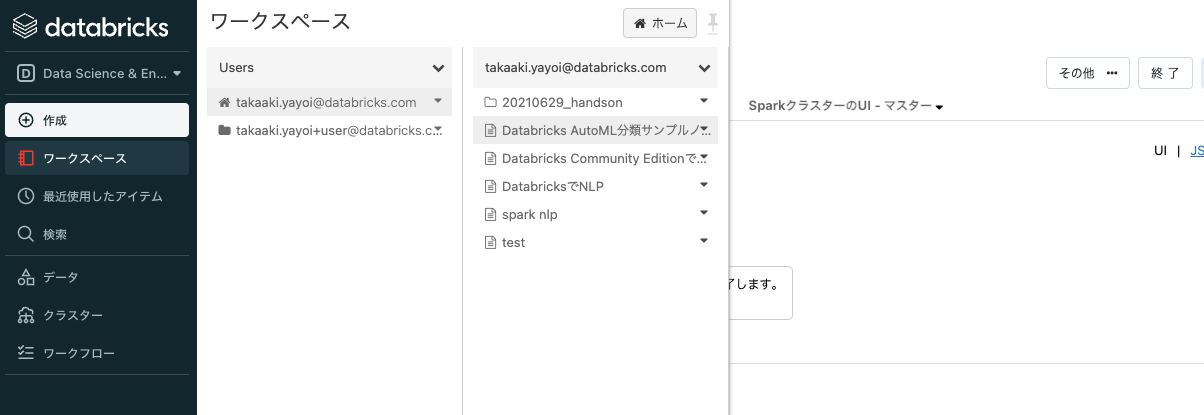
再びサイドメニューからワークスペースをクリックし、自分のホームディレクトリにある
Databricks AutoML分類サンプルノートブックをクリックして、ノートブックを開きます。
-
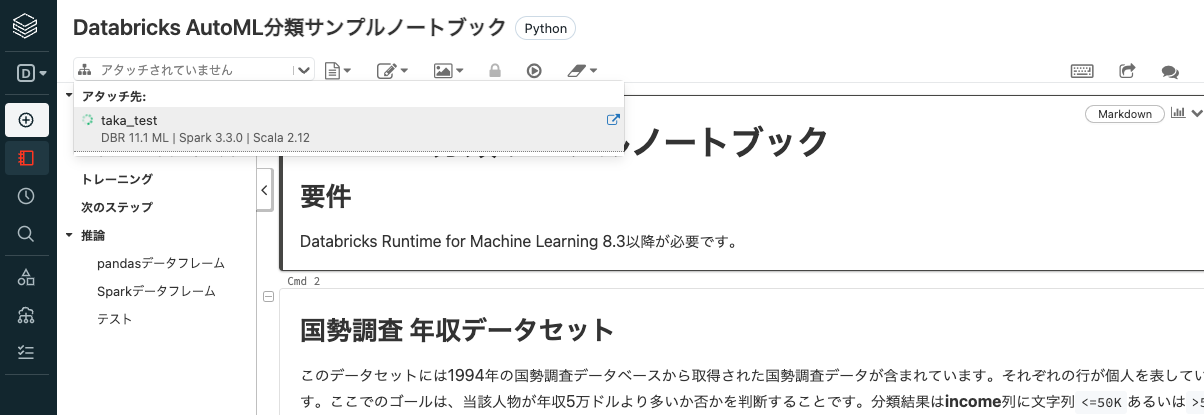
左上のドロップダウンリストから先ほど選択したクラスターを選択します。
-
クラスターが起動するとインジケータがチェックマークに変わります。
分類問題を解いてみる
国勢調査 年収データセット
分類問題で使用するデータセットには1994年の国勢調査データベースから取得された国勢調査データが含まれています。それぞれの行が個人を表しています。ここでのゴールは、当該人物が年収5万ドルより多いか否かを判断することです。分類結果はincome列に文字列<=50Kあるいは>50kで表現されます。
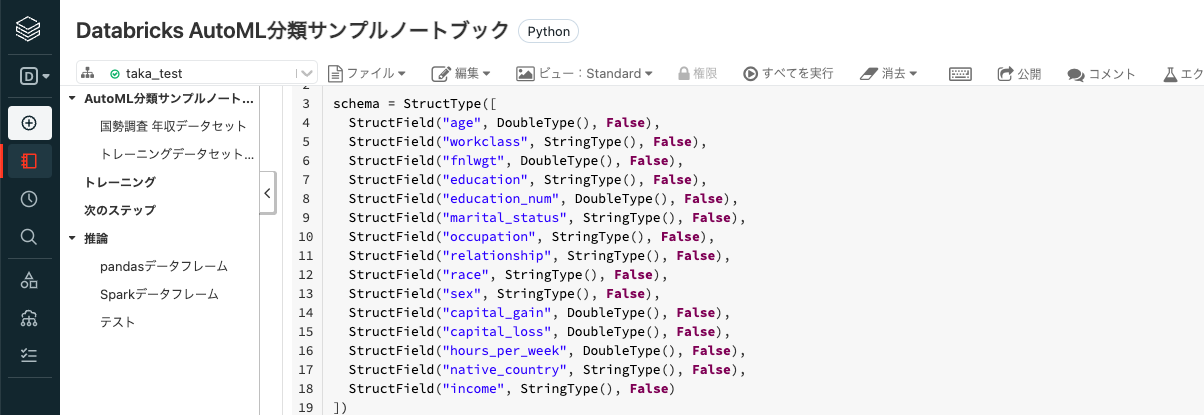
以下のセルではデータのスキーマを定義した上で、データを読み込んでSparkデータフレームとしてロードしています。セルを実行するにはセル右側にある▶︎ボタンを展開し、▶︎セルを実行をクリックします。

from pyspark.sql.types import DoubleType, StringType, StructType, StructField
schema = StructType([
StructField("age", DoubleType(), False),
StructField("workclass", StringType(), False),
StructField("fnlwgt", DoubleType(), False),
StructField("education", StringType(), False),
StructField("education_num", DoubleType(), False),
StructField("marital_status", StringType(), False),
StructField("occupation", StringType(), False),
StructField("relationship", StringType(), False),
StructField("race", StringType(), False),
StructField("sex", StringType(), False),
StructField("capital_gain", DoubleType(), False),
StructField("capital_loss", DoubleType(), False),
StructField("hours_per_week", DoubleType(), False),
StructField("native_country", StringType(), False),
StructField("income", StringType(), False)
])
input_df = spark.read.format("csv").schema(schema).load("/databricks-datasets/adult/adult.data")
トレーニングデータセットとテストデータセットの分割
train_df, test_df = input_df.randomSplit([0.99, 0.01], seed=42)
display(train_df)
トレーニング
以下のコマンドでAutoMLを実行します。モデルが予測すべき目的変数を、引数target_colで指定する必要があります。実行が完了すると、トレーニングでベストなモデルを生成したノートブックにアクセスして、コードを確認することができます。このノートブックには特徴量の重要度のグラフも含まれています。timeout_minutesが30に設定されているので、処理に最大30分要します。
from databricks import automl
summary = automl.classify(train_df, target_col="income", timeout_minutes=30)
こちらを実行するとAutoMLによって大量の機械学習モデルが生成されますが、これら全てはMLflowによって自動でトラッキングされます。MLflowでは1回の機械学習モデルのトレーニングをランと呼び、それらのランをまとめてエクスペリメントという単位で管理します。
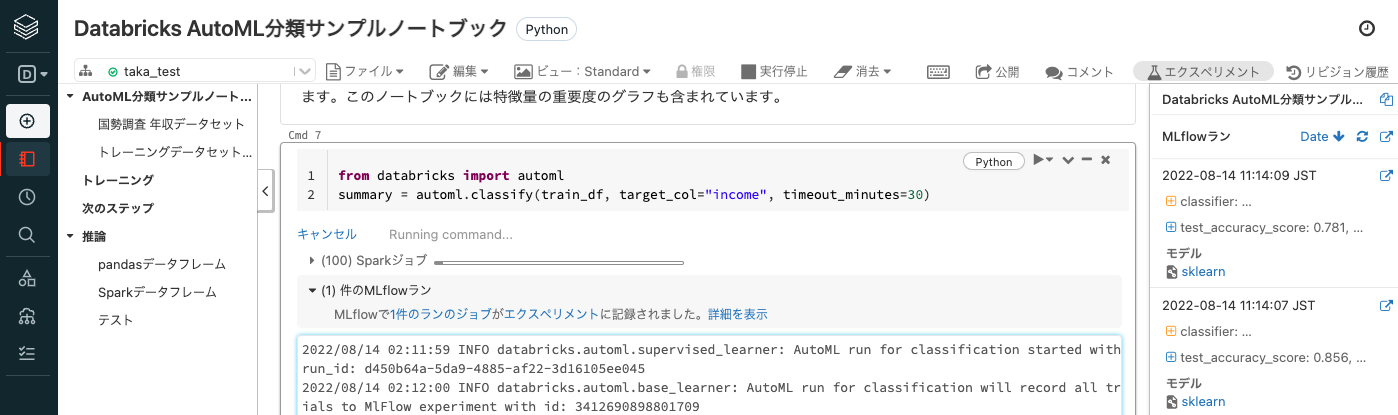
画面右上のエクスペリメントをクリックするとサイドバーとして記録されたモデルが一覧表示されます。
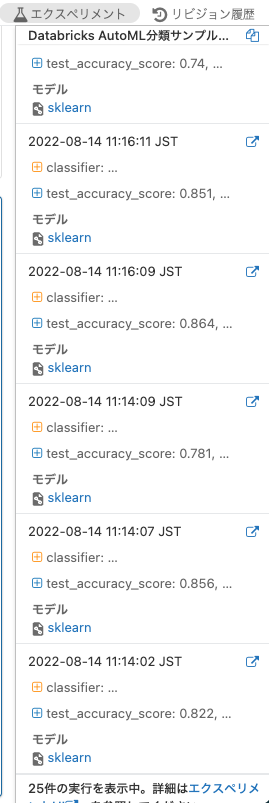
この状態でMLflowランの右にある右上向きに矢印が伸びているアイコンをクリックすると、別タブで詳細画面(エクスペリメントページ)が開きます。ちなみにその左にあるDate↓をクリックするとモデルのソート順を変更することができます。
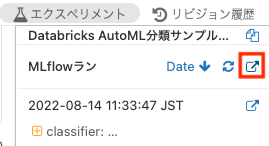
エクスペリメントページではトレーニングされたモデルのハイパーパラメーターやアルゴリズムなど詳細を確認したり、モデル同士を比較することができます。
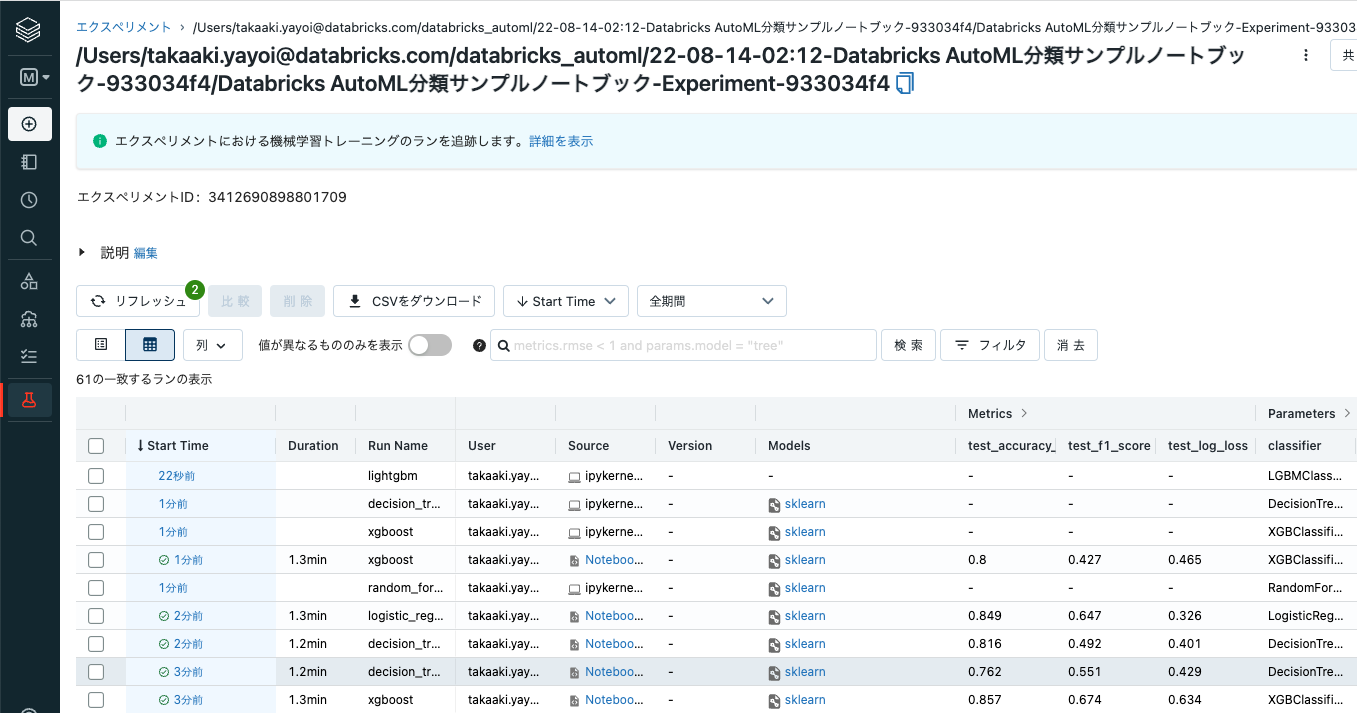
トレーニングが終了すると以下のようなリンクが表示されます。
-
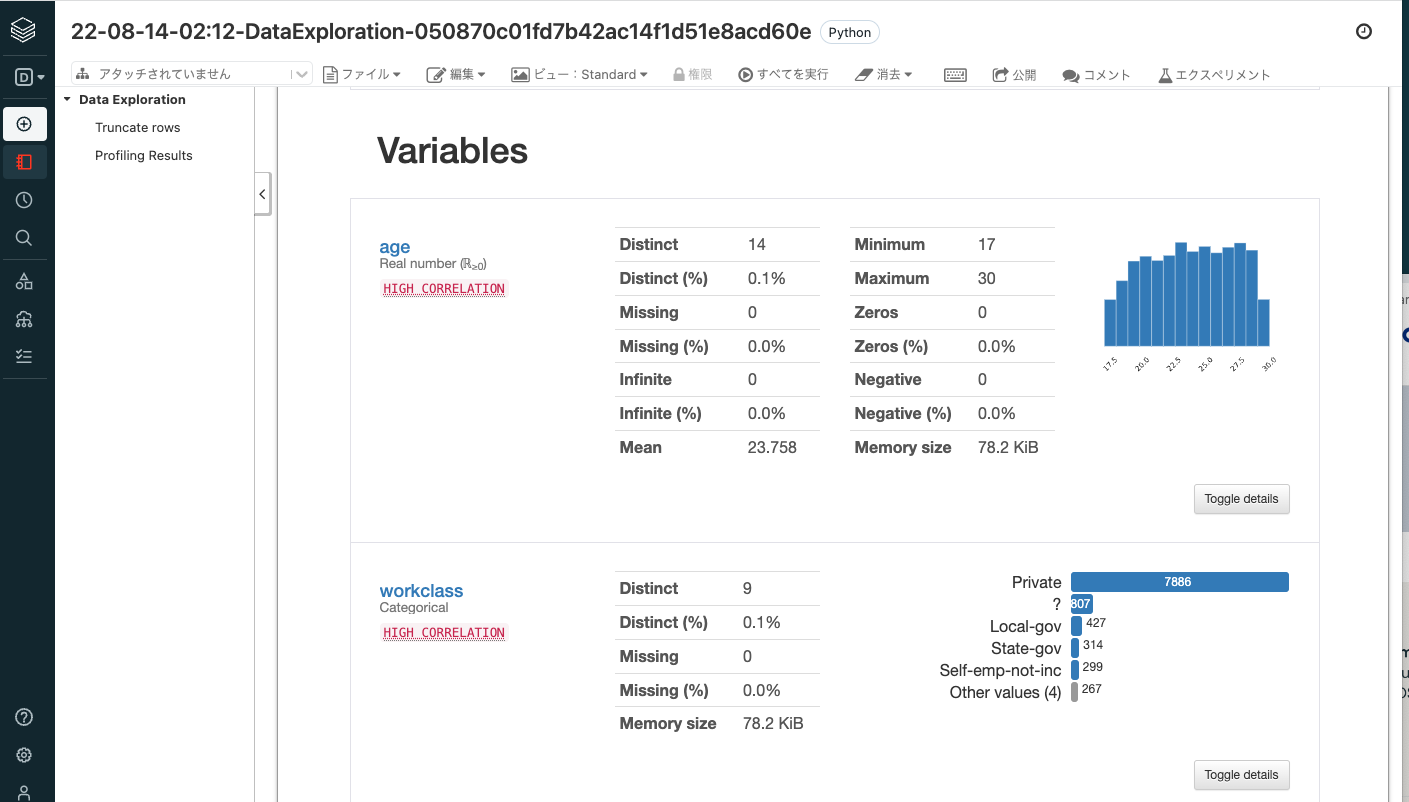
data exploration notebookは、AutoMLに入力されたデータの分布などを確認できるノートブックであり、リンクをクリックすると別タブで開きます。
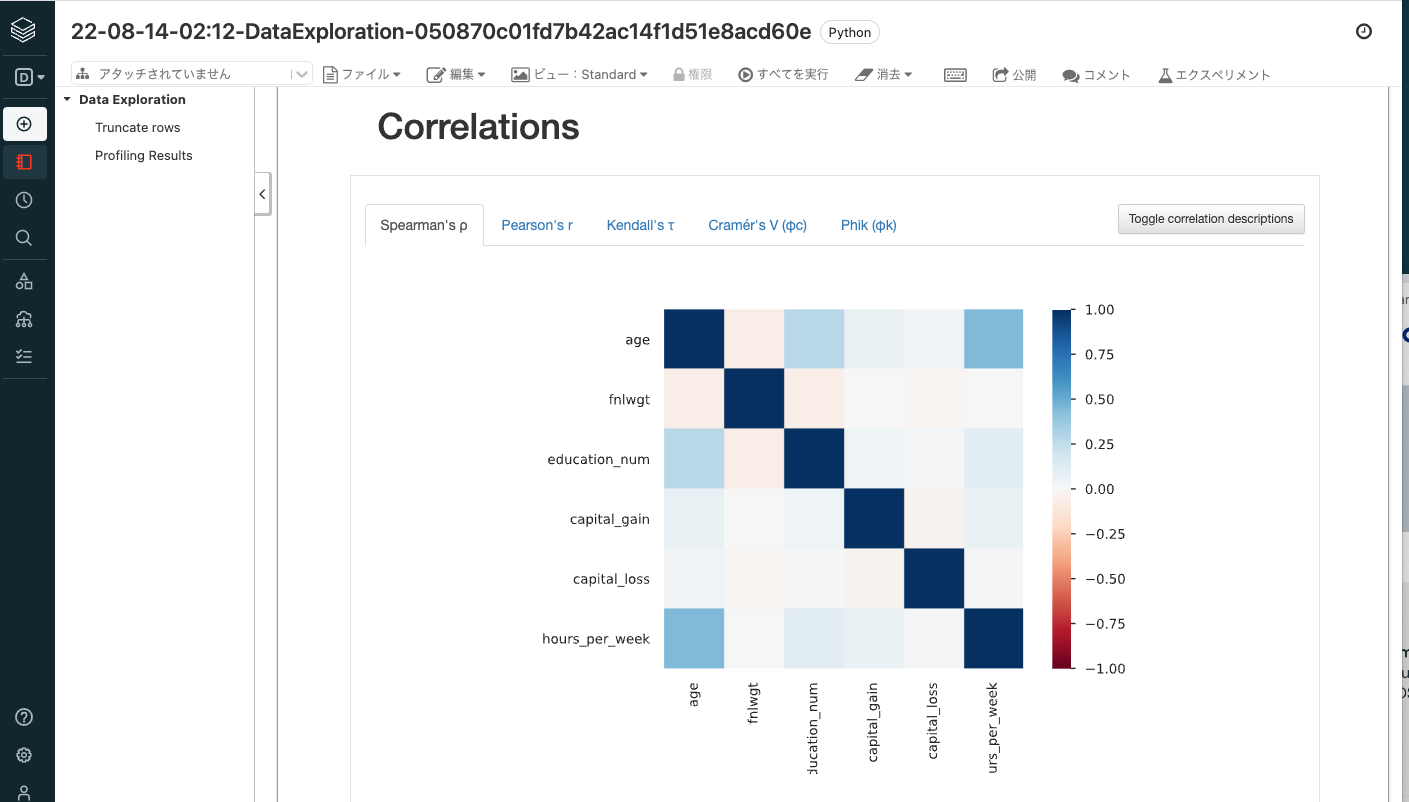
-
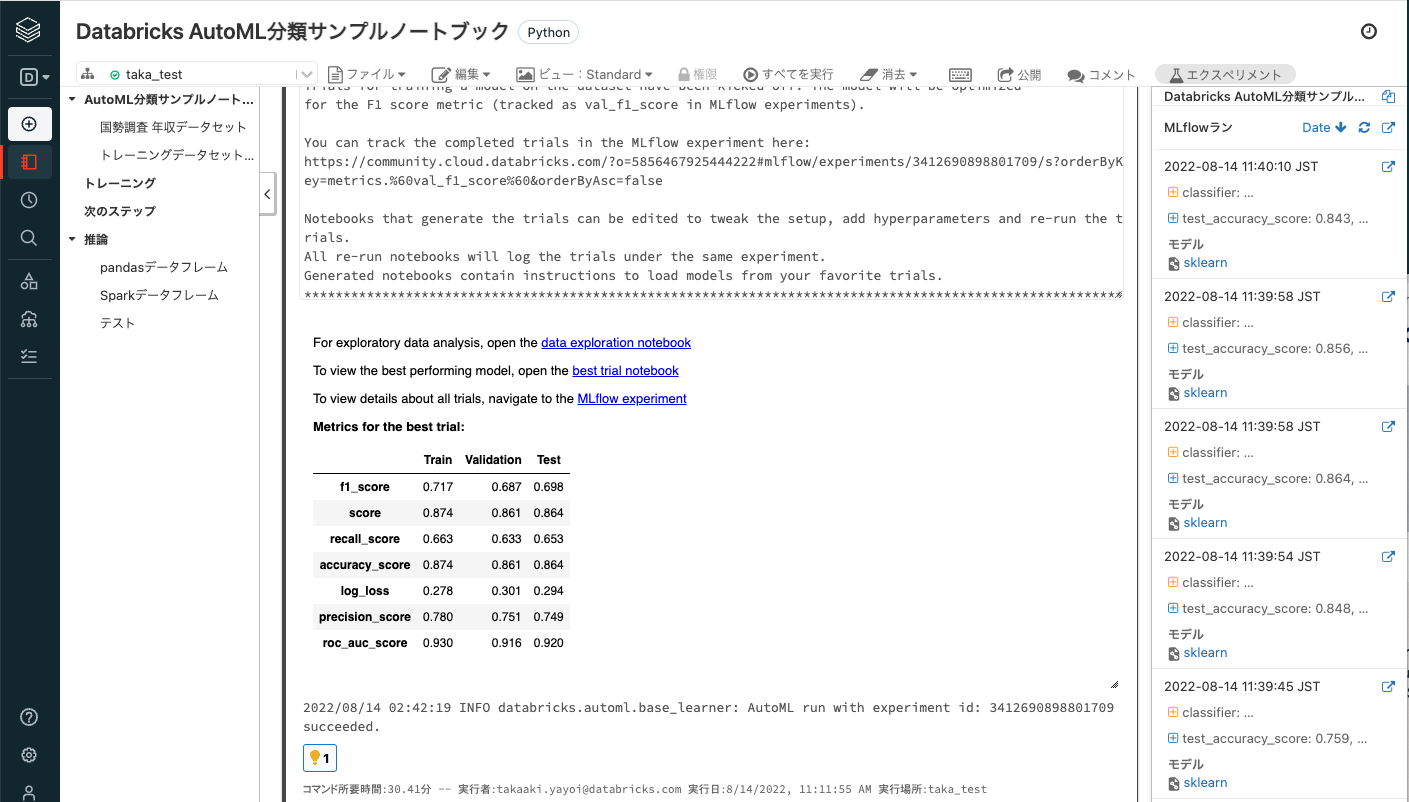
best trial notebookは、AutoMLの結果最も良い精度を出したモデルをトレーニングした処理を記述しているノートブックであり、リンクをクリックすると別タブで開きます。今回はLightGBMが最も良い精度となりました。
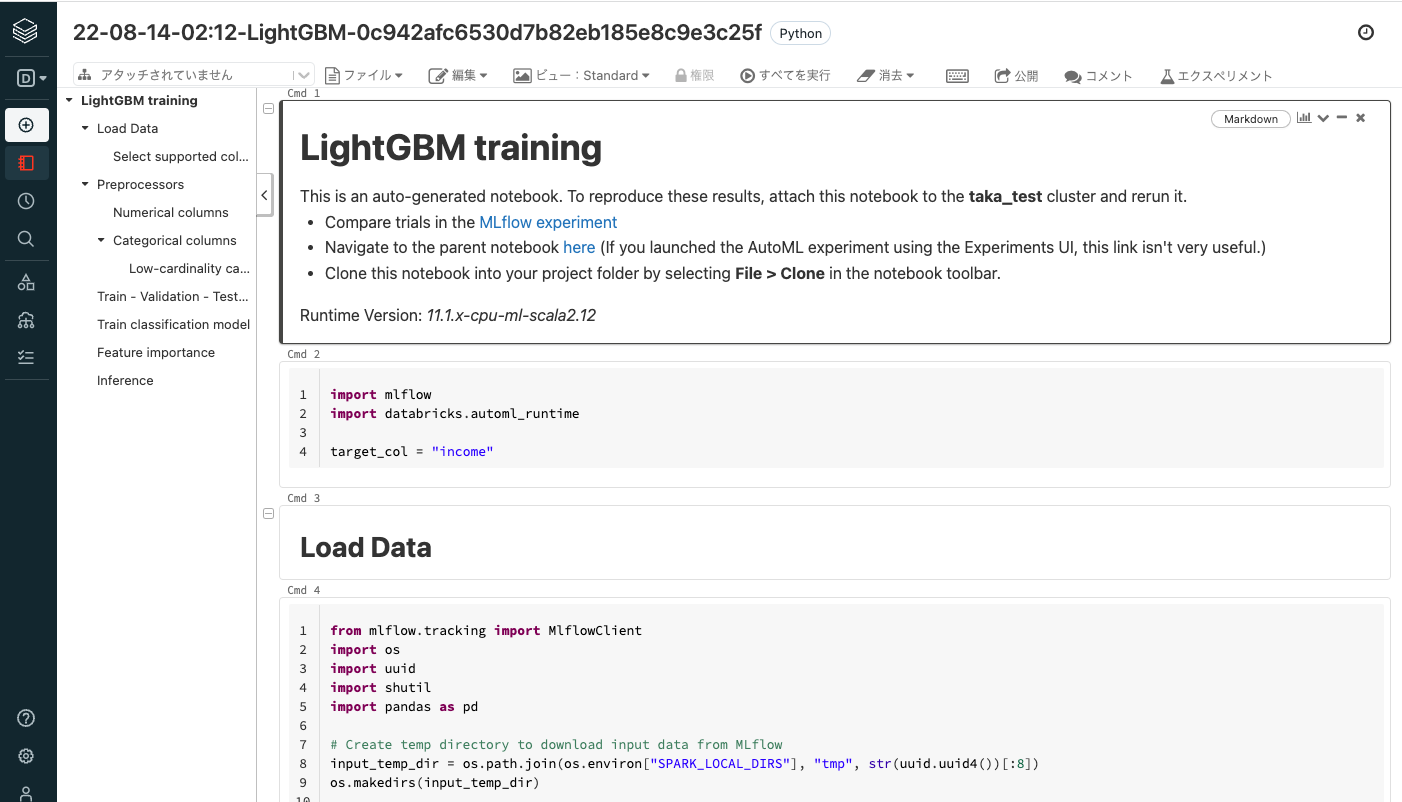
-
MLflow experimentは、先ほど上で確認したエクスペリメントページへのリンクとなります。今回は合計74モデルがトレーニングされました。
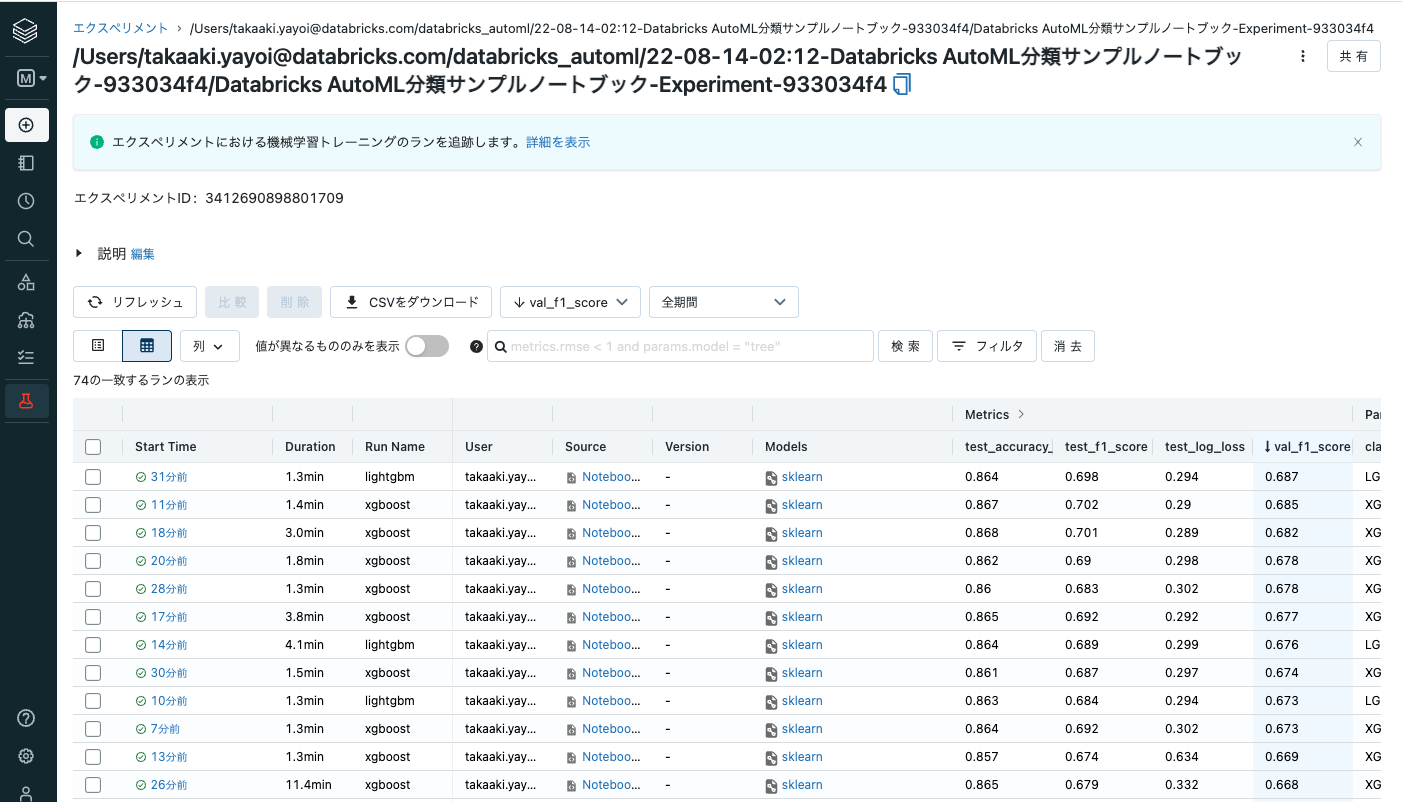
ここで、ラン一覧の左上のチェックボックスにチェックを入れ全てのモデルを選択した状態で比較をクリックすると、それぞれのモデルを詳細に比較することができます。
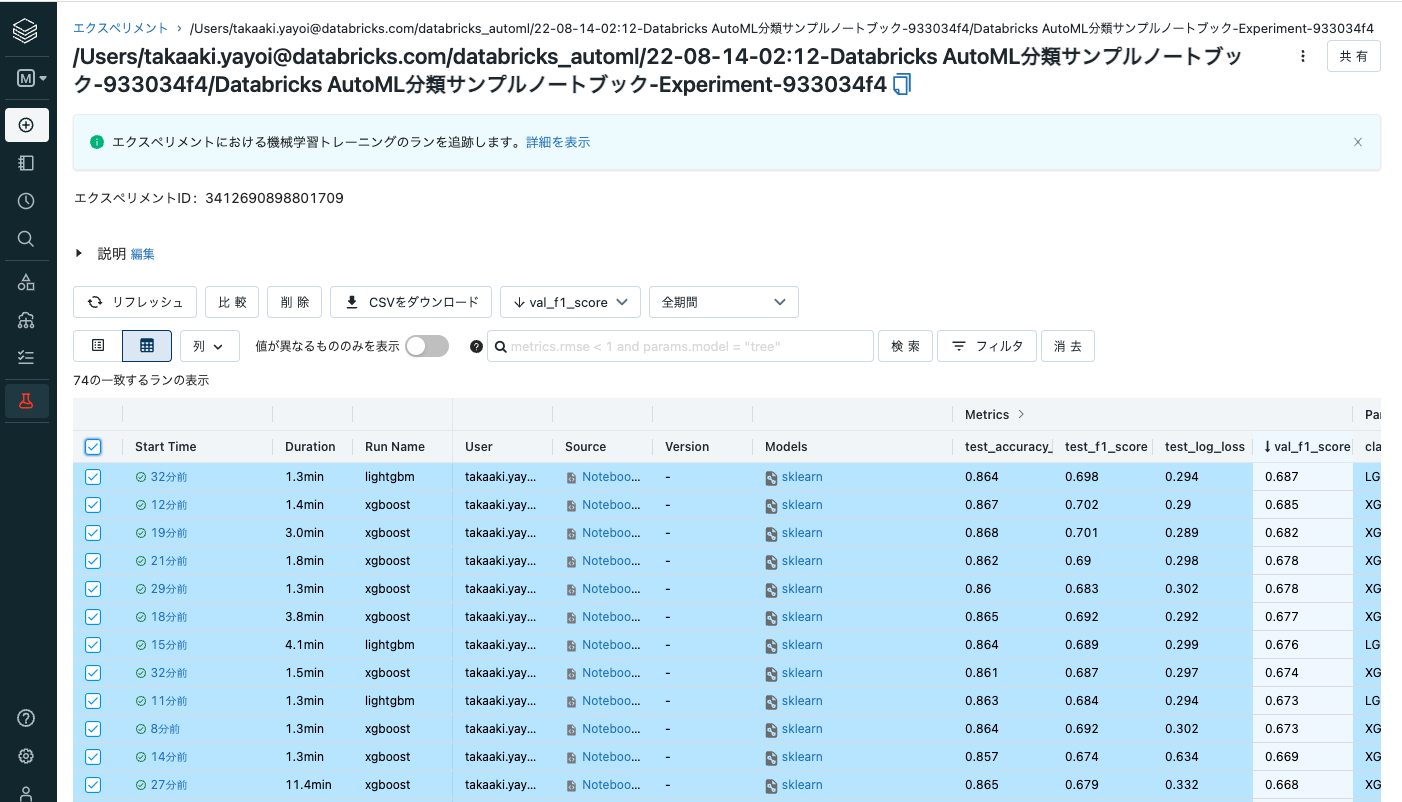
散布図を選択し、縦軸、横軸を選択することで、どのような傾向にあるのかをグラフで確認することも可能です。
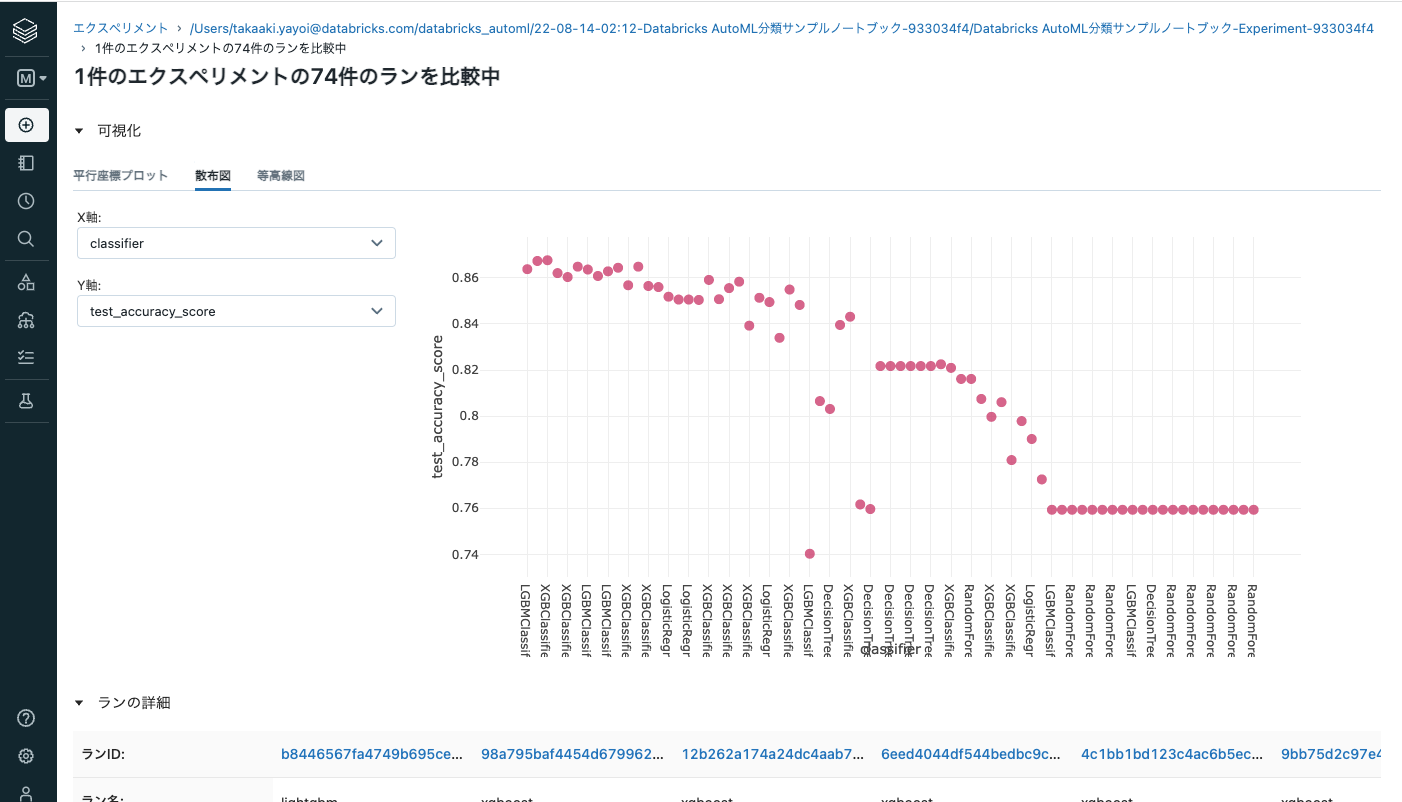
フルバージョンのDatabricksであれば、データセットの指定や問題の選択などをGUIから行うことができますが、Community Editionであってもこれだけの機能を活用してAutoMLを行うことができます。加えて、処理過程はすべてPythonノートブックとして生成されるので、中身のロジックのチェックやカスタマイズも容易です。
推論
トレーニングした機械学習モデルで推論を行うことも、MLflowを使えば簡単です。
新たなデータを用いて予測を行う際に、AutoMLでトレーニングしたモデルを活用することが可能です。以下の例では、pandasデータフレームのデータに対してどのように予測を行うのか、Sparkデータフレームに対して予測を行うために、モデルをどのようにSparkのUDF(ユーザー定義関数)として登録するのかをデモします。以下のコマンドでは、最も精度が良かった機械学習モデルのパスを取得しています。
model_uri = summary.best_trial.model_path
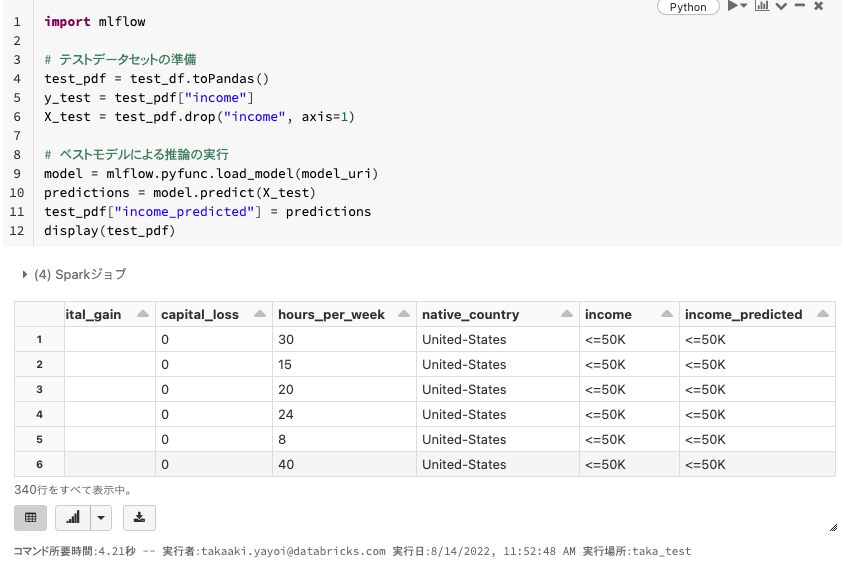
pandasデータフレームに対する推論の実施
import mlflow
# テストデータセットの準備
test_pdf = test_df.toPandas()
y_test = test_pdf["income"]
X_test = test_pdf.drop("income", axis=1)
# ベストモデルによる推論の実行
model = mlflow.pyfunc.load_model(model_uri)
predictions = model.predict(X_test)
test_pdf["income_predicted"] = predictions
display(test_pdf)
結果の一番右側にincome_predictedというカラムが追加されており、推論が行われていることがわかります。
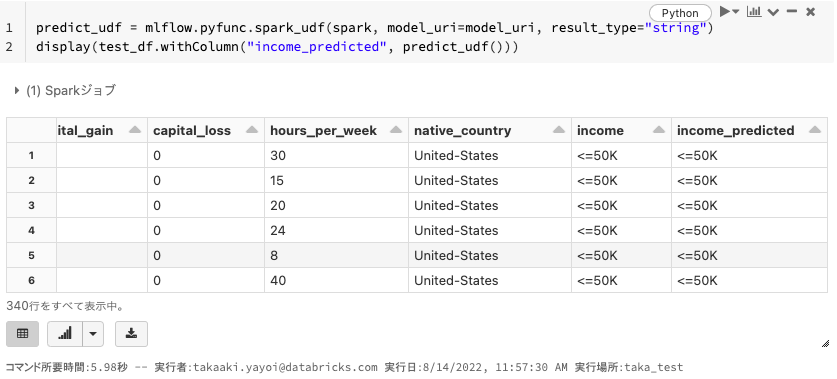
Sparkデータフレームに対する推論の実施
pandasデータフレームでも推論は可能ですが、推論するデータが大量になってきた場合、分散処理が可能となるSparkデータフレームを用いることをお勧めします。その際の推論では機械学習モデルをユーザー定義関数として定義することで、Pythonのapplyと同じような手順で分散処理による推論を行うことができます。
predict_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri, result_type="string")
display(test_df.withColumn("income_predicted", predict_udf()))
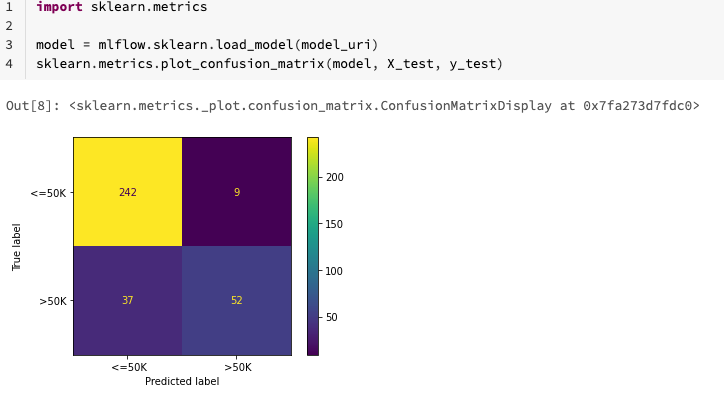
テスト
実運用環境において、最終的なベストモデルがどれだけの性能を発揮するのかを見積もるために、ホールドアウトしておいたテストセットで予測を行います。以下の図では正しい予測と誤った予測をブレークダウンしています。
まとめ
こちらでは、すぐにでも試せるCommunity EditionでのAutoMLを体験いただきました。Databricks AutoMLはGUIもサポートしていますが、それよりも重要なのは中身の処理が全てわかるようになっているガラスボックスアプローチであると考えています。これには以下のメリットがあります。
- 機械学習プロジェクトにおけるベースラインモデルをクイックに構築し、以降のカスタマイズを容易に行えます。
- いわゆるシチズンデータサイエンティストとプロフェッショナルデータサイエンティストのコラボレーションも円滑に行えるようになります(シチズンデータサイエンティストがビジネス知識を活かしてベースラインモデルを構築し、プロフェッショナルデータサイエンティストがチューニングを行う等)。
この他、Databricksでの機械学習に興味がある方はこちらの記事もご覧になってください。
- Databricks AutoMLのご紹介 : 機械学習開発の自動化に対するガラスボックスアプローチ
- Databricks AutoMLのマニュアル
- あなたの機械学習プロジェクトをDatabricks AutoMLでスーパーチャージしましょう
- Databricks機械学習ガイド
- Databricksにおける機械学習チュートリアル
- Databricksで機械学習を始めてみる
- 機械学習エンジニアとしてDatabricksを使い始める
- Databricksにおける機械学習モデル構築のエンドツーエンドのサンプル