Use AWS Glue Data Catalog as the metastore for Databricks Runtime | Databricks on AWS [2021/9/14時点]の翻訳です。
DatabricksランタイムでAWS Glueデータカタログをメタストアとして使用するように設定できます。これはその場で使えるHiveメタストアの代替として使用できます。
それぞれのAWSアカウントには、AWSリージョンにAWSアカウントIDと同じカタログIDを持つ単一のカタログがあります。Databricks向けにGlueカタログメタストアとして用いることで、AWSサービス、アプリケーション、AWSアカウントにまたがった共有メタストアを活用する可能性があります。
複数のDatabricksワークスペースで同じメタストアを共有するように設定することができます。
本文では、インスタンスプロファイルを用いてDatabricksでGlueデータカタログにセキュアにアクセスする方法を説明します。
要件
- Databricksがデプロイされており、Glueデータカタログを含むAWSアカウントのIAMロール、ポリシーにアクセスできるAWS管理者を持っている必要があります。
- Databricksがデプロイされているのとは異なるAWSアカウントとは別のAWSアカウントにGlueデータカタログがある場合には、クロスアカウントアクセスポリシーは、DatabricksがデプロイされているAWSアカウントからカタログへのアクセスを許可する必要があります。
メタストアとしてGlueデータカタログを設定する
Glueカタログのインテグレーションを有効化するためには、AWS設定のspark.databricks.hive.metastore.glueCatalog.enabledをtrueに設定します。この設定はデフォルトで無効になっています。すなわち、デフォルトではDatabricksがホストしているHiveメタストアを使用し、設定をおkなった場合に他の外部メタストアを使用します。
インタラクティブ、ジョブクラスターにおいては、クラスターの起動前にクラスターに設定を行います。
重要!
この設定オプションは、稼働中のクラスターでは変更できません。
spark-submitジョブを実行する際、この設定オプションを--conf spark.databricks.hive.metastore.glueCatalog.enabled=trueを用いて、spark-submitのパラメーターに指定するか、以下のようにSparkSession あるいはSparkContextを作成する前に設定します。
from pyspark.sql import SparkSession
# Set the Glue confs here directly instead of using the --conf option in spark-submit
spark = SparkSession.builder. \
appName("ExamplePySparkSubmitTask"). \
config("spark.databricks.hive.metastore.glueCatalog.enabled", "true"). \
enableHiveSupport(). \
getOrCreate()
print(spark.sparkContext.getConf().get("spark.databricks.hive.metastore.glueCatalog.enabled"))
spark.sql("show databases").show()
spark.stop()
Glueカタログへのアクセスをどのように設定するのかは、DatabricksとGlueカタログが同じAWSアカウント、リージョンに存在するか、異なるアカウント、リージョンに存在するのかに依存します。本書の残りでは、適切なステップに従ってください。
- 同じAWSアカウント、リージョン ステップ1、ステップ3-5に従ってください。
- クロスアカウント ステップ1-6に従ってください。
- クロスリージョン ステップ1、ステップ3-6に従ってください。
重要!
AWS Glueデータカタログのポリシーは、メタデータに対するアクセス権のみを定義します。S3のポリシーはコンテンツ自身に対するアクセス権を定義します。これらのステップではAWS Glueデータカタログのポリシーを設定します。これらのステップでは、関連するS3バケットやオブジェクトレベルのポリシーは設定しません。DatabricksにおけるS3のアクセス権の設定に関しては、Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセスをご覧ください。
より詳細に関しては、Restrict access to your AWS Glue Data Catalog with resource-level IAM permissions and resource-based policiesをご覧ください。
ステップ1: Glueデータカタログにアクセスするためのインスタンスプロファイルを作成する
- AWSコンソールからIAMサービスに移動します。
- サイドバーのロールをクリックします。
-
ロールの作成をクリックします。
- 信頼するエンティティのタイプでは、AWSサービスを選択します。
- EC2サービスをクリックします。
- ユースケースではEC2をクリックします。

- 次へ:アクセス権、次へ:レビューをクリックします。
- ロール名フィールドにはロール名を入力します。
- ロールの作成をクリックします。ロール一覧が表示されます。
- ロール一覧で作成したロールをクリックします。
- Glueカタログに対するインラインポリシーを追加します。
- アクセス権タブで
 をクリックします。
をクリックします。 - JSONタブをクリックします。
- 以下のポリシーをタブにペーストします。
- アクセス権タブで
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantCatalogAccessToGlue",
"Effect": "Allow",
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": [
"*"
]
}
]
}
リソース(カタログ、データベース、テーブル、ユーザー定義関数)に対してよりきめ細かい設定を行う場合には、Specifying AWS Glue Resource ARNsをご覧ください。
上のポリシーにある許可アクションのリストで不十分な場合には、エラー情報をDatabricks担当者にお伝えください。最もシンプルなワークアラウンドは、Glueに対するフルアクセスのポリシーを定義するというものです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantFullAccessToGlue",
"Effect": "Allow",
"Action": [
"glue:*"
],
"Resource": "*"
}
]
}
ステップ2: ターゲットGlueカタログに対するポリシーを作成する
Databricksのデプロイメントに使用されているAWSアカウントとGlueカタログが存在するAWSアカウントが異なる場合にのみこのステップを実行してください。
- ターゲットのGlueカタログが存在するAWSアカウントにログインし、Glueコンソールに移動します。
- 設定において、アクセス権のボックスに以下のポリシーに貼り付けます。
<aws-account-id-databricks>、ステップ1の<iam-role-for-glue-access>、<aws-region-target-glue-catalog>、<aws-account-id-target-glue-catalog>それぞれを設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Example permission",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
},
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": "arn:aws:glue:<aws-region-target-glue-catalog>:<aws-account-id-target-glue-catalog>:*"
}
]
}
ステップ3: Databricksのデプロイメントに使用したIAMロールを検索する
このIAMロールは、Databricksアカウントをセットアップした際に使用したものとなります。
以下のステップは、お使いのアカウントがE2バージョンのプラットフォームであるかどうかによって異なります。多くの既存のお客様はE2となっています。お使いのアカウントタイプが不明の場合には、Databricks担当者にお問い合わせください。
E2アカウントの場合
-
アカウントオーナー、あるいはアカウント管理者としてAccount Consoleにログインします。
-
Workspaceに移動し、ワークスペース名をクリックします。
-
CredentialsボックスにあるRole ARNの最後にあるロール名をメモします。
例えば、Role ARNが
arn:aws:iam::123456789123:role/finance-prodである場合、finance-prodがロール名となります。
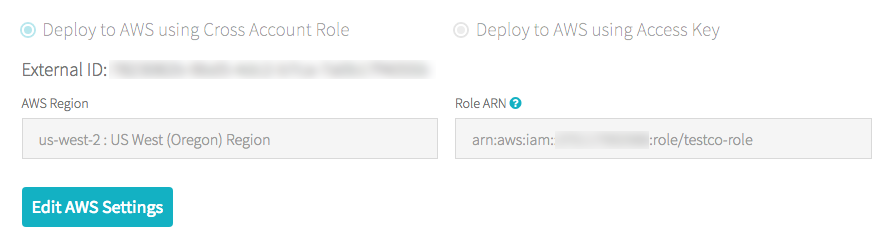
E2アカウントでない場合
- アカウントオーナーとしてAccount Consoleにログインします。
- AWS Accountタブをクリックします。
- Role ARNの末尾のロール名をメモします。以下の場合、testco-roleとなります。
ステップ4: EC2ポリシーにGlueカタログのインスタンスプロファイルを追加する
-
AWSのコンソールでIAMサービスに移動します。
-
サイドバーのロールをクリックします。
-
ステップ3でメモしたロールをクリックします。
-
アクセス権タブでポリシーをクリックします。
-
ポリシーの編集をクリックします。
-
Databricksがステップ1で作成したインスタンスプロファイルを、Sparkクラスターが稼働しているE2インスタンスにパスできるようにポリシーを変更します。以下に、新たなポリシーがどのようなものであるのかのサンプルを示します。
<iam-role-for-glue-access>をステップ1で作成したロールに置き換えてください。JSON{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1403287045000", "Effect": "Allow", "Action": [ "ec2:AssociateDhcpOptions", "ec2:AssociateIamInstanceProfile", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupEgress", "ec2:AuthorizeSecurityGroupIngress", "ec2:CancelSpotInstanceRequests", "ec2:CreateDhcpOptions", "ec2:CreateInternetGateway", "ec2:CreatePlacementGroup", "ec2:CreateRoute", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateVpc", "ec2:CreateVpcPeeringConnection", "ec2:DeleteInternetGateway", "ec2:DeletePlacementGroup", "ec2:DeleteRoute", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DeleteVpc", "ec2:DescribeAvailabilityZones", "ec2:DescribeIamInstanceProfileAssociations", "ec2:DescribeInstanceStatus", "ec2:DescribeInstances", "ec2:DescribePlacementGroups", "ec2:DescribePrefixLists", "ec2:DescribeReservedInstancesOfferings", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSpotInstanceRequests", "ec2:DescribeSpotPriceHistory", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:DescribeVpcs", "ec2:DetachInternetGateway", "ec2:DisassociateIamInstanceProfile", "ec2:ModifyVpcAttribute", "ec2:ReplaceIamInstanceProfileAssociation", "ec2:RequestSpotInstances", "ec2:RevokeSecurityGroupEgress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>" } ] }- E2バージョンのプラットフォームでない場合
JSON{ "Sid": "Stmt1403287045000", "Effect": "Allow", "Action": [ "ec2:AssociateDhcpOptions", "ec2:AssociateIamInstanceProfile", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupEgress", "ec2:AuthorizeSecurityGroupIngress", "ec2:CancelSpotInstanceRequests", "ec2:CreateDhcpOptions", "ec2:CreateInternetGateway", "ec2:CreateKeyPair", "ec2:CreateRoute", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateVpc", "ec2:CreateVpcPeeringConnection", "ec2:DeleteInternetGateway", "ec2:DeleteKeyPair", "ec2:DeleteRoute", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DeleteVpc", "ec2:DescribeAvailabilityZones", "ec2:DescribeIamInstanceProfileAssociations", "ec2:DescribeInstanceStatus", "ec2:DescribeInstances", "ec2:DescribePrefixLists", "ec2:DescribeReservedInstancesOfferings", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSpotInstanceRequests", "ec2:DescribeSpotPriceHistory", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:DescribeVpcs", "ec2:DetachInternetGateway", "ec2:DisassociateIamInstanceProfile", "ec2:ModifyVpcAttribute", "ec2:ReplaceIamInstanceProfileAssociation", "ec2:RequestSpotInstances", "ec2:RevokeSecurityGroupEgress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances" ], "Resource": [ "*" ] } -
ポリシーのレビューをクリックします。
-
変更の保存をクリックします。
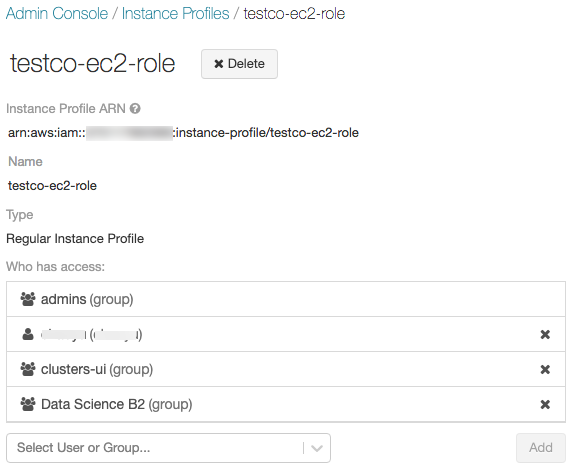
ステップ5: DatabricksワークスペースにGlueカタログのインスタンス流プロファイルを追加する
-
Admin consoleに移動します。
-
Instance Profilesタブをクリックします。
-
Add Instance Profileボタンをクリックします。ダイアログが表示されます。
-
ステップ1のインスタンスプロファイルARNを貼り付けます。

Databricksは、このインスタンスプロファイルARNが文法的、意味的に正しいかどうかを検証します。意味的な正しさを検証するために、Databricksはこのインスタンスプロファイルを用いてクラスターを起動するドライランを実行します。このドライランが失敗するとUI上に検証エラーが表示されます。注意
タグ強制のポリシーが含まれる場合、適切なインスタンスプロファイルの追加であるにもかかわらず、インスタンスプロファイルの検証が失敗する場合があります。検証に失敗したとしても、このインスタンスプロファイルをDatabricksに追加したい場合には、インスタンスプロファイルAPIを使用してskip_validationを指定してください。 -
Addをクリックします。
-
オプションとして、このインスタンスプロファイルを使用してクラスターを起動できるユーザーを指定することができます。
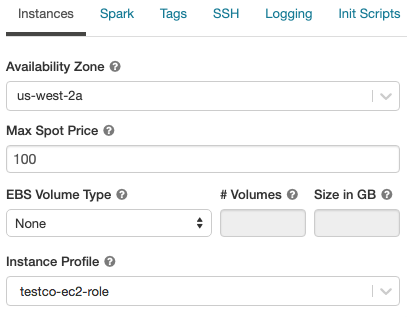
ステップ6: Glueカタログのインスタンスプロファイルを使用してクラスターを起動する
-
クラスターを作成します。
-
クラスター作成ページでInstancesタブをクリックします。
-
Instance Profilesドロップダウンリストから、上のインスタンスプロファイルを選択します。
-
以下のコマンドをノートブックで実行し、Glueカタログにアクセスできることを確認します。
SQLshow databases;コマンドが成功すれば、DatabricksランタイムクラスターはGlueを使うように設定されたことを意味します。
-
DatabricksのデプロイメントとGlueデータカタログのAWSアカウントが異なる場合には、追加のクロスアカウントの設定が必要となります。
AWS設定で
spark.hadoop.hive.metastore.glue.catalogid <aws-account-id-for-glue-catalog>を設定します。 -
ターゲットのGlueカタログのリージョンがDatabricksのデプロイメントと異なる場合には、
spark.hadoop.aws.region <aws-region-for-glue-catalog>も設定します。 -
SparkにはビルトインのHiveサポートがありますが、これを使うかどうかはDatabricksのランタイムバージョンに依存します。
-
アイソレーションモード: ビルトインのHiveサポートは無効化されます。Hive 1.2.1.spark2のライブラリは
/databricks/glue/からロードされます。Databricksランタイム7.3 - 8.3では、アイソレーションモードが有効化されており、無効化することはできません。Databricksランタイム 8.4以降では、アイソレーションモードがデフォルトですが、無効化することができます。 -
ビルトインモード: ビルトインのHiveサポートは有効化されており、HiveのバージョンはSparkのバージョンに依存します。Databricksランタイム 5.5 ESと6.4 ESでは、ビルトインモードは有効化されており、無効化することはできません。Databricksランタイム 8.4以降では、クラスターで
spark.databricks.hive.metastore.glueCatalog.isolation.enabled falseを設定することでビルトインモードを有効にすることができます。
-
アイソレーションモード: ビルトインのHiveサポートは無効化されます。Hive 1.2.1.spark2のライブラリは
-
クレデンシャルパススルーを有効化するには、
spark.databricks.passthrough.enabled trueを設定します。これには、Databricksランタイム 8.4以降、あるいは、Databricksランタイム 5.5か6.4が必要となります。Databricksランタイム 8.4以降では、この設定によって自動でビルトインモードが有効化されます。
制限
- DatabricksのメタストアとしてAWS Glueデータカタログを用いた際、デフォルトのHiveメタストアよりもレーテンシーが高くなる可能性があります。詳細は、トラブルシューティングのセクションのDatabricksのHiveメタストアよりもGlueカタログで高いレーテンシーとなるを参照ください。
- defaultデータベースは
dbfs:(Databricksファイルシステム)スキーマを用いたURIがロケーションに設定されています。このロケーションはAWS EMRやAWS AthenaのようなDatabricks外のAWSアプリケーションからアクセスできません。ワークアラウンドとして、CREATE TABLEを呼び出す際に、バケットの場所を指定するためにLOCATION句を用いてs3://mybucketのようにバケットの位置を指定してください。あるいは、defaultデータベース以外のデータベースにテーブルを作成し、そのデータベースのLOCATIONにS3の場所を指定してください。 - 動的にGlueカタログとHiveメタストアを切り替えることはできません。新たなSpark設定を有効にするには、クラスターを再起動する必要があります。
- クレデンシャルパススルーは、Databricksランタイム8.4以降でのみサポートされています。
- 以下の機能はサポートされていません。
- Databricks Connect
- クロスシステムインタラクション
トラブルシューティング
DatabricksのHiveメタストアよりもGlueカタログで高いレーテンシーとなる
外部メタストアとしてGlueデータカタログを使用した際、デフォルトのDatabricksがホスティングするHiveメタストアよりもレーテンシーが高くなる場合があります。Glueカタログクライアントでクライアントサイドのキャッシングを有効化することをお勧めします。以下のセクションでは、テーブルとデータベースに対してどのようにクライアントサイドのキャッシングを有効化するのかを説明します。クラスターとSQLエンドポイントに対してクライアントサイドのキャッシングを設定することができます。
注意
- クライアントサイドのキャッシュは、テーブル一覧を取得するオペレーション
getTablesでは利用できません。 - Time-to-live (TTL)の設定は、キャッシュの有効性とメタデータの鮮度に対する許容度のトレードオフとなります。特定のシナリオで納得のいくTTLの値を選択してください。
詳細に関しては、AWSドキュメントのEnabling client side caching for Glue Catalogを参照ください。
テーブル
spark.hadoop.aws.glue.cache.table.enable true
spark.hadoop.aws.glue.cache.table.size 1000
spark.hadoop.aws.glue.cache.table.ttl-mins 30
データベース
spark.hadoop.aws.glue.cache.db.enable true
spark.hadoop.aws.glue.cache.db.size 1000
spark.hadoop.aws.glue.cache.db.ttl-mins 30
Databricksランタイムクラスターにインスタンスプロファイルがアタッチされていない
Databricksランタイムクラスターにインスタンスプロファイルがアタッチされていない場合、メタストアの検索を必要とするオペレーションを実行した際に以下の例外がスローされます。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: com.amazonaws.SdkClientException: Unable to load AWS credentials from any provider in the chain: [EnvironmentVariableCredentialsProvider: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY)), SystemPropertiesCredentialsProvider: Unable to load AWS credentials from Java system properties (aws.accessKeyId and aws.secretKey), com.amazonaws.auth.profile.ProfileCredentialsProvider@2245a35d: profile file cannot be null, com.amazonaws.auth.EC2ContainerCredentialsProviderWrapper@52be6b57: The requested metadata is not found at https://169.254.169.254/latest/meta-data/iam/security-credentials/];
必要とするGlueカタログにアクセスするのに十分なアクセス権を持ったインスタンスプロファイルをアタッチしてください。
不十分なGlueカタログアクセス権
メタストアのオペレーションを実行するのに必要な権限が許可されていないインスタンスプロファイルを使用した場合、以下のような例外が発生します。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User: arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
アタッチされているインスタンスプロファイルに十分なアクセス券があることを確認してください。例えば、上の例外ではインスタンスプロファイルにglue:GetDatabaseを追加します。
ファイルに対して直接SQLを実行した際にglue:GetDatabaseアクセス権エラー
Databricksランタイム8.0未満で、以下のようにファイルに対して直接SQLを実行した際、
select * from parquet.`path-to-data`
以下のようなエラーに遭遇する場合があります。
Error in SQL statement: AnalysisException ... is not authorized to perform: glue:GetDatabase on resource: <glue_account>:database/parquet
これは、リソースdatabase/<datasource-format>(<datasource-format>はparquetやdeltaのようなデータソースフォーマット)に対するglue:GetDatabaseを実行する権限がIAMポリシーで許可されていないためです。
database/<datasource-format>におけるglue:GetDatabaseを許可するようにIAMポリシーに権限を追加してください。
Spark SQLのアナライザーの実装において制限があります。SQLに対するファイルの登録データソースに対する解決を試みるようにフォールバックする前に、カタログに対するリレーションを解決するように試みます。最初のカタログに対する解決の試みが例外を発生させなかった場合にのみ、このフォールバックが動作します。
リソースdatabase/<datasource-format>が存在しないケースにおいても、ファイルに対するSQLクエリーのフォールバックが成功するためには、Glueカタログに対するIAMポリシーは、ファイルに対してglue:GetDatabaseを実行できるように許可されている必要があります。
Databricksランタイム8.0以降では、この問題は自動でハンドリングされるので、このワークアラウンドは不要となります。
GlueカタログIDのミスマッチ
デフォルトでは、Databricksクラスターは、Databricksがデプロイされたのと同じAWSアカウントのGlueカタログへの接続を試みます。
ターゲットのGlueカタログがDatabricksデプロイメントと異なるAWSアカウント、異なるリージョンにあり、spark.hadoop.hive.metastore.glue.catalogidが設定されていない場合には、ターゲットカタログではなく、DatabricksがデプロイされているAWSアカウントのGlueカタログに接続します。
spark.hadoop.hive.metastore.glue.catalogidが設定されていても、ステップ2の設定が適切に行われていない場合、メタストアへのアクセスの際には以下のような例外が発生します。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User:
arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
本書のステップ2とステップ6に従って適切に設定されているのかを確認してください。
GlueカタログとAthenaカタログの競合
2017/8/14以前にAmazon AthenaやAmazon Redshift Spectrumを用いてテーブルを作成した場合、データベースとテーブルはAWS Glueデータカタログとは別のAthena管理のカタログに格納されます。これらのテーブルとDatabricksを連記させるためには、AWS Glueデータカタログへのアップグレードを行う必要があります。さもないと、DatabricksランタイムはGlueカタログへの接続に失敗するか、データベースへのアクセス、作成に失敗し、例外メッセージはわかりにくいものとなります。
例えば、GlueカタログではなくAthenaカタログに"default"データベースが存在している場合、以下のようなメッセージが表示されます。
AWSCatalogMetastoreClient: Unable to verify existence of default database:
com.amazonaws.services.glue.model.AccessDeniedException: Please migrate your Catalog to enable access to this database (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>)
Upgrading to the AWS Glue Data Catalog in the Amazon Athena User Guideの手順に従ってください。
空のLOCATIONによるデータベースでのテーブル作成
いろいろなソースからGlueカタログのデータベースは作成されます。Databricksランタイムが作成するデータベースは、デフォルトではLOCATIONフィールドは空ではありません。直接Glueコンソールから作成された、あるいは他のソースからインポートされたデータベースにおいては、LOCATIONフィールドが空のものがあります。
Databricksランタイムが、LOCATIONフィールドが空のデータベースでテーブルを作成しようとした際、以下のようなエラーが発生します。
IllegalArgumentException: Can not create a Path from an empty string
SQLでテーブルを作成する際にLOCATIONを指定するか、DataFrame APIでoption("path", <some_valid_path>)を指定して、LOCATIONフィールドに空でない適切なパスを指定して、Glueカタログにデータベースを作成してください。
AWS Glueコンソールでデータベースを作成する際には、名称のみが必要となります。"Description"と"Location"はオプションと表示されます。しかし、Hiveメタストアのオペレーションは"Location"に依存しますので、Databricksランタイムで使用するデータベースにはLOCATIONを指定するようにしてください。
別システムで作成されたテーブル、ビューへのアクセス
AWS AthenaやPrestoのような別のシステムで作成されたテーブルやビューにアクセスする際、DatabricksランタイムやSparkでは動作しない場合があり、これらのオペレーションはサポートされていません。分かりにくいメッセージを出して処理が失敗する場合があります。例えば、Athenaで作成されたビューにアクセスする際、DatabricksランタイムやSparkha以下のような例外をスローします。
IllegalArgumentException: Can not create a Path from an empty string
この例外は、AthenaやPrestoは、DatabricksランタイムやSparkが期待するのと違うフォーマットでビューのメタデータを格納していることに起因します。