How to Build a Similarity-based Image Recommendation System for e-Commerce - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
なぜレコメンデーションシステムが重要なのか
平均的な消費者にとってオンラインショッピングはデフォルトの体験となっており、有名なブリックアンドモルタルの小売業者ですらeコマースを取り入れています。ユーザー体験を円滑なものにするには、eコマースにおいては複数の要素を検討する必要があります。ユーザー体験を改善し、結果的にオンライン業者の収益を改善すると立証されている機能の一つに、製品のレコメンデーションシステムがあります。今となっては、製品レコメンデーションがないウェブサイトに到達することがほぼ困難となっています。
しかし、全てのレコメンデーションエンジンが等しく作られているわけでも、等しく作られなくてはいけないわけでもありません。異なるショッピング体験は、レコメンデーションを行うために異なるデータを必要とします。購買者に対してパーソナライズされた体験を提供するためには、データに対する異なる感覚とレコメンデーションの方法を必要とします。多くのレコメンデーションエンジンでは、表形式に整形されたユーザー、製品属性データに対して機械学習モデルをトレーニングします。
このプロセスにおいて利用できる計算資源、アルゴリズムの多大なる発展、レコメンデーションエンジンを構築するのに活用できるデータの量、種類の増加は指数関数的なものとなっています。特に、過去数年間において画像データを格納、処理、学習する手段は劇的に増加しました。これにより、小売業者はシンプルな協調フィルタリングアルゴリズムの先にある、画像分類やディープ・コンボルーショナル・ニューラルネットワークのようなより複雑な方法を活用できるようになり、商品の見た目の類似性を考慮し、レコメンデーションの入力として活用できるようになりました。オンランショッピングは視覚的な体験に大きく依存し、多くの消費者は商品の見た目で購入を決断するので、特にこのことが重要となってきます。
本書では、レコメンデーションシステムの基礎となる画像ベースの類似性モデルのトレーニング、デプロイのエンドツーエンドのプロセスを説明します。さらに、Databricksで活用できる分散計算機能を用いて、どのようにトレーニングプロセスをスケールできるのか、Delta LakeやMLflowのような基本コンポーネントがこのプロセスをシンプルかつ再現可能にするのかを説明します。
なぜ類似学習なのか?
類似性モデルは対照学習(contrastive learning)を用いてトレーニングされます。対照学習では、類似するアイテム間の距離が最小となり、似ていないアイテム間の距離が最大となるような埋め込み空間を機械学習(ML)モデルが学習することがゴールとなります。ここでは、さまざまな衣料品の約70,000点の画像から構成されるファッションMNISTデータセットを使用します。上の説明に基づいて、このラベル付データセットでトレーニングされる類似性モデルは、類似する商品(例えば、ブーツ同士)は集まり、異なる商品(例、プルオーバー)とは互いに離れ合う埋め込み空間を学習します。教師あり対照学習では、アルゴリズムは学習に用いる画像ラベルのようなメタデータと、生の画像データにアクセスすることができます。
これは以下のように図示できます。
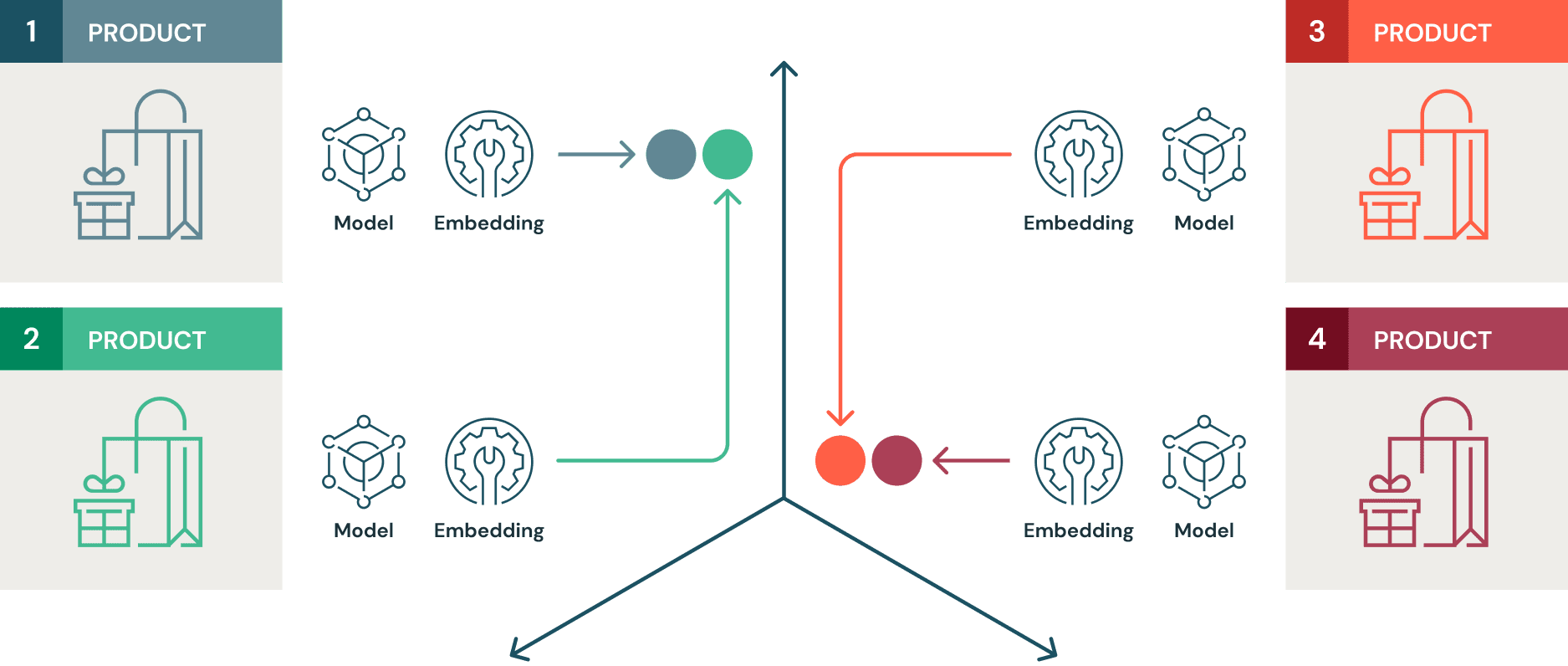
従来型の画像分類MLモデルは、予測するクラスの確率を最大化する損失関数を最小化することにフォーカスしています。しかし、レコメンデーションエンジンは基本的には、特定アイテムの代替案を提示しようとします。これらのアイテムは特定の埋め込み空間において他のものよりも近しいものと説明することができます。すなわち、多くの場合、レコメンデーションエンジンの動作原理は、従来の教師あり学習よりも、対照学習のメカニズムにより近しいものといえます。さらに、類似性モデルは、それらの類似性に基づいて未知のデータに対して一般化することに長けています。例えば、オリジナルのトレーニングデータにジャケットの画像が含まれておらず、パーカーやブーツの画像が含まれていたとしても、このデータセットでトレーニングした類似性モデルは、パーカーに近くブーツから遠いジャケットの画像の埋め込みを特定することでしょう。これは、レコメンデーション手段の世界においては非常に強力なものとなります。
特にここでは、GPUクラスターでのモデルトレーニングをスケールさせるために、Horovodと組み合わせたApache Sparkと、モデルをトレーニングするためにTensorflow Similarity libraryを使用します。数行を記述するだけで、SparkとGPUクラスターを用いてハイパーパラメーター探索をスケールさせるためにHyperoptを使用します。これら全ての実験はMLflowでトラッキング、記録され、モデルのリネージュと再現性を担保します。データリネージュをトラッキングするためにデータソースとしてDeltaを使用します。
環境のセットアップ
Tensorflow SimilarityのGithubリポジトリにあるsupervised_hello_world exampleは、このタスクを簡単に行うための完璧なテンプレートを提供してくれます。レコメンデーションエンジンで我々がやろうとしていることは、類似性モデルの振る舞いと似たものとなります。すなわち、アイテムの画像を選択して、あなたの興味を惹きそうな類似性の高いn個のアイテムを取得するために、モデルに問い合わせを行います。
Databricksのプラットフォームを完全に活用するためには、GPUドライバーノード(最初にシングルノードのトレーニングを行うためです)、2つ以上のGPUワーカーノード(ハイパーパラメーターをスケールさせ、トレーニング自身を分散するためです)、そして、Databricks機械学習ランタイム10.0以降を使うのがベストです。このエクササイズではT4 GPUインスタンスが良い選択肢となります。

(クラスターの起動時間を含み)このプロセスには5分もかかりません。
Deltaテーブルへのデータの取り込み
ファッションMNISTのトレーニングデータ、テストデータは、シンプルなシェルコマンドと、画像とラベルファイルを表形式に変換するのに使用するヘルパー関数convert(https://pjreddie.com/projects/mnist-in-csv/ にあるオリジナルバージョンからの修正あり)を用いてお使いの環境にインポートすることができます。続いて、これらのテーブルをDeltaテーブルとして格納することができます。
新たな観測結果(新規の画像とラベル)を追加していくことになるので、トレーニングデータ、テストデータをDeltaテーブルに格納することは重要となります。Deltaのトランザクションログはデータの変更を追跡します。これによって、後ほど説明する類似性インデックスで、データの再インデクシングを行う際に使用する新鮮なデータを追跡することが可能となります。
類似性モデルのトレーニングにおけるニュアンス
類似性モデルをトレーニングするのに使用するニューラルネットワークは、通常の教師あり学習で使用するものと非常に類似しています。ここでの大きな違いは、使用する損失関数とメトリック埋め込みレイヤーにあります。ここでは、コンピュータービジョンアプリケーションで広く使われている、シンプルなコンボリューショナルニューラルネットワーク(cnn)アーキテクチャを使用します。しかし、対照メソッドを用いて学習を行うためにモデルを有効化するコードにちょっとした違いがあります。
マルチクラス分類で見たことがあるかもしれないsoftmax損失関数の代わりに、複数の類似性損失関数を見ることになります。対照学習で用いられる他の従来型の損失関数と比べて、Multi-Similarity Lossは複数の類似性を考慮します。これらの類似性には、自己類似性、正の相対類似性、負の相対類似性があります。Multi-similarity Lossは、イテレーティブなハードペアマイニング、重み付けの手段によって、これら3つの類似性を計測し、劇的なパフォーマンスゲインを対照学習タスクにもたらします。この特定の損失関数に関してはWangらによるオリジナルの論文をご覧ください。
このサンプルの文脈においては、この損失関数は埋め込み空間において、似ているアイテム間の距離を最小化し、似ていないアイテム間の距離を最大化するのに役立ちます。Tensorflow_Similarityリポジトリのsupervised_hello_worldサンプルで説明されているように、MetricEmbedding()を用いてモデルに追加されている埋め込みレイヤーはL2正規化を伴うdenseレイヤーです。それぞれのミニバッチでは、ランダムにサンプリングされたクラス(クラスの数はハイパーパラメーターとなります)から固定数のエンべディング(画像数に対応します)がランダムに選択されます。これらは、近接性が高いが似ていないサンプルにペナルティを課すために3つの異なるタイプの類似性の情報が使われる、Multi-Similarity Lossレイヤーでハードペアマイニングと重み付けの対象となります。
これは以下のようになります。
def get_model():
from tensorflow_similarity.layers import MetricEmbedding
from tensorflow.keras import layers
from tensorflow_similarity.models import SimilarityModel
inputs = layers.Input(shape=(28, 28, 1))
x = layers.experimental.preprocessing.Rescaling(1/255)(inputs)
x = layers.Conv2D(32, 3, activation='relu')(x)
x = layers.MaxPool2D(2, 2)(x)
x = layers.Dropout(0.3)(x)
…
…
x = layers.Dropout(0.3)(x)
x = layers.Flatten()(x)
outputs = MetricEmbedding(128)(x)
return SimilarityModel(inputs, outputs)
…
…
loss = MultiSimilarityLoss(distance=distance)
model.compile(optimizer=Adam(learning_rate), loss=loss)
TensorFlow Similarityでトレーニングされた類似性モデルがどのように機能するのかを理解することが重要です。モデルのトレーニングの過程で、類似するアイテム間の距離を最小化するエンベディングを学習しました。ライブラリのIndexerクラスは、選択された距離メトリックに基づいてこれらのエンベディングからインデックスを構築する機能を提供します。例えば、選択された距離メトリックがcosineであれば、コサイン類似性に基づいてインデックスが構築されます。
インデックスは近いエンべディングを持つアイテムをクイックに検索するために存在しています。この検索を高速にするためには、最も類似したアイテムを比較的低いレーテンシーで取得できるようにする必要があります。特定アイテムに近いn個のアイテムを取得し、レコメンデーションに使えるようにするために、ここで使うクエリーでは、Approximate Nearest Neighbor Searchを使用しています。
#Build an index using training data
x_index, y_index = select_examples(x_train, y_train, CLASSES, 20)
tfsim_model.reset_index()
tfsim_model.index(x_index, y_index, data=x_index)
#Query the index using the lookup method
tfsim_model.lookup(x_display, k=5)
.
.
.
Apache Sparkによる並列性の活用
シングルノードでも問題なくモデルをトレーニングし、クエリーが行えるようにインデックスを作成することはできます。MLflowの助けを借りてRESTエンドポイント経由でクエリーできるように、トレーニングモデルをデプロイすることもできます。使用されるファッションMNISTのデータセットは小規模であり、単体のGPUインスタンスのメモリーに容易に収まるので、これは理にかなったことです。しかし、実際には、製品の画像データセットのサイズは数Gバイトにもなり得ます。また、小規模データセットでトレーニングしたモデルにおいても、単体のGPUインスタンスでモデルの最適なハイパーパラメーターの検索を行うと非常に時間がかかるプロセスになる場合があります。両方のケースにおいて、数行のコードを変更するだけで、Sparkによって実現される並列性が魔法のように動作します。
Apache Sparkによるハイパーパラメーター最適化の並列化
ニューラルネットワークのケースでは、人口のニューロンの重みをトレーニングの過程で更新されるパラメーターと考えることができます。これは、最急降下法と誤差逆伝播法で行われます。しかし、レイヤーの数、レイヤーごとのニューロン数、ニューロンにおけるアクティベート関数はこのプロセスでは最適化されません。これらはハイパーパラメーターと呼ばれ、モデリングのプロセスを進めるためには、可能なハイパーパラメーターの組み合わせ全てから、賢い方法で検索を行わなくてはなりません。
従来のモデルのチューニング(ハイパーパラメーター検索)は、徹底的なグリッドサーチやランダムサーチのような素朴なおアプローチで行うことが可能です。モデルチューニングで広く活用されているオープンソースフレームワークであるHyperoptは、このプロセスにより効率的なベイジアンサーチを活用します。
この検索は、ベイジアンサーチのような賢いアルゴリズムを用いたとしても、時間がかかる場合があります。しかし、SparkとHyperoptを組み合わせて、このプロセスをクラスター全体で並列化することで、処理時間を劇的に削減することができます。このスケーリングをこなうために必要なことは、通常Hyperoptで使用しているpythonコードに2行を追加するだけです。並列度の引数は2(クラスターのGPUの数)に設定することに注意してください。
.
.
from hyperopt import SparkTrials
.
.
trials = SparkTrials(parallelism = 2)
.
.
best_params = fmin(
fn=train_hyperopt,
space=space,
algo=algo,
max_evals=32,
trials = trials
)
.
.
この並列処理のメカニズムは以下のように図示されます。
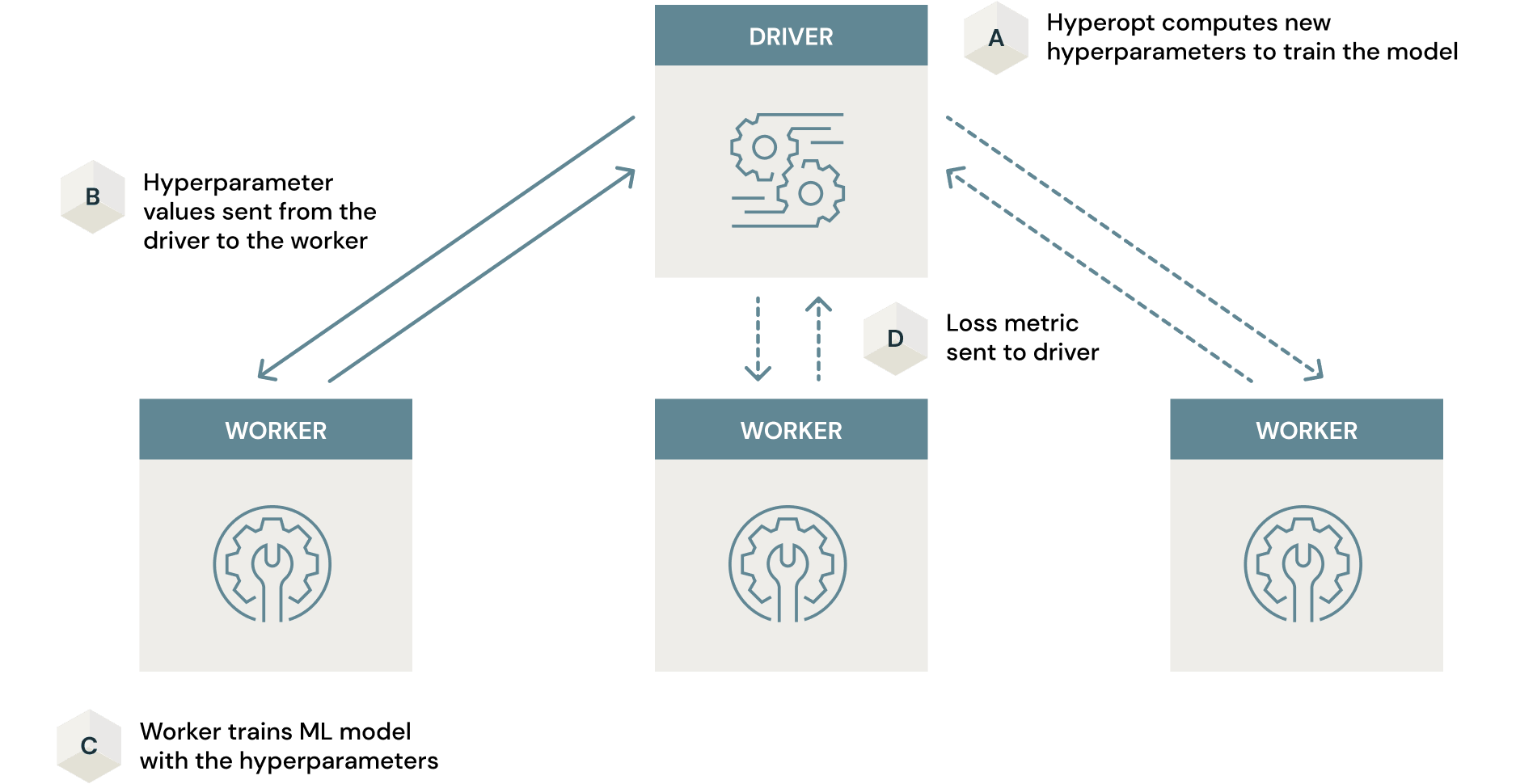
Scaling Hyperopt to Tune Machine Learning Models in Pythonでは、これがどのように動作するのかに関して素晴らしいディープダイブが行われています。この類似性モデルのケースでは、特にTensorflowを活用しているので、このプロセスにGPUノードを使用することが重要となります。いかなる時間削減も、CPUノードを使った不要かつ非効率的なトレーニングプロセスで帳消しになってしまいます。この分析の詳細はこちらの記事で説明されています。
Horovodによるモデルトレーニングの並列化
以前のセクションで見た通り、Hyperoptは並列で異なるハイパーパラメーターの組み合わせで複数のモデルをトレーニングすることでハイパーパラメーター検索を分散するためにSparkを活用します。それぞれのモデルのトレーニングは単体のマシンで行われます。分散モデルトレーニングは、トレーニングプロセスをより効率的にするために、Sparkが処理できる分散プロセスの別の活用方法となります。ここでは、単体のモデルがクラスターの複数のマシンでトレーニングされます。
トレーニングデータセットが大規模の場合、プロダクションとして使える類似性モデルをトレーニングする際の別のボトルネックになる場合があります。これに対するアプローチには、シングルマシンでデータのサブセットでトレーニングするというものが考えられます。これは、最適ではない最終モデルという結果になってしまいます。しかし、Sparkと、クラスターでモデルトレーニングプロセスを並列化するためのオープンソースフレームワークであるHorovodを組み合わせることで、この問題を解決することができます。HorovodとSparkを組み合わせることで、最小限のコード変更で大規模データセットに対するモデルトレーニングに対して、データ並列化のアプローチを提供します。ここでは、ニューラルネットワークの重みを学習するために、データのサブセットの定義が渡されると、それぞれのノードで並列でモデルがトレーニングされます。これらの重みはクラスター間で同期され、最終モデルを作り出します。最終的インは、シングルマシンで行うよりも少ない時間で、データセット全体に対してトレーニングした高度に最適化されたモデルを手に入れることができます。ディープラーニングを容易にスケールさせる(させない)6つのステップではディープラーニングにおいて、どのように分散計算機能を活用するのかの詳細が述べられています。繰り返しになりますが、HorovodはGPUクラスターを使った時が最も効果的です。さもないと、クラスターでモデルトレーニングをスケールさせる試みは期待通りの効率をもたらしません。
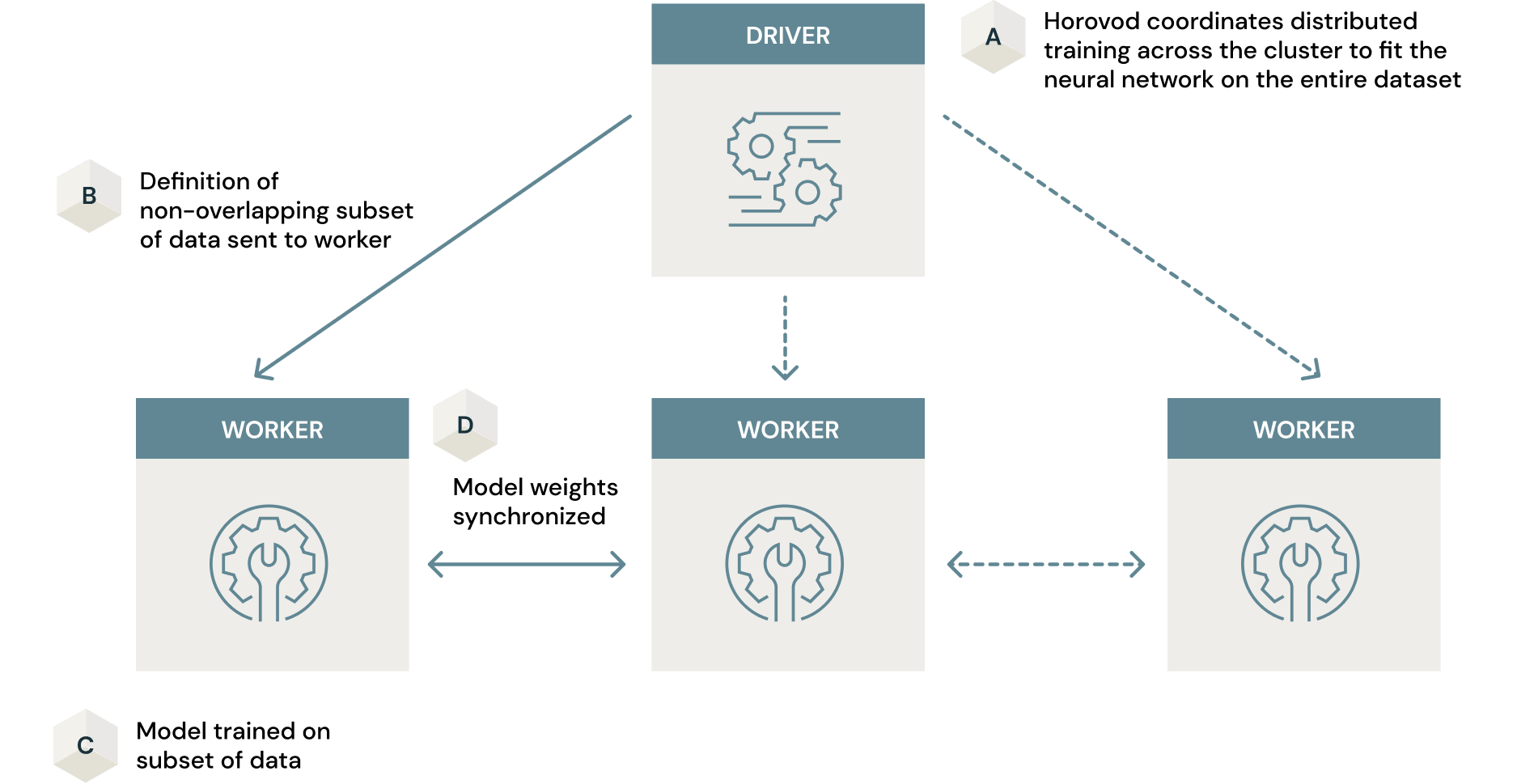
モデルトレーニングにおける大規模画像データセットの取り扱いは、検討すべき別の重要な要素となります。この例では、ファッションMNISTは非常に小さなデータセットであり、クラスターに全く負荷をかけません。しかし、大規模な画像データセットは企業内で度々見られるものであり、このようなデータに対する類似性モデルのトレーニングを必要とするユースケースが存在するかもしれません。このような場合、ディープラーニングを前提としたデータキャッシングライブラリであるPetastormが役立ちます。こちらでリンクされているノートブックは皆様のユースケースでこのテクノロジーを活用する助けになることでしょう。
モデルとインデックスのデプロイ
最終モデルが最適なハイパーパラメーターでトレーニングされたならば、類似性モデルのデプロイプロセスに注意しなくてはなりません。これは、モデルとインデックスは一緒にデプロイされる必要があるためです。しかし、MLflowを用いることでこのプロセスは驚くほどシンプルになります。以前述べたように、クエリーサンプルから推定されるエンベディングを用いてデータのインデックスをクエリーすることでレコメンデーションが取得されます。これは以下のようにシンプルに図示することができます。
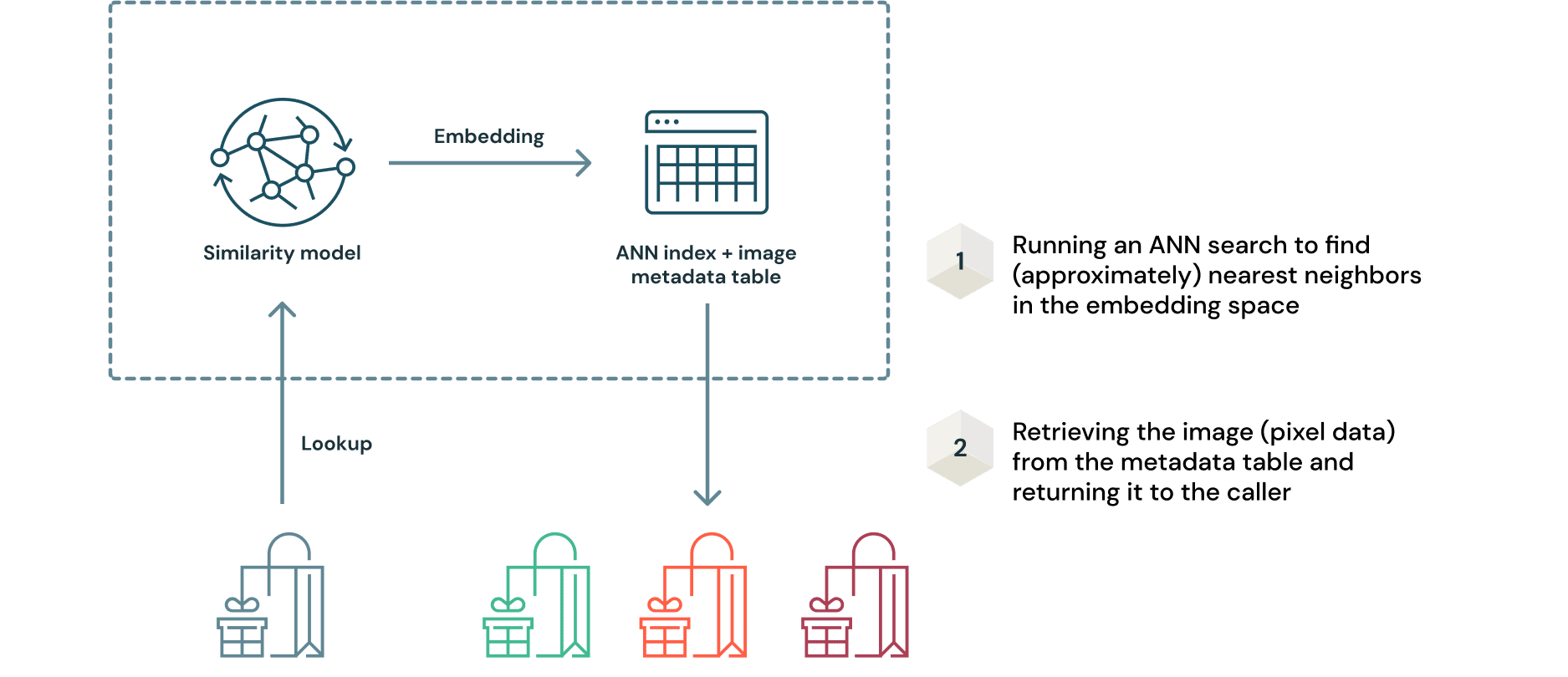
このアプローチのキーとなるメリットは、新規画像データを受信したとしてもモデルを再トレーニングする必要がないということです。エンべディングはモデルから生成され、クエリーのためにANNインデックスに追加されます。オリジナルの画像データはDeltaフォーマットなので、テーブルに対する像分はDeltaのトランザクションログに記録されます。これによって、データ取り込みプロセス全体の再現性を確保することができます。
MLflowでは、モデルサービングのためのモデルパッケージングを容易にするために、著名な(そうでないものも)MLフレームワークに対する数多くのフレーバーを提供しています。実際には、クエリー可能な類似性モデルとANNインデックスの例ように、トレーニングしたモデルと前処理、後処理のロジックを一緒にデプロイする必要が出てきます。ここで、我々はカスタムのrecommender modelクラス(ここではTfsimWrapperと名付けています)を作成し、推論と検索ロジックをカプセル化するためにmlflow.pyfuncモジュールを使用することができます。こちらのリンク先ではどのように行うのかが詳細に説明されています。
import mlflow.pyfunc
class TfsimWrapper(mlflow.pyfunc.PythonModel):
""" model input is a single row, single column pandas dataframe with base64 encoded byte string i.e. of the type bytes. Column name is 'input' in this case"""
""" model output is a pandas dataframe where each row(i.e.element since only one column) is a string converted to hexadecimal that has to be converted back to bytes and then a numpy array using np.frombuffer(...) and reshaped to (28, 28) and then visualized (if needed)"""
def load_context(self, context):
import tensorflow_similarity as tfsim
from tensorflow_similarity.models import SimilarityModel
from tensorflow.keras import models
import pandas as pd
import numpy as np
self.tfsim_model = models.load_model(context.artifacts["tfsim_model"])
self.tfsim_model.load_index(context.artifacts["tfsim_model"])
def predict(self, context, model_input):
from PIL import Image
import base64
import io
image = np.array(Image.open(io.BytesIO(base64.b64decode(model_input["input"][0].encode()))))
#The model_input has to be of the form (1, 28, 28)
image_reshaped = image.reshape(-1, 28, 28)/255.0
images = np.array(self.tfsim_model.lookup(image_reshaped, k=5))
image_dict = {}
for i in range(5):
image_dict[i] = images[0][i].data.tostring().hex()
return pd.DataFrame.from_dict(image_dict, orient='index')
同じMLflowのUIの中で、あるいはMLflow APIを用いて、モデルのアーティファクトを記録し、登録を行い、RESTエンドポイントにデプロイすることもができます。この機能に加え、デプロイメントの迅速な引き継ぎを支援するために、記録の際にモデルのシグネチャとして入出力を定義することも可能です。これは以下の3行のコードで自動で行われます。
from mlflow.models.signature import infer_signature
signature = infer_signature(sample_image, loaded_model.predict(sample_image))
mlflow.pyfunc.log_model(artifact_path=mlflow_pyfunc_model_path, python_model=TfsimWrapper(), artifacts=artifacts,
conda_env=conda_env, signature = signature)
シグネチャが推定されると、期待されるデータの入出力の形式が、以下にようにUIに表示されます。

RESTエンドポイントを作成した後は、ワークスペースの画面の左のサイドメニューからUser settingsにアクセスし、パーソナルアクセストークンを作成します。このトークンを用いて、RESTエンドポイント向けに自動で生成されたPythonラッパーコードを、任意のユーザー向けアプリケーションや、モデル推論を行う内部プロセスに埋め込むことができます。
以下の関数は、REST呼び出しのJSONレスポンスをデコードするのに役立ちます。
import numpy as np
def process_response_image(i):
"""response is the returned JSON object. We can loop through this object and return the reshaped numpy array for each recommended image which can then be rendered"""
single_image_string = response[i]["0"]
image_array = np.frombuffer(bytes.fromhex(single_image_string), dtype=np.float32)
image_reshaped = np.reshape(image_array, (28,28))
return image_reshaped
このブログ記事向けのリポジトリには、このエンドポイントにクエリーを実行するために構築された、シンプルなStreamlitアプリケーションのコードが格納されています。
Databricksでご自身の環境を構築してみる
通常、レコメンデーションのためのデータの取り込み、整形、大規模なモデルの最適化、トレーニング、類似モデルのデプロイのプロセスは、多くの人にとって馴染みのない、かつ、難しいものとなっています。Databricksが提供する高度に最適化されたマネージドのSpark、Delta Lake、MLflowの基盤を用いることで、このプロセスはレイクハスプラットフォーム上でシンプルかつ、わかりやすいものになります。管理された計算クラスターにアクセスでき、複数GPUのプロビジョニングのプロセスはシームレスなので、全てのプロセスはほんの数分しかかかりません。以下でリンクされているノートブックでは、類似性モデルの構築、デプロイを詳細にウォークスルーしています。是非Databricksでトライしていただき、皆様の要件に合うようにカスタマイズし、ご自身でプロダクションレベルのMLベースの画像レコメンデーションエンジンを構築いただけたらと思います。
日本語訳