Enabling Computer Vision Applications With the Data Lakehouse
- The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
ブログ記事、Tackle Unseen Quality, Operations and Safety Challenges with Lakehouse enabled Computer Visionで述べたように、小売、製造のオペレーションを変革するためのコンピュータービジョンアプリケーションのポテンシャルは誇張ということはありません。すなわち、企業がこのポテンシャルを実現することを数多くの技術的課題が妨げているのです。コンピュータービジョンアプリケーションの開発、実装に関する技術的パートのシリーズにおける最初の導入編では、これらの課題を深掘りし、データ取り込み、モデルトレーニング、モデルデプロイメントにおける基本的なパターンを探索します。
画像データ固有の特徴のため、我々はこれらの情報アセットをどのように取り扱うのかを注意深く検討する必要があり、トレーニングしたモデルとフロントエンドのアプリケーションとのインテグレーションは、従来とは異なるデプロイメント経路を検討する必要があります。あらゆるコンピュータービジョンの課題を全て解決するソリューションは存在しませんが、実世界のビジネス問題を解決するためにコンピュータービジョンシステムの活用を推進した企業によって開発された数多くのテクニック、技術が存在しています。これらを活用することで、この記事で説明するように、デモ段階から本格運用に迅速に移行することが可能となります。
データの取り込み
(設計、計画の後の)多くのコンピュータービジョンアプリケーション開発の第一歩は画像データの集積です。カメラを搭載したデバイスによって画像ファイルが取得され、モデルのトレーニングを行う中央のストレージリポジトリに送信されます。
PNGやJPEGのような多くの著名なフォーマットはメタデータの埋め込みをサポートしていることの注意すべきです。画像の高さ、幅のような基本的なメタデータは画素値を2次元表現への変換をサポートします。Exchange Information File Format (Exif)のような追加のメタデータは、カメラに関する詳細情報、設定、場合によっては位置情報(デバイスにGPSセンサーが搭載されている場合)を提供します。
画像ライブラリを構築する際、コンピュータービジョンアプリケーションに蓄積された数百万の画像をデータサイエンティストが検索を行う際に有用な画像の統計情報、メタデータは、レイクハウスのストレージに画像が到着した際に処理されます。Pillowのような一般的なオープンソースライブラリを活用することで、メタデータ、統計情報の両方が抽出され、容易に検索できるようにレイクハウス環境のテーブルに永続化されます。画像を構成するバイナリーデータもまた、これらのテーブルにオリジナルファイルへのパス情報と共に永続化することも可能です。
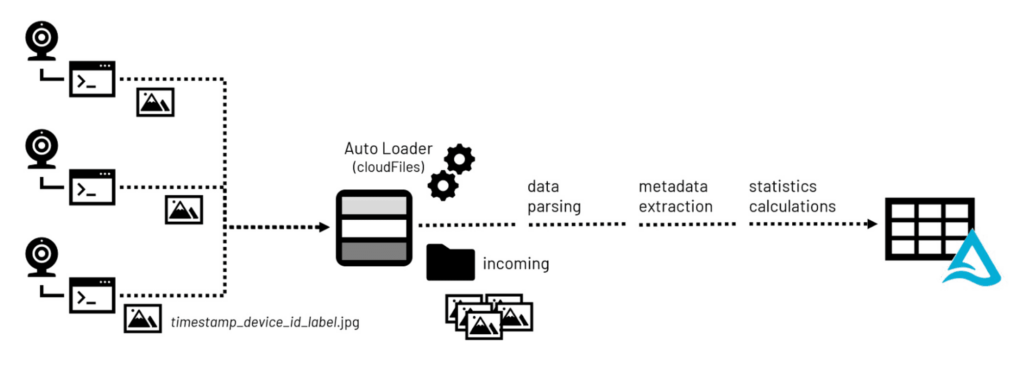
図1 投入される画像データに対するデータ処理ワークフロー
モデルのトレーニング
堅牢なモデルをトレーニングするために必要となる、他の大量の画像ファイルと組み合わされる個々の画像ファイルのサイズは、モデルのトレーニングにおいてそれらのファイルをどのように取り扱うのかについて注意深く検討する必要があることを意味します。モデルへの入力をpandasデータフレームにまとめるようなデータサイエンスの取り組みで一般的に使われるテクニックは、エンタープライズ規模においては、個々のコンピューターのメモリーの制限のため、多くの場合うまく動きません。コンピューティングクラスターとして設定された複数のコンピューターノードにデータボリュームを分散するSpark™データフレームは、多くのコンピュータービジョンライブラリではアクセスできないので、この問題に対する別のソリューションが必要となります。このモデルトレーニングの最初の問題を解決するために、先進的ディープラーニングモデルタイプの大規模トレーニングに特化したキャッシングテクノロジーであるPetastormを活用することができます。Petastormを用いることで、レイクハウスから大規模データを取得し、一時的なストレージベースのキャッシュに保存することができます。ディープニューラルネットワーク開発で最も人気があり、一般的にコンピュータービジョンアプリケーションで用いられている2つのライブラリであるTensorflowとPyTorchは、より大規模なPetastormデータセットに対してイテレーションを行うことで、キャッシュからバッチで小規模なデータのサブセットを読み込むことができます。
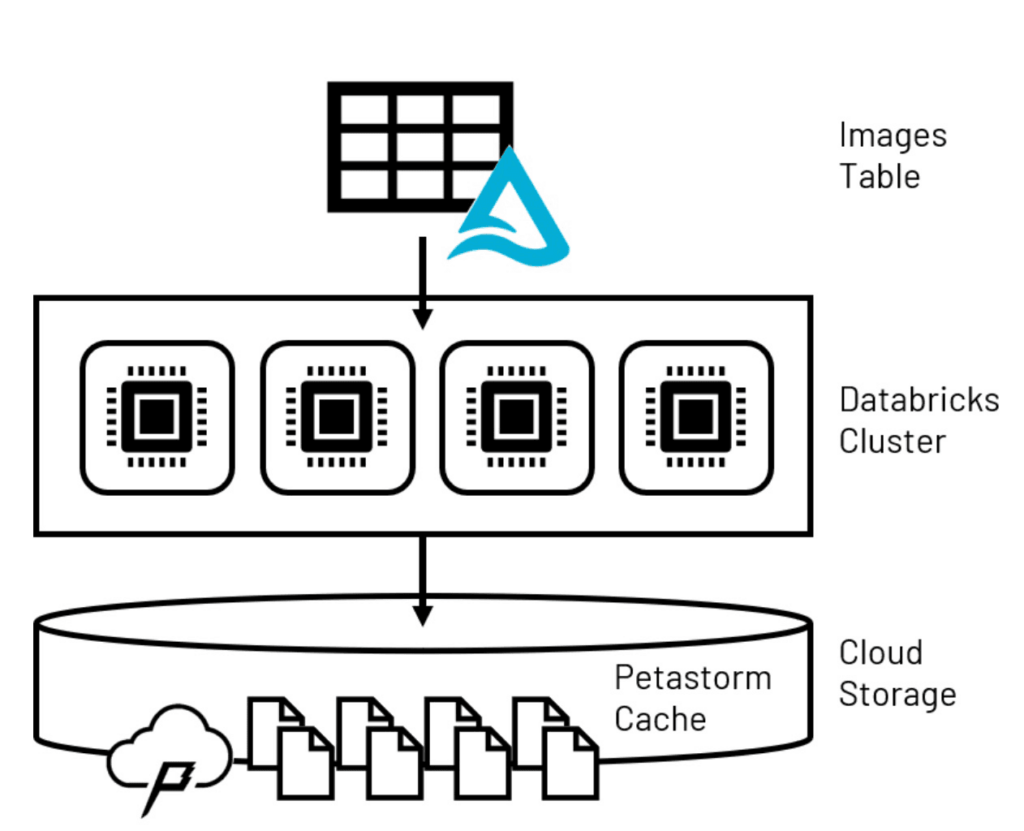
図2 一時的なPetastormキャッシュに永続化されたレイクハウスデータ
取り扱えるボリュームのデータを得た後の次の課題は、モデルトレーニング自身の高速化です。機械学習モデルはイテレーションを通じて学習を行います。これは、トレーニングが入力データセットに対する一連の繰り返されるパスから構成されることを意味します。それぞれのパスにおいて、モデルはより優れた予測精度をもたらす様々な特徴量に対する最適な重みを学習します。
モデルの学習アルゴリズムは、ハイパーパラメーターと呼ばれるパラメーターセットによって制御されます。多くの場合、これらのハイパーパラメーターの値をドメイン知識のみで設定することは困難であるため、最適な性能を示す最適なハイパーパラメーターを発見するために、複数のモデルをトレーニングすることが典型的なパターンとなります。このプロセスはハイパーパラメーターチューニングと呼ばれ、イテレーションに対するイテレーションとなります。
膨大な数のイテレーションを現実的な時間内に終わらせるためのテクニックは、並列に処理が実行されるように、クラスターのコンピュートノードに対してハイパーパラメーターチューニングを分散するというものです。Hyperoptを活用することで、これらの処理はウェーブとして実行され、ウェーブの間にHypteroptソフトウェアがどのハイパーパラメーターの値がどの成果に結びついたのかを評価し、次のウェーブにおけるハイパーパラメーターの値をインテリジェントに設定します。ウェーブを繰り返すことで、ソフトウェアは網羅的な評価を実行するよりもはるかに高速に最適なハイパーパラメーターセットに収束することができます。
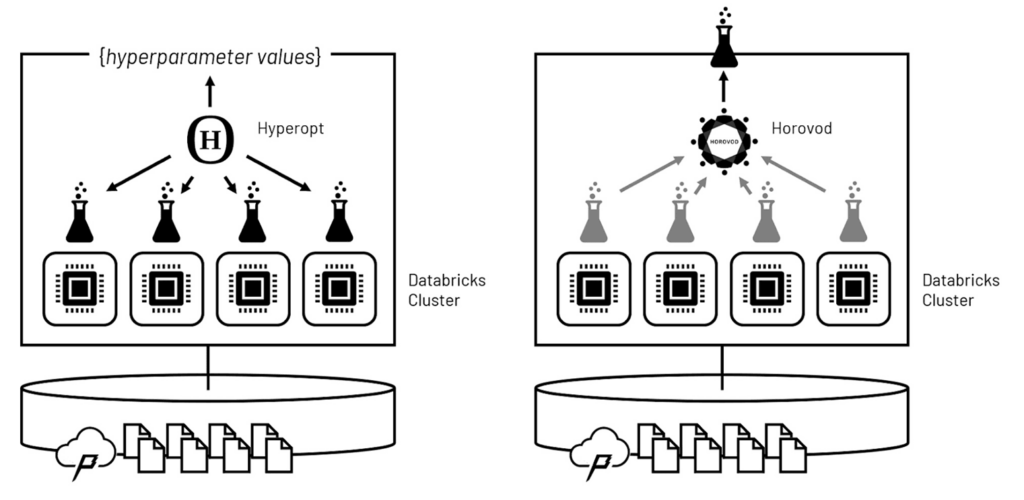
図3 ハイパーパラメーターチューニングとモデルトレーニングそれぞれを分散するためにHyperoptとHorovodを活用
最適なハイパーパラメーターの値が決定されたら、Horovodを用いて、クラスターにおいて最終モデルのトレーニングを分散処理します。Horovodは、重複しない入力トレーニングデータのサブセットを用いて、それぞれのクラスターのコンピュートノードでモデルを独立にトレーニングするように調整を行います。これらの並列の処理によって学習された重みは、完全な入力セットに対するパスで統合され、全体的な学習に基づいてモデルがリバランスされます。最終的な結果として、全体的なクラスターの計算能力を用いてトレーニングされた最適なモデルが得られます。
モデルのデプロイメント
コンピュータービジョンのモデルを獲得した後は、多くの場合、人間のオペレーターが確認できる場所にモデルの予測をもたらすことがゴールとなります。いくつかのシナリオにおいては、バックオフィスで集中管理された画像のスコアリングが適切ですが、より多くの場合では、ローカル(エッジ)デバイスが、リアルタイムでスコアリングを行うために画像の取得とトレーニング済みモデルの呼び出しを行います。モデルの複雑性、ローカルデバイスのキャパシティとレーテンシー、ネットワーク遅延の許容度に基づき、多くの場合、エッジのデプロイメントは2つの形態を取ります。
マイクロサービスのデプロイメントにおいては、モデルはネットワークからアクセス可能なサービスとして提供されます。このサービスは集中管理された場所、あるいは、いくつかのエッジデバイスに近い場所になるように複数の場所でホスティングされます。デバイスで稼働するアプリケーションは、必要なスコアを受け取るために画像をサービスに送信します。このアプローチには、モデルのホスティングに大きな自由度があることと、通常エッジデバイスで利用できるよりもはるかに多くのリソースにアクセスできるメリットがあります。一方で、追加のインフラストラクチャが必要になり、ネットワークの遅延、アプリケーションに影響を及ぼす障害のリスクといったデメリットも存在します。
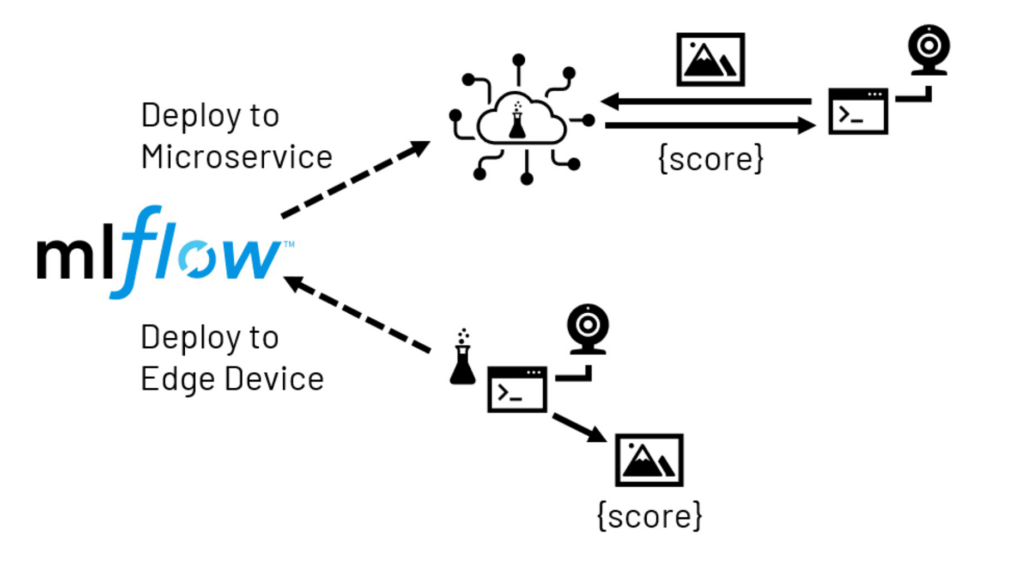
図4 MLflowを活用したエッジデプロイメントのパス
エッジデプロイメントにおいては、先ほどトレーニングしたモデルが直接ローカルデバイスに送信されます。これにより、モデルがデリバリーされた後はネットワークに関する心配事から解放されますが、デバイスの限定的なハードウェアリソースが制約となります。さらに、多くのエッジデバイスは、モデルがトレーニングされたのとは大きく異なるプロセッサーを使用しています。これによって、ソフトウェアの複雑性に関わる課題を引き起こすので、このデプロイメントにリソースをコミットする場合には十分に検討を行う必要があります。
Databricksで全てを統合する
これら異なる課題をどのように解決するのかをデモするために、PiCameraを搭載したRaspberry Piデバイスから取得したデータを活用する一連のノートブックを開発しました。上で説明したすべての機能が設定ずみであるDatabricks機械学習ランタイムを用いて、これらの画像の取り込み、モデルトレーニング、デプロイメントをデモできるように、このデバイスで撮影された画像はクラウドストレージ環境に送信されます。デモの詳細を知りたい場合には、以下のノートブックを参照してください。