How (Not) To Scale Deep Learning in 6 Easy Steps - The Databricks Blogの翻訳です。
あなたのディープラーニング、トレーニング時間がかかりすぎていませんか?いいニュースがあります!
こちらからサンプルノートブックをダウンロードできます。
イントロダクション:問題
ときにディープラーニングは魔法使いのように見えます。最先端のアプリケーションをは素晴らしいと感じる時もあればうんざりする時もあります。これらの結果をもたらすツールは素晴らしいことにほとんどがオープンソースであり、クラウドで時間単位で利用できるハードウェアを活用して魔法のように使うことができます。
企業がディープラーニングをビジネス上の問題、解約予測、イメージキュレーション、チャットボット、時系列分析などに適用したいと考えても不思議ではありません。ツールが利用であると言っても、簡単に使えるとは限りません。適切なアーキテクチャを選択したとしても、レイヤーとアクティベーションは技術というより芸術の領域にあるものです。
この記事では、精度を高めるためにどのようにディープラーニングのアーキテクチャをチューンすべきかは検証しません。しかし、このプロセスはトライアンドエラーを通じた大量のモデルのトレーニングが必要となりまり、すぐに課題に直面することになります:ディープラーニングのトレーニングの性能向上です。
ディープラーニングトレーニングのチューニングは、ETLのチューニングのようには行きません。特定のハードウェアによる膨大な計算が必要となり、皆様は最終的にトレーニングが「遅すぎる」ということに気づきます。ユーザーは多くのケースで、パフォーマンスを損なういくつかの基本的な間違いを見逃しつつも、スケールアップをしようとして、高速ではないにもかかわらず高価かつ大袈裟なソリューションを用いようとします。
代わりにこの記事では、トレーニングにおけいて陥りがちなパフォーマンスの落とし穴を避けるための基本的なステップをウォークスルーし、スケールアップするために複雑なツールとハードウェアを適切に適用する方法を順を追って説明します。願わくば、安直に追加のGPUを投入することなしに、あなたのモデリングの作業がより高速になればと考えています。
シンプルな分類タスク
ここでのフォーカスは学習の問題自身ではないため、以下の例ではシンプルなデータセットと問題を用います:Caltech 256 datasetの約3万の画像を257カテゴリーへの分類します。
データはJPEGファイルから構成されています。これらは、以下の以前学習済みのベースレイヤーと合わせるために共通の次元(299×299)にリサイズされる必要があります。次に大規模トレーニングを行うために、ラベルと共に画像はParquetファイルに書き込まれます。これは、Apache Sparkの「binary」ファイルデータソースによって実現されます。完全なソースコードに関しては、上述のサンプルノートブックを参照してください。以下に抜粋を示します。
img_size = 299
def scale_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes)).convert('RGB')
image.thumbnail((img_size, img_size), Image.ANTIALIAS)
x, y = image.size
with_bg = Image.new('RGB', (img_size, img_size), (255, 255, 255))
with_bg.paste(image, box=((img_size - x) // 2, (img_size - y) // 2))
return with_bg.tobytes()
...
raw_image_df = spark.read.format("binaryFile").\
option("pathGlobFilter", "*.jpg").option("recursiveFileLookup", "true").\
load(caltech_256_path).repartition(64)
image_df = raw_image_df.select(
file_to_label_udf("path").alias("label"),
scale_image_udf("content").alias("image")).cache()
(train_image_df, test_image_df) = image_df.randomSplit([0.9, 0.1], seed=42)
...
train_image_df.write.option("parquet.block.size", 1024 * 1024).\
parquet(table_path_base + "train")
test_image_df.write.option("parquet.block.size", 1024 * 1024).\
parquet(table_path_base + "test")
Sparkにビルトインされている「image」データソースでもデータを読み込むことができます。
Tensorflowに対する人気のハイレベルフロントエンドであるKerasは、画像を分類するディープラーニングモデルを直感的に記述することができます。画像分類器をスクラッチから構築する必要はありません。代わりに、この例ではKerasに組み込まれた事前学習済みのXceptionを再利用し、分類のためにdenseレイヤーを追加します(スタンドアローンのKeras 2.2.4ではなく、tensorflow.kerasのTensorflow 1.13.1に含まれているKerasを使用していることに注意ください)。事前学習済みレイヤーはそれ以上学習されません。これをステップ0:「画像を取り扱う際には事前学習済みモデルと転送学習を使う」ととらえていただければと思います!
ステップ1: GPUを使う
ディープラーニングのトレーニングでCPUを使うケースは、GPUが利用できない場合のみと言えます。Databricksのようなクラウドプラットフォームで作業する際には、必要なドライバー、ライブラリがインストールされたGPUマシンをプロビジョンすることは容易です。この例では単一のK80 GPUを使用してモデルのトレーニングに着手します。
はじめにParquetから10%のサンプルデータをロードしてpandasデータフレームに読み込み、画像データをリシェイプし、サンプルの90%を用いてメモリー上でトレーニングを行います。ここでは、小さなバッチサイズを用いて60エポックでトレーニングします。ちょっとしたティップスです:事前学習済みネットワークを用いる際、ネットワークが期待するレンジに画像を正規化することは重要です。ここでは[-1, 1]となり、Kerasはこのための関数としてpreprocess_inputを提供します。
注意
Databricksでこのサンプルを実行する際には、GPUを伴う5.5 MLランタイム以降を指定し、ドライバーにはシングルGPUのインスタンスタイプを選択してください。このサンプルではSparkを使うので、1台のワーカーノードも必要となります。
df_pd = spark.read.parquet("...").sample(0.1, seed=42).toPandas()
X_raw = df_pd["image"].values
X = np.array(
[preprocess_input(
np.frombuffer(X_raw[i], dtype=np.uint8).reshape((img_size,img_size,3)))
for i in range(len(X_raw))])
y = df_pd["label"].values - 1 # -1 because labels are 1-based
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
...
def build_model(dropout=None):
model = Sequential()
xception = Xception(include_top=False,
input_shape=(img_size,img_size,3), pooling='avg')
for layer in xception.layers:
layer.trainable = False
model.add(xception)
if dropout:
model.add(Dropout(dropout))
model.add(Dense(257, activation='softmax'))
return model
model = build_model()
model.compile(optimizer=Nadam(lr=0.001),
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=2, epochs=60, verbose=2)
model.evaluate(X_test, y_test)
...
Epoch 58/60
- 65s - loss: 0.2787 - acc: 0.9280
Epoch 59/60
- 65s - loss: 0.3425 - acc: 0.9106
Epoch 60/60
- 65s - loss: 0.3525 - acc: 0.9173
...
[1.913768016828665, 0.7597173]
結果は良好です。精度は91.7%です!しかし、重要な欠陥があります。ホールドアウトしておいた10%の検証用データによる真の精度は76%となっています。実際のところ、このモデルは過学習しています。これは良くありません、というか悪いです。これは、多くの時間をトレーニングに費やしたのにもかかわらず、結果が若干悪化していることになります。検証用データに対する精度の減少が止まった時点でトレーニングを止めるべきです。これによって、より良いモデルを得られるだけではなく、高速にトレーニングを完了できます。
ステップ2: アーリーストッピングを使う
Keras(他のフレームワーク)は、これ以上トレーニングを続けたらモデルが悪化しそうな場合には、トレーニングを停止する機能を提供しています。Kerasにおいては、EarlyStoppingコールバックとなります。これを用いて、それぞれのエポックにおける評価プロセスに検証用データを渡すことになります。エポックを数回繰り返した際に改善が見られない場合、トレーニングが停止します。restore_best_weights=Trueを指定することで、最終的なモデルの重みは、最後のモデルではなく、最も精度が高いモデルのものになります。デフォルトでこの設定にしておくべきです。
...
early_stopping = EarlyStopping(patience=3, monitor='val_acc',
min_delta=0.001, restore_best_weights=True, verbose=1)
model.fit(X_train, y_train, batch_size=2, epochs=60, verbose=2,
validation_data=(X_test, y_test), callbacks=[early_stopping])
model.evaluate(X_test, y_test)
...
Epoch 12/60
- 74s - loss: 0.9468 - acc: 0.7689 - val_loss: 1.2728 - val_acc: 0.7597
Epoch 13/60
- 75s - loss: 0.8886 - acc: 0.7795 - val_loss: 1.4035 - val_acc: 0.7456
Epoch 14/60
Restoring model weights from the end of the best epoch.
- 80s - loss: 0.8391 - acc: 0.7870 - val_loss: 1.4467 - val_acc: 0.7420
Epoch 00014: early stopping
...
[1.3035458562230895, 0.7597173]
ここでは、60エポックではなく14エポックでトレーニングが停止しています。時間としては18分です。検証用データによる評価を行なっているため、それぞれのエポックの時間は若干伸びています(75秒対65秒)。精度は改善されており、76.7%となっています。
アーリーストッピングにおいては、fit()に渡されるエポック数だけが、実行されるエポックの最大数に対する制限として影響することに注意してください。これは大きな値が設定される場合があります。これは同じことを示している事象の最初の一つです:トレーニングの単位としてエポック数は問題にならないということです。これらは単にトレーニングに入力される全体のデータを構成するデータバッチの数です。しかし、トレーニングは、十分にトレーニングが行われるまで繰り返しバッチに対してデータを渡すことを意味します。エポック数は直接重要ではありません。しかし、同じデータ量に対してトレーニングに要した時間を比較するためには、エポック数は有用です。
ステップ3: より大きいバッチサイズでGPUを最大限活用する
Databricksでは、GangliaベースのUIでクラスターのメトリクスを確認できます。トレーニング中のGPU利用率を確認できます。ボトルネックを特定できる場合があるため、チューニングにおいては利用率のモニタリングは重要です。ここでは、GPUの利用率は90%程度となっており良好と言えます。
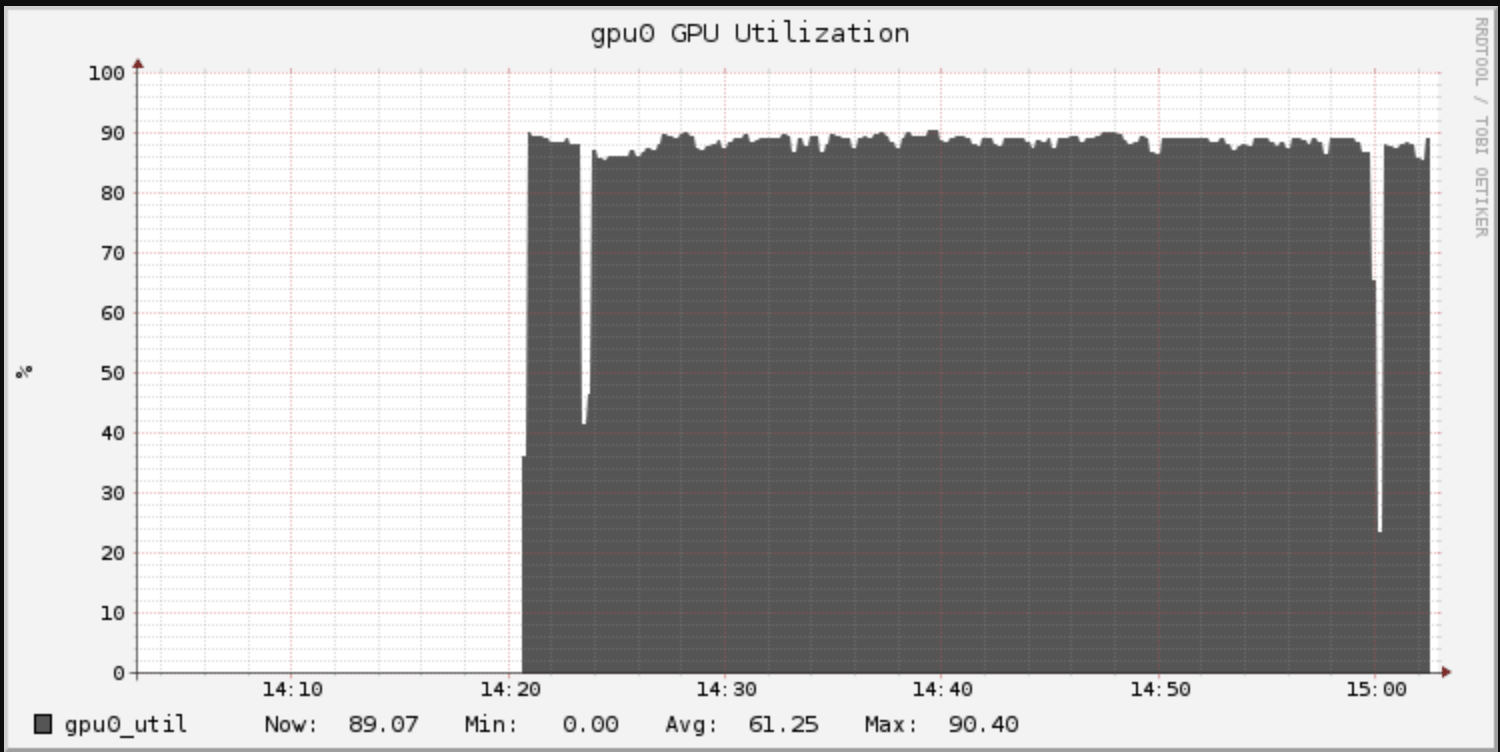
90%よりも100%の方が望ましいです。バッチサイズ2は小さいため、処理においてGPUを十分活用できていません。バッチサイズを大きくすることで利用率を向上できます。GPUを忙しくさせることだけが目的ではありますが、追加の作業を行うことでメリットが生まれます。より大きいバッチは、それぞれのバッチで、モデルのアップデートを(あるところまでは)改善します。結果的に、より高い学習率でトレーニングできるようになり、モデルが改善を停止するまでの時間を短縮できます。
あるいは、追加のキャパシティによって、活用するネットワークのアーキテクチャの複雑性を増すことができます。この例では、アーキテクチャのチューニングは探索しませんが、ネットワークの過学習の傾向を低減するためにいくつかのドロップアウトを追加します。
model = build_model(dropout=0.5)
model.compile(optimizer=Nadam(lr=0.004),
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=16, epochs=30, verbose=2,
validation_data=(X_test, y_test), callbacks=[early_stopping])
…
Epoch 6/30
- 56s - loss: 0.1487 - acc: 0.9583 - val_loss: 1.1105 - val_acc: 0.7633
Epoch 7/30
- 56s - loss: 0.1022 - acc: 0.9717 - val_loss: 1.2128 - val_acc: 0.7456
Epoch 8/30
- 56s - loss: 0.0853 - acc: 0.9744 - val_loss: 1.2004 - val_acc: 0.7597
Epoch 9/30
Restoring model weights from the end of the best epoch.
- 62s - loss: 0.0811 - acc: 0.9815 - val_loss: 1.2424 - val_acc: 0.7350
Epoch 00009: early stopping
バッチサイズを2から16に増やすことで、学習率は0.001から0.004になり、エポックにおけるGPU時間は75秒から60秒になりました。同等の精度(76.3%)に9エポックで到達しました。全体のトレーニング時間は、前回の65フンと比較してわずか9分です。
さらに学習率を上げることは容易ですが、この場合トレーニング精度は低くなります。バッチサイズを8倍にする際には、多くの場合、学習率も最大8倍にすることをお勧めします。いくつかの研究では、バッチサイズをNに増やした場合、学習率はsqrt(N)になるということが述べられています。
Kerasによって入力データがシャッフルされるので、トレーニングプロセス固有のランダム性に注意してください。データが投入される順序に依存して、アーリーストッピングが早く発生したり、遅く発生したりすること、さらには、精度は多くのケースで改善しますが、時には低下することがあることに注意してください。だとしても、追加のトレーニングをおこなうことで、最終的にはアーリーストッピングの忍耐は増加することになります。
ステップ4: 大規模データにアクセスするためにPetastormと/dbfs/mlを使う
上のトレーニングにおいては10%のサンプルデータを使用し、上で述べたティップスを用いて、新たなベストプラクティスを導入しトレーニング時間を短縮できました。次のステップではもちろん、全てのデータでトレーニングを行います。これによってさらに高い精度を期待できますが、より多くのデータを処理する必要が出てきます。全体のデータセットは数Gバイトになり、メモリには入りきるかもしれませんが、ここではあえて入りきらないものと考えましょう。異なるアプローチを用いることで、トレーニングの際にデータは効率的に分割されメモリにロードされることになります。
幸い、UberによるPetastormライブラリは、Tensorflow(Keras)にParquetデータを読み込むように設計されています。これは、トレーニングでpandasデータフレームではなく、Tensorflow Datasetsを使用するために、トレーニングと前処理のコードに組み込むことができます。ここでのデータセットはデータに対する無限のイテレータとして動作し、エポックを構成するためにいくつのバッチが必要なのかをsteps_per_epochで定義できます。これによって、エポックを任意に定義できます。
長時間のトレーニングジョブにおいて、トレーニングのエラーから復帰できるように、トレーニングの進捗のチェックポイントを作成することが一般的です。これもまたコールバックとして追加されます。
注意
このサンプルを実行する際には、petastormライブラリをクラスターにインストールしてください。
path_base = "/dbfs/.../"
checkpoint_path = path_base + "checkpoint"
table_path_base = path_base + "caltech_256_image/"
table_path_base_file = "file:" + table_path_base
train_size = spark.read.parquet(table_path_base_file + "train").count()
test_size = spark.read.parquet(table_path_base_file + "test").count()
# Workaround for Arrow issue:
underscore_files = [f for f in (os.listdir(table_path_base + "train") +
os.listdir(table_path_base + "test")) if f.startswith("_")]
pq.EXCLUDED_PARQUET_PATHS.update(underscore_files)
img_size = 299
def transform_reader(reader, batch_size):
def transform_input(x):
img_bytes = tf.reshape(decode_raw(x.image, tf.uint8), (-1,img_size,img_size,3))
inputs = preprocess_input(tf.cast(img_bytes, tf.float32))
outputs = x.label - 1
return (inputs, outputs)
return make_petastorm_dataset(reader).map(transform_input).\
apply(unbatch()).shuffle(400, seed=42).\
batch(batch_size, drop_remainder=True)
上のメソッドでは、TensorflowのトランスフォーメーションAPIに関して、以前のコードから前処理の部分を再実装しています。PetastormはParquetファイルの行グループサイズに完全に依存してバッチデータを提供するデータセットを作成することに注意してください。トレーニングにおけるバッチサイズを制御するには、データを適切なサイズのバッチを作り直すために、Tensorflowのunbatch()とbatch()を使用してください。また、PetastormでArrowを通じてParquetを読み込む際の問題を回避するために、現状ではちょっとしたワークアラウンドが必要となります。
batch_size = 16
with make_batch_reader(table_path_base_file + "train", num_epochs=None) as train_reader:
with make_batch_reader(table_path_base_file + "test", num_epochs=None) as test_reader:
train_dataset = transform_reader(train_reader, batch_size)
test_dataset = transform_reader(test_reader, batch_size)
model = build_model(dropout=0.5)
model.compile(optimizer=Nadam(lr=0.004),
loss='sparse_categorical_crossentropy', metrics=['acc'])
early_stopping = EarlyStopping(patience=3, monitor='val_acc',
min_delta=0.001, restore_best_weights=True, verbose=1)
# Note: you must set save_weights_only=True to avoid problems with hdf5 files and /dbfs/ml
checkpoint = ModelCheckpoint(checkpoint_path + "/checkpoint-{epoch}.ckpt", save_weights_only=True, verbose=1)
model.fit(train_dataset, epochs=30, steps_per_epoch=(train_size // batch_size),
validation_data=test_dataset, validation_steps=(test_size // batch_size),
verbose=2, callbacks=[early_stopping, checkpoint])
さらには、技術的理由から、/dbfsを使う際にはModelCheckpointはsave_weights_only=Trueに設定する必要があります。また、エポックごとに異なるチェックポイントのパスを使用する必要があります。{epoch}を含むパスパターンを使用してください。
Epoch 8/30
Epoch 00008: saving model to /dbfs/tmp/sean.owen/binary/checkpoint/checkpoint-8.ckpt
- 682s - loss: 1.0154 - acc: 0.8336 - val_loss: 1.2391 - val_acc: 0.8301
Epoch 9/30
Epoch 00009: saving model to /dbfs/tmp/sean.owen/binary/checkpoint/checkpoint-9.ckpt.
- 684s - loss: 1.0048 - acc: 0.8397 - val_loss: 1.2900 - val_acc: 0.8275
Epoch 10/30
Epoch 00010: saving model to /dbfs/tmp/sean.owen/binary/checkpoint/checkpoint-10.ckpt
- 689s - loss: 1.0033 - acc: 0.8422 - val_loss: 1.3706 - val_acc: 0.8225
Epoch 11/30
Restoring model weights from the end of the best epoch.
Epoch 00011: saving model to /dbfs/tmp/sean.owen/binary/checkpoint/checkpoint-11.ckpt
- 687s - loss: 0.9800 - acc: 0.8503 - val_loss: 1.3837 - val_acc: 0.8225
Epoch 00011: early stopping
エポックの時間は11倍以上長くなっていますが、ここでのエポックは、10%のサンプルデータではなくトレーニングデータ全体となっていることを思い出してください。クラウドストレージのParquetを読み込む際、チェックポイントを書き込む際のI/Oが追加のオーバーヘッドになっています。GPU使用率のグラフは「トゲトゲした」GPU利用を示しています。
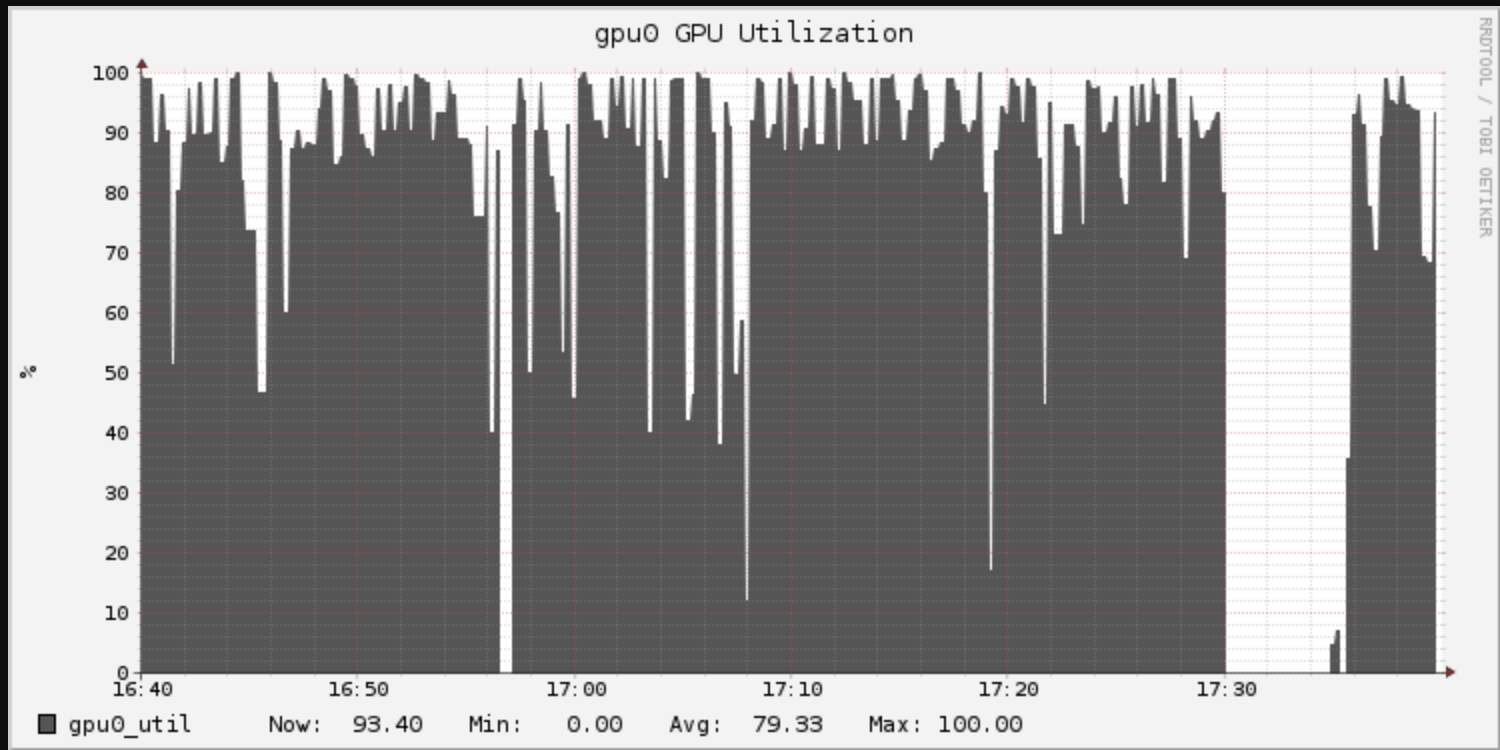
改善はあったのでしょうか?精度が大きく改善され83%になっています。対価は長いトレーニング時間です。9分から126分になりました。多くのアプリケーションにおいては、このコストは相応なものと言えます。
Databricksでは、トレーニングの際にParquetファイルがローカルファイルとして見えるように、最適化されたファイルシステムマウントの実装を提供しています。/dbfs/…ではなく/dbfs/ml/…を通じてファイルにアクセスすることで、I/O性能を改善できます。また、Petastorm自体も毎回クラウドストレージからデータを読み込まないように、ローカルディスクへのキャッシュを行います。
path_base = "/dbfs/ml/..."
checkpoint_path = path_base + "checkpoint"
table_path_base = path_base + "caltech_256_image/"
table_path_base_file = "file:" + table_path_base
def make_caching_reader(suffix, cur_shard=None, shard_count=None):
return make_batch_reader(table_path_base_file + suffix, num_epochs=None,
cur_shard=cur_shard, shard_count=shard_count,
cache_type='local-disk', cache_location="/tmp/" + suffix,
cache_size_limit=20000000000,
cache_row_size_estimate=img_size * img_size * 3)
上のコードのようにmake_readerのところでmake_caching_reader を使用します。
Epoch 6/30
Epoch 00006: saving model to /dbfs/ml/tmp/sean.owen/binary/checkpoint/checkpoint-6.ckpt
- 638s - loss: 1.0221 - acc: 0.8252 - val_loss: 1.1612 - val_acc: 0.8285
...
Epoch 00009: early stopping
概ね同じ結果となりつつも、トレーニング時間が126分から96分に短縮されました。いまだ10倍のデータに対して10倍以上の時間がかかっていますが、7%の精度改善は悪くありません。
ステップ5: 複数のGPUを使う
これでもまだ性能改善が必要で、予算に余裕はありますか?V100のようなより大規模なGPUを使用して再度チューニングすることは簡単です。しかし、ある程度までは複数のGPUを使うことを考えるべきです。例えば、クラウドで8台のK80 GPUを利用することが可能です。Kerasは複数のGPUでのトレーニングを並列化するためのシンプルなユーティリティ関数multi_gpu_modelを提供しています。1行のコード変更で済みます。
num_gpus = 8
...
model = multi_gpu_model(model, gpus=num_gpus)
注意
このサンプルを動かす際には、ドライバーノードには8台のGPUを搭載したインスタンスを選択してください。
変更は簡単ですが、ある程度の精度を達成するためにはトレーニングを繰り返す必要があります。エポックごとの時間は630秒から270秒になりました。8倍速くはなっていませんし、3倍にもなっていません。8個のそれぞれのGPUは、16個の入力の個々のバッチの1/8のみを処理しており、バッチあたり2つを効果的に処理しています。上で述べた通り、バッチサイズを8倍、256に増加させることは可能ですし、学習率を0.018に増加できます。(すべてのコードに関しては添付のノートブックをご覧ください)
エポックあたり135秒となりトレーニングは高速になりました。この高速化はいいものですが、8倍にはなっていません。精度は安定して83%程度ですので、トレーニングの高速化という意味では道半ばです。Kerasの実装はシンプルですが最適化されていません。Kerasが部分的な勾配をシンプルながらも遅い方法で結合している間、GPUがアイドル状態になるためGPU利用率はスパイキーです。
UberによるHorovodは、高効率な方法で単一マシン上の複数のGPUでディープラーニングをスケールさせるだけでなく、複数マシン上のGPUでもディープラーニングをスケールできるプロジェクトです。複数マシンにおけるトレーニングと関連づけられがちですが、それだけがスケールアップの方法ではありません。現状の複数GPU環境でも有用です。同じVMに接続された8台のCPUを利用する方がネットワークを横断するよりも効率的です。
SparkとHorovodを統合するためにDatabrikcsのHorovodRunnerユーティリティを使用するために、コードに対して別の修正が必要となります。
batch_size = 32
num_gpus = 8
def train_hvd():
hvd.init()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
K.set_session(tf.Session(config=config))
pq.EXCLUDED_PARQUET_PATHS.update(underscore_files)
with make_caching_reader("train", cur_shard=hvd.rank(), shard_count=hvd.size()) as train_reader:
with make_caching_reader("test", cur_shard=hvd.rank(), shard_count=hvd.size()) as test_reader:
train_dataset = transform_reader(train_reader, batch_size)
test_dataset = transform_reader(test_reader, batch_size)
model = build_model(dropout=0.5)
optimizer = Nadam(lr=0.016)
optimizer = hvd.DistributedOptimizer(optimizer)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy', metrics=['acc'])
callbacks = [hvd.callbacks.BroadcastGlobalVariablesCallback(0),
hvd.callbacks.MetricAverageCallback(),
EarlyStopping(patience=3, monitor='val_acc',
min_delta=0.001, restore_best_weights=True,
verbose=(1 if hvd.rank() == 0 else 0))]
if hvd.rank() == 0:
callbacks.append(ModelCheckpoint(
checkpoint_path + "/checkpoint-{epoch}.ckpt",
save_weights_only=True, verbose=1))
model.fit(train_dataset, epochs=30,
steps_per_epoch=(train_size // (batch_size * num_gpus)),
validation_data=test_dataset,
validation_steps=(test_size // (batch_size * num_gpus)),
verbose=(2 if hvd.rank() == 0 else 0), callbacks=callbacks)
hr = HorovodRunner(np=-num_gpus)
hr.run(train_hvd)
再びここでいくつか注意点があります:
- Horovodトレーニング関数においても、再びArrowに関するワークアラウンドが必要になります。
- 適切にバリデーションメトリクスの平均を取るために
hvd.callbacks.MetricAverageCallbackを使用してください - 1台のワーカー(rank 0)でのみチェックポイントコールバックを実行するようにしてください。
- ローカルで実行する際には、HorovodRunnerの引数
np=に使用するGPUの数のマイナスの値を指定してください。 - ここでのバッチサイズは全体ではなくGPUあたりのものになります。steps_per_epochは異なる方法で計算されます。
トレーニングのアウトプットは非常にごちゃごちゃしたものなのでここには掲載しません。トレーニング時間は96分から12.6分になり、ほぼ7.6倍です。これは理論上最大の8倍の高速化に近いものになっています!精度は83.5%となっています。1台のGPUの際には9分で76%の精度でした。
ステップ6: 複数のマシンでHorovodを使う
時には、8台、16台のGPUでも不十分であり、多くの場合マシンが1台ということもあります。あるいは、クラウドにおける価格変動生を活用することで、安価な複数のマシンにGPUを配備する方が安く上がる場合があります。上のHorovodのサンプルは、1行の変更だけで1台の8GPUマシンではなく8台の1GPUマシンで実行することができますHorovodRunnerはSpark 2.4のbarrier modeサポートによって、Sparkクラスター上でHorovodを分散処理することができます。
num_gpus = 8
...
hr = HorovodRunner(np=num_gpus)
注意
上のサンプルは、それぞれ1台のGPUを搭載した8台のワーカーのクラスターで実行してください。
必要な変更は、ドライバーではなくクラスターの8GPUを利用するように、-8ではなく9を指定するところだけです。嬉しいことにGPU利用は8台のマシンに分散されます(アイドル状態にあるのはトレーニングに参加しないドライバーです)。
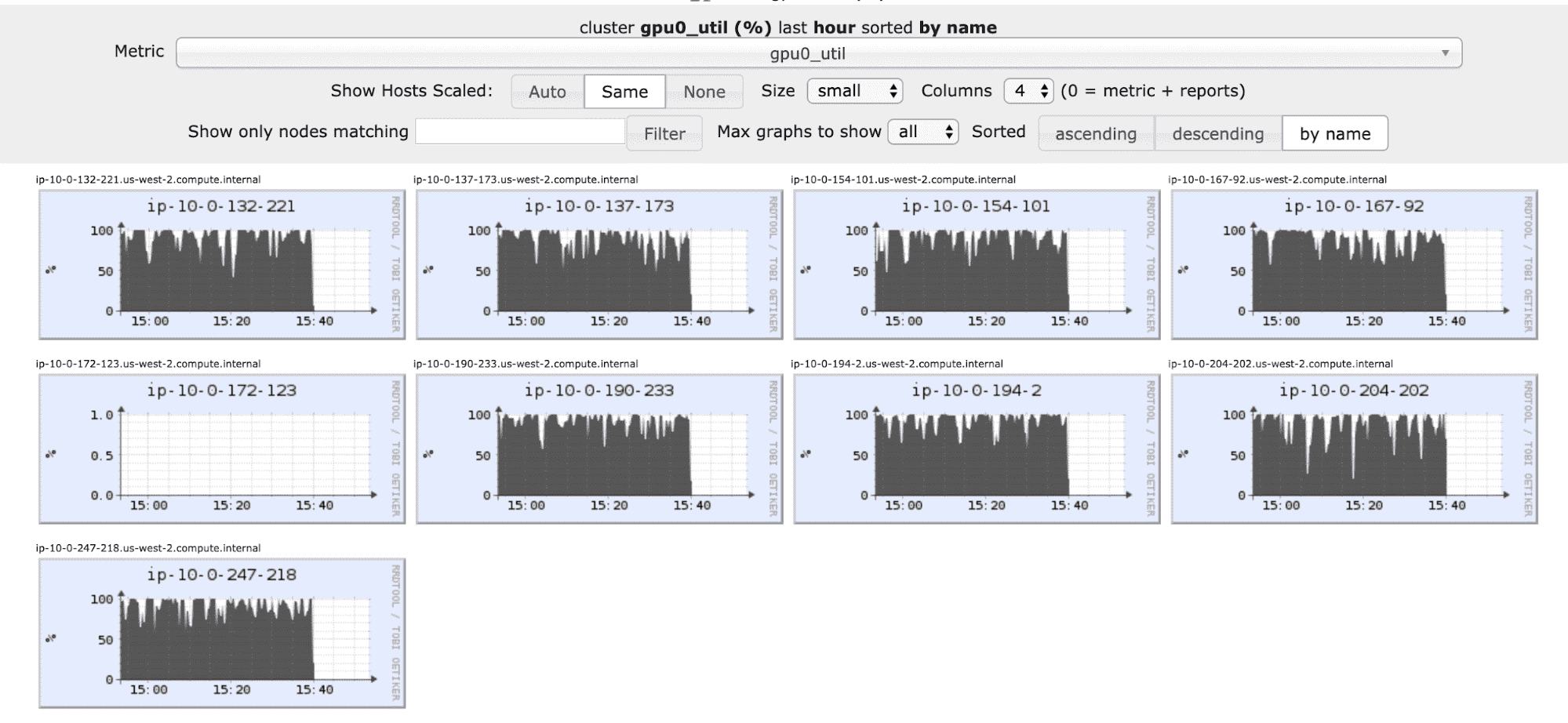
精度は予想通り大きく変わらず83.6%となります。全体の実行時間は12.6分から17分となりました。これは、マシン間のGPUの調整によるオーバーヘッドです。このオーバーヘッドはコスト観点では許容できるケースがあります。また、このオーバーヘッドはトレーニングに16個以上のGPUを利用してスケールさせるためには必要悪とも言えます。もちろん、可能な場合には、1台のマシンにすべてのGPUを搭載させるべきです。
この程度の規模の問題に対しては、より多くのGPUリソースを効率的に活用することは難しいかもしれません。リソースを効率的に活用するためには、より大きい学習率が必要となりますが、すでに可能な限り大きな値になっています。このネットワークにおいては、いくつかのK80 GPUをデプロイすることが最適かもしれません。もちろん、より大規模なネットワーク、データセットが世の中には存在します!
まとめ
ディープラーニングは強力は魔法と言えますが、我々は常にディープラーニングを高速に実行したいと考えます。いくつかの方法でスケールさせることが可能です。モデルトレーニングの設定を行う際には、新たなベストプラクティスと落とし穴が存在しています。これらのいくつかは、ここでの小規模の画像分類モデルを助け、精度をわずかに改善しながらも実行時間を7倍短縮しました。スケールするために必要な最初のステップはリソースに関することではなく、簡単な最適化です。
クラウドで大規模データセットに対するトレーニングをスケールさせるためには、新たなツールが必要となりますが、最初から複数のGPUは必要ありません。注意深くPetastormと/dbfs/mlを活用することで、10倍のデータで82.7%の精度を実現しつつも、同じハードウェアで10倍までの時間をかけずに済んでいます。
スケールアップの次のステップは、複数のGPUをHorovodのようなツールとともに活用することでしたが、マシンのクラスターが標準であるETLとはことなり、ここではマシンのクラスターは不要でした。1台の8GPUインスタンスを用いることで、8倍高速になり、83%以上の精度を達成しました。最大の問題に対して複数のGPUインスタンスが必要となりますが、Horovodを活用することで、このようなケースでもオーバーヘッド少なくGPUを活用することができます。