滋賀大学で講義した資料を説明します。4.5時間の講義でした。
スライドはこちら。
デモや実習のリポジトリ。
アジェンダ
- イントロダクション: データエンジニアリングとは
- データエンジニアリングとETLの基本
- 2つの実装アプローチ
- Part 1: Sparkの基礎(90分)
- Apache Sparkとは
- Apache Sparkのアーキテクチャ
- DataFrameと変換処理
- PySparkによる命令型ETL実装
- Part 2: Lakeflow SDP(90分)
- 宣言型パイプラインの概念
- コアとなる構成要素
- エクスペクテーション(データ品質)
- Lakeflowジョブによる自動化
- Part 3: 実践演習(90分)
- NYC Taxiデータを使って命令型・宣言型の両方でETLパイプラインを構築
イントロダクション
データエンジニアリングとは
データエンジニアリングとは分析などでデータを活用できるようにするための営みです。
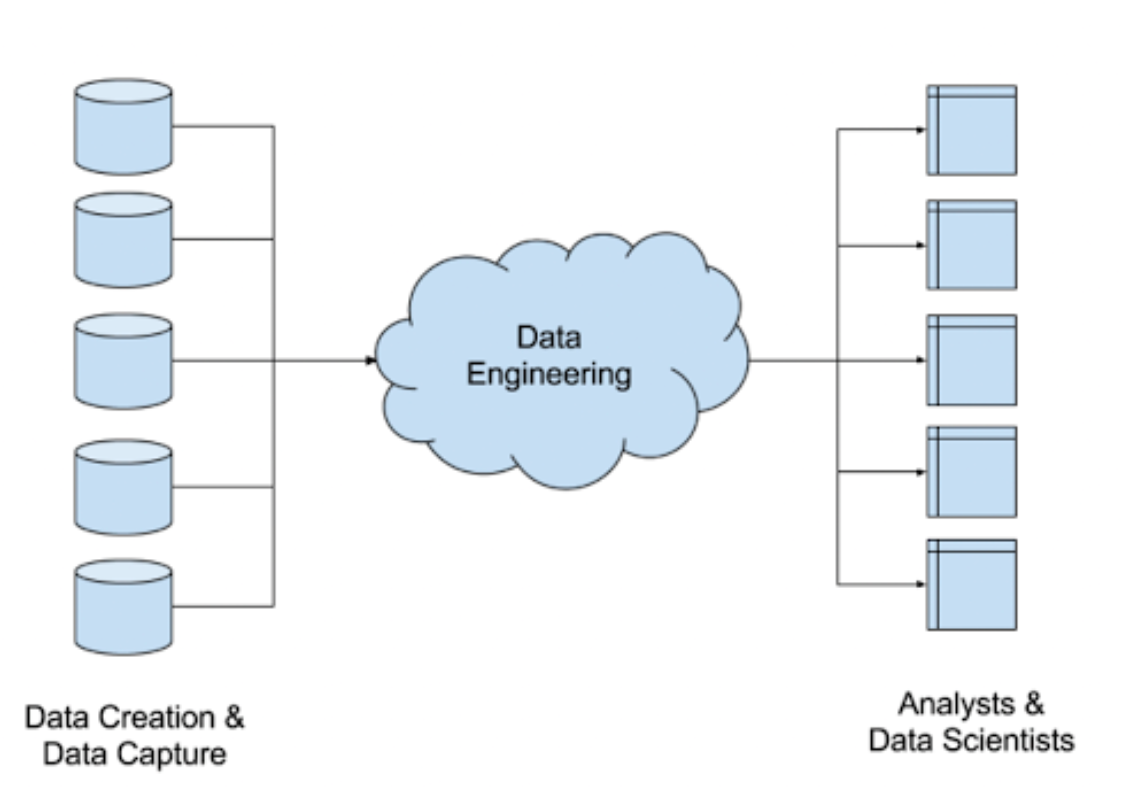
データエンジニアリングとは、様々なソースやフォーマットで提供される生のデータを収集、分析できるようにするシステムの設計、構築に関するプロセスを意味します。このようなシステムによって、ユーザーはビジネスの成長につながる実践的なデータアプリケーションを作り出すことが可能となります。
データエンジニアリングは、需要の高まっているスキルです。生成AIの出現により、その需要はさらに高まりを見せています。データエンジニアは、データを統合し、あなたたちがナビゲートする助けとなるシステムを設計する人たちです。データエンジニアは以下を含む様々なタスクを実行します:
- 取得:ビジネスに関連するすべての様々なデータセットを特定します
- クレンジング:データにおけるすべてのエラーを特定し、綺麗にします
- 変換:すべてのデータに共通的なフォーマットを与えます
- 曖昧性の除去:複数の方法で解釈し得るデータを解釈します
- 重複排除:データの重複したコピーを排除します
これらが完了すると、データレイクやデータレイクハウスのような中央リポジトリにデータを格納することができます。また、データエンジニアはデータのサブセットをデータウェアハウスにコピー、移動することができます。
データエンジニアは以下を含む様々なツールとテクノロジーを扱います:
- ETLツール: ETL(抽出、変換、ロード)ツールはシステム間でデータを移動します。データにアクセスし、分析により適した形にするためにデータを変換します。
- SQL: 構造化クエリー言語(SQL)はリレーショナルデータベースへのクエリーにおける標準言語です。
- Python: Pythonは汎用プログラミング言語です。データエンジニアはETLタスクでPythonを使うことがあります。
- クラウドデータストレージ: Amazon S3、Azure Data Lake Storage(ADLS)、Google Cloud Storageなど
- クエリーエンジン: 回答を得るためにデータに対してクエリーを実行するエンジン。データエンジニアは、Dremio Sonar、Spark、Flinkなどのエンジンを取り扱います。
データエンジニアはビジネスアナリストやデータサイエンティストと連携してプロジェクトに取り組みます。


Databricksとの関係性についても触れます。ビジネスアナリストの方が利用するDatabricksの機能は、全体から見るとほんの一部です。

一方、データエンジニアリングの視点からDatabricksを見ると、大部分が関係していることがわかります。それだけ、データエンジニアの方に求められるスキルが幅広いということです。

ETL処理
ETLとはExtract(抽出)、Transform(変換)、Load(ロード)から構成される処理です。データエンジニアリングに取り組む際には基本的にこの流れに従います。

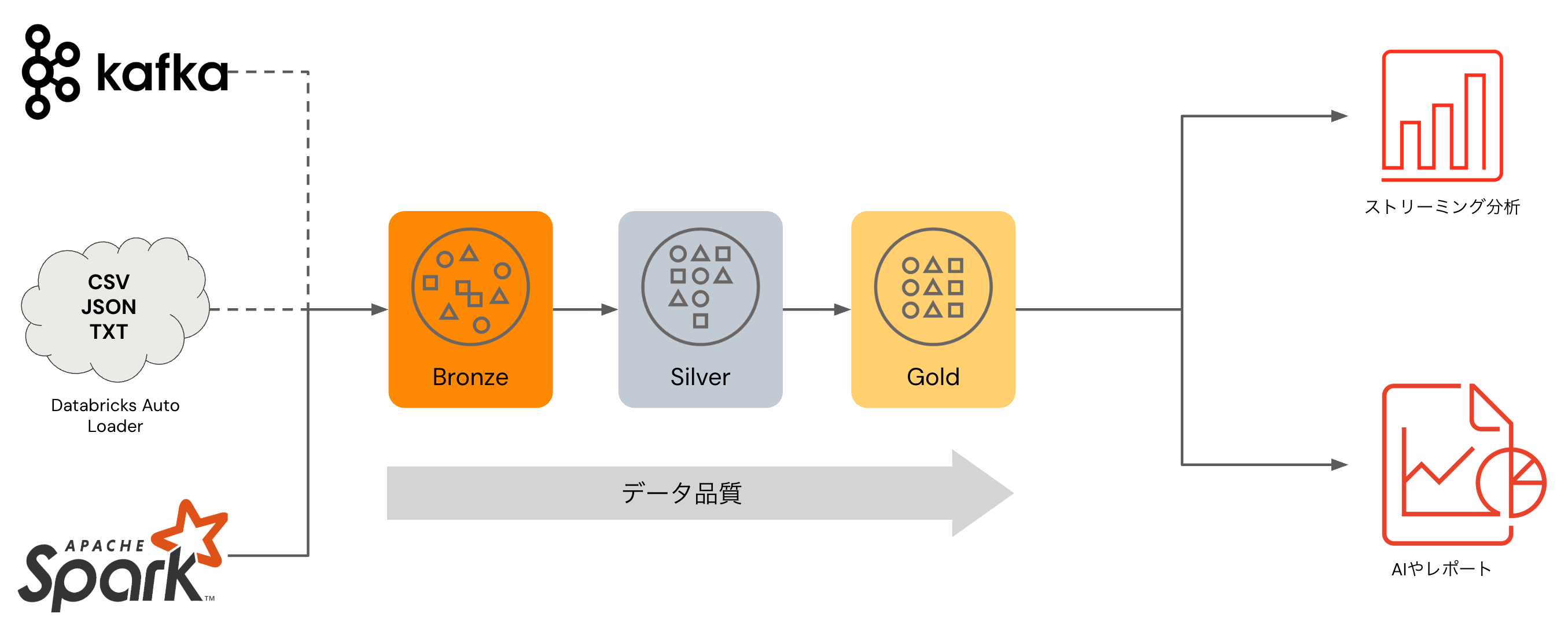
メダリオンアーキテクチャ
メダリオンアーキテクチャは特定の機能を指すものではなく、データパイプラインを構築する際に従うべき情報の整理学であり、Databricksで提唱しているアーキテクチャです。
- メダリオンアーキテクチャは、レイクハウスに格納されているデータの品質を示す一連のデータレイヤーを表現します。
- 企業のデータプロダクトに対して信頼できる唯一の情報源(single source of truth)を構築するために、Databricksではマルチレイヤーのアプローチを取ることをお勧めしています。
- このアーキテクチャは、公立的な分析に最適化されたレイアウトでデータ格納される前の検証、変換を行う複数のレイヤーをデータが追加する際の、原子性、一貫性、分離性、耐久性を保証します。ブロンズ(生)、シルバー(検証済み)、ゴールド(拡張済み)という用語はそれぞれのレイヤーにおけるデータの品質を表現しています。
2つの実装アプローチ
ここまで、データエンジニアリングに関係するコンセプトを説明してきましたが、実際にデータエンジニアリングにおける実装はどのようにおこなうのでしょうか?Databricksでは2つのアプローチが存在します。
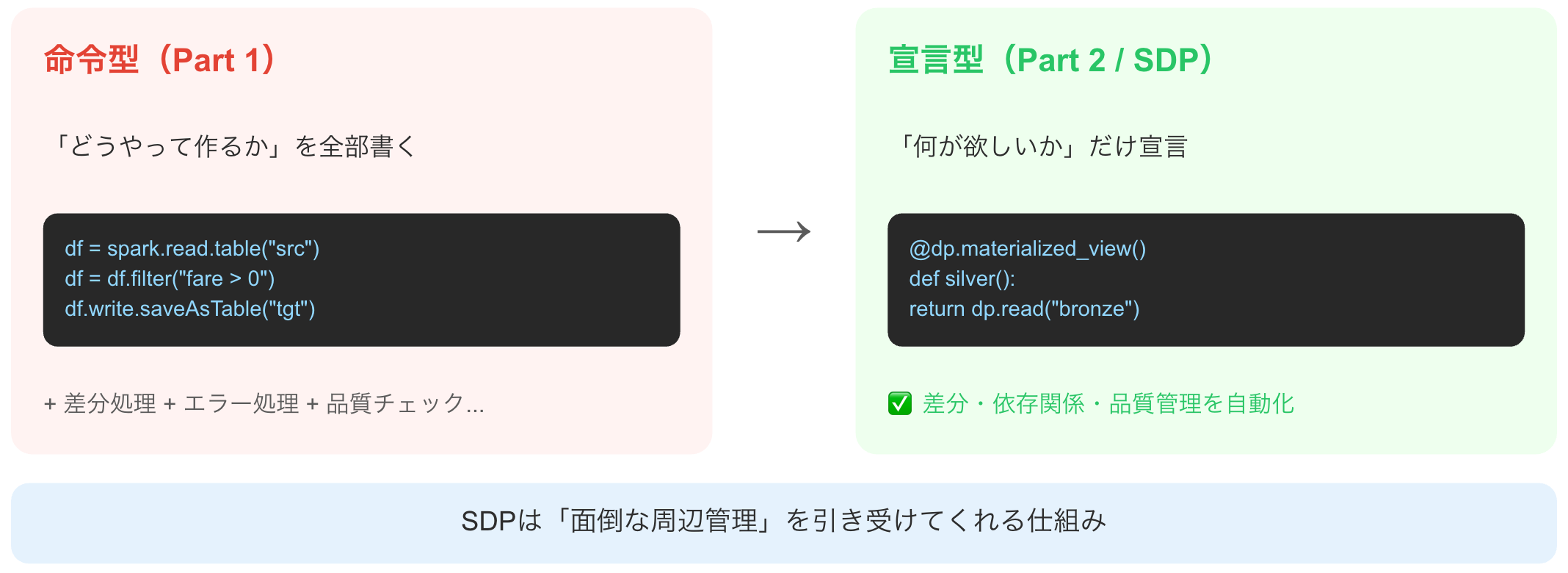
命令型(PySpark)
どうやって処理するかをステップバイステップで記述
df = spark.read.csv(...)
df = df.filter(...)
df.write.saveAsTable(...)
メリット: ✓ 柔軟性が高い ✓ デバッグしやすい
デメリット: △ コード量が多い △ 運用が大変
宣言型(Lakeflow SDP)
何が欲しいかを宣言し、実行方法はシステムにお任せ
@dp.table
def silver_data():
return dp.read("bronze")
メリット: ✓ 簡潔 ✓ 自動で依存関係解決
デメリット: △ 細かい制御が難しい
本講座ではまず命令型で基礎を学び、その後宣言型の利点を体験します。
Part 1 : Sparkの基礎
なぜPandasではなくSparkなのか?

データ量が少なければpandasで問題ありませんが、pandasではメモリに収まらないデータを処理することができないため、大規模データを取り扱う際にはSparkが選択肢として上がってきます。
Sparkの動作原理を学びましょう。
Sparkでもpandas同様にデータフレームを取り扱います。

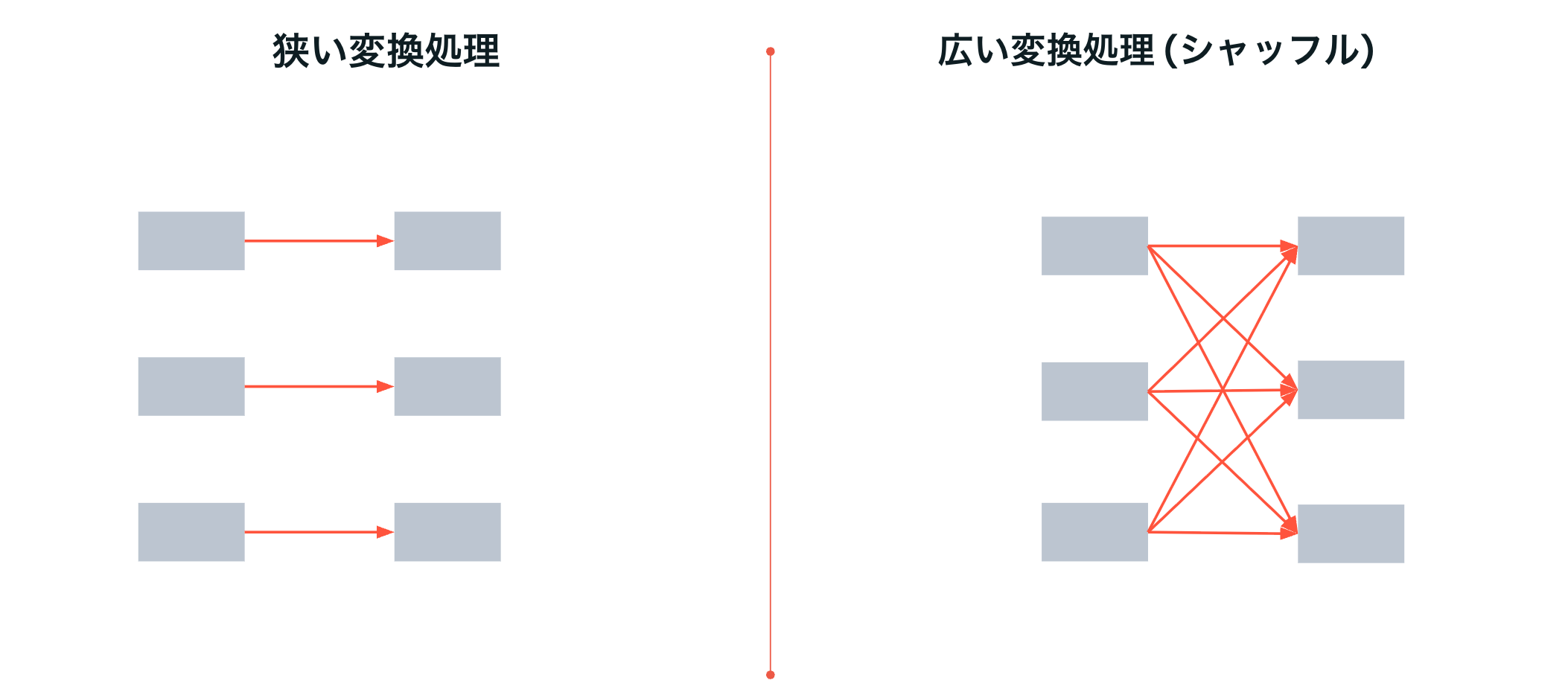
Sparkデータフレームを操作する際には、トランスフォーメーションとアクションの違いを理解することが重要です。トランスフォーメーションは変換ロジックを定義しますが、変換処理自身を実行しません。アクションを呼び出すことで定義された変換処理が実行されます。これは、遅延評価とよばれるものであり、処理を実行する前にSparkが処理を最適化できるようにするためです。

Sparkはデータを分散させて処理を行います。フィルタリングなど分散されたデータで処理が完結する狭い変換処理では、並列化の恩恵を最大限に享受できます。一方、集計や結合などの広い変換処理では、分散したデータのやり取りが必要となります。これはシャッフルと呼ばれ、処理性能にインパクトを与えるので注意が必要です。
視覚的にSparkを学ぶアーティファクトです。
本格的にSparkを勉強したい方はこちらの書籍もどうぞ。私たちが執筆しました。
Part 2 : Lakeflowによる宣言型パイプライン
すべては良いデータからスタートします。

一方、ガバナンスの欠如、複雑性、貧弱な信頼性などが良いデータの実現を妨げています。

Lakeflowはこれらの課題を解決します。


LakeflowはDatabricksにおけるデータエンジニアリングをシンプルなものにします。

Lakeflowは、コネクト、Spark宣言型パイプライン(SDP)、ジョブから構成されています。本講義ではSDPとジョブにフォーカスします。

Lakeflow SDPは、シンプルな宣言型アプローチを使用して信頼性の高いデータパイプラインを構築する、初のETLフレームワークです。Lakeflow SDPはインフラストラクチャを大規模に自動管理するため、データアナリストやエンジニアはツールに費やす時間を削減し、データから価値を引き出すことに集中できます。

宣言型アプローチでは、どう行うかではなく、何を行うべきかを記述します。以下の二つのコードは同じ処理を記述しています。
Spark命令型プログラム
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
microBatchOutputDF
.groupBy("key")
.agg(max_by("ts", struct("*").alias("row"))
.select("row.*")
.createOrReplaceTempView("updates")
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO cdc_data_raw t
USING updates s
ON s.key = t.key
WHEN MATCHED AND s.is_delete THEN
UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
A=CASE WHEN s.ts > t.ts THEN s.a ELSE t.a,
B=CASE WHEN s.ts > t.ts THEN s.b ELSE t.b,
… for every column …
WHEN NOT MATCHED THEN INSERT *
""")
}
cdcData.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("append")
.start()
宣言型パイプラインプログラム
AUTO CDC INTO cdc_data
FROM source_data
KEYS (id)
SEQUENCE BY ts
APPLY AS DELETE WHEN is_deleted
SDPのコアとなる概念
インクリメンタル処理とは?
一言で言うと 「前回から変わった部分だけ」を処理する方式です。

大量のデータを取り扱うデータエンジニアリングにおいて、毎日すべてのデータを処理することは非効率的です。毎日のデータ更新を例に考えてみましょう。

インクリメンタルな処理を実装することで、処理時間、コストを削減することができます。しかし、自前でインクリメンタル処理を実装することは困難です。そこでLakeflow SDPです。Lakeflow SDPがインクリメンタル処理を簡単にしてくれます。

Lakeflowの構成要素を説明する前に、一般的なテーブルとビューの定義を確認しましょう。

Part1では、df.write.saveAsTableを用いてテーブルを保存しました。このアプローチで高度なデータパイプラインを実装しようとすると、いくつかの課題に直面します。

これらの課題を、SDPでは宣言するだけで解決します。
宣言するのは主に以下の2つの要素です。

- マテリアライズドビュー(MV) データ変換・集計・JOIN
- ストリーミングテーブル(ST) ファイルの増分取り込み
迷ったらMV、ファイルの取りっこ身にはSTと覚えておきましょう。
マテリアライズドビュー(MV)とは

ストリーミングテーブル(ST)とは

MVとSTの使い分け

- 典型的なパイプライン構成では、Bronze層とSilver層をSTで、Gold層をMVで作ります。
- STはファイルの取り込みだけでなく、フィルタリング、型変換、カラム追加といった1行が1行になる処理であれば続けて使えます。
- 集計(groupBy)やJOINが必要になったタイミングでMVに切り替えます。これは、STが「追加」しかできないのに対し、集計やJOINは既存の行を「更新」する必要があるためです。
Lakeflow SDPでパイプライン構築がシンプルに
Lakeflowパイプラインエディタで効率的にデータパイプラインを構築できます。

エクスペクテーションでデータ品質を担保します。

- データエクスペクテーションにより、パイプライン内でデータ品質と整合性の制御を定義
- 柔軟なポリシーでデータ品質エラーに対処: 失敗、破棄、アラート、隔離
- すべてのデータパイプライン実行と品質メトリクスが取得、追跡、報告されます
Lakeflow SDPでパイプライン管理がシンプルに
イベントログでパイプラインのイベントを確認できます。
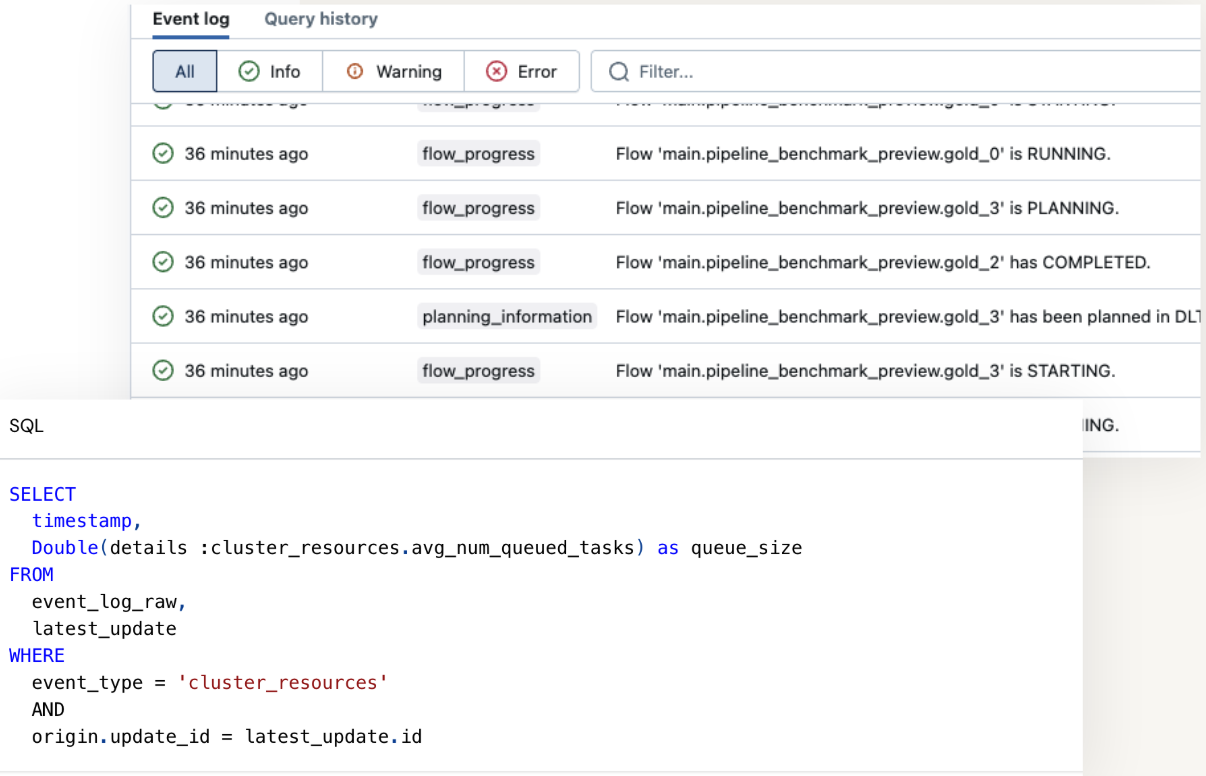
- パイプラインに関連するすべての情報を包含(データ品質チェック、進捗、リネージ)
- 宣言型パイプラインUI、API、またはDeltaテーブルとして直接クエリで表示可能!
データリネージでエンドツーエンドのリネージを確認できます。

Lakeflowジョブ
Lakeflowジョブは、パイプラインを含む様々なものをオーケストレーションします。
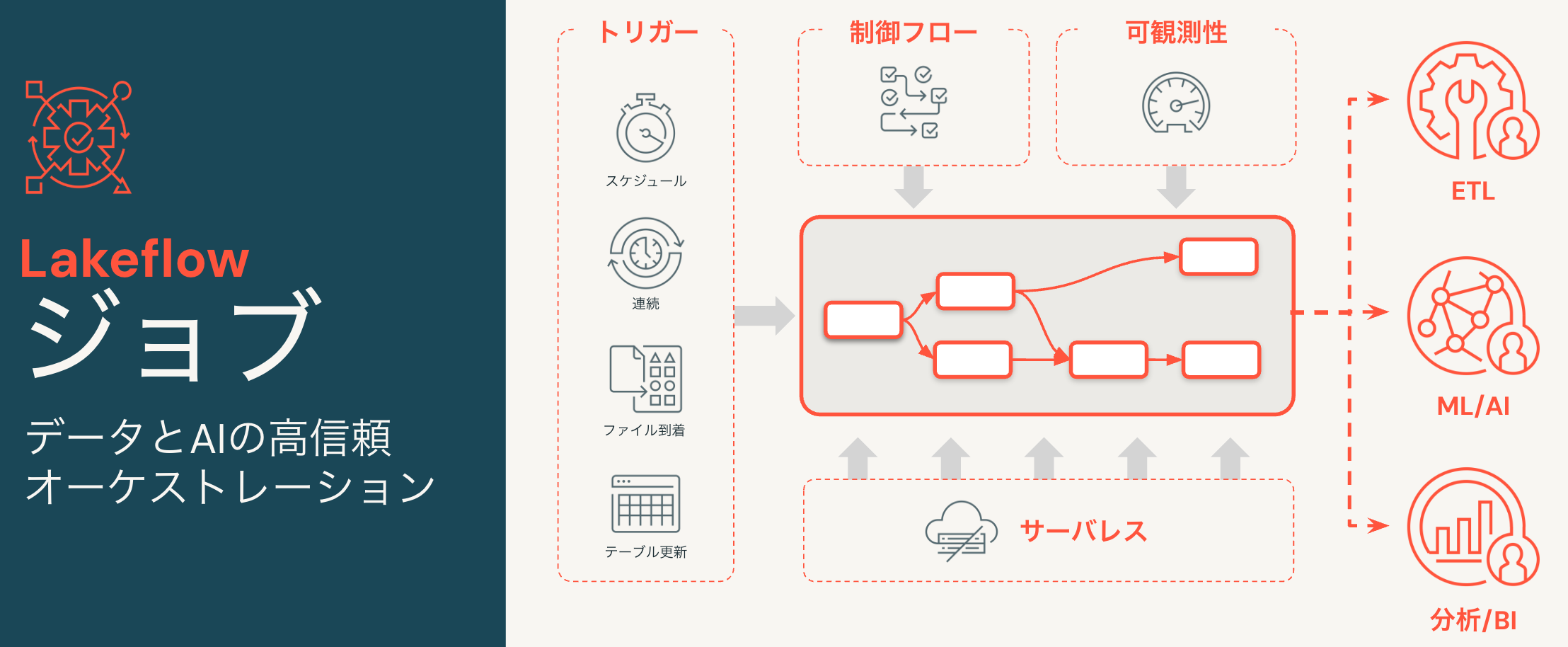
Lakeflowジョブの主要コンセプト

GUIとAPIでジョブを作成できます。

ジョブの実行結果を視覚的に確認できます。

手動実行、スケジュール実行に加えて、テーブル更新、ファイル到着をトリガーにすることも可能です。
- テーブル更新トリガー 指定されたテーブルの更新が発生したときにジョブ実行をトリガーします。データの鮮度を保証します。UCテーブル、ストリーミングテーブル、マテリアライズドビューをサポート。
- ファイル到着トリガー 外部ロケーションに新しいファイルが到着したときにジョブの実行をトリガーします。

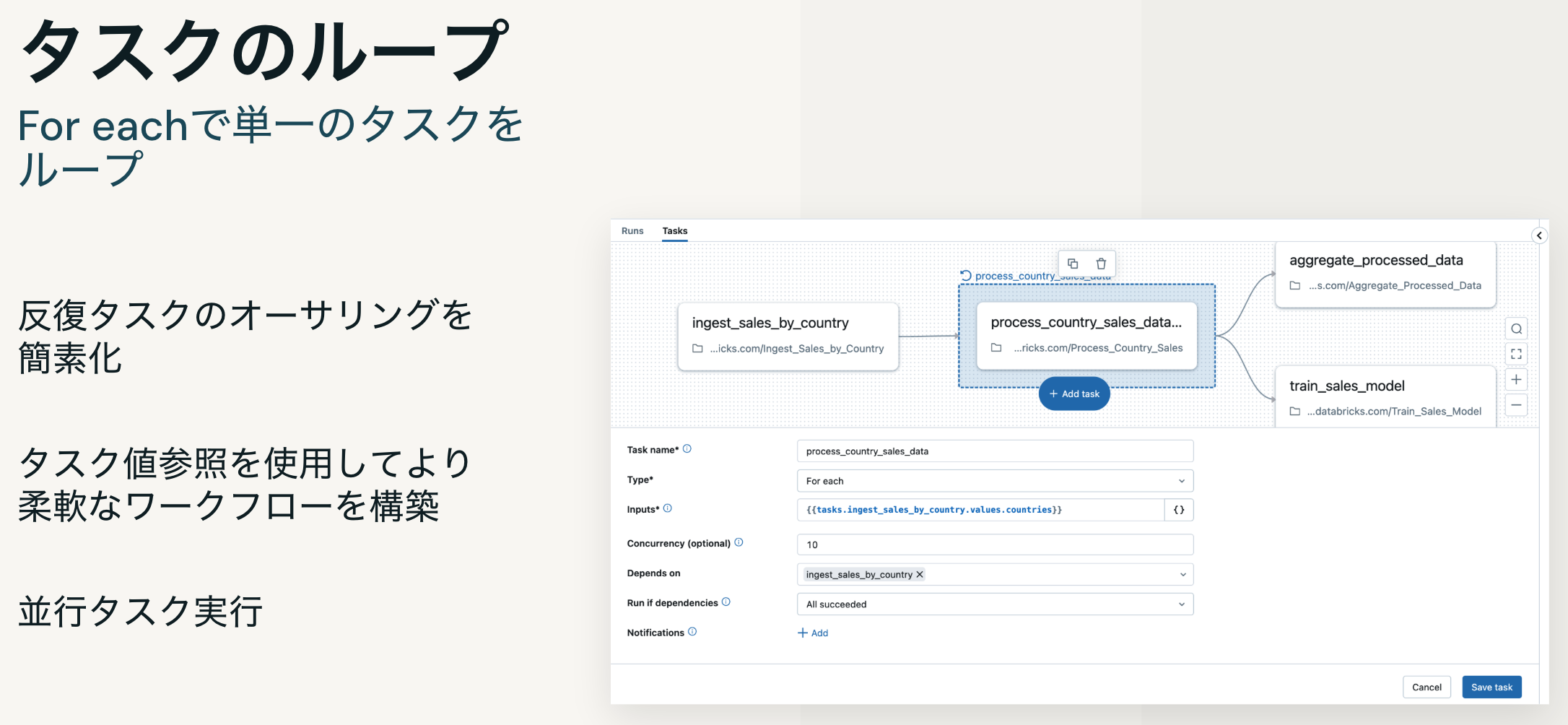
ジョブに含まれるタスクを条件分岐やループなど様々なロジックで制御可能です。
Part 3 : 実践演習
- 演習1(25分): PySparkによる命令型ETL
Bronze → Silver → Gold パイプラインを手動実装 - 演習2(25分): Lakeflow SDP宣言型パイプライン
同じ処理を宣言型で実装 - 演習3(15分): エクスペクテーションの追加
データ品質チェックを追加 - 演習4(15分): ジョブによる自動化
ワークフローとスケジュール設定
使用するノートブックなどはこちらに格納されています。
参考資料
- 実習のノートブック
- Lakeflow SDP入門:基礎から実践まで #Databricks - Qiita
- はじめてのDatabricks #Databricks - Qiita
- Databricks記事のまとめページ(その1) #Databricks - Qiita
- Databricksドキュメント | Databricks on AWS
- Databricks によるデータエンジニアリング | Databricks on AWS
- Lakeflow Spark宣言型パイプライン | Databricks on AWS
- ハンズオンで学ぶ Databricks - Databricksにおけるデータエンジニアリング - Speaker Deck
- Databricksにおけるビジネスアナリストからデータエンジニアへの転換 #Databricks_AI_BI - Qiita
- Apache Spark徹底入門