「Qiitaでいいねしたら草生えるページ」を作った副産物として全いいねの日時データを取得できました。
いいねした日時を使った分析をすると今までわからなかった驚愕の事実が見えてきました。
今までのQiita分析記事とこの記事では何が違うのか?
今までにもQiitaのいいねを分析した記事はいくつもありましたが、これらの中では記事データを使った分析を行なっていました。
データの取得元はAPIでいうと /api/v2/items になります。
このデータでは記事の投稿日時はわかってもいいねした日時まではわかりませんでした。
これに対してこの記事で使用するデータは、各記事についたいいねを /api/v2/items/:item_id/likes から取得しています。
このデータではいいねした日時までわかります。
この記事では今までわからなかったいいねした日時を使った分析を行なっています。
今までの投稿日ベース時系列いいね分析は問題あり
今までのQiita分析記事では以下のようなグラフが使用されていました。
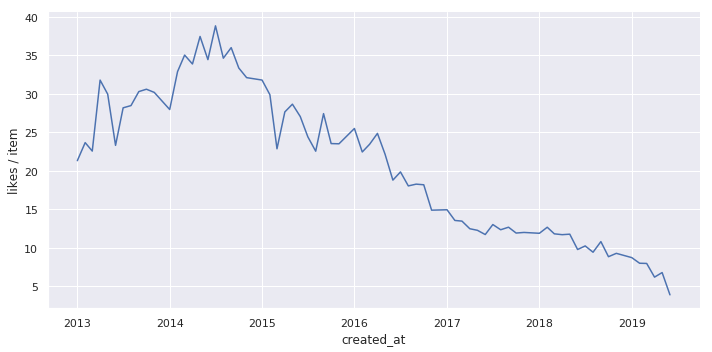
これは月毎の1記事あたり平均いいね数をグラフ化したものです。
x軸は投稿した日付になっています。つまり、いつ投稿された記事が**「今現在」**どれだけのいいねを獲得しているかのグラフになります。
これらの記事では以下のような考察をしているものがあります。
- 2014年の記事は2018年の記事より3倍のいいねを獲得している(データを取得した日で値が変わるので5倍と言ってる記事もある)
- 2014年以降はいいねの獲得が難しくなっている
- 原因は2016年11月のいいね導入
まず1と2ですが、冷静に考えるとおかしな話です。
例えて言うならこういう事です。
2014年生まれの子(現在5歳)と2018年生まれの子(現在1歳)の「今現在の身長」を比較して、
「2014年の子の方が背が高い。だから最近の子は成長が遅いんだ。」
と言っているようなものです。
話を元に戻します。
2014年の記事に付いたいいねは2014年だけではなくそれ以降に付いたいいねも含まれていて、2019年7月現在、合計約5.5年分です。
これに対して2018年の記事に付いたいいねは2018年から現在までの約1.5年です。
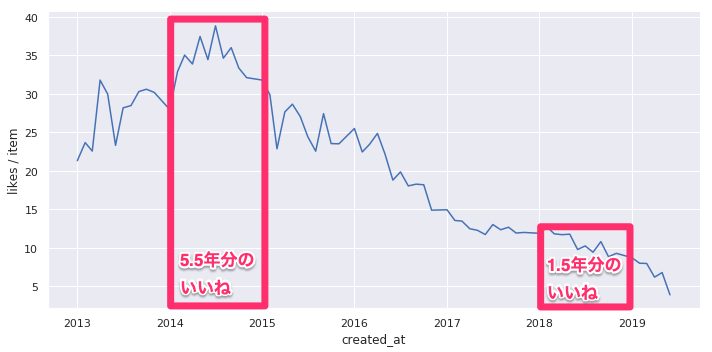
この期間が違う2つのいいね数を単純に比較するに意味があるでしょうか?
「最初の1年でついたいいね数」や「年数で割ったいいね数」で比較するなら分かりますが、そのまま比較するのは無意味です。
(自分も一度似たような発言をしてしまいましたが...)
最後の3についてですが、このデータからはとても読み取れません。
これは「はじめに結論ありき」で強引に結びつけているように思えます。
知りたいこと
今までの投稿日ベースの時系列いいね分析は明らかに間違いがありました。
しかし「最近はいいねの獲得が難しくなっている」というのは体感として事実です。
2016年11月のいいね導入についても、その後のいいね数に全く影響がないということはないでしょう。
そこでこの記事ではいいねの日時を使って
- いいね数は減少しているのか?
- 2016年11月のいいね導入はいいね数に影響はあったのか?
- いいね数が減少している、またはそう感じるこれ以外の原因はあるのか?
を中心に調べていきます。
分析
データは2019年6月24日頃に取得したものを使用します。
ここで使用したデータと分析結果はkaggleで公開しています。
- Dataset: https://www.kaggle.com/tag1216/qiita-items-and-likes-20190624
- Kernel: https://www.kaggle.com/tag1216/qiita-likes-analytics
この記事ではその中からいくつかピックアップして紹介していきます。
もし他の情報も知りたい方はkaggleで公開しているkernelを参照してください。
(説明を書いていないのでわかりにくいかもしれませんが)
それでは結果を見ていきましょう。
驚愕① 2017年のいいね数は前年比マイナス30%だが2018年には回復している
以下は月次いいね数のグラフです。
x軸は記事の投稿日ではなくいいねした日になります。
なお、12月はアドベントカレンダーの影響で大きく変動するのでグラフでは異常値として除外しています。
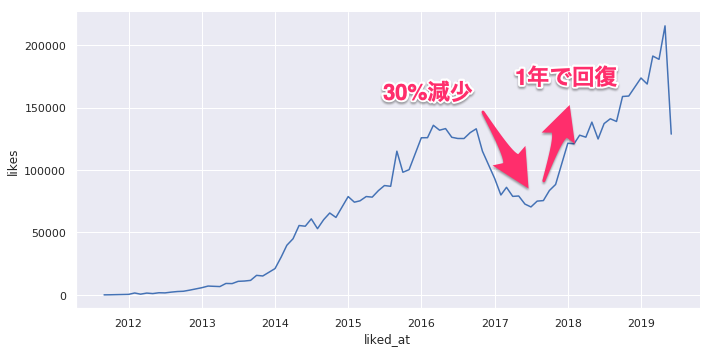
明確に2016年11月ごろからいいね数が大幅に減少しているのがわかります。
しかし2017年後半には持ち直してきており、2018年には2017年の水準を超えています。
このことから、「2016年11月のいいね導入」はその後のいいね数に大きな影響を与えたことがわかりますが、すでにその影響はなくなっていると見ていいでしょう。
その他の数値も見てみましょう。
「いいねした人のUU数」
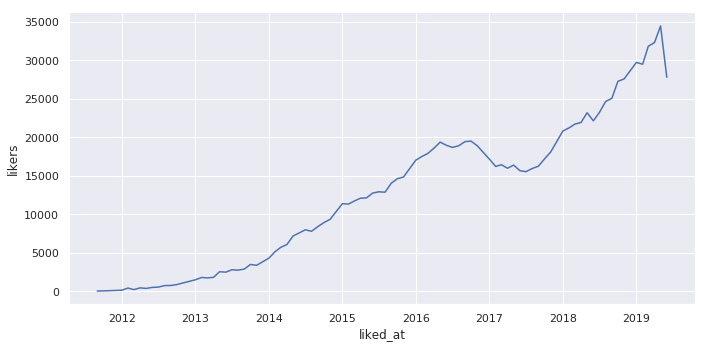
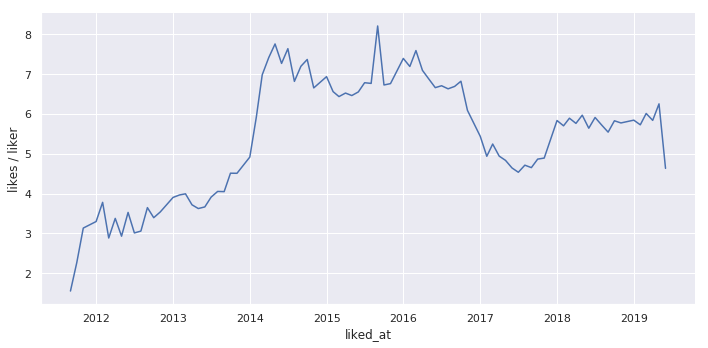
「いいねした人一人当たりのいいね数」
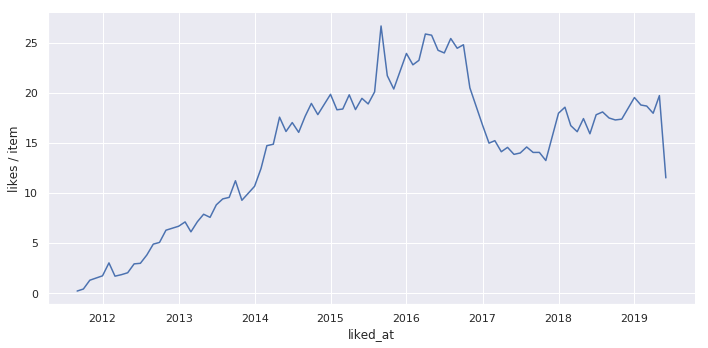
「1記事あたりのいいね数」
「いいねした人のUU数」はいいね数とほぼ同じです。
「いいねした人一人当たりのいいね数」と「1記事あたりのいいね数」は2017年以降もピークよりは若干低い値に留まっています。
「1記事あたりのいいね数」は上昇傾向にあったので、現在も「2016年11月のいいね導入」の影響が残っていると言えます。
なお、「1記事あたりのいいね数」はその年に発生したいいね数をその年に投稿された記事数で割って算出したものです。
その年に投稿された記事以外へのいいねも含まれています。
驚愕② 1年目の平均いいね数は2014年が12.5、2018年が8.1
ここからは、いいねした日と記事の投稿日の関係を見るために、いいね数を「いいねした年」と「投稿した年」で集計したデータを使用します。
grouped_likes = (
likes_items
.groupby([
pd.Grouper(key="liked_at", freq="YS"),
pd.Grouper(key="created_at", freq="YS"),
])
.liker.count()
.rename("likes")
)
likes_matrix = grouped_likes.reset_index().pivot_table(
index="liked_at",
columns="created_at",
values="likes",
aggfunc="sum",
)
以下は上記データをヒートマップで可視化したものです。
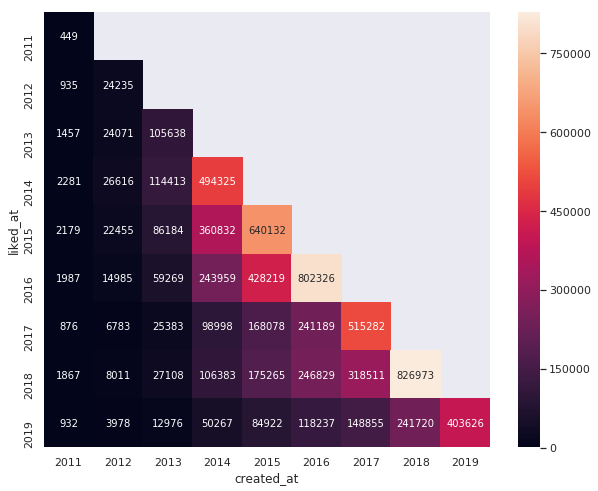
x軸が記事の投稿年、y軸がいいねした年です。
この表は縦に見ると「その年に投稿された記事がいついいねされたか」が分かります。
横に見ると「その年に発生したいいねがいつ投稿された記事についたか」が分かります。
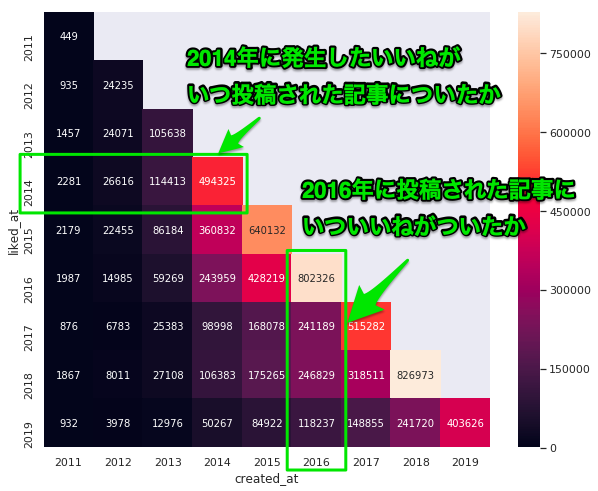
このままだと分かりにくいので各年の1記事あたりいいね数にしてみます。
各年の1記事あたりいいね数(平均いいね数)は以下の通りです。
| 投稿日 | 1記事あたりいいね数 |
|---|---|
| 2011 | 24.1 |
| 2012 | 19.4 |
| 2013 | 27.5 |
| 2014 | 34.2 |
| 2015 | 26.6 |
| 2016 | 20.2 |
| 2017 | 13.4 |
| 2018 | 10.6 |
| 2019 | 6.8 |
2014年は34.2、2018年は10.6で3倍以上の差がありますが、最初の1年のいいね数で見ると...
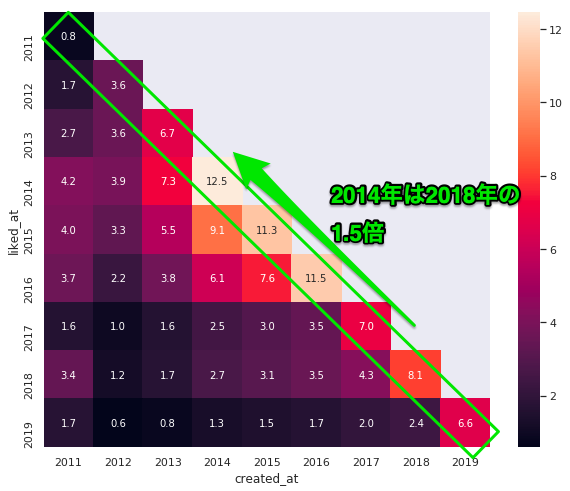
1年目で獲得したいいね数で見ると2014年は12.5、2018年は8.1で1.5倍程度の差になります。
統計値で見ると差があることはわかりましたが、この程度の差だと普段違いを感じることは無いと思います。
「最近はいいねの獲得が難しくなっている」と感じるのは他に何らかの原因がありそうです。
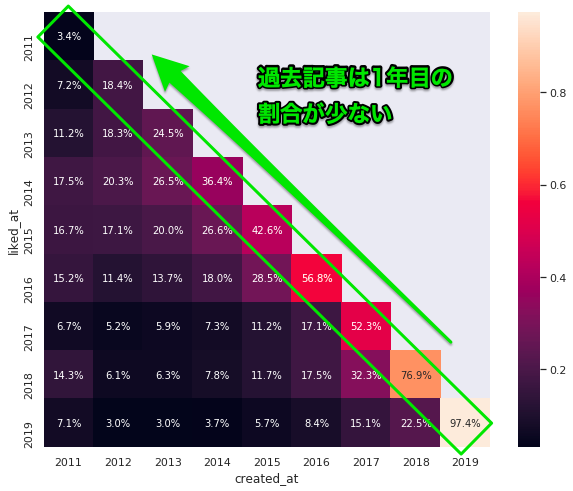
驚愕③ 過去の記事は2年目以降に獲得したいいねの割合が大きい
次は「いついいねされたかの割合」で出してみます。
先ほどと同じように1年目だけ見ると、過去のほうが1年目で獲得した割合が少なくなっています。
逆に言うと、過去の記事は2年目以降に獲得したいいねの割合が大きいということになります。
過去記事のいいね数が大きいのは毎年いいねが積み上げられた結果だということです。
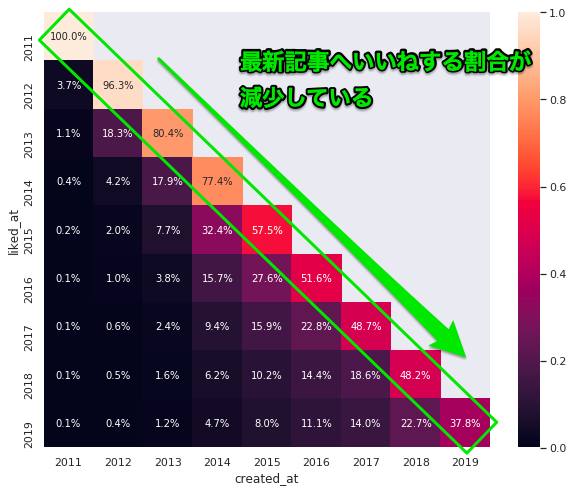
驚愕④ 最近は過去の記事にいいねする割合が増えている
次は「いつ投稿された記事にいいねしたかの割合」をみていきます。
1年目だけ見ると、最近は同年に投稿された記事に対するいいねの割合が減少しています。
つまり、過去の記事にいいねする割合が徐々に増えていることが分かります。
驚愕⑤ いいね総数の6割は1ヶ月以上前の記事に付いている
ここからはいいねが何日前の記事に付いたのかを可視化します。
この期間を以下の区分で分割して割合を見ていきます。
- 0〜1日未満
- 1日〜1週間未満
- 1週間〜1ヶ月未満
- 1ヶ月以上
likes_items["time_delta"] = likes_items.liked_at - likes_items.created_at
def cut_time_delta(df):
return pd.cut(
df.time_delta.dt.days,
bins=[0, 1, 7, 30, 99999],
labels=["1day", "1week", "1month", "1month over"],
right=False,
).value_counts().sort_index()
period_stats = (
likes_items
.groupby(pd.Grouper(key="liked_at", freq="YS"))
.apply(lambda x: cut_time_delta(x) / len(x))
.stack()
.rename("value")
)
sns.heatmap(
period_stats.unstack("time_delta"),
annot=True, fmt=".1%",
yticklabels=yearly_likes_stats.index.year,
)
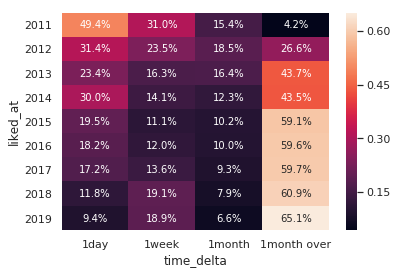
最近は約6割のいいねが1ヶ月以上前の記事に付いています。
これって結構意外な数字ではないでしょうか。もっと最新の記事にいいねが付いていると思っていませんでしたか?
驚愕⑥ 2018年以降トレンドの影響で特定の記事にいいねが偏っている
先ほどの期間の区分ですが、大雑把で無意味な括りのようで実は以下のような意味で区切ってあります。
- 0〜1日未満 : 「タグフィード」や「全ての記事」など最新記事をチェックしていいねが付いたもの
- 1日〜1週間未満 : トレンドからいいねが付いたもの
- 1週間〜1ヶ月未満 : 毎週水曜配信のQiitaニュースからいいねが付いたもの
- 1ヶ月以上 : オーガニック検索やサイト内検索からいいねが付いたもの
これを踏まえて先ほどの表を見るといくつか気づくことがあります。
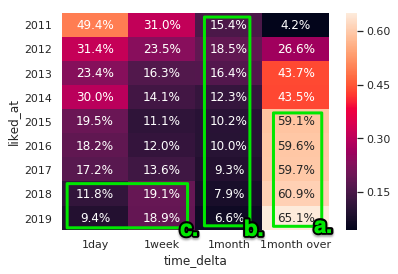
a. 2015年以降検索からのいいねが増えて、以後60%前後で安定。
b. Qiitaニュースからのいいねは減少傾向にある。
c. 2018年以降、最新記事からのいいねとトレンドからのいいねが入れ替わった。
a.の2015年からの変化の原因は何でしょうか?今のところ想像がつきません。
b.の数値が意外です。もう少し多い感覚がありましたが週一なので全体に対する影響は小さかったんですね。
そういえば最近Qiitaニュースに関するアンケートがありましたが、トレンドと差別化できてないこともあり、何らかのテコ入れがありそうです。
c.についてはもう少し詳しく見ていきます。
この期間のいいね(1〜7日前の記事についたいいね)を記事単位で集計し、記事毎のいいね数の分布を出してみます。
いいね数分布の区分は
- 1以上10未満
- 10以上100未満
- 100以上
です。
trend_likes = likes_items[
("1days" <= likes_items.time_delta) &
(likes_items.time_delta < "7days")
]
trend_items = trend_likes.groupby([
pd.Grouper(key="created_at", freq="YS"),
"item_id"
]).liker.count().rename("likes")
trend_likes_dist = (
trend_items.groupby([
"created_at",
pd.cut(trend_items, bins=[1, 10, 100, 99999], right=False)
])
.sum()
.groupby("created_at")
.apply(lambda x: x / x.sum())
.rename("value")
)
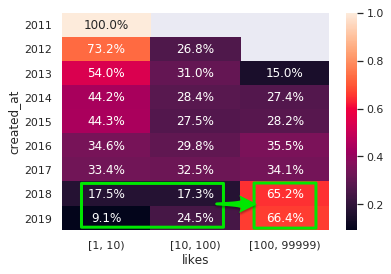
2018年以降、つまりトップページがトレンドになってから以降、いいね数が100件を超える記事が 記事のいいね総数が 倍増しています。
このことから、トレンド導入によって最新記事へのいいねは特定の記事(トレンドに載った記事)に大きく偏っていると考えられます。
「最近はいいねの獲得が難しくなっている」と感じる最大の原因はここにあるのではないでしょうか。
驚愕⑦ Qiiaのトレンドは...
可視化の趣向が違うのと衝撃的な内容なので別記事にします。
おまけ① 初いいねが付くまでの日数
pd.cut(
(likes_items
.groupby("item_id")
.time_delta.min()
.dt.days
),
bins=[0, 1, 7, 30, 365, 99999],
labels=["1day", "1week", "1month", "1year", "1year over"],
right=False,
).value_counts().sort_index() / len(items)
1day 0.539090
1week 0.082175
1month 0.038557
1year 0.098697
1year over 0.028684
約5割の記事は1日以内にいいねが付いています。
1年以上前の記事で現在0いいねでも3%の確率でいいねが付くようなので気長に待ちましょう。
おまけ② 投稿から3分以内のいいね
投稿から3分以内に付いたいいね数が多いユーザーです。
(likes_items[
(likes_items.created_at >= "2018") &
(likes_items.time_delta <= "3minutes")
]
.groupby("author")
.liker.count().rename("quick liked")
.sort_values(ascending=False)
.reset_index()
[:30]
).style.hide_index().format({"author": "@{:s}"})
| author | quick liked |
|---|---|
| @suin | 62 |
| @KanNishida | 45 |
| @kaizen_nagoya | 24 |
| @creaith | 24 |
| @sj-i | 24 |
| @takuya_tsurumi | 23 |
| @tanabee | 19 |
| @reoisym | 18 |
| @takahirom | 16 |
| @ucan-lab | 16 |
| @mizchi | 14 |
| @Hailee | 14 |
| @yoshinori_hisakawa | 14 |
| @kaityo256 | 14 |
| @piacerex | 13 |
| @kyogom | 13 |
| @uhyo | 11 |
| @reoring | 11 |
| @miyumiyu | 11 |
| @shsssskn | 11 |
| @shuhey_fujiwara | 11 |
| @naoya_matsuda | 11 |
| @kahirokunn | 11 |
| @nunulk | 10 |
| @4_mio_11 | 9 |
| @ababup1192 | 9 |
| @nouphet | 8 |
| @superyusuke | 8 |
| @Gaccho | 8 |
| @tatsuya_yamamura | 8 |
QiitaやTwitterでフォロワーが多いユーザーはわからないでもないですが、それ以外は例のOrganizationパワーでしょうかね。
Pandasを使ったデータ分析の実践例 - やはりQiitaアドベントカレンダーの「企業・学校・団体」カテゴリーにはヘビーライカーが多かった
きっと社内Slackでこんなやりとりがあるのかも知れません。
書いた人 「Qiitaに記事書いたで〜 みんな17時までにいいねしてくれやで〜」
いいねした人 「一番乗りでいいねしといたで〜(読んでへんけど)」
書いた人 「無事トレンドに載ったやで〜 ありがとな〜」
いいねした人 「お互い様やで〜 次にワイが書くクソ記事もよろしくやで〜」
書いた人 「任せとき〜 (読まへんけど)」
最後に
いかがでしたか?
いいねした日時を使うことで今まで見えなかったことが色々とわかったと思います。
他にも
- 曜日時間帯別いいね数
- コホート分析
- 短期間だけ注目される記事と長期間愛される記事の違い
- 怪しげないいねの検出
など、今までできなかった色々な分析ができると思います。
データは公開しているので興味のある方はぜひチャレンジしてください。
参考
他のQiita分析記事
以下を参照してください。
Qiitaで起きた出来事
- 2016/06/29頃 人気の投稿ページ(トレンドの前身) https://blog.qiita.com/146688745654-2/
- 2016/11/14頃 いいね導入 https://blog.qiita.com/153200849029-2/
- 2017/11/25頃 トップ画面がトレンドに(β) https://qiita.com/mizchi/items/290973cd1f68fcbe035c
- 2018前後? トップ画面がトレンドに
- 2018/04/19頃 トレンドロジック変更 https://blog.qiita.com/173120067699-2/