
ベガコーポレーション データ戦略部 データ分析基盤エンジニアの武本です。データ基盤関連の記事を書くのも3回目ですね。
今回はデータ連携に特化して書いていきたいと思っています。データの特徴を捉えて、どう取得してくるのかという話になります。
データレイクとは
AWSの説明 によると以下の内容が挙げられています。
- データレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリ
- データをそのままの形で保存できるため、データを構造化しておく必要がない
- ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができる
3つ目の用途の部分が重要だと考えていて、その用途を満たす為の大量のデータ。つまりデータの湖が必要になります。そのデータの湖をデータレイクと呼びます。
データレイクの作り方
データレイクがデータ分析に必要な材料集めとわかったことで、続いてその作り方についてです。
データレイクを作るにはETLツールというExtract (抽出)・Transform (変換)・Load (書き出し)を行うツールが必要になります。
今回はETLツールとしてDigdag、Embulkを使ってBigQueryでデータレイクを構築する手法について記載します。
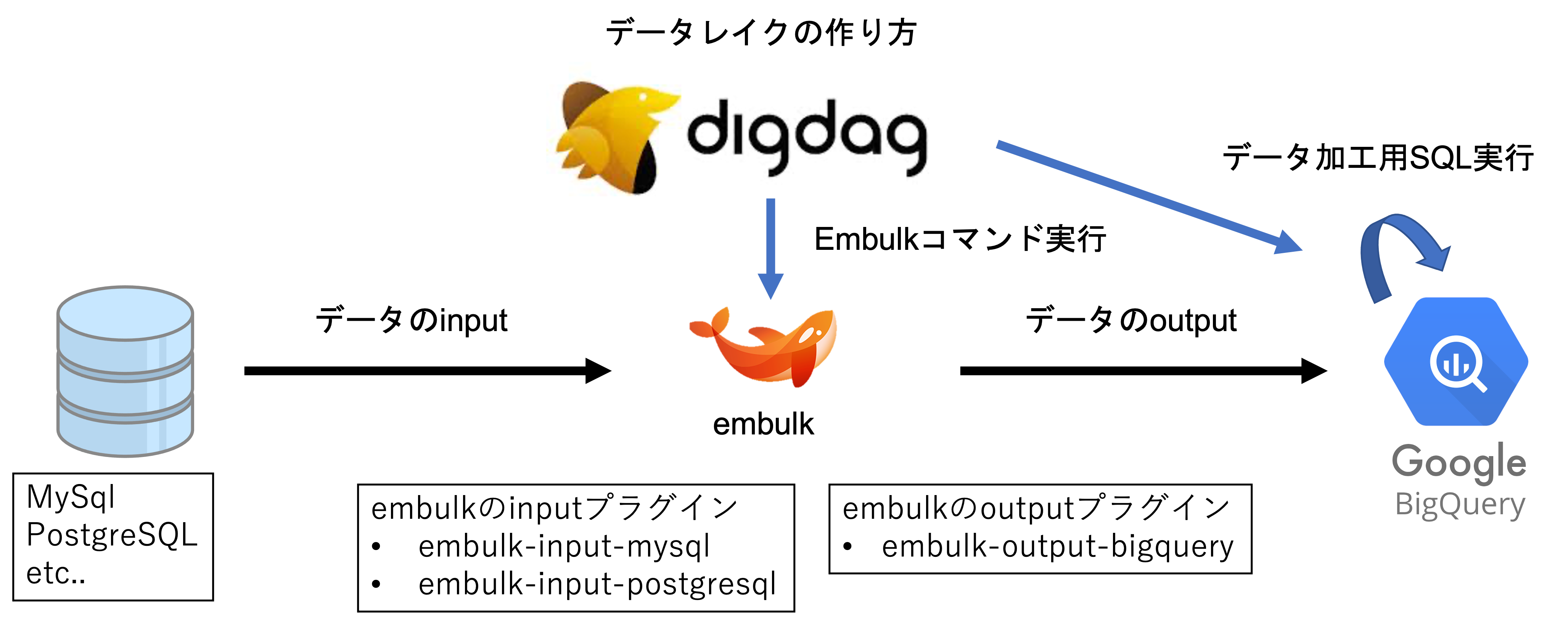
| ツール名 | 役割 |
|---|---|
| Digdag | ワークフローエンジン。今回はバッチスケジューラとして使う。Embulkの実行やBigQueryのクエリ実行を行う |
| Embulk | Extract (抽出)・Load (書き出し)の役割を担うデータ転送ツール |
| BigQuery | データレイクを実現するデータの溜まり場。フルマネージドのサーバーレスデータウェアハウス。弊社ではTransform (変換)もBigQuery上で行っている |
digdag, embulkの使い方については以前書いた記事digdag + embulk データ分析基盤の初期運用をEC2で構築のdigdag + embulkの項目をご覧ください。
データの特徴を捉えたデータ抽出
いよいよ本題です。データレイクの大まかな作り方がわかったところで一つ疑問が湧いて来ないでしょうか?
具体的にどんなデータをどうやって連携するのかという点です。
今回は以下の観点で記載できたらと考えています。
- マスタデータとトランザクションデータ
- 全件取得と差分取得
- データ抽出の方法
- 最新レコード抽出
- BigQuery Partitionテーブル
- マスタデータの履歴テーブル
マスタデータとトランザクションデータ
マスタデータは商品データなどの固定的なデータ、トランザクションは受注データなど流動的なデータと捉えることが多く概ねその認識であっています。
但し商品も日々追加・更新される為、境界線が曖昧な部分があります。
そこでデータレイクという観点で意識したいことは全件取得するのか、差分取得するのかという違いです。
具体的には 全件取得・差分取得 にて記載します。
全件取得と差分取得
全件取得と差分取得の違いを端的に言うと、実装の手軽さ・実行コスト・品質管理コストの3点になります。
システム運用においては、
- 保守性
- コスト
- 品質
のバランスを取ることが求められますが、データエンジニアリングにおいても同じことが言えます。
それが先ほど挙げた実装の手軽さ・実行コスト・品質管理コストの3点です。
この観点で全件取得と差分取得を比較すると、
| 全件 | 差分 | |
|---|---|---|
| 実装の手軽さ | 簡潔 | 複雑 |
| 実行コスト(DBやサーバへの負荷) | 高い | 低い |
| 品質管理コスト(重複・欠損リスク) | 低い | 高い |
となります。
また、マスタテーブルとトランザクションテーブルの性質を比較すると
| マスタ | トランザクション | |
|---|---|---|
| レコード数増分 | 少ない | 多い |
| UPDATE | すべてのレコードが対象 | 一定期間経過したレコードは対象外 |
| DELETE | ありうる | 基本的にない |
したがって基本的な考え方は
| 方法 | 理由 | |
|---|---|---|
| マスタ | 全件取得 | レコード数が少なく、どのレコードが更新されるかわからない為 |
| トランザクション | 差分取得 | レコード数が多く、更新されないレコードを対象から除きたい為 |
となります。
ただし、
- レコード数が大きすぎるマスタテーブルは実行コストを優先して差分取得
- 現時点でレコード数・増分とも少ないトランザクションテーブルは実装の手軽さを優先して全件取得
といった例外的な対応をする場合もあります。
データ抽出の方法
全件取得・差分取得両方に対応したmysql用のembulkファイルをご紹介します。
in:
type: mysql
host: {{env.HOST}}
user: {{env.USER}}
password: {{env.PASSWORD}}
database: {{env.DATABASE}}
table: {{env.EMBULK_INPUT_TABLE}}
select: "{{env.SELECT}}"
{% if env.WHERE != '' %}
where: "{{env.WHERE}}"
{% endif %}
ssl: {{env.SSL}}
options:
useLegacyDatetimeCode: false
serverTimezone: {{env.DEFAULT_TIMEZONE}}
connectTimeout: 7200000
socketTimeout: 7200000
{% if env.SSL == 'true' %}
enabledTLSProtocols: TLSv1.2
{% endif %}
column_options: {{env.IN_COLUMN_OPTION}}
default_timezone: "{{env.DEFAULT_TIMEZONE}}"
out:
type: bigquery
mode: {{env.MODE}}
auth_method: service_account
json_keyfile:
content: |
{
"private_key_id": "{{ env.GCP_PRIVATE_KEY_ID }}",
"private_key": "{{ env.GCP_PRIVATE_KEY }}",
"client_email": "{{ env.GCP_CLIENT_EMAIL }}"
}
path_prefix: /tmp/
file_ext: .csv.gz
source_format: CSV
project: {{env.GCP_PROJECT_ID}}
dataset: {{env.DESTINATION_DATESET}}
location: asia-northeast1
table: {{env.EMBULK_OUTPUT_TABLE}}
auto_create_table: true
{% if env.SCHEMA_FILE_PATH != '' %}
schema_file: {{env.SCHEMA_FILE_PATH}}
{% endif %}
formatter: {type: csv, charset: UTF-8, delimiter: ",", header_line: false}
allow_quoted_newlines: TRUE
default_timezone: "{{env.DEFAULT_TIMEZONE}}"
column_options:
- {{env.OUT_COLUMN_OPTION}}
{% if env.PARTITION_FIELD != '' %}
time_partitioning:
type: MONTH
field: {{env.PARTITION_FIELD}}
{% endif %}
encoders:
- {type: gzip}
全件取得 or 差分取得に関係ある項目はinputのwhereとoutputのmodeの部分です。
| where | mode | |
|---|---|---|
| 全件取得 | “” | replace |
| 差分取得 | “DATE_FORMAT(updated_at, ‘%Y-%m-%d’) BETWEEN ‘{取得開始日}’ AND ‘{取得終了日}’“ | append |
全件取得の場合はWhereの指定なし、modeをreplaceにすることで全件データの置き換えを行います。
対して、差分更新の場合はWhereの指定を行い、modeをappendにすることで更新されたデータのみの取得を行います。
最新レコード抽出
最新レコードとは何かの前に、なぜ全件取得の方が品質管理コストが低いのか説明します。
DELETEされたレコードの検知が難しいという点もありますが、BigQueryの場合データが重複してしまうという問題点があることです。
BigQueryのデータ更新は基本的にWRITE_TRUNCATEもしくはWRITE_APPENDで行います。つまりUPDATEという概念がありません。基本的にと記載したのはデータ操作言語(DML)でUPDATEすることは可能ですが料金が高めに設定されている為、ETLツールに組み込むには向いていません。
差分更新(WRITE_APPEND)した場合の欠点ですが、それは更新前のデータが残ってしまうという点です。
| id | price | updated_at |
|---|---|---|
| 1 | 200 | 2022-07-20 13:47:33 |
↓ データ更新後、再度データ取得
| id | price | updated_at |
|---|---|---|
| 1 | 200 | 2022-07-20 13:47:33 |
| 1 | 300 | 2022-07-25 14:17:33 |
このようにpriceの更新があった場合、BigQuery側にはappendにしている都合上過去のレコードが残ってしまいます。
これを解決する為に最新レコードの抽出を行います。
SELECT
*
FROM
`{project_id}.{dataset_id}.{table_id}`
QUALIFY
ROW_NUMBER() OVER(PARTITION BY id ORDER BY updated_at DESC) = 1
PARTITION BYにPRIMARY KEY、 ORDER BYにupdated_at DESCを指定することでレコードを最新順に並べることができます。並べたレコードから先頭のみを抽出することで最新のレコードのみを取得することが可能になります。
その結果をテーブルとしてLoad (書き出し)することで最新レコード抽出を行っています。
このように差分更新の場合はレコード抽出という作業が必要になる為、弊社では全件取得できる場合は全件取得するようにしています。
BigQuery Partitionテーブル
BigQueryでは分割テーブルを用いることでクエリコストを下げることができます。
その設定としてデータ抽出の方法で挙げたembulkファイルにpartitionという項目を追加しています。
time_partitioning:
type: MONTH
field: {{env.PARTITION_FIELD}}
typeに分割範囲、fieldにカラムを指定することで分割を実現します。
分割数には4000個のパーティションという制限がある為、4000日制限のDAYではなく、4000ヶ月制限のMONTHを採用しています。
マスタデータの履歴テーブル
全件replace取得の欠点もあります。更新前のデータが残らないという事象です。
差分更新の際のデータをreplaceで取得した場合、id: 1が元々200円 だったというデータが残らないことになります。
| id | price | updated_at |
|---|---|---|
| 1 | 200 | 2022-07-20 13:47:33 |
↓ データ更新後、再度replace取得
| id | price | updated_at |
|---|---|---|
| 1 | 300 | 2022-07-25 14:17:33 |
以下のデータは残らない。
| id | price | updated_at |
|---|---|---|
| 1 | 200 | 2022-07-20 13:47:33 |
そういったデータ更新の履歴を残す為に全件append取得を行います。
in:
select: CURRENT_DATE(), id, price, updated_at
out:
mode: append
selectに取得日とその他取得したいカラム、modeにappendを指定することでマスタデータを履歴的に残すことが可能になります。
まとめ
今回はデータレイクの作り方というタイトルでデータ連携方法について記載しました。
最新レコードの抽出やマスタデータの履歴テーブルの話に関しては参考記事も少なく試行錯誤して実装しました。他にもっと良いやり方があるのかもしれませんが、弊社ではこのように運用していますという紹介として少しでも参考になればと思っています。
ご感想やご意見ありましたらコメントの程よろしくお願いします!