はじめに
ディープラーニング勉強の一環として、GAN(敵対的生成ネットワーク)を使った手書き文字の生成にチャレンジしてみました。
- ディープラーニングよく分からないけど画像生成に興味ある
- 機械学習とか勉強してみてGANに興味あるけど、難しそうで手を出せない
- PytorchでGANを実装してみたい
という方の参考になれば嬉しいです。
※詳しい理論の説明はしていません。参考となるリンクをいくつか載せているので、必要な場合はそちらを参照してください。

↑最終的にこんな感じで文字生成することができました。
環境
簡単に、私が実行した環境を記載しておきます。
- 言語:python
- DeepLearning用ライブラリ:Pytorch
- 環境:GoogleColaboratory
- 使用するデータ:MNIST(0~9の数字の手書き文字データ)
- モデル:CGAN(ConditionalGAN) ※GANの1種
GoogleColabは無料でGPUを使用できるクラウド環境です。
高性能なPCがなくてもディープラーニングを試すことができるのでおすすめです。
【参考】Google Colaboratoryで初めての機械学習
GAN(敵対的生成ネットワーク)とは
GANはディープラーニングのモデルのうち、生成モデルと呼ばれるモデルの1種です。
画像生成や文章生成などに使われており、特に画像については本物と見間違えるほどの物を作成しているモデルもあります。

↑の画像はGANで作られた架空の部屋の画像です。
もはや本物の画像にしか見えないレベル。
GANの概要
GANの詳しい仕組みについては割愛しますが、イメージのために概要だけ簡単に説明します。
GANには2人の登場人物がいます。
- Generator(生成者):偽物を作る人。
- Discriminator(判別者):偽物か本物かを判別する人。
GANでは、この2人が戦うことでよりよい画像を生成することを目指します。
生成者は判別者に見破られないように何度も試行錯誤してよい画像を生成しようとし、判別者は生成者に騙されないようにどんどん目利きが上手くなろうとします。


↑某少年漫画で例えると、左の贋作を作る人がGenerator(生成者)で右の目利きする人がDiscriminator(判別者)です。
CGAN(ConditionalGAN)とは
GANには色々な種類があるのですが、今回はConditionalGAN(条件付きGAN)というモデルを使います。
ConditionalGANはただ生成するだけでなく、どれを生成するのかを指定することができるという特徴があります。
今回のように手書き数字を学習させる場合、通常のGANだと「数字」というざっくりした生成しかできないのですが、CGANの場合は「0」とか「1」とか具体的な数字を指定して生成することができます。
通常のGANよりも手順は少し複雑なのですが、実際にそれぞれの数字がどのように生成されているのかを見たかったのでこちらのモデルを選びました。
【参考】今さら聞けないGAN(6) Conditional GANの実装
学習の準備
最初に必要なライブラリをインポートします。
また、後で生成した画像を保存するためにGoogleDriveをマウントしておきます。
※GoogleColabを使わない方は、マウント不要です。
# ライブラリのインポート
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
import torch
import torchvision
import torch.nn as nn
import torch.nn.init as init
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.datasets as dset
import torchvision.utils as vutils
import os
import random
import time
# GoogleDriveのマウント
from google.colab import drive
drive.mount('/content/gdrive')
# フォルダの移動
cd /content/gdrive/My Drive/Colab Notebooks/MNIST_CGAN
# 保存するフォルダを指定&作成
outf = './result_lsgan'
try:
os.makedirs(outf, exist_ok=True)
except OSError as error:
print(error)
pass
パラメータの定義
モデルで使用するパラメータを先に決めておきます。
# 設定
nz = 100 #画像を生成するための特徴マップの次元数
nch_g = 64 #Generatorの最終層の入力チャネル数
nch_d = 64 #Discriminatorの先頭層の出力チャネル数
workers = 2 #データロードに使用するコア数
batch_size=50 #バッチサイズ
n_epoch = 30 #エポック数(繰り返し学習する回数)
lr = 0.0002 #学習率
beta1 = 0.5 #最適化関数に使用するパラメータ
display_interval = 100 #学習経過を表示するスパン
# 乱数のシード(種)を固定
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
データセットの読み込み
学習に使用するMNISTデータセットを読み込みます。
Pytorchの場合、モデルに学習させるためにdataloaderという形式にしておく必要があります。
2019/7/16追記
デバイスの定義が抜けていたので追記しました。
# MNISTのトレーニングデータセットを読み込む
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))])
dataset = torchvision.datasets.MNIST(root='mnist_root',
train=True,
download=True,
transform=transform)
# データローダーを作成する
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=int(workers))
# 学習に使用するデバイスを得る。可能ならGPUを使用する
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)
MNISTデータセットは、計6万件の手書き文字画像です。
以下のようなデータが入っています。
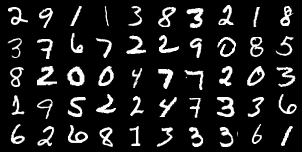
モデルの作成
学習させるモデルを作っていきます。
Generator(生成者)の定義
偽物を作る側のモデルを定義します。
入力と出力の形式は以下の通りです。
- 入力:(バッチサイズ, チャネル数, 高さ, 横幅) = (50, 100, 1, 1)
- 出力:(バッチサイズ, チャネル数, 高さ, 横幅) = (50, 1, 28, 28)
MNISTのデータは28×28ピクセルの画像なので、Generatorモデルの出力はそれに合うように徐々に高さと横幅を広くしています。
白黒画像なのでチャネル数は1です。
以下を1固まりとして、層を積み重ねていきます。
- ConvTranspose2d(転置畳み込み層):入力のサイズ(高さと横幅)を大きくするために使います。
- BatchNorm2d(バッチ正規化層):学習安定化のために使っています。
- ReLU(活性化関数)
転置畳み込み層のstrideやpaddingの決め方については、以下を参考にさせていただきました。
層間で出力と入力を合わせる必要があるのが少し面倒でした。
PyTorchでのConvTranspose2dのパラメーター設定について
class Generator(nn.Module):
def __init__(self, nz=100, nch_g=64, nch=1): #nzは入力ベクトルzの次元
super(Generator, self).__init__()
#ネットワーク構造の定義
self.layers = nn.ModuleList([
nn.Sequential(
nn.ConvTranspose2d(nz, nch_g * 8, kernel_size=2, stride=1 ,padding=0), #高さ1×横幅1 → 高さ2×横幅2
nn.BatchNorm2d(nch_g * 8),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 8, nch_g * 4, kernel_size=4, stride=2 ,padding=1), #2×2 → 4×4
nn.BatchNorm2d(nch_g * 4),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 4, nch_g * 2, kernel_size=4, stride=2 ,padding=1), #4×4 → 8×8
nn.BatchNorm2d(nch_g * 2),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 2, nch_g,kernel_size=2, stride=2, padding=1), #8×8 → 14×14
nn.BatchNorm2d(nch_g),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g, nch,kernel_size=4, stride=2, padding=1),#14×14 →28×28
nn.Tanh()
),
])
#順伝播の定義
def forward(self, z):
for layer in self.layers: #layersの各層で演算を行う
z = layer(z)
return z
Discriminator(判別者)の定義
偽物と本物を見分けるモデルを定義します。
入力と出力の形式は以下です。
- 入力:(バッチサイズ, チャネル数, 高さ, 横幅) = (50, 1, 28, 28)
- 出力:(バッチサイズ, チャネル数, 高さ, 横幅) = (50, 1, 1, 1)
入力として28×28の画像を受け取って、偽物か本物かを予測する数値を返します。
class Discriminator(nn.Module):
def __init__(self, nch=1, nch_d=64): #nchは入力のチャンネル数
super(Discriminator, self).__init__()
#ニューラルネットワークの構造を定義
self.layers = nn.ModuleList([
nn.Sequential(
nn.Conv2d(nch, nch_d*2, kernel_size=3, stride=3 ,padding=0), #28×28 → 7×7
nn.LeakyReLU(negative_slope=0.2)
),
nn.Sequential(
nn.Conv2d(nch_d*2, nch_d*4,kernel_size=3, stride=1 ,padding=1) ,#7×7 → 7×7
nn.BatchNorm2d(nch_d*4),
nn.LeakyReLU(negative_slope=0.2)
),
nn.Sequential(
nn.Conv2d(nch_d*4, nch_d*8,kernel_size=3, stride=3 ,padding=1), #7×7 → 3×3
nn.BatchNorm2d(nch_d*8),
nn.LeakyReLU(negative_slope=0.2)
),
nn.Conv2d(nch_d*8, 1, kernel_size=3, stride=1 ,padding=0)
])
#順伝播の定義
def forward(self,x): #xは本物画像or贋作画像
for layer in self.layers: #各層で演算を行う
x = layer(x)
return x.squeeze() #不要な次元を削除
定義したモデルを作成
上で定義した通りに2つのモデルを作成します。
また、重みの初期化を学習時に行うので、その関数も定義しておきます。
# 重みを初期化する関数を定義
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1: # 畳み込み層の場合
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif classname.find('Linear') != -1: # 全結合層の場合
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif classname.find('BatchNorm') != -1: # バッチ正規化の場合
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
# Generatorの作成
netG = Generator(nz=nz+10, nch_g=nch_g).to(device) #10はn_class=10を指す。出し分けに必要なラベル情報。
netG.apply(weights_init)
print(netG)
# Discriminatorの作成
netD = Discriminator(nch=1+10, nch_d=nch_d).to(device) #10はn_class=10を指す。分類に必要なラベル情報。
netD.apply(weights_init)
print(netD)
ラベル学習のための関数を定義
CGANを使って数字の出し分けをしたいので、各画像がどの数字を指すかを表すラベルも学習させる必要があります。
その学習に必要な関数を定義します。
また、あとでラベルごとの数字を生成するためのノイズ(Generatorの入力)を作成しておきます。
# Onehotエンコーディング
def onehot_encode(label,device, n_class=10):
eye = torch.eye(n_class, device=device)
return eye[label].view(-1, n_class, 1, 1) #連結するために(Batchsize,n_class,1,1)のTensorにして戻す
# 画像とラベルを連結する
def concat_image_label(image, label, device, n_class=10):
B,C,H,W = image.shape #画像Tensorの大きさを取得
oh_label = onehot_encode(label, device) #ラベルをOne-hotベクトル化
oh_label = oh_label.expand(B, n_class, H, W) #画像のサイズに合わせるようラベルを拡張
return torch.cat((image, oh_label), dim=1,) #画像とラベルをチャンネル方向(dim=1)で連結する
# ノイズとラベルを連結する
def concat_noise_label(noise, label, device):
oh_label = onehot_encode(label, device)
return torch.cat((noise, oh_label), dim=1)
# 画像確認用のノイズとラベルを設定
fixed_noise = torch.randn(batch_size, nz, 1, 1, device=device) #ノイズの生成
fixed_label = [i for i in range(10)] * (batch_size // 10) #0~9の値の繰り返す(5回)
fixed_label = torch.tensor(fixed_label, dtype=torch.long, device=device) #torch.longはint64を指す
fixed_noise_label = concat_noise_label(fixed_noise, fixed_label, device) #確認用のノイズとラベルを連結
損失関数・最適化関数の定義
- 損失関数:モデル学習時の指標。この損失を少なくすることを目指す。
- 最適化関数:どのように損失を下げていくかを決める。
損失関数は、LSGANを参考にしてMSELossを使用しています。勾配消失を起きにくくなり、学習安定化の効果があるようです。
最適化関数には、GANで適していると言われているAdamを使用しています。
【参考】GAN(Generative Adversarial Networks)を学習させる際の14のテクニック
# 損失関数
criterion = nn.MSELoss() #二乗誤差損失
# 最適化関数
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5)
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5)
学習状況を可視化するための関数を定義
きちんと学習できるかを確認するための、グラフを作成する関数を定義しておきます。
後ほど、「1エポック内の学習状況の可視化」と「学習状況全体の可視化」の2パターンを行います。
# エポックごとのlossを可視化
def plot_loss (G_losses, D_losses, epoch):
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss - EPOCH "+ str(epoch))
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 全体でのlossを可視化
def plot_loss_average (G_loss_mean, D_loss_mean):
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss - EPOCH ")
plt.plot(G_loss_mean,label="G")
plt.plot(D_loss_mean,label="D")
plt.xlabel("EPOCH")
plt.ylabel("Loss")
plt.legend()
plt.show()
モデルの学習
準備が整ったので、実際に学習していきます。
G_loss_mean = [] #学習全体でのlossを格納するリスト(generator)
D_loss_mean = []
epoch_time = [] #時間の計測結果を格納するリスト
for epoch in range(n_epoch):
start = time.time() #時間の計測を開始
G_losses = [] #1エポックごとのlossを格納するリスト(Generator)
D_losses = []
for itr, data in enumerate(dataloader):
#本物画像のロード
real_image = data[0].to(device) #本物画像をロード
real_label = data[1].to(device) #本物画像のラベルとロード
real_image_label = concat_image_label(real_image, real_label, device) #画像とラベルを連結
#贋作画像生成用のノイズとラベルを準備
sample_size = real_image.size(0) #0は1次元目(バッチ数)を指す
noise = torch.randn(sample_size, nz, 1 ,1, device=device)
fake_label = torch.randint(10, (sample_size,), dtype=torch.long, device=device)
fake_noise_label = concat_noise_label(noise, fake_label, device) #ノイズとラベルを連結
#識別の目標値を設定
real_target = torch.full((sample_size,), 1., device=device) #本物は1
fake_target = torch.full((sample_size,), 0., device=device) #偽物は0
#Discriminator(判別器)の更新
netD.zero_grad() #勾配の初期化
output = netD(real_image_label) #順伝播させて出力(分類結果)を計算
errD_real = criterion(output, real_target) #本物画像に対する損失値
D_x = output.mean().item()
fake_image = netG(fake_noise_label) #生成器Gで贋作画像を生成
fake_image_label = concat_image_label(fake_image, fake_label, device) #贋作画像とラベルを連結
output = netD(fake_image_label.detach()) #判別器Dで贋作画像とラベルの組み合わせに対する識別信号を出力
errD_fake = criterion(output, fake_target) #偽物画像に対する損失値
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake #Dの損失の合計
errD.backward() #誤差逆伝播
optimizerD.step() #Dのパラメータを更新
#Generator(生成器)の更新
netG.zero_grad()
output = netD(fake_image_label) #更新した判別器で改めて判別結果を出力
errG = criterion(output, real_target) #贋作画像を本物と誤認させたいので、目標値はreal_targetの1
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
# lossの保存
G_losses.append(errG.item())
D_losses.append(errD.item())
#学習経過の表示
if itr % display_interval == 0:
print('[{}/{}][{}/{}] Loss_D: {:.3f} Loss_G: {:.3f} D(x): {:.3f} D(G(z)): {:.3f}/{:.3f}'
.format(epoch + 1, n_epoch,
itr + 1, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
if epoch == 0 and itr == 0:
vutils.save_image(real_image, '{}/real_samples.png'.format(outf),
normalize=True, nrow=10)
#確認用画像の生成(1エポックごと)
fake_image = netG(fixed_noise_label)
vutils.save_image(fake_image.detach(), '{}/fake_samples_epoch_{:03d}.png'.format(outf, epoch + 1),
normalize=True, nrow=10)
#lossの平均を格納
G_loss_mean.append(sum(G_losses) / len(G_losses))
D_loss_mean.append(sum(D_losses) / len(D_losses))
#lossのプロット
plot_loss (G_losses, D_losses, epoch)
#1エポックごとの時間を記録
epoch_time.append(time.time()- start)
# 学習全体の状況をグラフ化
plot_loss_average(G_loss_mean, D_loss_mean)
生成した画像を見てみる
実際に生成された画像を見てみます。(冒頭で指定したフォルダに作成されます。)
エポック5あたりですでに本物画像にかなり近くなっています。
それ以降は大きな変化はありませんが、最終結果のエポック30ではより鮮明になっているように感じます。
GIF(Epoch 1 ~ 30)
画像
Epoch 1

Epoch 3

Epoch 5
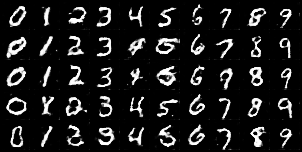
Epoch 10

Epoch 15

Epoch 30

(比較)本物の画像

かなり本物と似たような文字が生成できているのではないでしょうか。
学習状況をグラフ化
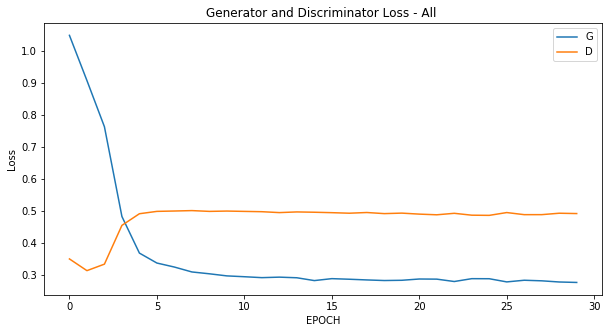
実際にどのように学習が進んだかを見てみましょう。
学習全体でのLossの推移を見れば分かる通り、最初はGeneratorのLossが大きい状態(Discriminatorに見破られている)状態になっています。
ただ、エポックを経るごとに段々とGeneratorのLossが減っていき、エポック4あたりから状況が逆転してDiscriminatorのLossが上回っていることが分かります。
つまりGeneratorが上手な偽物を作れるようになり、Discriminatorを騙せるようになったことが分かります。
画像の精度が高くなっていたのもエポック5あたりだったので、概ね合致しています。
エポック10~30の間は殆ど同じようなグラフで、Generatorが上手くDiscriminatorを騙し続けている状態でした。
学習全体のLoss推移
各エポック内のLoss推移
Epoch 1
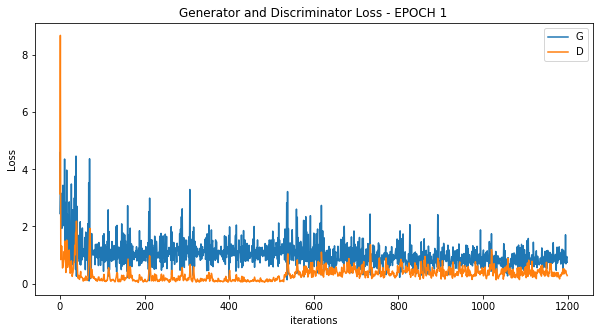
Epoch 5
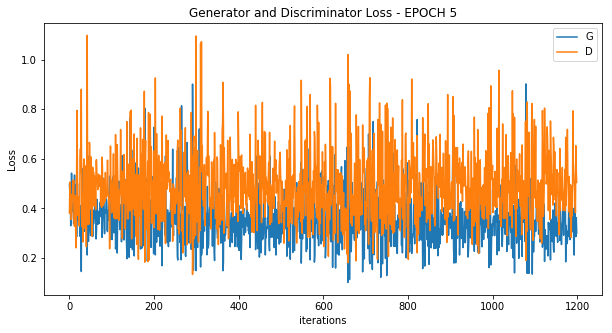
Epoch 10
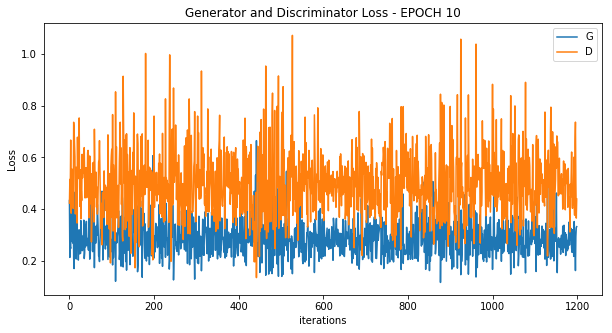
Epoch 30
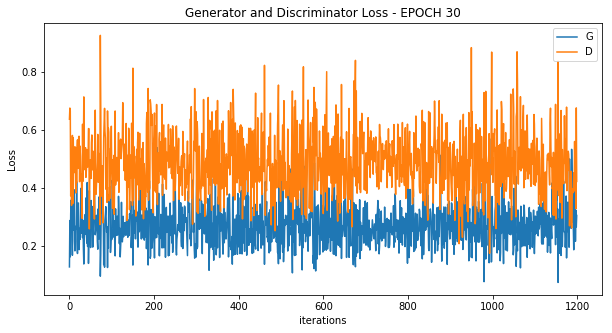
今回はGeneratorのLossが上手く下がっていますが、場合によってはDiscriminatorが優秀すぎて学習が上手く進まないこともあります。
※同じモデルも流すたびに結果が変わってくることもあるので、上手くいかない場合は何度かやってみるといいかもしれません。
まとめ
今回はCGANを使って文字生成をしてみました。
GANは学習が難しいという前評判通り、ちょっとモデルに変化を加えると上手くいかなかったりと結構苦労しました。
ただ、最終的には思ったよりも手書き文字らしきものが作れて驚いています。
今後はより難しい画像とかにチャレンジしていけたらなと思います。
参考文献・サイト
最後に参考にさせていただいた本やサイト等をまとめて載せておきます。
【Pytorch】
Pytorch ニューラルネットワーク 実装ハンドブック
→今回紹介したコードの元になっています。Pytorch本は貴重なので重宝しています。
【GAN】
今さら聞けないGAN(1) 基本構造の理解
今さら聞けないGAN(6) Conditional GANの実装
LSGAN(論文) →冒頭で紹介した架空の部屋画像を生成したのがLSGANです。
【GAN学習のテクニック】
PyTorchでのConvTranspose2dのパラメーター設定について
GANで学習がうまくいかないときに見るべき資料
GAN(Generative Adversarial Networks)を学習させる際の14のテクニック
【その他】
GoogleColab 解説記事