本記事では、データサイエンティスト、AIエンジニアの方がPythonでプログラムを実装する際に気をつけたいポイント、コツ、ノウハウを私なりにまとめています。
AIエンジニア向け記事シリーズの一覧
その1. AIエンジニアが気をつけたいPython実装のノウハウ・コツまとめ(本記事)
その2. AIエンジニアが知っておきたいAI新ビジネス立案のノウハウ・コツまとめ
2020年4月に書籍を、出版しました。
【書籍】
AIエンジニアを目指す人のための機械学習入門 実装しながらアルゴリズムの流れを学ぶ(電通国際情報サービス 清水琢也、小川雄太郎 、技術評論社)
https://www.amazon.co.jp/dp/4297112094/
本投稿は、上記の書籍に書ききれなかった
「AIエンジニアが、Pythonでプログラムを実装する際に気をつけたいことのまとめ」
です。
本記事の内容は、あくまで筆者が意識しているポイントです。
これが唯一の答えというわけではありませんが、みなさまの参考になれば幸いです。
はじめに本記事の内容を示します。
その後、各内容の解説を記載します。
AIエンジニアが気をつけたいPython実装のポイント
レベル1
1.1 変数、関数、クラス、メソッドの命名規則を守る
1.2 命名方法1:変数名やメソッド名から冗長な部分を除く
1.3 importの記載はルールに従う
1.4 乱数のシードを固定して、再現性を担保する
1.5 プログラムは関数化して実行する
レベル2
2.1 命名方法2:reverse notation(逆記法)で命名し、読み取りやすくする
2.2 SOLIDのSを意識し、関数、メソッドが単一責務で短い内容にする
2.3 関数、メソッドには型ヒントをつける
2.4 クラス、メソッド、関数にはdocstringを記載する
2.5 学習済みモデルの保存時に、前処理やハイパーパラメータなどの情報を一緒に保存する
レベル3
3.1 命名方法3:適切な英単語と品詞で、責務が分かる名前をつける
3.2 適切に例外処理を実装する
3.3 適切にログを実装する
3.4 関数、メソッドの引数は3つ以下にする
3.5 *args、**kwargsを適切に使う
レベル4
4.1 三項演算子でif文を短く書く
4.2 sklearn準拠で、前処理およびモデルのクラスを実装する
4.3 デコレータを適切に活用する
4.4 チーム開発用にエディターの設定を統一する
4.5 GitHubのプルリクエスト用templateを準備し注意点を記載しておく
解説
レベル1
1.1 変数、関数、クラス、メソッドの命名規則を守る
関数名や変数名の付け方は悩みどころです。
命名方法も重要ですが、まずルールとしての命名規則を守ります。
(命名規則は「PEP8: Pythonコードのスタイルガイド」として案内されています)
●変数、関数、メソッド、モジュール
⇒小文字のみ、必要に応じて単語をアンダースコアで区切る
例 lower_case_with_underscores
●クラス名
⇒先頭だけ大文字の単語を繋げる、アンダースコアは使わない
例 CapWords
●クラス内のみで使用されるプライベート変数
⇒変数名の前にアンダースコア
例 _single_leading_underscores
「クラス内のみで使用されるプライベートメソッド」
⇒メソッド名の前にアンダースコア
例 _single_leading_underscore(self, ...)
●定数
⇒大文字のみ、単語をアンダースコアで区切る
例 ALL_CAPS_WITH_UNDERSCORES
●パッケージ名
⇒小文字のみ
例 lowers
※備考1:関数とメソッドの違い
関数はクラス内にはない独立した手続き。メソッドはクラス内にある関数を示します。
※備考2:モジュールとパッケージ
パッケージは一番大きなトップレベル。モジュールはパッケージ内のファイルです。
例えば、sklearnはパッケージです。sklearn.linear_modelのlinear_modelはモジュールです。
1.2 命名方法1:変数名やメソッド名から冗長な部分を除く
例えばクラスclass_1に、変数max_lengthを持たせる場合、メンバ変数の名前は
class_1_max_lengthとはせず、単純にmax_lengthにします。
というのも、他のクラスからこのクラス変数にアクセスする際に、
class_1.class_1_max_length = 10
のように、クラス名が冗長になるからです。
class_1.max_length = 10
となる方が良いです。
メンバ変数は使用されるときに、「クラス名.変数名」になることを想像して命名します。
1.3 importの記載はルールに従う
外部クラスや関数をimportする際に気をつける3点を案内します。
●importを記載する順番
以下のように3タイプのライブラリを空白行で区切って記載します。
import 標準ライブラリ
空白行
import サードパーティに関連するもの(PyPIからpip installしたもの)
空白行
import 自分たちが今回用に作成したもの`
空白行
●importの記載の仕方
モジュールをまるごとimportします。
例えば、パッケージpkgのモジュールmodule_1のクラスclass_1があった場合に、
from pkg.module_1 import class_1
とはせず、
from pkg import module_1
として、
プログラム内では、例えば
my_class = module_1.class_1()
と、モジュールレベルで使用します。
●importの記載の仕方2
importで複数のパッケージをimportしません。
import pkg, pkg2
とはせず、
import pkg import pkg2
と記載します。
ただし、モジュールの場合の複数記載はOKです。
例えば以下。
from pkg import module_1, module_2
※備考
私もimportの仕方は結構適当なところがあります。
良くないですね。
Autoformatterやその他ツールでimport文の記載を直してくれるので、それらを活用するのもおすすめです。
1.4 乱数のシードを固定して、再現性を担保する
データサイエンス、AIの実装時にはランダムな部分が多いので、乱数のシードは必ず固定し、プログラムの再現性を担保します。
実装例は次の通りです。
import os
import random
import numpy as np
import torch
SEED_VALUE = 1234 # これはなんでも良い
os.environ['PYTHONHASHSEED'] = str(SEED_VALUE)
random.seed(SEED_VALUE)
np.random.seed(SEED_VALUE)
torch.manual_seed(SEED_VALUE) # PyTorchを使う場合
ただし、PyTorchでGPUを使用する場合はさらに、
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
を、設定します。これらを設定しないと、GPU利用時には再現性を担保できません。
ですが、torch.backends.cudnn.deterministic = Trueは、GPUでの計算速度を下げてしまいます。
そのため私の場合、実行速度を優先し、GPUでの学習の再現性の担保までは求めないです。
なおPyTorchでの再現性確保の手続きについてはこちらが詳しいです。
PyTorch REPRODUCIBILITY
また、scikit-learnの場合は各アルゴリズムで乱数シードを受け取る部分もあるので、こちらも固定します。
例:scikit-learn
from sklearn.linear_model import LogisticRegression
SEED_VALUE = 1234 # これはなんでも良い
clf = LogisticRegression(random_state=SEED_VALUE)
1.5 プログラムは関数化して実行する
Jupyter NotebookでもPythonのコマンドライン実行でも、関数化されていないプログラムは実行速度が遅くなります。
例えば、Google Colaboratoryで、
import time
import numpy as np
start = time.time()
data = np.random.rand(5000)
sum = 0
for i in range(len(data)):
for j in range(len(data)):
sum += data[j]
elapsed_time = time.time() - start
print(elapsed_time)
を実行すると、8.4秒かかりました。
これは1つのセルにプログラムをべた書きして実行している状態です。
同じように1つのセルで実行するのですが、メインのfor文の周りを関数化して実行してみます。
import time
import numpy as np
def main():
data = np.random.rand(5000)
sum = 0
for i in range(len(data)):
for j in range(len(data)):
sum += data[j]
return 0
start = time.time()
main()
elapsed_time = time.time() - start
print(elapsed_time)
この結果は6.2秒です。8秒かかったものが6秒になりました。
このようにJupyter Notebookで実行するにしても、長い時間がかかる処理をべた書きで実行するのではなく、main()のような関数にして、その関数を実行するようにします。
コマンドラインから実行するpythonファイル、例えば、hogehoge.pyを実装する場合も同様です。
python hogehoge.py
で実行したときに、遅くならないように、hogehoge.pyは以下のように書きます。
# import系
import fuga
# main関数内で使用する関数やクラス
def piyo():
your code
# main関数
def main():
your code
if __name__ == "__main__":
main()
最後の、if __name__ == "__main__":で、main()の実行をif文の中に入れているのは、
import hogehoge
をしたときに、このmain()関数が実行されないようにするためです。
このif文がないと、importしただけで、main()が実行されてしまいます。
レベル2
2.1 命名方法2:reverse notation(逆記法)で命名し、読み取りやすくする
例えば、aの長さ、bの長さ、cの長さみたいな3種類を変数にしたい場合、
a_length b_length c_length
とせずに、
length_a length_b length_c
とします。
この書き方をreverse notation(逆記法)と呼びます。
reverse notation(逆記法)の場合、単語の先頭が同じになるため、プログラムを読みやすいです。
また、長さではなく、aに着目している場合には
a_length a_width a_max_length
みたいな書き方になります。
気持ちとしては、「焦点を当てている対象を先頭に書き、変数の先頭を統一しよう」です。
2.2 SOLIDのSを意識し、関数、メソッドの行数はできる限り短くする
書籍 アジャイルソフトウェア開発の奥義、Clean Code、Clean Coder、Clean Architecture、など
の著者である、
ロバート・C. マーチン(アジャイルソフトウェア開発宣言メンバの1人)
が提唱した、ソフトウェア設計の原則がSOLIDです。
ただ本投稿のレベルでは、SOLIDの全部を意識しなくても大丈夫です。
ですが、SOLIDの1つ目、**S:Single responsibility principle(単一責任の原則)**は強く意識しましょう。
単一責任とは、「関数やクラス、そしてメソッドは、1つだけの責務を果たすようにする」という意味です。
ここでの**”単一”**が示す大きさの定義、抽象性と具体性のバランスは難しいのですが、
極力、関数やクラス、メソッドが短くて、上位概念の変更に影響されないことがポイントです。
データサイエンティスト、AIエンジニアが取り扱う業務は、
「データ前処理、学習、推論、・・・」のように、とても手続き型でフロー的な内容です。
すると、実装するプログラムも手続き的になり、ひとつのmainクラスやメソッドが肥大化し、
単一のクラスやメソッドで、上から下へ順番にたくさんのことを果たす(多くの責務を持つ)ようになりがちです。
Jupyter Notebookで閉じるレベルなら良いのですが、システム開発にデータサイエンス、AIを導入するには、この状態はつらいです
※私もAI実装の解説書籍では、初学者への理解のしやすさを優先して長いクラスやメソッドを書きますが、システム開発時には、もっと細かく分割します。
AIシステムのようなSoE(System of Engagement)の開発は、
SoR(System of Records)のような、要件定義、外部・内部設計をかっちりやるウォーターフォール開発ではなく、アジャイル開発が多いです。
アジャイル開発ではCI(Continuous Integration)≒自動テスト、を実施することが基本です。
そしてアジャイルなので、実際に作ってプロトタイプレベルで動作を見て、カイゼン変更を見つけ、より良いものを目指します。
このカイゼン時に、単一クラスやメソッドの責務がでかいと、作り直すコード行数も多くなります。
作り直すコード行数が多いと、影響範囲が広くなります。
すると新たに作る必要がある単体テストもたくさんになります。
と同時に、今まで作った単体テストの多くを捨てることになります。
このような単体テストの大幅入れ替えが頻繁に発生する状態で開発を進めると、そのうち単体テストをきちんと書かなくなり、システムの品質が下がります。
また、カイゼンによる作り直しで、想定外の場所に影響が生まれてバグが発生しやすくなります。
データサイエンティスト、AIエンジニアは、アジャイル開発におけるカイゼンを積極的に受け入れるためにも、
実装する関数、クラス、メソッドは、単一責務を果たす短い内容にして、
カイゼン変更に強い実装を心がけます。
ひとつの長い関数、クラス、メソッドが存在するよりも、
短すぎるかな?と心配になるくらいの関数、クラス、メソッドがたくさん存在する方が望ましいです。
書籍や記事によっては、「1つの関数やメソッドの行数は5行以内程度が良い」とあったりしますが、
5行を基準にするのは、AI系の実装では短すぎて厳しい、逆効果かと思います。
何行という基準ではなく、単一の責務を果たす長さ、カイゼン変更時に影響範囲が狭い実装、単体テストを捨てることが少ない実装、を心がけます。
そのための1つのコツとしては、関数やクラス、メソッドの冒頭にコメントで、
"""本メソッドは、●●を実施する責務を担います。"""
などと、責務を明示的に書いてしまうのも、最初は良い練習になります。
2.3 関数、メソッドには型ヒントをつける
「SOLIDのS:単一責務」を意識して、関数やメソッドを分割すると、たくさんの関数、メソッドができます。
たくさんの関数、メソッドが存在していると理解が大変です。
コードを書いているときは大丈夫ですが、このコードを3カ月後に見直したり、他の人が使おうとした場合に、
「この関数の引数には何が入って、どんな出力がアウトプットされるんだ?」
と混乱状態になります。
そこで、関数を実装する際には型ヒントをつけます。
型ヒントとは以下のような書き方です。
def calc_billing_amount(amount: int, price: int) -> int:
billing_amount = amount*price
return billing_amount
引数の変数の型が何か分かるように引数名のあとに型を記載します。
また関数から出力される変数の型が分かるように、型を記載します。
この型ヒントは、その名の通りヒントであって、強制ではありません。
そのため、上記の関数では最初のamountにintではなくfloatを与えて、
calc_billing_amount(0.5, 100)
としても実行できてしまいます。エラーにはなりません。その点は注意が必要です。
型ヒントで、リストや辞書を使う場合や、intでもfloatなど複数の型がOKな場合は以下の書き方をします。
from typing import Dict, List, Union
def calc_billing_amount(
amount_list: List[int], price_dictionary: Dict[str, Union[int, float]]
) -> int:
billing_amount = 0
for index, (key, value) in enumerate(price_dictionary.items()):
billing_amount += amount_list[index] * value
return int(billing_amount)
from typing import List, Dict, Unionで、型ヒント用のリスト、辞書、そしてどちらでも良い場合に使用するUnionをimportします。
そして、例えば、要素がint型のリストの場合はList[int]とします。
keyがstring型、そしてvalueがintかfloatのどちらでも良い場合の辞書は
Dict[str, Union[int, float]]
と書きます。
実行は
amount = [3, 10]
price = {"item1": 100, "item2": 30.5}
calc_billing_amount(amount, price)
で、605と出力されます。
また、自分たちで定義したオリジナルのクラスを型ヒントにする場合は以下のように書きます。
class User:
def __init__(self, name: str, user_type: str):
self.name = name
self.user_type = user_type
def print_user_type(user: "User") -> str:
print(user.user_type)
自作のクラスUserを定義し、このUserを引数に実行される関数print_user_typeを定義しています。
Pythonのバージョン3.7以降であれば、
from __future__ import annotations
を使って"User"を、Userにできるのですが、Google ColaboratoryもPythonのバージョンはまだ3.6ですし、上記の書き方をお勧めします。
上記の型ヒントを与えたクラスを実行するには、通常通り、
taro = User("taro", "admin")
print_user_type(taro)
とします。すると出力に、adminと表示されます。
型ヒントを書くのは面倒ですが、単一責務でたくさんのクラス、メソッドに分割して実装すると後から困ります。
とくに仕事の場合は、チームメンバが自分が書いたコードを見たり、使用したりすることが多いので、
他人が使用しやすい&カイゼンしやすい実装を心がけます。
2.4 クラス、メソッド、関数にはdocstringを記載する
docstringはクラスやメソッド、関数の仕様や使用方法の説明です。
単一責務でたくさんのクラス、関数になってくると、使いまわす際に理解するのが大変です。
型ヒントだけでは分かりづらいので、さらに詳細説明としてdocstringを書きます。
ただ、面倒なので、プライベートメソッドや行数が少ないメソッドなどは1行のdocstringでも良いと思います。
一方で、他のチームメンバも使用するクラスやメソッド、AIシステムで重要な位置を占めるメインのクラス、処理が長いクラスなど、
詳細な説明があった方が、他のメンバが使いやすい場合には詳細にdocstringを書きます。
docstringの書き方はなんでも良いのですが、通常は、
・reStructuredText
・Google style
・Numpy style
のいずれかで書きます。
この3タイプのいずれかで書くのは、その後Sphinxを使えば自動でドキュメント化できるからです。
そのためSphinxに対応しているdocstringの記法を採用します。
docstringの3タイプの解説はこちらが詳しいです。
docstringのstyle3種の例
Google styleとNumpy styleは縦に長くなりがちなので、私はreStructuredTextが好きです。
reStructuredTextでのdocstringは以下のように書きます。
class User:
"""本システムを使用するアカウントユーザーを示すクラスです。
:param name: ユーザーのアカウント名
:param user_type:アカウントのタイプ(adminかnormal)
:Example:
>>> import User
>>> taro = User("taro", "admin")
"""
def __init__(self, name: str, user_type: str):
self.name = name
self.user_type = user_type
def print_user_type(self):
"""ユーザーのタイプをprint文で出力します
:pram None: 入力の引数はありません
:return: user_typeを文字列として出力
:rtype: str
:Example:
>>> import User
>>> taro = User("taro", "admin")
>>> taro.print_user_type()
admin
"""
print(self.user_type)
Exampleまで書いておくと、すぐに使い方が分かるので、他の人が使いやすく、私は好きです。
どこまで詳細に書くのか、Exampleや引数、returnの説明を書くのかは状況次第です。
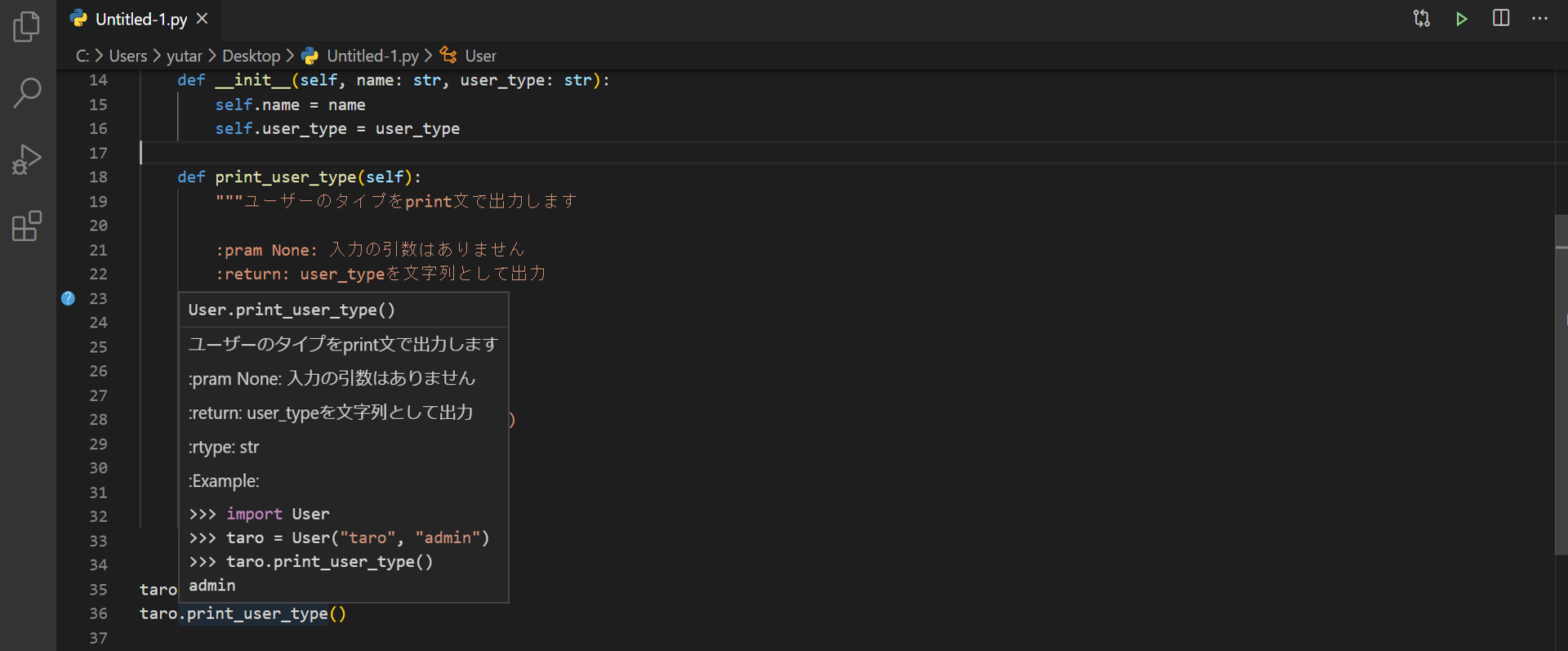
上記のように記載しておくと、VS codeなどのEditorでは、
以下の図のように、該当のプログラム部分にマウスカーソルを当てると、このdocstringが表示されるので、プログラムを理解しやすいです。
(下の図では、print_user_type()にマウスカーソルを当てています)
2.5 学習済みモデルの保存時に、前処理やハイパーパラメータなどの情報を一緒に保存する
AI、機械学習、ディープラーニングにおいては、学習済みモデルだけを保存するのではなく、前処理パイプライン、モデルのハイパーパラメータの設定など、学習を再現できる情報、そして、推論するために必要な全オブジェクトを保存します。
これらの全情報が含まれていれば保存の仕方はなんでも良いのですが、scikit-learnとPyTorchでの保存例を以下に示します。
例:scikit-learnの場合
from datetime import datetime, timedelta, timezone
import numpy as np
from joblib import dump, load
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
# 適当なデータとして、irisを用意
X, y = load_iris(return_X_y=True)
# 前処理(標準化して、2乗項の特徴量を追加)
preprocess_pipeline = Pipeline(steps=[("standard_scaler", StandardScaler())])
preprocess_pipeline.steps.append(("polynominal_features_2", PolynomialFeatures(2)))
# 前処理の適用
X_preprocessed = preprocess_pipeline.fit_transform(X)
# 学習器の用意
C = 1.2 # ハイパーパラメータの設定
model = LogisticRegression(random_state=0, C=C)
# 学習の実施
model.fit(X_preprocessed, y)
# 学習データでの性能
accuracy_training = model.score(X_preprocessed, y)
# 各種データを保存する用意
JST = timezone(timedelta(hours=+9), "JST") # 日本時刻に
now = datetime.now(JST).strftime("%Y%m%d_%H%M%S") # 現在時間を取得
training_info = {
"training_data": "iris",
"model_type": "LogisticRegression",
"hyper_pram_logreg_C": C,
"accuracy_training": accuracy_training,
"save_date": now,
}
save_data = {
"preprocess_pipeline": preprocess_pipeline,
"trained_mode": model,
"training_info": training_info,
}
filename = "./iris_model_" + now + ".joblib"
# 保存
dump(save_data, filename)
こうして保存した内容をロードする場合は、
load_data = load(filename)
# ロードした内容を読み込む
preprocess_pipeline = load_data["preprocess_pipeline"]
model = load_data["trained_mode"]
print(load_data["training_info"])
です。
このロードの例ではtraining_infoをprintしているので、
{'training_data': 'iris', 'model_type': 'LogisticRegression', 'hyper_pram_logreg_C': 1.2, 'accuracy_training': 0.9866666666666667, 'save_date': '20200503_205145'}
みたいなものが出力されます。
例:PyTorchの場合
参考 PyTorch SAVING AND LOADING MODELS
PATH = './checkpoint_' + str(epoch) + '.pt'
torch.save({
'epoch': epoch,
'total_epoch': total_epoch,
'model_state_dict': model.state_dict(),
'scheduler.state_dict': scheduler.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss_train': loss_train,
'loss_eval': loss_eval,
}, PATH)
ロードする場合は
# モデルなどのオブジェクトを先に作る
model = TheModelClass() # これは保存したのと同じモデル
scheduler = TheSchedulerClass() # これは保存したのと同じScheduler Class
optimizer = TheOptimizerClass() # これは保存したのと同じOptimizer Class
# ロードして与える
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
total_epoch = checkpoint['total_epoch']
epoch = checkpoint['epoch']
loss_train = checkpoint['loss_train']
loss_eval = checkpoint['loss_eval']
# 学習か推論かに応じて以下を実行
model.train()
# model.eval()
ディープラーニングのデータセットとデータローダーまでcheckpointに保存すると、保存ファイルがでかくなりすぎるので、これらは別途保存します。
# データセット、データローダーの保存
torch.save(trainset, './trainset.pt')
torch.save(trainloader, './dataloader.pt')
ロードするときは
trainset = torch.load('./trainset.pt')
trainloader = torch.load('./dataloader.pt')
以上、PyTorchでの保存とロードでした。
scikit-learnにせよ、PyTorchにせよ、保存の仕方の細かい点は何でも良いです。
ただ、モデルだけを保存してしまい、あとから
「このモデルはどうやって学習されたんや!?」
「このモデルはどんな性能なんや!?」
「このモデルにデータ投入するための、学習済みの前処理パイプがない!!」
みたいな事態にならないように気をつけます。
※備考1:scikit-learnの例で前処理とモデルをひとつのパイプラインにしていない理由は、前処理を別のリソースで実施し、モデルAPIに放り込む可能性があるからです。
とくに大量のデータ処理を高速に実施したい場合に、前処理だけ他の場所で分散して実施する際に使いやすいようにしておきたい気持ちがあります。
また、前処理は一緒で、異なるモデルを学習させるときに、この前処理パイプラインだけを流用したい気持ちもあります。
※備考2:前処理クラスを自作する注意点については後ほど解説します。ここでは自作クラスなどを使用している前処理パイプラインなどをロードする場合は、ロード前に通常のsckit-learnの前処理クラスをimportしておくだけでなく、自作クラスもimportしておき、その後ロードします。
ロードする際に、展開されるクラスがimportされていないと、ロード時にエラーが発生するので注意が必要です。
レベル3
3.1 命名方法3:適切な英単語と品詞で、責務が分かる名前をつける
クラス、メソッド、関数を細かく分割すればするほど、それらの命名が非常に重要になります。
名前を見れば、「何をするものなのか?すなわち、どんな責務を負っていて、何をinputに、何をoutputするのか」
これが分かることが理想的です。
ただ、日本人には難しいところです。
プログラミングの世界ではコメントは不要だ、コードの命名を見ればそれがコメントだ、
的な考え方もありますが、
日本人の英語の語彙力とニュアンスの違いを理解する能力では厳しいものがあります。
またデータサイエンスやAI系の場合は、アルゴリズムそのものが複雑なので、
初見の人がコメントなしの実装を見て、クラスやメソッドの中身を理解するのは難しいです。
ですが、命名方法は可能な限り、意図が伝わりやすいものを目指します。
最低限守りたいのは、
[1] クラス名、変数名は名詞にする
[2] メソッド、関数の名前は動詞から始める
[3] メンバ変数の真理値(boolean型)の場合は、以下のような動詞から始まって良い
(例)is_admin、has_item、can_drive、みたいな
[4] codicなどを使おう
https://codic.jp/engine
3.2 適切に例外処理を実装する
エラー(例外)のtry-catchはまったく楽しくない面倒な部分で、データサイエンティスト、AIエンジニアには苦痛(だと思います)。
Jupyter Notebookだけで終わるプロジェクト規模であれば問題ないのですが、AIをシステムに実装する場合は、エラーハンドリングが重要です。
例外が発生した際にシステムの処理全体が止まってしまいます。
そのため、実装コードにおいて、
tryがトップレベルにあるように(つまり、コードがtry:の中にいない状況を避ける)ようにします。
Pythonの公式の解説はぜひ目を通しましょう。
公式 8. エラーと例外
例:割り算をする関数を定義する場合
def func_division(a, b):
ret = a/b
return ret
これをやると、
ans = func_division(10, 0)
みたいなのが来るとエラーが発生して、プログラム全体が止まってしまいます。
なので、
def func_division(a, b):
try:
ret = a/b
return ret
except:
print("例外が発生しました")
と書きます。
ただ、これでは不十分です。
処理内容から発生する例外が予想がつく場合には、きちんとそのエラーでハンドリングして、相応の例外処理をします。
def func_division(a, b):
try:
ret = a/b
return ret
except ZeroDivisionError as err:
print('0除算の例外が発生しました:', err)
except:
print("予期せぬ例外が発生しました")
これであれば、
ans = func_division(10, 0)
が来れば、
0除算の例外が発生しました: division by zero
と出力され、
ans = func_division("hoge", "fuga")
と数値でない入力が与えらた場合、
予期せぬ例外が発生しました
と出力されます。
今後ますますAIの実システムへの実装は加速するため、Jupyter Notebookレベルでしかプログラムが書けない人間は困ります(と思います)。
ポイントは「tryがトップレベルにあるように(つまり、コードがtry:の中にいない状況を避ける)」を意識することです。
※備考:tryの範囲を狭くする
try-catchだけでも面倒と思いますが、だからといって、大きな処理(たくさんの行)をがっつりと1つのtryに入れることは避けます。どこで例外が発生したか分からないからです。
意味のある1つの処理単位でtry-catchするようにします。
また、後ほど解説しますが、メソッドにたくさんの行が存在する時点で、実は別のメソッドに分割すべき場合が多いです。
3.3 適切にログを実装する
データサイエンティスト、AIエンジニアの場合、print文で出力して状態を確認するのが一般的ですが、システムに組み込む場合はprint文では困るので、きちんとログとして書き込みます。
ログの使い方は以下のようなイメージです。
import logging
logger = logging.getLogger(__name__)
# logに入れる値を適当に作成
total_epoch = 1000
epoch = 100
loss_train = 5.44444
# logで記録する内容
log_list = [total_epoch, epoch, loss_train]
# logに記録
logger.info(
"total_epoch: {0[0]}, epoch: {0[1]}, loss_train: {0[2]:.2f}".format(log_list)
)
# logに記録した内容を出力して確認(今は確認用。本来は不要)
print("total_epoch: {0[0]}, epoch: {0[1]}, loss_train: {0[2]:.2f}".format(log_list))
この場合、ログされる内容をprint文で確認すると、
total_epoch: 1000, epoch: 100, loss_train: 5.44
となっています。
ここで、{0[2]:.2f}は、.formatで受けたリストの2番目を小数点2桁までで表示する、という意味です。
loggerにせよ、print文にせよ、Pythonでの書き方はいろいろありますが、
書き込む変数が多い場合には、私は上記のようにリストにして渡す書き方をします。
logger.infoだけでなく、logger.debug、logger.warning、logger.errorなどをログのレベルは状況に合わせて変更します。
最低限は上記の例の雰囲気で良いですが、ログの世界は深いです。
ログの公式ドキュメントを読んでおくのも良いと思います。
@paulxll さま、よりアドバイス追記![]()
f-stringを使った例(Python 3.8を想定)をいただきました。こちらもご参考ください♪
# logに入れる値を適当に作成
total_epoch = 1000
epoch = 100
loss_train = 5.44444
# logに記録
logger.info(f"{total_epoch=}, {epoch=}, loss_train: {loss_train=:.2f}")
備考:上記はPython3.8以上での書き方です。バージョン3.7以下の場合は、
logger.info(f"total_epoch: {total_epoch}, epoch: {epoch}, loss_train: {loss_train:.2f}")
となります(アドバイスいただき、ありがとうございます ![]() )。
)。
3.4 関数、メソッドの引数は3つ以下にする
関数、メソッドの引数は多くても3つまで。4つ以上は避けます(私の場合)。
引数が多いとその関数の使い方が理解しづらいですし、単体テストの準備や管理も面倒になります。
たくさんの引数を取らせたい場合は、辞書型変数でhogehoge_config、などにし、1つの辞書変数にして関数に渡します。
例:複雑な計算の関数
(例外処理を書こうと上で説明したところ恐縮ですが、面倒なので例外処理は省略)
def func_many_calculation(a, b, c, d, e):
ret = a*b*c/d/e
return ret
と定義して ans = func_many_calculation(10, 2, 3, 5, 2)
と使うと、引数が多すぎて、面倒です。
間違いの元にもなります。
そこで例えば、
def func_many_calculation(func_config):
a = func_config["a"]
b = func_config["b"]
c = func_config["c"]
d = func_config["d"]
e = func_config["e"]
ret = a*b*c/d/e
return ret
と定義し、 func_config = {"a": 10, "b": 2, "c": 3, "d": 5, "e": 2}
と代入する変数を辞書で作成して
ans = func_many_calculation(func_config)
と実行します。
ただ、この書き方は関数の定義が面倒すぎるので、
def func_many_calculation(a, b, c, d, e):
ret = a*b*c/d/e
return ret
と、関数の定義部分ではたくさんの引数を書き、
実行する部分では、引数は少なくするようにして、
func_config = {"a": 10, "b": 2, "c": 3, "d": 5, "e": 2}
ans = func_many_calculation(**func_config)
とするのが良いです。
※備考:**func_configという、見慣れない引数の書き方です。
この**は辞書型変数のアンパック操作を意味します。
つまりここでは、
func_many_calculation(**func_config)
は
func_many_calculation(func_config["a"], func_config["b"], ・・・, func_config["e"])
を意味します。
**による辞書型変数のアンパックは便利なので、ぜひ使えるようになりましょう。
3.5 *args、**kwargsを適切に使う
*args、**kwargsが何なのか分からないけど、自ら積極的に使う!!
そんなデータサイエンティスト、AIエンジニアはいませんが、
「なんだか分かっていないけど、論文実装のリポジトリを見ると、*args、**kwargsをたくさん見かける」
そんな経験は多いかと思います。*args、**kwargsとは友達になっておきましょう。
3.4の辞書型変数のアンパック操作の説明のあとなら、*args、**kwargsは怖くありません。
argsはargumentsの略で、argumentは日本語で引数という意味です。
kwargsはkeyword argumentsの略です。
ここで、*はリスト変数のアンパック操作です。
**は3.4で説明したように、辞書型変数のアンパック操作です。
この*、**を関数の引数で使用した場合は次のようになります。
例えば
def func_args_kwargs(*args, **kwargs):
print(args)
if len(args) >= 2:
print(args[1])
print(kwargs)
flg_a = kwargs.pop("flg_a", False)
print(flg_a)
のような関数を定義した場合に、
func_args_kwargs(10, 20)
を実行すると、入力の引数10と20がargsに入り、
(10, 20) 20 {} False
と出力されます。
続いて、辞書型変数も入力に使用し、
func_args_kwargs(10, **{"flg_a":True})
を実行すると、最初の辞書以外の引数はargsに入り、辞書はkwargsに入って、
(10,) {'flg_a': True} True
と出力されます。
*args、**kwargsは可変長引数と呼ばれます。
なぜこのような可変長引数*args、**kwargsを使用するのか説明します。
可変長引数を使用する理由は3つあります。
1つ目は理由は、関数の引数に余分なものが入っていても実行できるようにするためです。
例えば
def func_args_kwargs2(a, *args, **kwargs):
print(a)
を実行すると
func_args_kwargs2(10, 20, 30)
の出力は
10
となり、エラーにならずに実行できます。
2つ目の理由は、関数を拡張して引数をあとから増やしたくなった場合に、*argsで受け取れば、関数の中身や引数定義の部分を書き換えずに済むからです。
3つ目の理由は、関数やメソッドを実行する際の引数として、オプショナルであり、実行時に渡しても渡さなくても良い引数を受け取る部分として、*args、**kwargsを使用します。
この際には、*argsや**kwargsを受け取らなかった場合のデフォルト値を設定しておきます。
例:
def func_args_kwargs3(a, *args, **kwargs):
b = kwargs.pop("b", 2.0)
print(a*b)
と定義すると、
func_args_kwargs3(3.0)
の出力は6.0となります。関数内のbはデフォルトの2.0が使用されます。
func_args_kwargs3(3, **{"b":4.0})
の場合、出力は12.0となります。関数内のbは引数で与えた4.0になります。
以上が、*args、**kwargsの働きです。
※備考:実装時に、*args、**kwargsを使うことは、私の場合少ないです。
OSSや公開された論文実装の場合には、*args、**kwargsはよく使用されています。
これらの開発の場合は、いろいろな人がその実装コードを使うので、不確実性が高いです。
そのため、理由の1つ目に示したように、不要な引数が入っていても動作するよう、*args、**kwargsを使用しているのかな?と私は思っています。
レベル4
4.1 三項演算子でのif文に慣れる
Pythonではif文を三項演算子で書き、1行にまとめるケースが多いです。
こちらに慣れておきましょう。
(私は書籍執筆時にはあまり使いませんが、実装コードでは行数が減って読みやすいので使用します)
# 偶数か奇数かを判定
num = 10
if num % 2 == 0:
print("偶数")
else:
print("奇数")
は
# 偶数か奇数かを判定
num = 10
print("偶数") if num % 2 == 0 else print("奇数")
と書きます。
print文での見本よくないですね。
代入の時は以下のようになります。
num = 10
a = "偶数" if num % 2 == 0 else "奇数"
# a = "偶数" if num % 2 == 0 else a = "奇数" # これはエラーになる
print(a)
@Nabetani さま、よりアドバイス追記![]()
print("偶数") if num % 2 == 0 else print("奇数")
# より
print("偶数" if num % 2 == 0 else "奇数")
# が好ましいと感じます。
私の場合
- 条件演算の結果の値が必要な場合は foo if cond else bar を使う。
- 条件演算の結果の値が不要な場合は foo if cond else bar は避け、if cond:<改行>foo<改行>else:<改行>bar を使う
としています。
4.2 sklearn準拠で前処理およびモデルのクラスを実装する
sklearn準拠とは、scikit-learnのBaseEstimator、TransformerMixin、ClassifierMixinなどを継承して、scikit-learnの他のオブジェクトと一緒に、scikit-learnのPipelineクラスで取り扱えるように実装したクラスです。
自前の前処理クラスやモデルをsklearn準拠にしておけば、scikit-learnのPipelineに組み込んで利用できるので便利です。
例えば、前処理クラスであれば以下のように書きます。TransformerMixinとBaseEstimatorを継承させます。
from sklearn.base import BaseEstimator, ClassifierMixin, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted, check_X_y
class TemplateTransformer(TransformerMixin, BaseEstimator):
""" 前処理クラスの見本"""
def __init__(self, demo_param='demo'):
self.demo_param = demo_param # のちのち使用するパラメータはinitで用意
def fit(self, X, y=None):
"""前処理で必要な学習の実施。yが存在しない場合もy=Noneで与えておく"""
X = check_array(X, accept_sparse=True) # check_arrayはsklearnの入力の検証関数
# 何か学習する処理。ここでは一例でn_features_というパラメータを学習している
self.n_features_ = X.shape[1]
# 前処理のTransformerそのものを返す
return self
def transform(self, X):
""" 引数Xに前処理を適用する"""
# 前処理を適用する際に、学習しておくべきパラメータ(ここではn_features_)があるか確認
check_is_fitted(self, 'n_features_')
# sklearnの入力の検証
X = check_array(X, accept_sparse=True)
# 何らか変換処理
X_transformed = hogehoge(X)
return X_transformed
また、モデルクラスの場合はClassifierMixin、BaseEstimatorを継承させます。
以下は教師あり学習をイメージしていますが、教師なし学習でも同じように書きます。
from sklearn.base import BaseEstimator, ClassifierMixin, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted, check_X_y
class TemplateClassifier(ClassifierMixin, BaseEstimator):
""" モデルクラスの見本"""
def __init__(self, demo_param="demo"):
self.demo_param = demo_param # のちのち使用するパラメータはinitで用意
def fit(self, X, y):
"""学習の実施。教師あり学習などでyが存在しない場合もy=Noneで与えておく"""
# sklearnの入力の検証
X, y = check_X_y(X, y)
# 何らか学習
self.fugafuga = piyopiyo(X, y)
# 学習した学習器(model)そのものを返す
return self
def predict(self, X):
""" 未知のデータの推論"""
# 推論前に学習しておくべきパラメータ(ここではfugafuga)があるか確認
check_is_fitted(self, ["fugafuga"])
# sklearnの入力の検証
X = check_array(X)
# 推論する
y_predicted = self.fugafuga(X)
return y_predicted
sklearn準拠に実装する際には、scikit-learnでテンプレートが公開されているので、それをベースに変更するのをおすすめします。
Developing scikit-learn estimators
4.3 デコレータを適切に活用する
デコレータとは@hogehogeみたいなやつです。
よくメソッド名や関数名の上についていて、なんだろう?と思いながら、スルーすると思います。
ですが、デコレータとは友達になりましょう。
Pythonで標準のデコレータと、自作のデコレータがあります。
Python標準のデコレータでよく見かけるのは、
@property、@staticmethod、@classmethod、@abstractmethod
あたりです。
ひとつずつ確認します。
@propertyは、クラスの外部からそのメンバ変数を変更不能にします。
(例)
class User:
def __init__(self, name: str, user_type: str):
self.name = name
self.__user_type = user_type
@property
def user_type(self):
return self.__user_type
として、Userクラスのuser_typeは@propertyで定義します。
すると、
taro = User("taro", "admin")
print(taro.user_type)
は問題なく実行できて、adminと出力されます。
ですが、
taro.user_type="normal"
と、@propertyで定義したメンバ変数を変えようとすると、エラーがでます。
このように、外部から変えられない変数を定義できます。
(例)
@staticmethod、@classmethod
class User:
def __init__(self, name: str, user_type: str):
self.name = name
self.user_type = user_type
@staticmethod
def say_hello(name):
print("Hello " + name)
@staticmethod、@classmethodはクラスをオブジェクトとして実体化しなくても、そのメソッドを使用可能にします。
上記のように定義して以下を実行すると、
User.say_hello("Hanako")
Hello Hanakoと出力されます。
@staticmethodと@classmethodの違いは、またそこに直面したときに調べれば良いです。
他に標準のPythonのデコレータで見かけるのは@abstractmethodです。
クラスのメソッドにこの@abstractmethodがついている場合、このクラスを継承した子クラスでは、そのメソッドを必ず実装しなければいけないです。
実装しないとエラーになります。
抽象クラスを定義し、継承した子クラスでメソッドの定義を強制する際に、@abstractmethodを使用します。
だいたい、このあたりを理解していればデータサイエンス、AI系では大丈夫かと。
DjangoでWebアプリケーションを作り出すと、またDjangoのデコレータが出てきますが、それはそのときに調べれば大丈夫です。
続いて、自作のデコレータについて解説します。
Userクラスでuser_typeがadminの場合だけ実行できる処理があるとします。
class User:
def __init__(self, name: str, user_type: str):
self.name = name
self.user_type = user_type
def func_admin_can_do(self):
if self.user_type=="admin":
# なんらかadminだけができる処理
print("I'm admin.")
else:
print("cannot do this func with auth error.")
このように書いても良いのですが、user_typeがadminの場合だけ実行できる処理が他にもたくさんあったとすると、そのたびにif文でチェックするのは面倒です。
そこでデコレータを使用すると以下のようになります。
def admin_only(func):
"""デコレータの定義"""
def wrapper(self, *args, **kwargs):
if self.user_type == "admin":
# adminだけができる処理
return func(self, *args, **kwargs)
else:
print("cannot do this func with auth error.")
return wrapper
class User:
def __init__(self, name: str, user_type: str):
self.name = name
self.user_type = user_type
@admin_only
def func_admin_can_do(self):
# なんらかadminだけができる処理
print("Im admin.")
このように定義すれば、@admin_onlyというデコレータをつけるだけで、ユーザーがadminの場合のみ処理を実行できます。
adminかどうか判定して処理をするメソッドが多いなど、同じことを何度も書くケースではデコレータを活用します。
4.4 チーム開発用にエディターの設定を統一する
コーディング時にオートフォーマッターを使用すると、自動で整形されるので便利です。
Pythonであれば、blackが最近は多いです。
ただ、チームメンバが別々のフォーマッターを利用していると、フォーマットの変更だけで、ファイルが上書き保存される機会が増えて、git commitの内容がぐちゃぐちゃになります。
そのため、チームで開発する際には、オートフォーマッターは統一します。
例えば、リポジトリの直下にフォルダ「.vscode」を作成し、その中にファイル「settings.json」を入れておきます。
setting.jsonには
"python.formatting.provider": "black"
あたりを書いておき、blackでフォーマットされるようにします。
メンバがコーディングする際にはVS codeでこのフォルダを開いて実行すれば、
リポジトリの.vscodeのsetting.jsonの設定が反映されるので、全員が同じコーディング・スタイルに統一されます。
Python用のVS codeの設定はこちらの記事がとても良いです。
4.5 GitHubのプルリクエスト用templateを準備し注意点を記載しておく
本投稿で挙げた内容や、その他、気をつけてもらいたい点は、GitHubのプルリクエスト用templateとして用意します。
リポジトリの直下にフォルダ「.github」を作成し、その中にファイル「PULL_REQUEST_TEMPLATE.md」を作成します。
このPULL_REQUEST_TEMPLATE.mdがプルリクエスト時の投稿内容のテンプレートとして表示されます。
本投稿で挙げた内容を書いておくと、
レベル1
- [ ] 変数、関数、クラス、メソッドの命名規則を守っているか?
- [ ] 命名方法1:変数名やメソッド名から冗長な部分は除かれているか?
- [ ] importの記載はルールに従っているか?
- [ ] 乱数のシードを固定して、再現性を担保しているか?
- [ ] プログラムは関数化して実行されているか?
レベル2
- [ ] 命名方法2:reverse notation(逆記法)で命名され、読み取りやすいか?
- [ ] SOLIDのSを意識し、関数、メソッドが単一責務で短い内容か?
- [ ] 関数、メソッドには型ヒントをつけているか?
- [ ] クラス、メソッド、関数にはdocstringが記載されているか?
- [ ] 学習済みモデルの保存時に、前処理やハイパーパラメータなどの情報を一緒に保存しているか?
レベル3
- [ ] 命名方法3:適切な英単語と品詞で、責務が分かる名前がつけられているか?
- [ ] 例外処理が適切に実装されているか?
- [ ] ログを適切に実装しているか?
- [ ] 関数、メソッドの引数は3つ以下になっているか?
- [ ] `*args`、`**kwargs`を適切に使えているか?
レベル4
- [ ] 三項演算子でif文を短く書いているか?
- [ ] sklearn準拠で、前処理およびモデルのクラスが実装されているか?
- [ ] デコレータを適切に活用しているか?
- [ ] チーム内でエディターの設定が統一されているか?
- [ ] プルリクエスト用templateを用意、活用しているか?
です。
まとめ
以上、データサイエンティスト、AIエンジニアがPythonで実装時に気をつけたい点、実装のノウハウ・コツをまとめました。
投稿を書いたものの、私自身完全には守れていないルールもあります。
また、私自身も若輩者で経験も浅いので、もっとこうした方が良いという、先達からのアドバイスもいただければ幸いです。
そして、厳格に規律を敷きすぎて窮屈に感じるのは良くないので、
「チームの皆が気持ちよく開発できて、そして品質が担保される」
そんな落としどころを、チームごとにルール化すると良いかもしれません。
以上、ご一読いただき、ありがとうございました。
最近の連載一覧
[1]【実装解説】日本語版BERTをGoogle Colaboratoryで使う方法(PyTorch)
[2]【実装解説】日本語版BERTでlivedoorニュース分類:Google Colaboratoryで(PyTorch)
[3]【実装解説】脳科学と教師なし学習。情報量最大化クラスタリングでMNISTを分類
[4]【実装解説】日本語BERT × 教師なし学習(情報量最大化クラスタリング)でlivedoorニュースを分類
【備考】私がリードする、AIテクノロジー部開発チームはメンバ募集中です。興味がある方はこちらから
【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません