kerasのModel.fitの処理が書いてあるtrain_step()を書き換えてVAEとか蒸留とかGANをやる手順の記事です。
1. 独自の学習ステップの書き方
3つの選択肢があるようです
本記事では1をやっていきます
処理の自由度は3が一番高く1が一番低くなりますが、1はkerasのエコシステムがそのまま使えるのが大きなメリットです。コールバックがそのまま使えたり、optimizerの状態を保存できたりと便利なので表現可能なら1で書くのが良さそうです。
1. keras.Modelの処理と同じ動作をするtrain_step
1-1. 準備
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
def make_data(n=400):
x = np.linspace(0, 1, n)
y = x * 2
return x, y
x, y = make_data(n=400)
def plot(x, y, y_pred=None):
plt.figure(figsize=(4, 4))
plt.scatter(x, y)
if y_pred is not None:
plt.scatter(x, y_pred)
plt.show()
plot(x, y)

1-2. 元々のkeras.Modelと同じ動作を書く
こちらの記事のコードでやっていきます
https://qiita.com/tonouchi510/items/1203bfe8e6bdb61d9902
Model.fitの動作はtrain_step()に書かれていますので、これを書き換えてカスタマイズしていきますが、まずは元々のkeras.Modelと同じ動作のtrain_stepを見てみましょう
class MyModel(tf.keras.Model):
def train_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred)
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
self.compiled_metrics.update_state(y, y_pred, sample_weight)
return {m.name: m.result() for m in self.metrics}
入ってきたdataを x, y に分けて、推定値である y_pred と y の差からlossを算出して勾配を出してself.optimizerでself.trainable_variablesを更新、self.compiled_metricsの状態を更新、更新済みのmetricsを受け取ってreturnするという処理になっています。
勾配算出に使っているtapeについては公式ページに解説があります
https://www.tensorflow.org/tutorials/customization/autodiff?hl=ja
train_step内の動作についても公式ページに解説があります
https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit?hl=ja
あとはtf.keras.Modelの代わりにMyModelでモデルをつくるだけです
inputs = tf.keras.layers.Input(1)
outputs = tf.keras.layers.Dense(1, activation='linear')(inputs)
model = MyModel(inputs, outputs, name='hoge')
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
model.compile(loss='mse', metrics='mse', optimizer=opt)
model.fit(x, y, validation_data=(x, y), epochs=100)
y_pred = model.predict(x)
plot(x, y, y_pred)

2. 標準のcompiled_lossをそのまま使える場合
Model.compile()で指定したcompiled_lossを使うとepochごとのlossのクリアやlossの表示などを自分でやらなくて済んで楽なので、まずはこれをやってみたいと思います。
ここではcompiled_lossをそのまま使える例として、回帰モデルの蒸留をやってみます。xをシャッフルしてmixupしたものを受け取って、教師モデルで推定したyを使って生徒モデルを学習させて、教師モデルと同じ結果を出力する生徒モデルをつくるイメージでやってみます。
2-1. 教師モデルの作成
まず教師モデルを作ります。
def make_model(name):
inputs = tf.keras.layers.Input(1)
outputs = tf.keras.layers.Dense(1, activation='linear')(inputs)
model = tf.keras.models.Model(inputs, outputs, name=name)
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
model.compile(loss='mse', optimizer=opt)
return model
teacher = make_model('teacher')
student = make_model('student')
teacher.fit(x, y, validation_data=(x, y), epochs=100)
y_pred = teacher.predict(x)
plot(x, y, y_pred)

本来は大きいけど精度が高い教師モデルを小さい生徒モデルに再現させる為にやるものなので、教師モデルが上記のように小さいならわざわざ蒸留する必要なんかないんですが書き方の例としてこれでやってみます。
2-2. 変更は最小限にしたカスタムモデル
とりあえず変更を最小限にやりたいことをやってみます
class Distiller(tf.keras.Model):
def __init__(self, inputs, outputs, teacher, **kwargs):
super(Distiller, self).__init__(inputs, outputs, **kwargs)
self.teacher = teacher
def train_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
y_teacher = self.teacher(x, training=False) # ← 変更箇所
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y_teacher, y_pred) # ← 変更箇所
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients((grad, var) for (grad, var) in zip(gradients, model.trainable_variables)
if grad is not None) # ← 変更箇所
self.compiled_metrics.update_state(y, y_pred, sample_weight)
return {m.name: m.result() for m in self.metrics}
シャッフルしてmixupするのは別途やっている想定で、受け取ったxに対する教師モデルの推定値y_teacherをstudentモデルが学習します。このとき、教師モデルは学習対象にしたくないので、training=Falseとして更新が掛からないようにしています。
training=Falseにするとその部分の勾配がNoneになりますが、そのまま渡すとself.optimizer.apply_gradients()が警告メッセージを出してきちゃうので、Noneでないものだけ渡すようにしています。(参考にしたページ)
ということで生徒モデルを学習してみます
inputs = tf.keras.layers.Input(1)
outputs = tf.keras.layers.Dense(1, activation='linear')(inputs)
model = Distiller(inputs, outputs, teacher)
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
model.compile(loss='mse', metrics='mae', optimizer=opt)#, run_eagerly=True)
model.fit(x, y, validation_data=(x, y), epochs=100)
y_pred = model.predict(x)
plot(x, y, y_pred)

このモデルのsummaryを見ると普通のモデルと同じように見えます。teacher部分はtrain_stepに書き加えているだけなのでsummaryには出てきません。
>>> model.summary()
Model: "distiller_23"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_38 (InputLayer) [(None, 1)] 0
_________________________________________________________________
dense_37 (Dense) (None, 1) 2
_________________________________________________________________
teacher (Functional) (None, 1) 2
=================================================================
Total params: 4
Trainable params: 4
Non-trainable params: 0
_________________________________________________________________
ではweightはどうかというと生徒モデルと教師モデルがセットで入っています。上が生徒モデル、下が教師モデルのweightになっています。
>>> model.weights
[<tf.Variable 'dense_3/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[1.9999967]], dtype=float32)>,
<tf.Variable 'dense_3/bias:0' shape=(1,) dtype=float32, numpy=array([1.6316116e-06], dtype=float32)>,
<tf.Variable 'dense_2/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[1.9999983]], dtype=float32)>,
<tf.Variable 'dense_2/bias:0' shape=(1,) dtype=float32, numpy=array([8.3305986e-07], dtype=float32)>]
>>> model.teacher.weights
[<tf.Variable 'dense_2/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[1.9999983]], dtype=float32)>,
<tf.Variable 'dense_2/bias:0' shape=(1,) dtype=float32, numpy=array([8.3305986e-07], dtype=float32)>]
生徒モデルだけ取り出して使いたいときにちょっとやりにくいので、次の項で生徒モデルを分けてみたいと思います。
2-3. 生徒モデルを分けて書くカスタムモデル
inputs, outputsを渡してDistillerクラスに生徒モデルをつくるのでなく、生徒モデルをkeras.Modelでつくっておいて、Distillerクラスに組み込むようにしてみます。
この場合はtest_step()も書き換える必要があります。3-2の書き方だとDistillerクラスに生徒モデルが格納されていたのでtest_step()でself(x)したときに生徒モデルが呼ばれて正常に動作していたんですが、こちらでは分けているのでtest_step()で生徒モデルが推定してくれるように書き換えるわけです。
class Distiller(tf.keras.Model):
def __init__(self, teacher, student, **kwargs):
super(Distiller, self).__init__(**kwargs)
self.teacher = teacher
self.student = student
def train_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
y_teacher = self.teacher(x, training=False)
with tf.GradientTape() as tape:
y_pred = self.student(x, training=True)
loss = self.compiled_loss(y_teacher, y_pred)
gradients = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients((grad, var) for (grad, var) in zip(gradients, model.trainable_variables)
if grad is not None)
self.compiled_metrics.update_state(y, y_pred, sample_weight)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
y_pred = self.student(x, training=False)
loss = self.compiled_loss(y, y_pred)
self.compiled_metrics.update_state(y, y_pred, sample_weight)
return {m.name: m.result() for m in self.metrics}
model = Distiller(teacher, student)
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
model.compile(loss='mse', metrics=('mae'), optimizer=opt, run_eagerly=True)
model.fit(x, y, validation_data=(x, y), epochs=100)
y_pred = model.student.predict(x)
plot(x, y, y_pred)

これで生徒モデルを分けて扱えるようになりました
3. compiled_lossを追加する場合
元々のModel.compile()が扱えないようなloss functionであっても、Model.compile()をoverrideして追加してやれば諸々を同様にやってくれます。
題材として判別モデルの蒸留をやってみます。回帰モデルと違って教師モデルからsoftmax出力が得られますので、これを生徒モデルが利用できるようにすることで教師モデルより小さい生徒モデルが同等の精度を得られるようにしようというものですが、その為に元々あるloss functionをそのまま使うというわけにはいかなくなるのでちょうど良い題材だと思います。
コードはkeras.ioにあったものをほぼそのまま使っています
https://keras.io/examples/vision/knowledge_distillation/
3-1. データの準備
mnistを使います
# Prepare the train and test dataset.
batch_size = 64
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
1
# Normalize data
x_train = x_train.astype("float32") / 255.0
x_train = np.reshape(x_train, (-1, 28, 28, 1))
x_test = x_test.astype("float32") / 255.0
x_test = np.reshape(x_test, (-1, 28, 28, 1))
plt.imshow(x_train[0])

3-2. 教師/生徒モデルの作成
こちらも本来は大きくて精度の高い教師モデルを小さい生徒モデルで再現する為のものですが、書き方の確認をするだけなので同じモデルで作っています
def make_model(name):
inputs = tf.keras.layers.Input(shape=(28, 28, 1))
network = tf.keras.layers.Conv2D(16, (3, 3), strides=(2, 2), padding="same")(inputs)
network = tf.keras.layers.LeakyReLU(alpha=0.2)(network)
network = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="same")(network)
network = tf.keras.layers.Conv2D(32, (3, 3), strides=(2, 2), padding="same")(network)
network = tf.keras.layers.Flatten()(network)
outputs = tf.keras.layers.Dense(10)(network)
model = tf.keras.models.Model(inputs, outputs, name=name)
return model
teacher = make_model('teacher')
student = make_model('student')
teacher.summary()
student.summary()
teacher.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
teacher.fit(x_train, y_train, epochs=5)
print(teacher.evaluate(x_test, y_test))
3-3. カスタムモデルをつくって学習
Model.compile()にself.student_loss_fnとself.distillation_loss_fnを追加することでupdate_stateが掛かるようにしています。tensorflowの公式ページではModel.metrics()を書くことでupdate_state()が掛かるようにしているので書き方が違うんですが、どちらが良いのかよく分からないので知っている人がいたら教えて下さい。
class Distiller(tf.keras.Model):
def __init__(self, teacher, student, **kwargs):
super(Distiller, self).__init__(**kwargs)
self.teacher = teacher
self.student = student
def compile(self, optimizer, metrics, student_loss_fn, distillation_loss_fn, alpha=0.1, temperature=3, **kwargs):
super(Distiller, self).compile(optimizer=optimizer, metrics=metrics, **kwargs)
self.student_loss_fn = student_loss_fn
self.distillation_loss_fn = distillation_loss_fn
self.alpha = alpha
self.temperature = temperature
def train_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
# 教師モデルで推定
teacher_predictions = self.teacher(x, training=False)
with tf.GradientTape() as tape:
# 生徒モデルで推定
student_predictions = self.student(x, training=True)
# lossを算出
student_loss = self.student_loss_fn(y, student_predictions)
distillation_loss = self.distillation_loss_fn(
tf.nn.softmax(teacher_predictions / self.temperature, axis=1),
tf.nn.softmax(student_predictions / self.temperature, axis=1),
)
loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss
# 勾配を算出
trainable_vars = self.student.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# optimizerでweightを更新
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# compiled_metricsを更新
self.compiled_metrics.update_state(y, student_predictions)
# metricsを算出して返す
results = {m.name: m.result() for m in self.metrics}
results.update(
{"student_loss": student_loss, "distillation_loss": distillation_loss}
)
return results
def test_step(self, data):
x, y, sample_weight = tf.keras.utils.unpack_x_y_sample_weight(data)
y_pred = self.student(x, training=False)
student_loss = self.student_loss_fn(y, y_pred)
self.compiled_metrics.update_state(y, y_pred, sample_weight)
results = {m.name: m.result() for m in self.metrics}
results.update({"student_loss": student_loss})
return results
distiller = Distiller(student=student, teacher=teacher)
distiller.compile(
optimizer=tf.keras.optimizers.Adam(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
student_loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
distillation_loss_fn=tf.keras.losses.KLDivergence(),
alpha=0.1,
temperature=10,
run_eagerly=True
)
distiller.fit(x_train, y_train, epochs=3)
distiller.evaluate(x_test, y_test)
4. Model.metrics()に書くやり方 + カスタムレイヤーの追加
もうちょっとややこしい作例としてカスタムレイヤーの追加が必要になるVAEをやってみます
カスタムレイヤーの作り方についてはkeras.ioに記事がありました
https://keras.io/guides/making_new_layers_and_models_via_subclassing/
VAEのコードもkeras.ioにありました
https://keras.io/search.html?q=vae
VAEってなんぞという方は以下の記事が分かりやすいと思います
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
4-1. データの準備
mnistのデータを使いますがラベルは必要ないので画像のみ、分ける必要がないので学習/テストデータを1つにまとめちゃいます。
(x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data()
mnist_digits = np.concatenate([x_train, x_test], axis=0)
mnist_digits = np.expand_dims(mnist_digits, -1).astype("float32") / 255
plt.imshow(mnist_digits[0])
plt.show()

4-2. サンプリングレイヤーをつくる
潜在変数zで表現されるlatent_dim次元の正規分布をサンプリングするレイヤーを作成します
class Sampling(tf.keras.layers.Layer):
"""Uses (z_mean, z_log_var) to sample z, the vector encoding a digit."""
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
4-3. encoderをつくる
画像からCNNで次元を落としていって、最終的にlatent_dim次元の正規分布まで次元削減するモデルをつくります。先程のSamplingレイヤーはencoderの最後に入ります。
latent_dim = 2
def make_encoder(latent_dim):
encoder_inputs = tf.keras.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = tf.keras.layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(16, activation="relu")(x)
z_mean = tf.keras.layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = tf.keras.layers.Dense(latent_dim, name="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = tf.keras.Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
return encoder
encoder = make_encoder(latent_dim)
encoder.summary()
tf.keras.utils.plot_model(encoder, show_shapes=True, expand_nested=True)
Model: "encoder"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_13 (InputLayer) [(None, 28, 28, 1)] 0
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 14, 14, 32) 320 input_13[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 7, 7, 64) 18496 conv2d_10[0][0]
__________________________________________________________________________________________________
flatten_5 (Flatten) (None, 3136) 0 conv2d_11[0][0]
__________________________________________________________________________________________________
dense_11 (Dense) (None, 16) 50192 flatten_5[0][0]
__________________________________________________________________________________________________
z_mean (Dense) (None, 2) 34 dense_11[0][0]
__________________________________________________________________________________________________
z_log_var (Dense) (None, 2) 34 dense_11[0][0]
__________________________________________________________________________________________________
sampling_4 (Sampling) (None, 2) 0 z_mean[0][0]
z_log_var[0][0]
==================================================================================================
Total params: 69,076
Trainable params: 69,076
Non-trainable params: 0
__________________________________________________________________________________________________

4-4. decoderをつくる
encoderとは逆にlatent_dim次元の正規分布から元画像と同じ次元まで次元を増やしていくdecoderモデルをつくります
def make_decoder(latent_dim):
latent_inputs = tf.keras.Input(shape=(latent_dim,))
x = tf.keras.layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = tf.keras.layers.Reshape((7, 7, 64))(x)
x = tf.keras.layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = tf.keras.layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = tf.keras.layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
decoder = tf.keras.Model(latent_inputs, decoder_outputs, name="decoder")
return decoder
decoder = make_decoder(latent_dim)
decoder.summary()
tf.keras.utils.plot_model(decoder, show_shapes=True, expand_nested=True)
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_14 (InputLayer) [(None, 2)] 0
_________________________________________________________________
dense_12 (Dense) (None, 3136) 9408
_________________________________________________________________
reshape_6 (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_transpose_18 (Conv2DT (None, 14, 14, 64) 36928
_________________________________________________________________
conv2d_transpose_19 (Conv2DT (None, 28, 28, 32) 18464
_________________________________________________________________
conv2d_transpose_20 (Conv2DT (None, 28, 28, 1) 289
=================================================================
Total params: 65,089
Trainable params: 65,089
Non-trainable params: 0
_________________________________________________________________

4-5. VAEモデルをつくる
先程の蒸留とは違いlossをModel.compile()に渡すのでなく、Model.metrics()のreturnで返すやり方になっています。compiled_metricsであればepochごとの状態のクリアを自動でやってくれますがこの作例ではcompileしていません。そういう書き方をする場合はModel.metricsのreturnで追加したlossを返すようにすればcompileしたときと同様、epochごとの状態クリアをやってくれるようになります。
tensorflow公式に紹介されているのがこのやり方なので、どちらかというとこちらの方がスタンダードな書き方なのかな?
class VAE(tf.keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = tf.keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = tf.keras.metrics.Mean(name="reconstruction_loss")
self.kl_loss_tracker = tf.keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
tf.keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
encoder = make_encoder(latent_dim)
decoder = make_decoder(latent_dim)
vae = VAE(encoder, decoder)
vae.compile(optimizer=tf.keras.optimizers.Adam())
vae.fit(mnist_digits, epochs=30, batch_size=128)
4-6. 潜在変数を可視化する
潜在変数を2次元にしてあるので、2次元にプロットすることが出来ます。そこで、潜在変数に対してどんな画像がdecodeされるかを可視化してみます。
def plot_latent_space(vae, n=30, figsize=15):
# display a n*n 2D manifold of digits
digit_size = 28
scale = 1.0
figure = np.zeros((digit_size * n, digit_size * n))
# linearly spaced coordinates corresponding to the 2D plot
# of digit classes in the latent space
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = vae.decoder.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[
i * digit_size : (i + 1) * digit_size,
j * digit_size : (j + 1) * digit_size,
] = digit
plt.figure(figsize=(figsize, figsize))
start_range = digit_size // 2
end_range = n * digit_size + start_range
pixel_range = np.arange(start_range, end_range, digit_size)
sample_range_x = np.round(grid_x, 1)
sample_range_y = np.round(grid_y, 1)
plt.xticks(pixel_range, sample_range_x)
plt.yticks(pixel_range, sample_range_y)
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.imshow(figure, cmap="Greys_r")
plt.show()
plot_latent_space(vae)
それっぽいですね

4-7. encoder
学習に使ったデータをラベルごとにencodeするとどの辺に配置されるのかプロットします。
def plot_label_clusters(vae, data, labels):
# display a 2D plot of the digit classes in the latent space
z_mean, _, _ = vae.encoder.predict(data)
plt.figure(figsize=(12, 10))
plt.scatter(z_mean[:, 0], z_mean[:, 1], c=labels)
plt.colorbar()
plt.xlabel("z[0]")
plt.ylabel("z[1]")
plt.show()
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train, -1).astype("float32") / 255
plot_label_clusters(vae, x_train, y_train)

5. 複数のモデルをそれぞれ学習する
最後に複数のモデルを交互に学習する例としてGANをやってみます
keras.ioにConditional GANの例があったのでこれをやっていきます
https://keras.io/examples/generative/conditional_gan/
GANがなんだか分からない人はこの辺を読みましょう
https://qiita.com/mm_918/items/c6bf085e7618b8af3d98
5-1. データの準備
batch_size = 64
num_channels = 1
num_classes = 10
image_size = 28
latent_dim = 128
generator_in_channels = latent_dim + num_classes
discriminator_in_channels = num_channels + num_classes
print(generator_in_channels, discriminator_in_channels)
28 x 28 pixelのグレースケール画像と0~9の10クラスのどれであるのかをone-hotで表現したラベルをtf.data.Datasetにしています
# We'll use all the available examples from both the training and test
# sets.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
all_digits = np.concatenate([x_train, x_test])
all_labels = np.concatenate([y_train, y_test])
# Scale the pixel values to [0, 1] range, add a channel dimension to
# the images, and one-hot encode the labels.
all_digits = all_digits.astype("float32") / 255.0
all_digits = np.reshape(all_digits, (-1, 28, 28, 1))
all_labels = tf.keras.utils.to_categorical(all_labels, 10)
# Create tf.data.Dataset.
dataset = tf.data.Dataset.from_tensor_slices((all_digits, all_labels))
dataset = dataset.shuffle(buffer_size=1024).batch(batch_size)
print(f"Shape of training images: {all_digits.shape}")
print(f"Shape of training labels: {all_labels.shape}")
k = np.random.randint(0, all_digits.shape[0], 1)[0]
print(k)
plt.imshow(all_digits[k])
plt.title(all_labels[k])
plt.show()

5-2. discriminatorの作成
mnistで普通に判別をやる場合は画像と0~9の正解ラベルの2つの情報を使って学習をしますが、discriminatorは画像と0~9の正解ラベルからその画像がgeneratorが乱数からつくったフェイクなのか本物なのかを判別するように学習します。
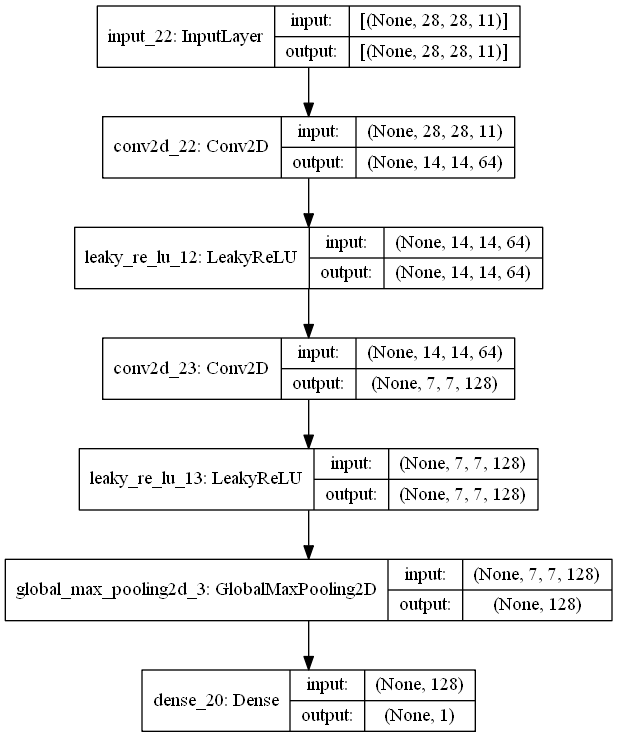
28x28 pixelの画像が来るので(28, 28, 1)が入力されるのかと思ったら、discriminator_in_channelが11なので(28, 28, 11)で入力されるようになっています。残りの10次元はなんなのかというと、one-hotのラベルがここに入っています。ラベルを担当する28x28の行列が10枚あって、正解ラベルに該当する行列は値がすべて1、正解ラベル以外の行列9枚は値がすべて0になっているものを受け取ります。
無駄に行列が大きいようにも思えますが、畳み込み層がラベル情報を上手く扱えるようにするには畳み込みの範囲内に常に情報がある状態にする為にこうなっているんじゃないかと思います。
def make_discriminator():
discriminator = tf.keras.Sequential(
[
tf.keras.layers.InputLayer((28, 28, discriminator_in_channels)),
tf.keras.layers.Conv2D(64, (3, 3), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Conv2D(128, (3, 3), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.GlobalMaxPooling2D(),
tf.keras.layers.Dense(1),
],
name="discriminator",
)
return discriminator
discriminator = make_discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, expand_nested=True)
5-3. generatorをつくる
latent_dim次元の乱数と0~9のone-hotラベルからフェイク画像をつくるモデルをつくります。画像だけでなくラベルをつけて学習することで、ラベルを指定して画像生成が出来るようになります。
この作例ではlatent_dimが128次元なので、0~9のone-hotラベルの10次元と合わせて138次元の入力から作成します。
def make_generator():
generator = tf.keras.Sequential(
[
tf.keras.layers.InputLayer((generator_in_channels,)),
# We want to generate 128 + num_classes coefficients to reshape into a
# 7x7x(128 + num_classes) map.
tf.keras.layers.Dense(7 * 7 * generator_in_channels),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Reshape((7, 7, generator_in_channels)),
tf.keras.layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(alpha=0.2),
tf.keras.layers.Conv2D(1, (7, 7), padding="same", activation="sigmoid"),
],
name="generator",
)
return generator
generator = make_generator()
tf.keras.utils.plot_model(generator, show_shapes=True, expand_nested=True)
5-4. GANモデルをつくる
1つのbatchに対してdiscriminatorの学習、generatorの学習を続けて行います。それぞれのモデルの構造が違う為にweightの次元も違いますし、learning_rateなどの最適値も違ってくるでしょうからoptimizerも分けているという事だと思います。
class ConditionalGAN(tf.keras.Model):
def __init__(self, discriminator, generator, latent_dim):
super(ConditionalGAN, self).__init__()
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
self.gen_loss_tracker = tf.keras.metrics.Mean(name="generator_loss")
self.disc_loss_tracker = tf.keras.metrics.Mean(name="discriminator_loss")
@property
def metrics(self):
return [self.gen_loss_tracker, self.disc_loss_tracker]
def compile(self, d_optimizer, g_optimizer, loss_fn):
super(ConditionalGAN, self).compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
def train_step(self, data):
# Unpack the data.
real_images, one_hot_labels = data
# Add dummy dimensions to the labels so that they can be concatenated with
# the images. This is for the discriminator.
image_one_hot_labels = one_hot_labels[:, :, None, None] # (64, 10, 1, 1)
image_one_hot_labels = tf.repeat(
image_one_hot_labels, repeats=[image_size * image_size]
)
image_one_hot_labels = tf.reshape(
image_one_hot_labels, (-1, num_classes, image_size, image_size)
) # (64, 10, 28, 28)
image_one_hot_labels = tf.transpose(image_one_hot_labels, (0, 2, 3, 1)) # (64, 28, 28, 10)
# Sample random points in the latent space and concatenate the labels.
# This is for the generator.
batch_size = tf.shape(real_images)[0]
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
random_vector_labels = tf.concat(
[random_latent_vectors, one_hot_labels], axis=1
) # (64, 138)
# Decode the noise (guided by labels) to fake images.
generated_images = self.generator(random_vector_labels) # (64, 28, 28, 1)
# Combine them with real images. Note that we are concatenating the labels
# with these images here.
fake_image_and_labels = tf.concat([generated_images, image_one_hot_labels], -1) # (64, 28, 28, 11)
real_image_and_labels = tf.concat([real_images, image_one_hot_labels], -1) # (64, 28, 28, 11)
combined_images = tf.concat(
[fake_image_and_labels, real_image_and_labels], axis=0
) # (128, 28, 28, 11)
# Assemble labels discriminating real from fake images.
labels = tf.concat(
[tf.ones((batch_size, 1)), tf.zeros((batch_size, 1))], axis=0
) # (128, 1)
# Train the discriminator.
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images) # (128, 1)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
# Sample random points in the latent space.
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim)) # (64, 128)
random_vector_labels = tf.concat(
[random_latent_vectors, one_hot_labels], axis=1
) # (64, 138)
# Assemble labels that say "all real images".
misleading_labels = tf.zeros((batch_size, 1)) # (64, 1)
# Train the generator (note that we should *not* update the weights
# of the discriminator)!
with tf.GradientTape() as tape:
fake_images = self.generator(random_vector_labels) # (64, 28, 28, 1)
fake_image_and_labels = tf.concat([fake_images, image_one_hot_labels], -1) # (64, 28, 28, 11)
predictions = self.discriminator(fake_image_and_labels) # (64, 1)
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# Monitor loss.
self.gen_loss_tracker.update_state(g_loss)
self.disc_loss_tracker.update_state(d_loss)
return {
"g_loss": self.gen_loss_tracker.result(),
"d_loss": self.disc_loss_tracker.result(),
}
5-5. 学習
その時点でgeneratorがどんな画像をつくるのか確認する関数をつくっておきます
def check_generator(generator, n=3):
_, one_hot_labels = next(iter(dataset))
image_one_hot_labels = one_hot_labels[:, :, None, None]
image_one_hot_labels = tf.repeat(
image_one_hot_labels, repeats=[image_size * image_size]
)
image_one_hot_labels = tf.reshape(
image_one_hot_labels, (-1, num_classes, image_size, image_size)
) # (64, 10, 28, 28)
image_one_hot_labels = tf.transpose(image_one_hot_labels, (0, 2, 3, 1)) # (64, 28, 28, 10)
random_latent_vectors = tf.random.normal(shape=(batch_size, latent_dim)) # (64, 128)
random_vector_labels = tf.concat(
[random_latent_vectors, one_hot_labels], axis=1
) # (64, 138)
generated_images = generator(random_vector_labels) # (64, 28, 28, 1)
fake_image_and_labels = tf.concat([generated_images, image_one_hot_labels], -1)
for k in np.random.randint(0, batch_size, n):
label = np.where(image_one_hot_labels[k][0, 0])[0][0]
print('k: {}, label: {}'.format(k ,label))
fake_image_and_label = fake_image_and_labels[k]
print('fake_image_and_label: {}'.format(fake_image_and_label.shape))
plt.imshow(fake_image_and_label[:, :, 0])
plt.show()
fig, ax = plt.subplots(2, 5, figsize=(10, 4))
for pos, channel in enumerate(range(1, 11)):
im = fake_image_and_label[:, :, channel]
i, j = pos // 5, pos % 5
ax[i, j].imshow(im, vmin=0, vmax=1)
ax[i, j].set_xticks([])
ax[i, j].set_yticks([])
plt.show()
check_generator(generator)
discriminator = make_discriminator()
generator = make_generator()
cond_gan = ConditionalGAN(
discriminator=discriminator, generator=generator, latent_dim=latent_dim
)
cond_gan.compile(
d_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
g_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
loss_fn=tf.keras.losses.BinaryCrossentropy(from_logits=True),
)
total_epochs = 0
print('#####################################')
print('### epochs: {}\n'.format(total_epochs))
check_generator(generator, n=3)
for epochs in [10, 10]:
cond_gan.fit(dataset, epochs=epochs)
print('#####################################')
print('### epochs: {}\n'.format(total_epochs))
check_generator(generator, n=3)
補機のgeneratorの出力です。入力もweightの初期値も乱数なので、当然ながら出てくるのは乱数です

10 epoch学習した後のgeneratorです。ちょっとそれっぽくなってきました

40 epoch学習してかなりそれっぽくなっています

6. デバッグするときはeager modeにしよう
Model.compile()すると高速に学習できるようにcompileしてくれるわけですが、その結果エラー発生箇所が分かりにくくなりますが、デバッグする時の為にcompileしないで学習することも出来るようになっています。
model.compile(loss='mse', metrics='mse', optimizer='adam', run_eagerly=True)
7. まとめ
いきなりややこしい学習を書くと動かない原因が分からずつらいので、シンプルなところから1つずつ足していく書き方が良いんじゃないかと思います。
レッツトライ
参考記事
https://qiita.com/tonouchi510/items/1203bfe8e6bdb61d9902
https://zenn.dev/koshian2/articles/5cdc96f2feeda8
https://twitter.com/fchollet/status/1348333222791319554
https://keras.io/guides/making_new_layers_and_models_via_subclassing/
https://qiita.com/tatsuya11bbs/items/7d7a2c920730ae0c592a
https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch
https://qiita.com/shinmura0/items/e51565960648dccf8486