学生だった4年前ぐらいにやったことなんですけど、聞いてください。
※国内に数少ないマイクロタスク型クラウドソーシング関連の記事をせっせと拡充しています。
ご興味ある方はフォローや過去記事も是非!
- 【MTurk入門】機械学習とかでよく耳にするAmazon Mechanical Turkとは&活用例
- Amazon Mechanical Turk API (Python, boto3)を使ってお手軽タスク外注
あらすじ
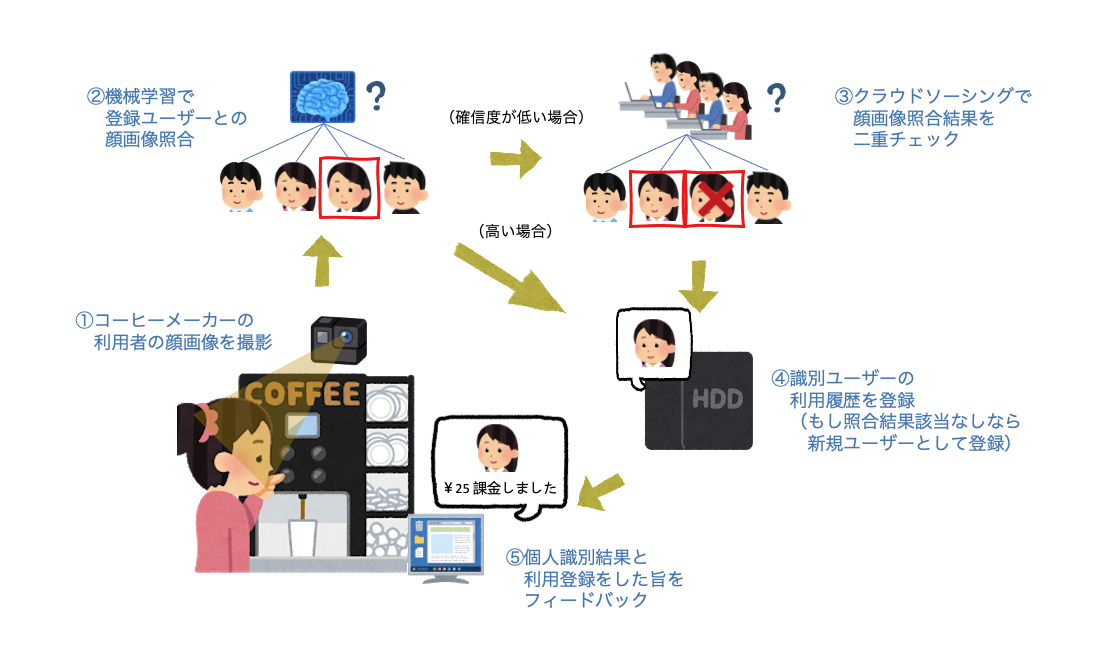
コーヒーマシン使用履歴をうまく記録したい
大学の研究室内で共用のコーヒーメーカー(豆も挽いてくれるやつ)があって、結構な人数が高頻度で使ってたんですが、
コーヒー代(25円/杯)の集金がダルいんですよね。意外と良い方法がなくて、
- 定額サブスク制 → 使用頻度のばらつきで不平が生じる
- コーヒー豆購入を割り勘 → 使用頻度のry
- つど集金箱で回収 → 小銭の用意が面倒すぎる
- 使用履歴をウェブシステムに登録 → し忘れの可能性。
- 使用履歴をすぐ横のメモに記帳 → し忘れの可能性。何よりダサい。情報系の研究室とは?
などなど、案を出しては没になる日々。
要は、
- 使った分だけ従量課金
- 使用履歴をちゃんと残す
さえ簡単にできれば良かったんです。
あとはまあ、数ヶ月おきぐらいにまとめて請求するぐらいで手間はだいぶ減りますからね。
自動化の機運!
まず思いついたのはMLで顔画像認識とかで自動化できるやん?ということなんですが、
- 人がチェック入れないと不安 → 精度次第だし、いちおう金が絡むので。。
- 新規ユーザー登録めんどい → カテゴリ追加(=顔画像の学習データ集め)が現実的じゃない
という問題が発生します。
そんなとき、
じゃあ人手をオンデマンドで外注すればいいじゃない!
という発想が浮かんでしまいました。
まあ、案外悪くないのではと思っていて、
顔画像認識の二重チェックを人間が行ってくれるだけではなく、
もしユーザーの顔が登録ユーザーの誰にも合致しなかった場合、**新規ユーザーとして識別&登録(学習データのラベリング&モデル再学習も含め)**することも出来るわけです。
MLでも出来ないことはないですが、「新規ユーザークラス」とかユーザー毎のモデルを別途用意したりするのは面倒くさいですよね。
面白そう!?はい作りましょう!
作ったもの
実際の見てくれ↓

モニターの表示↓

システム構成
※以下、自分が動かしたときと微妙に違いがあるかも知れません。(なんせ数年前なので、すみません...
まず全体のアーキテクチャです。
コーヒーメーカーの内部は一切いじくりません。外側からなんとかする方針です。
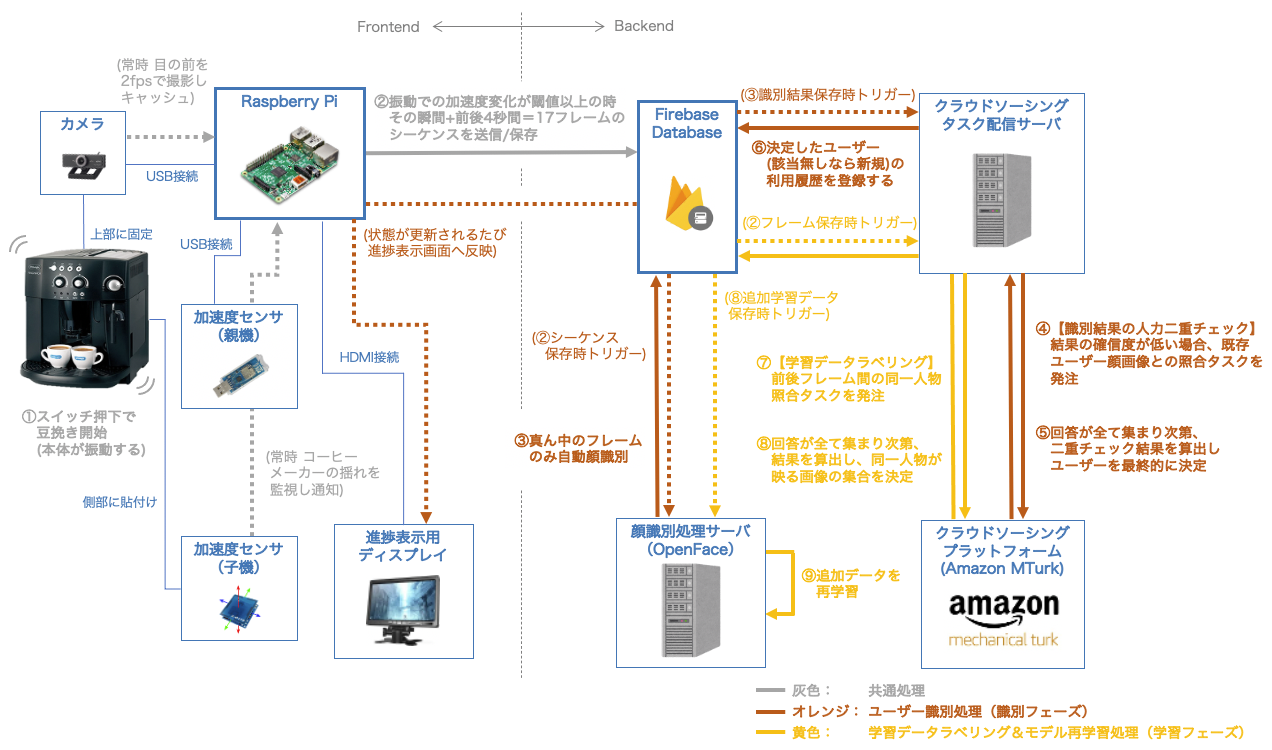
細かくてすみません...(クリックで拡大)。
それぞれ、
灰色(①〜②)の部分はエッジデバイス側の共通処理、
オレンジ(③〜⑥)の部分はユーザー識別処理(識別フェーズ)、
黄色(⑦〜⑨)の部分は学習データラベリング&モデル再学習処理(学習フェーズ) です。
大まかにまとめれば、
豆を挽く時の振動をコーヒーマシン動作とみなし、振動を検知したら撮り溜めていた画像シーケンス(計17枚)をバックエンドに送るということをしたのち、
-
識別フェーズ
- 代表の撮影画像1枚に対しOpenFaceで顔検出&識別処理を行い、出力に自信が無ければAmazon Mechanical Turkのワーカーに聞いた結果を元に最終識別結果を決定
-
学習フェーズ
- 代表画像以外の全ての撮影画像において、代表画像の人物と同じ人物が写っているかどうかをAmazon Mechanical Turkのワーカーに聞き、該当する画像全てに同一ユーザークラスをラベリングしてOpenFaceを再学習
ということをしています。なおフェーズとか言ってますが、識別・学習は同時進行が可能です。
作業
話したいのは主にクラウドソーシングの部分なので、他はざっくり説明します。
フロントエンドの準備
ラズパイ周り
加速度センサ情報受信、カメラ撮影、顔画像識別リクエスト送信などを引き受ける、エッジ側のコアの部分としてラズパイを用いています。
OSはRaspbianを使ったと思います。
-
Raspberry Pi 2 Model B(当時)
- 2 Model BだとWifi モジュールが別途必要でしたね

===
カメラとMONOSTICK(と当時はWifiモジュール)をUSBでぶっ刺しています。

- センサ受信用親機:MONO-WIRELESS MONOSTICK

===
進捗表示用HDMIディスプレイはユーザー識別処理状況をフィードバックする用途ですが、最初から接続しておけば開発にも便利です。
- 全視野178°IPSモニター (・・・覚えてないけどこのあたりだったような)

進捗表示画面は単純にラズパイの中でHTML/CSS/JSでローカルのウェブページとして実装し、Chromiumで全画面表示しました。
順番前後してしまいますが、進捗ステータスは全部Firebase Realtime Databaseから、コールバック関数へプッシュされてくるデータをもとに動的にレンダリングしてました。
最近だと公式ドキュメントはこのあたりでしょうか。
someRef.on('value', (snapshot) => { });...的なアレです。
===
あ、コーヒーメーカーは以下を教授がポケットマネーで買ってくれたのでした。太っ腹〜。

===
さてラズパイでの実装ですが、Pythonで書いたプログラム内で、スレッドなりプロセスなりで
- カメラで2fpsで写真を撮り、過去4秒分までオンメモリで取っておく
- 加速度センサーの出力を監視(し、閾値と比較)する
の2つの処理のループを回しておきます。
1.は良いとして、2.が若干厄介で、以下のような手順を踏んだのを覚えてます。
TWE-Lite-2525A(後述する加速度センサ子機)ではシリアル通信で加速度データが送られてくるので、それをPython側で拾ってあげる必要があるんですね。
カメラの設置
カメラはコーヒーマシンの上に置き、テープで固定しました。あまり手前に置くとユーザーの顔が近づきすぎるので、テストしながらいい塩梅を探ります。

加速度センサ子機の設置

組み立てた後のセンサは、ボタン電池をはめ込むのと反対側が平らになっているので、
そことコーヒーメーカーの側面(豆を入れる場所に近いところ)とを両面テープで接着します。
後から剥がしやすいように上半分だけテープを貼りましたが、振動は割といい具合に取れていたので大丈夫でした。

各種バックエンドサーバ―の準備
※顔識別処理サーバー・タスク配信サーバー用のコンピューターノードは、当時は研究室内のマシンとかを使ったかもですが、今の御時世AWSなりGCPなり何でもokかと思います。
メインデータのやり取り部分
システムのバックエンドの根幹として、Firebase Realtime Databaseを使います。

これを使う理由は、もちろんデータを簡単にクラウドに保存できることですが、やはり自分でバックエンドサーバーを立てる必要がなくなることも大きな利点です。
KVS内でのデータの追加・更新・削除の際のトリガー機能があるので、各サーバープログラム側でリスナーを設定しておくことで、
-
顔識別処理開始のリクエスト
- エッジ側にキャッシュしていた画像データをFirebaseに保存することで実現
-
クラウドソーシングタスク発注のリクエスト
- 顔識別処理結果の確信度をFirebaseに保存することで実現
-
進捗表示用ディスプレイの描画ステータス更新
- 各処理のステータスのフラグをFirebase上で保存・上書きすることで実現
という機能がそれぞれカバーできます。
顔識別処理サーバー
こちらはOpenFaceを使います。Carnegie Mellon Universityで開発されたフリーの顔検出・認識エンジンです。
識別クラス数にもよると思いますが、ごくわずかな学習データ(10クラスぐらいのとき、各クラス20枚ずつとか)でかなり正確に識別できていて驚いた記憶があります。

クラウドソーシング関連の準備
ここが一番アツい部分なので少々ちゃんと取り上げたいと思います。
プラットフォーム
クラウドソーシングプラットフォームの中でも最大規模なサービスの一つである、Amazon Mechanical Turkを使います。

他の多くのプラットフォームとは違い、APIが使えるという利点があります。外注したいタスクをプログラムから動的に発注したり中止したりできるため、今回のケースにも最適!ということでこちらを採用しました。
詳しくは是非以下の記事で!(宣伝)
- 【MTurk入門】機械学習とかでよく耳にするAmazon Mechanical Turkとは&活用例
- Amazon Mechanical Turk API (Python, boto3)を使ってお手軽タスク外注
実際のタスク(HITと呼ばれている)を発注するときには、いくつか方法があるんですが、
一番自由度が高いのはHTTPS経由でアクセスできるウェブサイトのURLをパラメータとして渡してあげる方法です。
こうすると、実際のMTurkワーカー側の作業画面では、そのウェブサイトがIFRAMEで読み込まれる形になります。
若干設計で気をつけるべきポイントがありますが、それはこちらの記事で説明してます。
タスク配信サーバーの準備
というわけでそのタスク(HIT)のウェブページを作ってあげます。
タスク配信サーバーと言ってますが実体はウェブサーバーです。
**①静的配信ページ(タスクの外枠・エントリーポイント用;下図中心部の「ウェブページ」)**と、
**②Web APIのアクセスポイント(タスク内容の動的読み込み&回答記録処理用;下図下部の「タスク配信用ウェブサーバー」)**を用意していきます。
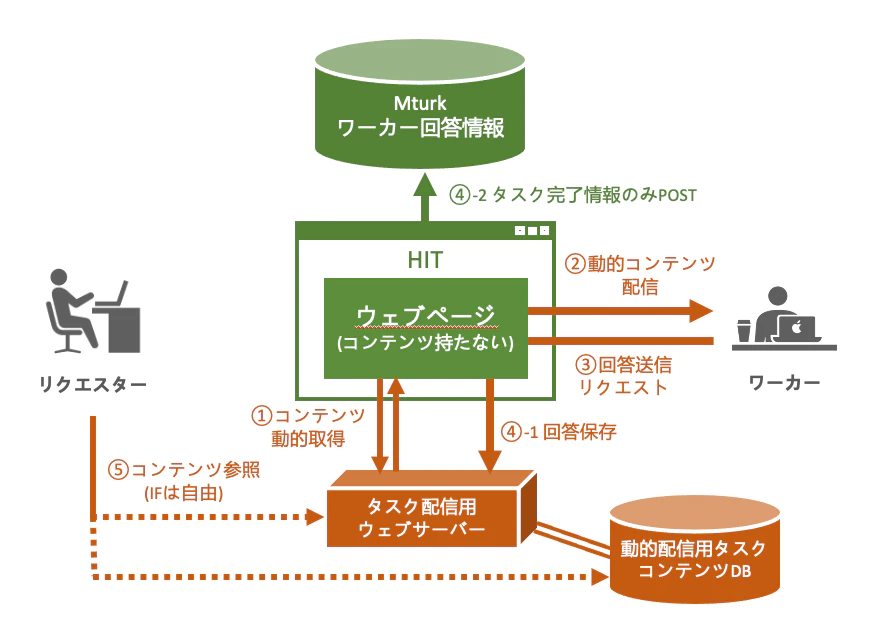
↑は過去記事からの引用で、今回はDBの部分がFirebaseになります。
今回は、識別フェーズと学習フェーズそれぞれ用にわずかに異なるタスクUIを作りました。
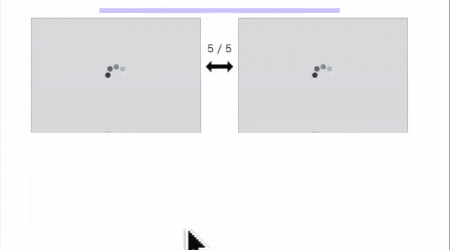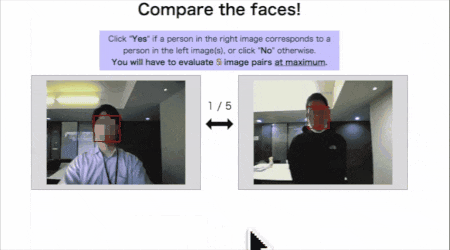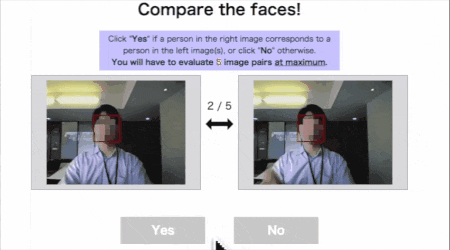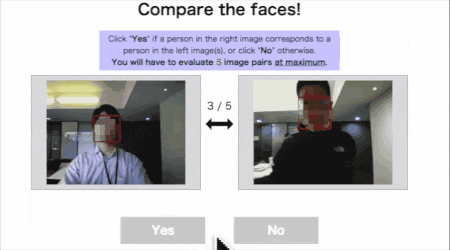
識別フェーズ↓
左は過去画像から切り出された既存ユーザーの顔写真(複数の場合もあり)、
右は今回のユーザーの撮影画像(代表1枚)です。
過去にコーヒーメーカーを使ったユーザーのうち、誰に該当するかを総当りで(AとB、AとC、AとD...)確かめます。

学習フェーズ↓
左は今回のユーザーの代表画像(加速度変化を検知した瞬間のフレーム)、
右は今回のユーザーの代表以外の画像(前後のいずれか1フレーム)です。
代表画像の前後フレームで同じ人物が写っているものがあれば、同一クラスラベルを付与して学習データに使えるので、それらを集めます。
静的ページ(タスク外枠)の設計
ご覧の通りページのテンプレートは同じにしたので、ここでは1パターンだけ作ればOKです。
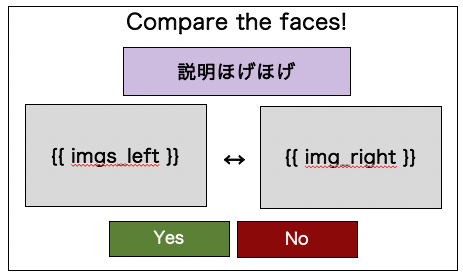
こういうやつです。変数はimgs_leftとimg_rightのみです。
左は識別タスクの時に複数になりうるのでimgs_leftとしてます。
ここの情報を、後述のWeb APIへAjaxリクエストを飛ばして取ってきたりすればいいです。当時はDjangoとかでサーバーサイドレンダリングしてましたが、昨今ではVueとか使ってフロント側で処理したほうが楽でしょう。
【申し訳程度のサンプルコードはこちら】
axiosのAPIは今回実装するものです。
以下は今回の投稿のために取り急ぎ実装したものなのでめちゃ雑ですが、一応大枠は動くはずです。
<html>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script>
<style>
#app { padding-top:20px; width:100%; text-align:center; }
#instruction { background-color:#bb97bb; width:500px; margin:0 auto; }
#imgbox-wrapper { display:flex; width: 850px; margin: 20px auto; justify-content: center; }
.imgbox { margin:20px; padding:5px; width:400px; height:250px; background-color:#eee; border:1px solid black; }
.imgbox>img { max-height:250px; }
.btn { width:200px; font-size:20px; height:40px; color:white; }
#btn-yes { background-color:green; }
#btn-no { background-color:red; }
</style>
<body>
<div id="app">
<h1>Compare the faces!</h1>
<div id="instruction">
Click "Yes" if a person in the right image corresponds to lorem ipsum ...
</div>
<div id="imgbox-wrapper">
<div class="imgbox">
<img v-for="url in img_urls_left" :key="url" :src="url" />
</div>
<div class="imgbox">
<img :src="img_url_right" />
</div>
</div>
<button @click="submitTask('yes')" class="btn" id="btn-yes">Yes</button>
<button @click="submitTask('no')" class="btn" id="btn-no">No</button>
</div>
</body>
<script>
new Vue ({
el: "#app",
data: {
worker_id: "someworkerid", // よしなに動的に変える
img_urls_left: [""],
img_url_right: ""
},
methods: {
requestTask() {
axios.get(`https://hogehoge.io/some/api/to/assign/task/to/${worker_id}`).then((res) => {
this.img_urls_left = res.data.img_urls_left;
this.img_url_right = res.data.img_url_right;
});
},
submitTask(ans) {
axios.post('https://hogehoge.io/some/api/to/submit/task/to',
{ worker_id, ans, img_urls_left, img_url_right }
).then((res) => {
if(res.endTask==true) submitHIT(); // 未実装
else requestTask();
});
}
},
created() {
this.requestTask();
}
});
</script>
</html>
Web APIアクセスポイントの設計
何かしらのウェブサーバーフレームワーク(PythonならDjangoやFlaskもいいですが、最近はasync対応のあるFastAPIやSanicがいいですね)で、以下を作ります。
- ワーカーが要求した時、比較してもらいたい画像対のURLあるいはblobを返すGETリクエスト用エンドポイント
- ある画像対における顔照合回答結果がワーカーから送られた時、回答をFirebaseに送信・保存するPOSTリクエスト用エンドポイント
- 実はここで、今まで集まった回答をもとに多数決をして、最終的な答えを決定する的な処理もしてます。
(※すいません、ここらへんに関してはサンプルコード用意する元気が無かったので後日やる気が出ればで...![]() )
)
MTurk APIからタスクを発注する
AWSのアカウント等を取得し、API用のセキュリティトークンを発行しておく必要があるんですが、この記事のスコープ外なので触れません。このあたりの記事が参考になると思います↓
で、詳しくはこちらの記事に書いてあるのですが、Amazon Mechanical Turk APIのcreateHITメソッドを実行することでタスクを発注します。
タイミングとしては、OpenFaceの顔認識結果がFirebaseに記録された時、確信度が閾値以下のときタスク発注、という感じで、ロジックをサーバープログラムに記述しておきます。
【サンプルコードはこちら】
import boto3
def get_client():
return boto3.client("mturk",
aws_access_key_id = "XXXXXXXXXXXXXXX", # 自分のアカウントのAccessKeyIdを入れる
aws_secret_access_key = "xxxxxxxxxxxxxxxxx", # 自分のアカウントのSecretAccessKeyを入れる
region_name = "us-east-1",
endpoint_url = "https://mturk-requester-sandbox.us-east-1.amazonaws.com" # Sandbox(テスト環境)のエンドポイント
)
if __name__=="__main__":
client = get_client()
res = client.create_hit(
Title="Compare the faces",
Description="Please compare the two suggested human faces and answer whether they are of the same person.",
Keywords="comparison,human,face,easy,image", # コンマ区切りで検索キーワードを指定
Reward="0.05",
MaxAssignments=3, # 受け付ける回答数(=ワーカー数)上限
LifetimeInSeconds=3600, # HITの有効期限を3600秒(1時間)後に設定
AssignmentDurationInSeconds=300, # HITの制限時間を300秒(5分)に設定
Question=f'''
<ExternalQuestion
xmlns="http://mechanicalturk.amazonaws.com/AWSMechanicalTurkDataSchemas/2006-07-14/ExternalQuestion.xsd">
<ExternalURL>https://hogehoge.io/main/index/page/for/task</ExternalURL>
<FrameHeight>800</FrameHeight>
</ExternalQuestion>'''
)
print("HIT ID:", res["HIT"]["HITId"])
print("Status Code:", res["ResponseMetadata"]["HTTPStatusCode"])
完成!
やたらと端折りましたが動かしてみましょう!GOGO!

スイッチをポチッとすると豆をひき始めます。
動画だと伝わらないんですけど、ゴアアアアーーー!って音と振動がけっこうあるんですよね。自宅だと近所迷惑かも

おお...?ザワザワ
知らぬ間に撮られていた写真が、あっという間にOpenFace氏に解析されてしまいました。
右の方に出てるのは確信度ランキングTop2のユーザー顔写真です。(1位の数値0.993とか高いけど、この時は閾値設定してなかったんだな...)
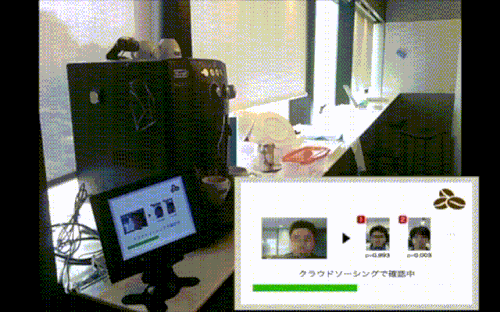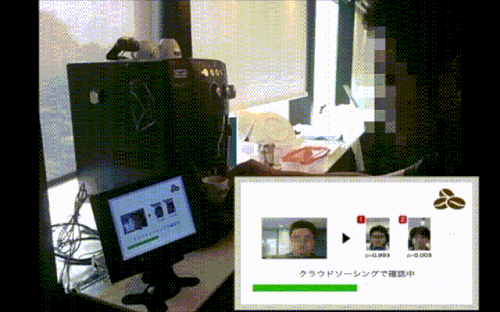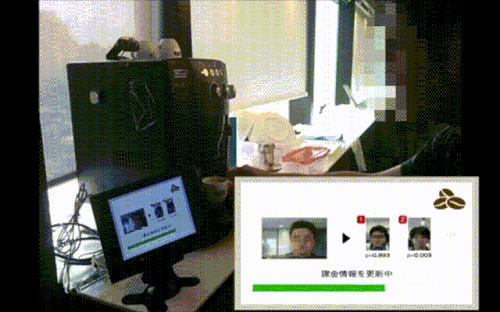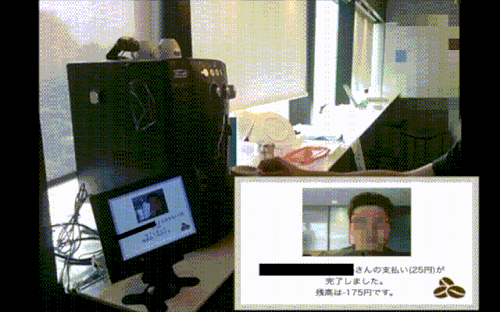
ものの数十秒でクラウドワーカーが二重チェックしてくれました(実はスピードアップのために、ここで触れなかった工夫もしてます。詳しくは未来の別記事にて)。
残高がマイナスになってるのは普通に計算ミスです。すみません。
考察
ドリャッと作ったので、改善点はたくさんあります。
- カメラ
- 照明とか角度の細かい設定は必要。
- 常時ONなので慣れるまで気味悪がられる。
- 加速度センサー
- 閾値の細かい設定は必要。
- 電池交換は半年〜1年に一回必要らしい。
- クラウドソーシング
- システム運用費がかかる。
- プライバシー配慮的には目元を隠すぐらいはしたほうがいいのかも。検証精度は落ちるだろうけど
- レスポンスの早さにはブレがあるけど、ワーカーを引き留めておくための金額とトレードオフ。
中でもプライバシーが気になる人は多いのではと思うのですが、たしかに人間の顔をネットに公開するのは慎重にならないといけないところです。
一応合意の取れているラボメンとかならまだしも、不特定多数の人が映るような環境のカメラ画像とかを公開するのは色々肖像権の問題とかありますので。。この辺りは他の記事で機会があったら話したいと思います。
...他の改善点も多々ありますが、この辺りでお許しくださいませ。
===
...まあ正直なところ、面白そう先行で作ったのであんまり運用は長続きしませんでしたっていうのがオチなんですけど... ![]()
色々と細々とした問題に向き合う時間は必要ですが、逆に時間さえあれば本格的運用もそんなに難しくないシステム構成ではあるのかなと思ってます。
まとめ
以上、Human-In-The-Loop IoT作ってみた記録でした。
また機会があれば他にもクラウドソーシング駆動アプリ、作ってみたいものです。