
(公式Twitterアイコンから拝借)
世界最大規模のクラウドソーシングプラットフォームの1つで、Amazon.comのサービスです。
合わせて読みたい過去記事:
前提:クラウドソーシングとは
知ってる方は飛ばしちゃってください。クリックすると開きます。
...ぐらいの広い言葉なんですが、実施形態としてもう少し細かい分類が主に4種類あり、
-
マイクロタスク型 ... 数秒〜小一時間ぐらいのウェブUI上で完結する作業が主。仕事はすぐに開始でき、ワーカーの作業量に応じて対価が支払われる。
-
プロジェクト型 ... 複雑で専門的知識を伴う仕事をプロジェクトベースで発注する。いわゆる個人事業主・フリーランス的な言葉から連想される形態。
-
コンペティション型 ... デザインなどの創造的な仕事が主に扱われる。公募に対して複数人のワーカーが成果物を提出し、採用されたワーカーのみ金銭報酬を獲得できる。
-
ボランティア型 ... シチズンサイエンスなどで用いられる。金銭報酬は発生せず、代わりに貢献・やりがい・楽しさなどがワーカーのモチベーションとなる。
となっています。
(参考元:機械学習プロフェッショナルシリーズ ヒューマンコンピュテーションとクラウドソーシング1より、自身の解釈により一部文言を編集)
日本国内だとクラウドワークスとかランサーズは聞いたことあるのではないでしょうか。
最近の傾向を追えてないのですが、これらはプロジェクト型・コンペティション型の形態がメインとなっていそうなのがウェブサイトから見て取れます。マイクロタスク型も対応しているようです。
↓ クラウドワークス公式ウェブサイト(https://crowdworks.jp/ )より

↓ ランサーズ公式ウェブサイト(https://www.lancers.jp/ )より

Amazon Mechanical Turk
マイクロタスク型に特化した、英語が共通言語のプラットフォームです。MTurkとかAMTとか略されることが多いです。
概要
通例、マイクロタスク型クラウドソーシングでは、タスクを依頼するユーザーはRequester(リクエスター)、仕事内容は**Microtask(マイクロタスク)と呼ばれます。
特にMTurkでは、マイクロタスクはHIT(ヒットと読む)**とよばれ、仕事を行う単一のウェブページを特に指します。
その他の基本原理は上述したものと同じです。

ワーカーとリクエスターのそれぞれのユーザーになることができます。
※ただしワーカーアカウントに関しては、5~10年ほど前から米国在住者以外のワーカー登録の多くが承認が通らないという状態になっていたりするらしく、登録できる可能性は現状そこまで高くないかもしれません。
ワーカー人口
Difallahらの論文によれば、MTurkでは2017年11月時点で10万人以上のワーカー(常時2千人以上のアクティブなワーカー)を擁しており、75%が米国在住者、16%がインド在住者とのこと。
プラットフォームの言語は英語ですが、依頼するタスクの中身はこれに限りません。
タスク内容
「マイクロ」なタスクといえど、MTurkにおけるタスク内容は様々で、例えば
- 音声や画像などの文字書き起こし
- ウェブサイトの人力スクレイピング
- 長文の要約
- アンケート
- システムの評価実験
など、色んな種類のものが散見されます。
実際の見た目
ワーカーのUIを少しだけ紹介します。
※リクエスタのUIについてはあまり参考になるものが見当たらないので載せませんが、このあたり(公式ガイド)を見るといいかもしれません。
HIT一覧
以下はワーカーがログインしてから最初に見る画面です。
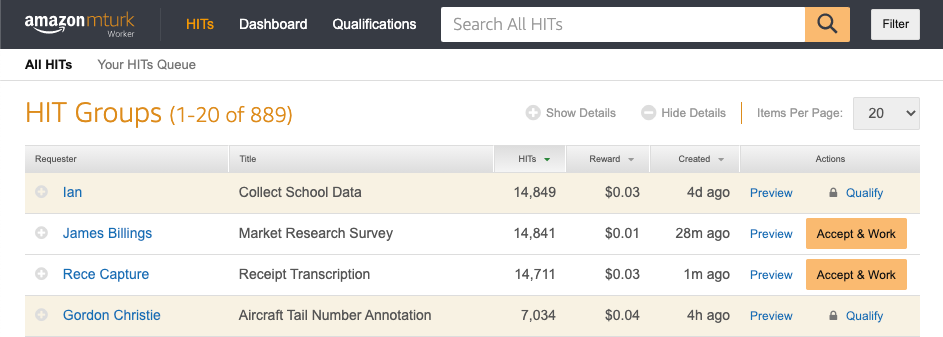
中央〜下部の表は、現在公開されているHITグループの一覧です。
実際は、テーブルの行はもっと下まで(デフォルトだと20件)伸びていて、かつ何十ページもあります。
左から順に、リクエスタ名・タイトル・含むHITインスタンス数・1HITあたり報酬額・グループ公開後の経過日時・HITグループに対する操作 が提示されています。
オレンジ色の行は、HITを行うために資格を得る必要があり、現在は選べないことを表しています。
ページ上部の検索ボックスで任意のクエリを入力することで、HITの絞り込みも可能です。
HIT作業画面
提示された情報を参考に、ワーカーは自分のペースで行いたいHITグループを選び、作業を行っていきます。開始する前に一旦プレビューするか、いきなり開始するかを選ぶことができます。
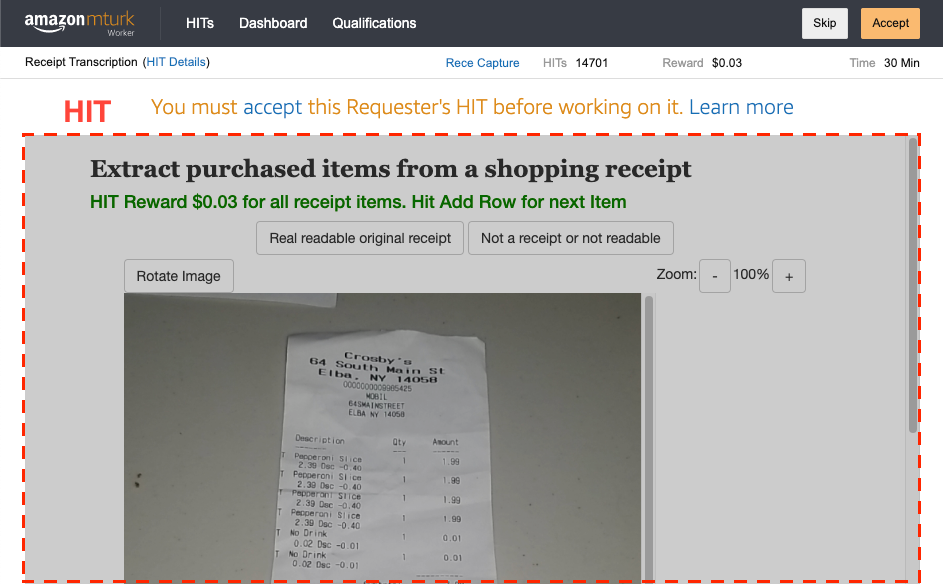
ここでは、「Receipt Transcription」というHITグループに含まれる、1万を超えるHITのうちの1つ(ランダムに選ばれる)がページ内のIFrameとして組み込まれて表示されます。
このHITで作業し回答を提出(Submit)した結果が、UI上部に示された額の報酬が支払われる対象となります。
メリット
クラウドソーシングのプラットフォームが多数存在する中でも、MTurkの強みは小回りがきくこと・自由度が高いことだと思います。
すぐタスクを依頼できる
何もない状態からタスク依頼まで必要なステップは、ざっくりまとめると
- AWSアカウントとMTurkアカウントを作る
- HIT報酬用に、MTurkアカウントへプリペイド金額をチャージ or AWSのクレジットカード情報を紐付ける
- HITを用意する
です2。1.は申込み自体は数分で完了し、2.もログイン後簡単にできます。
一方、かかりそうなのは3.ですが、すぐ使えるテンプレートがたくさん用意されているのがMTurkのアツい点です。これを使えばタスク作りはほぼ終わっているようなもんです。
公式ページからログインしなくても見られます。
2021年2月時点で、アンケート系2種類、ビジョン系11種類、言語系10種類、その他6種類、の合計29種類のテンプレートが用意されていて、割と機能も充実しているので、リクエスタにとってはありがたい環境です。たとえばVisionのInstance Segmentationというテンプレートならこんな見た目になっています。

こういった描画ツールを自作で作るのはなかなか骨が折れますよね。もちろんタスクによってはカスタマイズする必要も出てくるでしょうが、ここまでやってくれるならタスク投げるまでは本当にすぐです。
タスクのカスタマイズが自由
テンプレートがすぐに使えて便利な一方、やはりトレードオフとして設計の制約は付き物ですので、画像はここに置きたいんだ!とか、表示を遅らせたいんだ!など、必ずしも自分のタスク設計に合致するとは限りません。
そういう時は一から自分で作ることももちろんできます。ウェブプログラミングの知識(フロントエンド:HTML/CSS/JavaScript + 必要ならバックエンド)が必要になりますが、この場合はワーカーに自分のウェブアプリのユーザーになってもらうような状態に等しいので、ウェブアプリ上で処理可能・取得可能なことは"原理的には"何でもできます。例えば、
-
ワーカーの回答結果を自前サーバーのDBで管理する
- 通常は「HITページ内のinputタグの値をPOSTしてMTurkのサーバーへ送信・記録する」という方法をとりますが、実は送信情報に回答そのものを含めることは義務ではありません。フォームをPOSTする前に回答情報を自分のウェブサーバー等を経由してDBに別途保存したりするほうが、回答をすぐチェックできるし、検索クエリ等も投げられるし、永続化もできるので、ほとんどの場合扱いやすいです。
-
タスクの中身を動的にワーカーへ配信する
- テンプレートを用いる場合はタスク内容のコンテンツ(ラベリング対象のサンプル等)が静的な配信となるか、できてもHITごとにコンテンツをランダムに出し分ける程度です。自前ページなら、ワーカーのブラウザ上のJavaScriptからバックエンドにAJAXリクエストを投げ、タスクコンテンツを受信して非同期に描画するように組むことで、コンテンツに優先度を設定してサンプルごとの回答の集まりやすさを制御したり、ワーカーの正確さによりタスクを出し分けたりすることが可能です。
実際、私のタスクでもよく上記の手法を用いています。図にして比較すると、まず静的なページを用いた流れが以下のようになるのに対し、

自前アプリを作ると以下のようなことができます(オレンジ色が該当する部分)。

公開APIがある
話の流れ的に一番最後になってしまいましたが、これはMTurk以外の殆どのプラットフォームには用意されていない、最も強力な機能だと思います。
MTurkはそもそもAWSのサービスの一つです。他のAWSのサービスと同じように、MTurkにも実行プログラムから一連の操作を行うことを可能とするAPI群が用意されています。
サポートしている言語も、Python・Javascript(ブラウザ/Node.js)・Ruby・PHP・Javaその他多数...と、かなり幅広いです。
操作対象も相当幅広いです。HIT・ワーカー・Qualification(ワーカーフィルタリング用の資格情報)・回答情報等それぞれのリソースに対し、get/create/delete系のオペレーションが一通り揃っています。先述のように自前サーバーによる運用と組み合わせて使うなどすればかなり最強です。
後述の活用例で具体的に紹介しますが、例えば機械学習アプリケーションの運用に際しては、精度向上や未知データへの対応などのためにActive Learning(能動学習)のようなHuman-In-The-Loopなアプローチは必須になるでしょう。
「モデルが人間を必要としたまさにその時、どこからどうやって人に助けてもらえばいいの?」という問いに対し、**機械学習プログラムの出力の確信度が低い時、自動的にMTurkへアノテーションタスクを投げ、回答が集まった直後にその集計結果を追加学習する!**みたいなのは割と実現しやすく、テンションも上がる方法の一つかもしれません。
MTurkの活用例
あるシステムやワークフローにおけるクラウドワーカーの役割にフォーカスして、色々な観点から紹介していきたいと思います。研究論文がメインですが、どれも実用化まではそう遠くないものです。
個人的に特に推したいポイントとして、クラウドソーシングをデータ集めのために動かすオフラインな用途だけでなく、人間同士が、あるいは人間と機械(ソフトウェア)が、あるシステムの中で協調しながら一つの答えを導くようなオンラインな用途も注目していただきたいと思います。
学習データセット構築
とはいえ真っ先に思いつくのはこの用途ではないでしょうか。
数々の有名な機械学習データセットがMTurkを用いて構築されています。いくつか挙げると以下のとおりです。
-
ImageNet
- 物体名称ラベルが付与された画像データセット。
- ある検索クエリに対してヒットした48枚の画像を提示し、クエリに合致するものを選ばせるHIT3

-
MS COCO
- セグメンテーションとキャプション付与が行われた画像データセット。
- 1つの画像に対し、①画像に映る該当ラベルのオブジェクトの列挙、②列挙されたラベルに対応するオブジェクトの位置の特定、③おおよその位置をもとに行うセグメンテーション、の3つのステップをそれぞれ異なるHITとして作り、それぞれの回答結果を用いてパイプライン化する4。

-
SQuAD
- 文書読解のためのQAデータセット。
- ある段落の文章について、5つ質問文をワーカーに考えてもらい、答えを段落中でハイライトさせるHIT5。

などがあります。それぞれ相当な数(数十万〜数百万)のデータサンプルを含んでいて、大量の人力を比較的容易に動員できるMTurkならではの規模感だと言えるでしょう。
コンテンツクリエーション
MS COCOやSQuADのタスクのように、異なる質問に対する異なるクラウドワーカーの回答をパイプラインで繋ぐことで、クラウドワーカーにクリエイティブな成果物を作ってもらうことも出来ます。
-
Storia:一連のSNS投稿から物語文生成
- Twitterなどの一連のSNS投稿から、ある出来事(サッカーの試合とか)についてのまとめ記事を生成する。
- SNS投稿をワーカーに見せ、①ある投稿についての質問を考える、②その質問に回答する、というHITをそれぞれ行わせ、Q&Aセットを作る。その結果と関連する一連のSNS投稿を見ながら、さらに他の何人かのワーカーが構造を守りながら一段落分の文章を書き、最終的にワーカーの多数決で優れた文章を決める。

「人工知能」風に振る舞う
やたら汎用性の高いAIだ!と思っていたら、実は人間が中に入っていた、というMechanical Turkという名前の由来をそのまんま再現したようなクラウドソーシングの利用法です。
一見ジョークのようにも聞こえますが、機械での自動化をゴリゴリに頑張るよりも、時には人間が解いたほうが色々と都合がいいということを示す、実運用にも至っている大真面目なアプリケーションです。
-
- 目の見えない人でも写真撮影ができ、被写体について任意の質問を投げかけると説明を音声で読み上げてくれるスマホアプリ。私が短期留学中にお世話になったボスが学生だった頃の成果です。
-
スマホで撮影した写真と音声入力した質問クエリをワーカーに提示し、質問に答える説明文を入力させるHIT。HITを小刻みに投げることで常に検索結果上位に来るようにし、ワーカーの目に留まりやすくする手法も用いることで、ユーザーが質問を入力してから最短10秒程度で応答が返ってくる。

-
- Google Hangouts上で動くチャットアプリで、「近場でなんか良い店ない?」的なざっくりした質問など、どんなクエリでも対話を通して柔軟に答えてくれる。
- HIT上にワーカーが待機し、リアルタイムで調べ物やユーザーとのやり取りを行っていく。つまりMTurkワーカーがオペレーターのように振る舞っている。また、未来のユーザーのためにもワーカーをHIT上で待機させておく(プーリングしておく)ことで、アプリを起動した瞬間からワーカーとの対話が可能となる。

機械学習と人間が協調するAI
最後に、クラウドワーカー駆動アプリと機械学習のハイブリッドなアプリケーションを紹介します。機械と人間のそれぞれの得意なところを補いながら、機械学習モデルも同時に成長させていくという、Human-In-The-Loopの王道的な用途です。
-
Zensors:街中のカメラで任意のイベントの自動監視
- 室内・室外問わず好きな場所に設置したカメラの画像について、「今ラウンジのテーブルに座ってる人は何人?」とか「猫はいま何してる?」などの好きなクエリを文字列で登録するだけで、それを周期的にモニタリングできるアプリ。
- ユーザーが監視システム上でカメラを登録する時、特に注目すべき領域が定まっている場合はそれを選択させると、その領域だけを切り取った画像をクエリとともにワーカーへHITとして提示し、質問へ回答させる。

- タスクによっては、段々と実環境のラベル付きデータが集まることで機械学習モデルだけでも良い精度が出るようになる。その場合はクラウドワーカーにHITを投げないことでコストを削減し、未知データなどで識別の確信度が下がった場合にはまたワーカーにHITを投げる。

デメリット
メリットだけを書いているとMTurk教の人だと思われてしまうので、反対の面も書きます。もちろんMTurkは万能ではなく、他のプラットフォームのほうが向いている場合もあるし、なんならクラウドソーシングを使わないほうがいい場面もあります。
ということも踏まえ、ご自身のアクションの参考にしていただけると幸いです。
英語が前提
冒頭にも書きましたが、ワーカーの大半が英語話者なため、作るタスクや集まるデータも英語が基本です。
リクエスターには色んな国籍の人がいるので完璧な英語は必ずしも求められてませんが、あまり拙い英語だとタスク内容そのものへの誤解が生じ、正しく回答が得られないなどのリスクはあります。
日本語タスクを作ることも原理的には可能ですが、もともと日本語話者ワーカーの分母は少ない上、近年は米国人以外のワーカー受け入れを停止しているらしいという情報もあるので、期待しないほうがいいでしょう。
回答精度を高めるには工夫が必要
プラットフォームによってはワーカー一人ひとりの作業品質を重視し、トレーニングやテストを行うところもありますが、MTurkではそういったものはなく、作業の正確性はワーカー個人の経験・スキルやリクエスターのタスク設計に委ねられています。
一般に、特になにもしない(設計したタスクをそのまま公開する)と、時間帯やその時々で変化しますが、集まる2~3割の結果は勘違い回答や**悪意のある回答(ボットも含め)**が集まるというのが私の体感です。
もちろん対策はあり、具体的にいくつか挙げると、
-
ワーカーの事前フィルタリング ... リクエスターが独自に設計した事前テスト用のマイクロタスクにおいて、設定した基準をクリアしたワーカーだけにメインのマイクロタスクを公開する。
-
回答の冗長化 ... たとえば識別タスクのデータラベリングにおいて、1サンプル当たり3人とか5人分の回答を集めて、多数決や平均化処理などを行う。
-
ワーカーの事後フィルタリング ... 明らかに変な回答は目視で弾けばOK。あるいは、定期的に回答が既知の問題を仕込んでおいて、その精度によってワーカーごとの回答結果の扱いを変える。
などがあり、お互いに併用も可能です。上記は比較的簡単だし精度改善も期待できる方法ですが、それでも手間がかかってしまうのは否めないです。
おわりに
Amazon Mechanical Turk (MTurk)の概要と活用例について説明しました。聞いたことあるけどあんま知らない、みたいな方の理解の一助になれば幸いです。
日本では何故か、MTurkはもとより、クラウドソーシング自体がいまいち認知されていません。日本に存在するプラットフォームの特性上、オフラインのデータ収集はまだしも、「機械学習と人力が本当の意味で協調する未来」へのビジョンについてはいまいち見えにくいからかもしれません。
Human-In-The-Loopの研究もだいぶ進んできましたので、向こう数年でいよいよ実用化・ビジネス化の機運が高まってくるころだと思います(私の会社でもまさにそのチャンスを狙っているところです)。こうしたクラウドソーシングの活路を少しでも皆さんに共有し、一緒にこの界隈を盛り上げてくれる仲間が増えたら良いなと思っている次第です。