はじめに
@nishikyonさんのこの記事を参考にして、生成AIのRAGを使ってModelerスクリプトのマニュアルを検索して、Modelerスクリプトを生成してみます。
記事は以下の二本からなります。
①コレクションの作成
②スクリプト生成(この記事)
前の記事で①コレクションの作成を行いました。watsonx.dataのMilvusというベクターDBに、ModelerスクリプトのPDFマニュアルを登録したので、この記事では②スクリプト生成を行います。
RAGでwatsonx.dataのModelerスクリプトのPDFマニュアル検索した結果を用いて、生成AIのwatsonx.aiでModelerスクリプトを生成します。
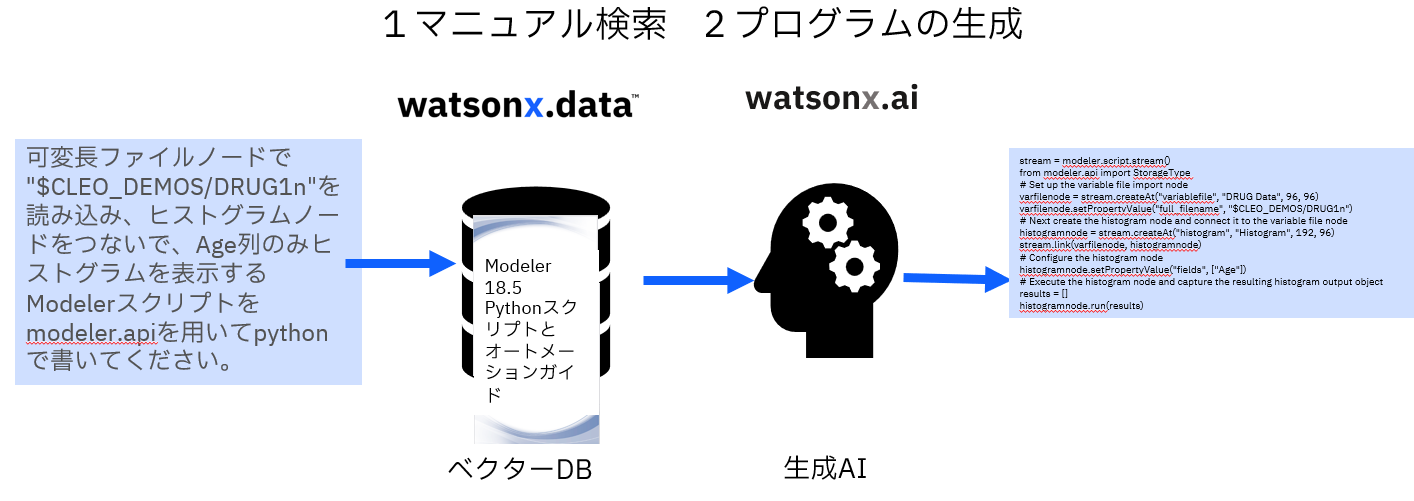
この記事はSPSS秋のユーザーイベント2024の東日本旅客鉄道の堀様のご講演の「ものづくり領域で活かされるSPSSの今とこれから-2異常検知と自動化」でご紹介したデモ③「ModelerのマニュアルをRAGで参照してスクリプトを生成」の解説です。
■テスト環境
- Modeler 18.5
- Windows 11 64bit
- python:3.11.9
- ibm_watsonx_ai:1.1.24
- langchain:0.3.9
- langchain_community:0.3.9
- pypdf:5.1.0
- langchain_huggingface:0.1.2
- langchain_milvus:0.1.7
- langchain-ibm:0.3.5
1. 事前準備
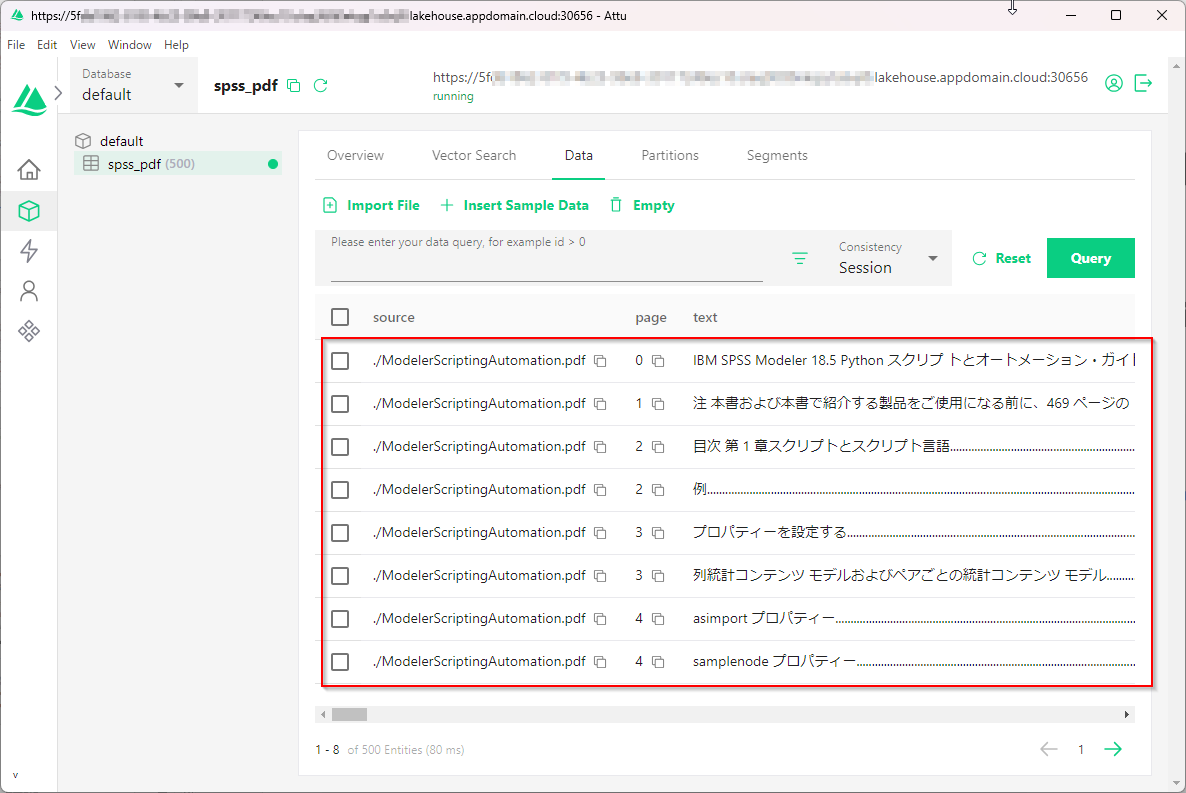
前の記事を参考にspss_pdfのコレクションを作っておいてください。Attuでみて、以下のようなコレクションがあれば、正しく作成されているのでOKです。
2. スクリプト生成のPythonのプログラム
2-1. Milvusへの接続情報をセット
①の記事と同様です。
wxdata_host:GRPCホスト
wxdata_port=GRPCポート
wxdata_user='ibmlhapikey' ←固定値
wxdata_apikey=watsonx.dataに接続できるAPIキー ←パスワードとして使用します。
wxdata_host='xxxxxxxxxxxxxxxxxxxxxxx.lakehouse.appdomain.cloud'
wxdata_port='xxxxx'
wxdata_user='ibmlhapikey'
wxdata_apikey='xxxxxxxxxxxxxxxxxxxxxxx'
接続するDB名(ここではdefault)と①で作成したコレクション名(ここではspss_pdf)を指定しておきます。
db_name ="default"
collection_name = "spss_pdf"
そしてコレクション名以外は、辞書形式にしてmilvus_connection_argsに保存しています(以前はhostとportの指定で動きましたが、langchain_milvus==0.1.7ではuriでの指定が必要でした)。
milvus_connection_args ={
'db_name':db_name,
'uri': "https://"+wxdata_host+":"+wxdata_port,
'user':wxdata_user,
'password':wxdata_apikey,
'secure':True
}
2-3. watsonx.aiへの接続情報をセット
この記事参考に、watsonx.aiへの接続情報をセットします。
watsonx.dataと同じアカウント、同じユーザーであれば同じAPIキーも使えます。
# watsonx.aiのAPIキー
wxai_apikey = 'xxxxxxxxxxxxxxxxxxxx'
# watsonx.aiのプロジェクトID
project_id = 'xxxxxxxxxxxxxxxxxxxx'
# エンドポイントURL
wxai_url = 'https://xxxxxxxxxxxxxxxxxx' #'https://jp-tok.ml.cloud.ibm.com'
2-4. embeddingsの指定
①の記事と同様です。
必ず、コレクションを作成したときと同じembeddingsを指定します。
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2")
2-5. コレクションへの接続
①の記事で作ったコレクションspss_pdfに接続します。
from langchain_milvus import Milvus
vector_store = Milvus(
embeddings,
connection_args=milvus_connection_args,
collection_name=collection_name
)
2-6. watsonx.aiのLLMに接続
watsonx.aiのLLMに接続します。
ここではllama-3-1-70b-instructのモデルを使います。
from ibm_watsonx_ai.metanames import GenTextParamsMetaNames as GenParams
from langchain_ibm import WatsonxLLM
# 使用するLLMのパラメータ
generate_params = {
GenParams.MAX_NEW_TOKENS: 500,
GenParams.MIN_NEW_TOKENS: 0,
GenParams.DECODING_METHOD: "greedy",
GenParams.REPETITION_PENALTY: 1.06
}
# LangChainで使うllm
custom_llm = WatsonxLLM(
model_id="meta-llama/llama-3-1-70b-instruct",
url=wxai_url,
apikey=wxai_apikey,
project_id=project_id,
params=generate_params,
)
2-7. RAGなしでModelerスクリプトを生成:ヒストグラム表示
それでは、Modelerスクリプトを以下のプロンプトで生成します。
可変長ファイルノードで"$CLEO_DEMOS/DRUG1n"を読み込み、ヒストグラムノードをつないで、Age列のヒストグラムを表示するModelerスクリプトをpythonで書いてください。
最初はRAGを使わない場合にどうなるかを見てみます。
単にLLMに上のプロンプトをinvokeして実行しています。
query="""可変長ファイルノードで"$CLEO_DEMOS/DRUG1n"を読み込み、ヒストグラムノードをつないで、Age列のヒストグラムを表示するModelerスクリプトをpythonで書いてください。"""
result=custom_llm.invoke(query)
print(result)
生成されたスクリプトは以下です。
import cleo
# CLEOのデモデータセットをロードします。
cleo.load_demos()
# ファイルノードを作成し、データセットを読み込みます。
file_node = cleo.FileNode()
file_node.file_path = "$CLEO_DEMOS/DRUG1n"
# ヒストグラムノードを作成し、ファイルノードに接続します。
histogram_node = cleo.HistogramNode()
histogram_node.input = file_node.output
# ヒストグラムノードの設定を行います。
histogram_node.column_name = "Age"
histogram_node.bin_count = 10
# Modelerを実行し、結果を取得します。
modeler = cleo.Modeler()
modeler.nodes = [file_node, histogram_node]
result = modeler.run()
# 結果を表示します。
print(result)
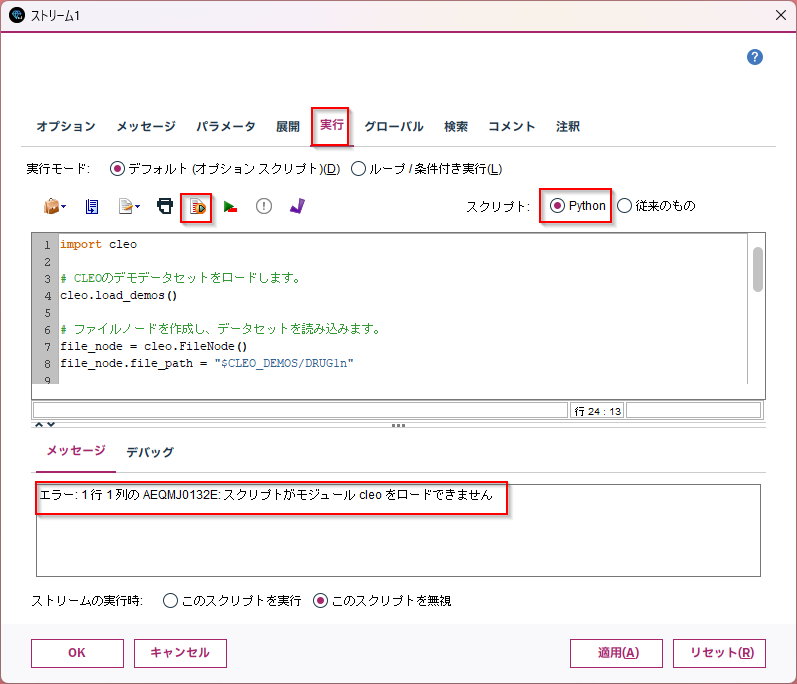
一見、それっぽく見えるかもしれませんが、Modelerスクリプトに設定して実行してみると、いきなりimport cleoが存在しないので動きません。また、メソッドも存在しないものばかりです。ハルシネーションが起きています。
2-8. RAGでModelerスクリプトを生成:ヒストグラム表示
それではRAGでModelerスクリプトを生成してみます。
今度はRetrievalQA.from_chain_typeでLLMとvector_storeのretrieverをセットで与えています。
また、return_source_documents=Trueで検索したマニュアルの情報も取り出しています。
from langchain.chains import RetrievalQA
retriever = vector_store.as_retriever()
qa = RetrievalQA.from_chain_type(llm=custom_llm, chain_type="stuff", retriever=retriever,return_source_documents=True)
answer = qa.invoke(query)
print(answer['result'])
生成されたスクリプトは以下です。
stream = modeler.script.stream()
# 可変長ファイルノードを作成
varfilenode = stream.createAt("variablefile", "DRUG Data", 96, 96)
varfilenode.setPropertyValue("full_filename", "$CLEO_DEMOS/DRUG1n")
# ヒストグラムノードを作成
histogramnode = stream.createAt("histogram", "Histogram", 192, 96)
# 可変長ファイルノードとヒストグラムノードをつなげる
stream.link(varfilenode, histogramnode)
# ヒストグラムノードのプロパティを設定
histogramnode.setPropertyValue("fields", ["Age"])
# ストリームを実行
stream.run()
Modelerスクリプトに設定して実行してみると、ノードは作成されましたが、途中でエラーになりました。
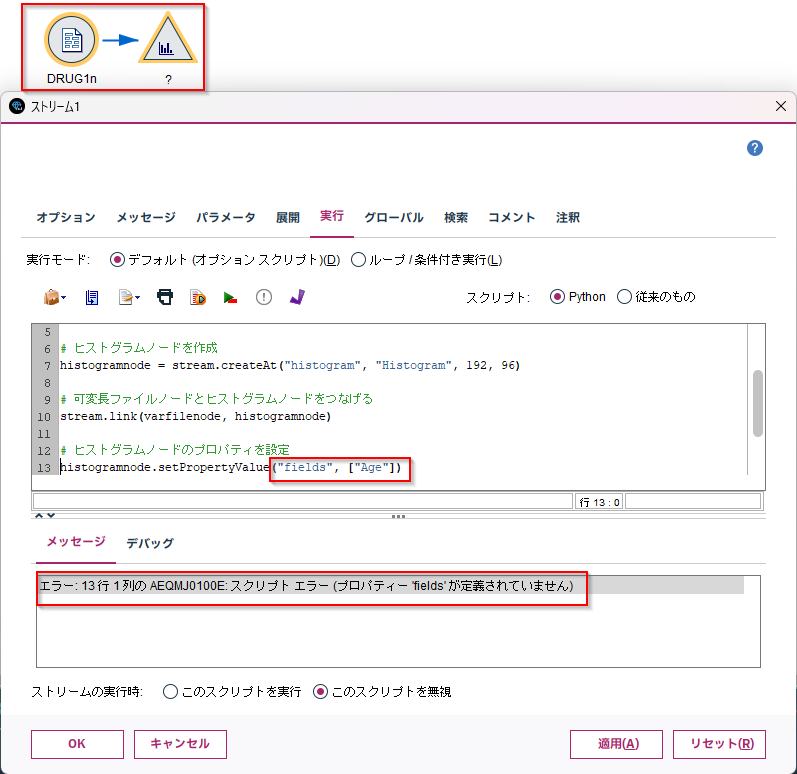
ヒストグラムノードは単一フィールドしか受け取れないのでfieldsというプロパティがないというエラーでした。以下のように修正します。
fields→field
["Age"]→ "Age"
# ストリームを実行
histogramnode.setPropertyValue("field", "Age")
修正して再度実行してみると、Ageの設定はできましたが、ストリーム実行で失敗しました。
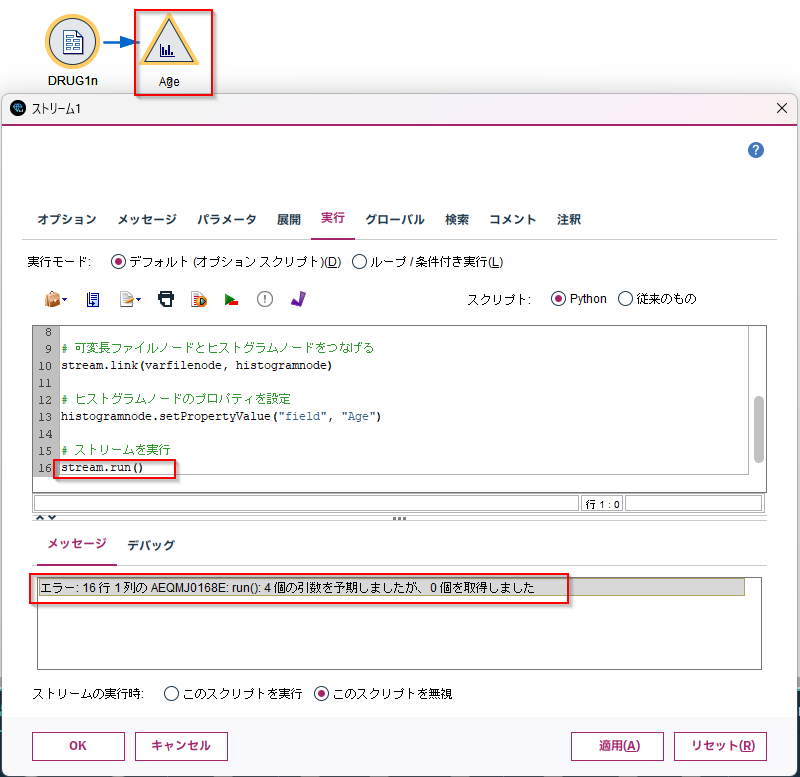
ヒストグラムノードだけを実行すればいいのと、戻り値は受け取らなくてよいので以下のように修正します。
# ヒストグラムノードのプロパティを設定
histogramnode.run(None)
再修正して、実行すると、うまく実行できました。
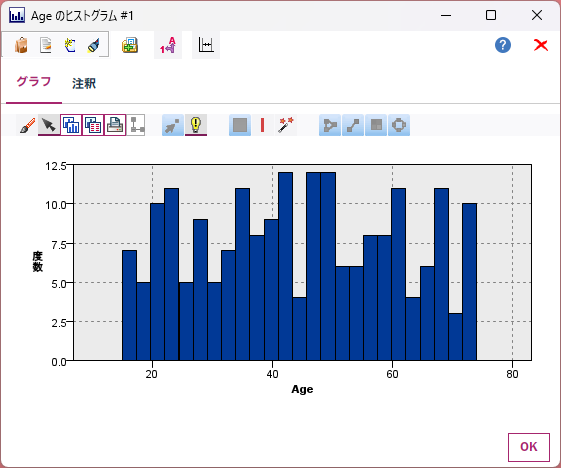
一部修正が必要でしたが、かなり使えるスクリプトを生成できたことがわかります。
2-9. ソース情報の確認
マニュアルのどこを参照したのかを表示してみます。
RetrievalQA.from_chain_typeでreturn_source_documents=Trueを指定したので、source_documentsに参照したマニュアルのページ情報が取れています。
# ソースの情報
source_docs=answer["source_documents"]
for doc in source_docs:
print("Page {:3d}: {:s}".format(doc.metadata['page'],repr(doc.page_content[0:50])))
結果は以下です。
Page 66: '表 26. ノードおよび出力\nノード名 出力名 コンテナ ID\ntable table "table'
Page 483: 'サポート・ベクトル・マシン・モデル\nノードのスクリプト・プロパティー 307\n散布図ノード\nプロパテ'
Page 449: '表 269. tsnenode プロパティー (続き)\ntsnenode プロパティー データ型 プ'
Page 41: '表 12. ノードを作成するためのメソッド (続き)\n方法 戻り値の型 説明\ns.createAt('
以下のページが最も近いと判断したようです。

この検索結果から検索やプロンプトのチューニングを考えることができます。
2-10. RAGでModelerスクリプトを生成:income平均計算
もう一つ別のプロンプトで、今度はincomeの平均を計算させてみます。
プロンプトを変えただけで、RAGでスクリプトを生成させるプログラムのコードは同じです。
# RAGでModelerスクリプトを生成:income平均計算
query="""以下のModelerスクリプトをmodeler.apiを用いてpythonで書いてください。
$CLEO_DEMOS/telco.savをfull_filenameとしてstatisticsimportで読込み、
aggregateノードにリンクし、"region"をキーにして、setKeyedPropertyValueをつかってincomeの平均値を算出してください。
そして、テーブルノードにリンクして下さい"""
from langchain.chains import RetrievalQA
retriever = vector_store.as_retriever()
qa = RetrievalQA.from_chain_type(llm=custom_llm, chain_type="stuff", retriever=retriever,return_source_documents=True)
answer = qa.invoke(query)
print(answer['result'])
生成されたスクリプトは以下です。
import modeler.api
# ストリームの取得
stream = modeler.script.stream()
# statisticsimportノードの作成
stats_import_node = stream.createAt("statisticsimport", "Import", 96, 96)
# full_filenameの設定
stats_import_node.setPropertyValue("full_filename", "$CLEO_DEMOS/telco.sav")
# aggregateノードの作成
aggregate_node = stream.createAt("aggregate", "Aggregate", 192, 96)
# statisticsimportノードからaggregateノードへのリンク
stream.link(stats_import_node, aggregate_node)
# キーの設定
aggregate_node.setPropertyValue("keys", ["region"])
# incomeの平均値の算出
aggregate_node.setKeyedPropertyValue("aggregates", "income", ["Mean"])
# テーブルノードの作成
table_node = stream.createAt("table", "Table", 288, 96)
# aggregateノードからテーブルノードへのリンク
stream.link(aggregate_node, table_node)
Modelerスクリプトに設定して実行してみると、エラーなく、ノードが作られました。
集計ノードを確認してみると、正しくincomeの平均をとっています。
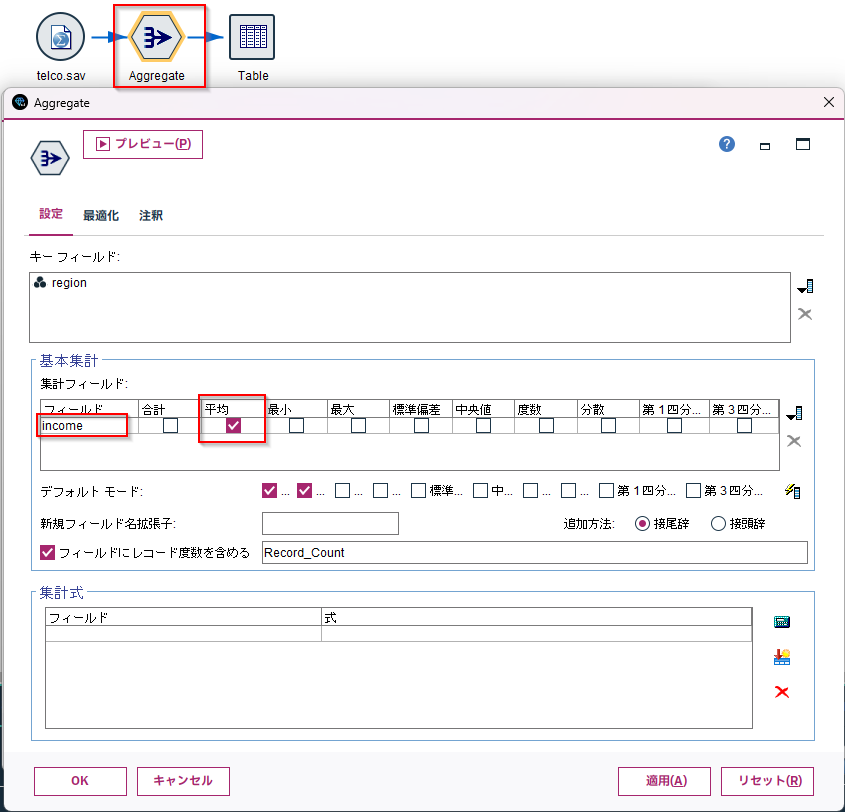
実行してみると、正しく動きました。
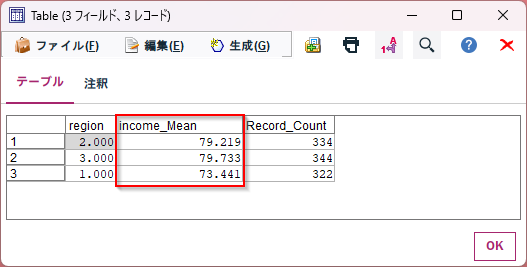
3. まとめ
RAGをつかってModelerスクリプトのマニュアルを読ませることで、なかなかの精度のスクリプトを生成することができました。
Qiita記事なども読ませたりすれば、もっと精度高く生成することができるのではないかと思います。
4. サンプルプログラム
5. 参考
20241127SPSS秋02_東日本旅客鉄道 堀様資料
RAGを使ってModelerスクリプトを生成①コレクションの作成 #SPSS_Modeler - Qiita
watsonx.aiのLLMでLangChainとMilvusを使ってPDFの内容をQ&Aしてみた(=RAG)