0. はじめに
@nishikyonさんのこの記事を参考にして、生成AIのRAGを使ってModelerスクリプトのマニュアルを検索して、Modelerスクリプトを生成してみます。
記事は以下の二本からなります。
①コレクションの作成(この記事)
②スクリプト生成
この記事では、まずはマニュアルを検索できるようにするために①コレクションの作成を行います。
watsonx.dataのMilvusというベクターDBにModelerスクリプトのPDFマニュアルを登録するところまで行います。
次の記事で②スクリプト生成を行います。
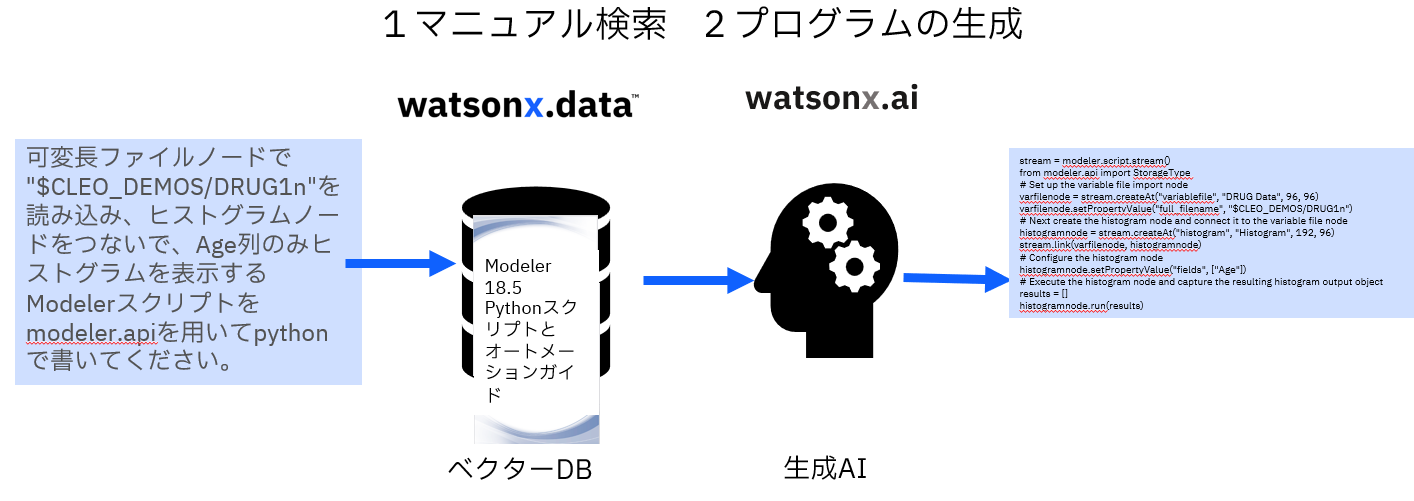
この記事はSPSS秋のユーザーイベント2024の東日本旅客鉄道の堀様のご講演の「ものづくり領域で活かされるSPSSの今とこれから-2異常検知と自動化」でご紹介したデモ③「ModelerのマニュアルをRAGで参照してスクリプトを生成」の解説です。
■テスト環境
- Modeler 18.5
- Windows 11 64bit
- python:3.11.9
- ibm_watsonx_ai:1.1.24
- langchain:0.3.9
- langchain_community:0.3.9
- pypdf:5.1.0
- langchain_huggingface:0.1.2
- langchain_milvus:0.1.7
- langchain-ibm:0.3.5
1. 事前準備
watsonx.dataのセットアップをこの記事に従って行ってください。
また、以下のコマンドなどでライブラリーを導入しておいてください。
py -3.11 -m pip install ibm_watsonx_ai
py -3.11 -m pip install langchain
py -3.11 -m pip install langchain_milvus
py -3.11 -m pip install langchain_community
py -3.11 -m pip install pypdf
py -3.11 -m pip install langchain_huggingface
py -3.11 -m pip install langchain-ibm
そして、Modelerスクリプトのマニュアルをダウンロードしておいてください。
2. コレクション作成のPythonのプログラム
2-1. Milvusへの接続情報をセット
この記事を参考にMilvusへの接続情報をセットします。
wxdata_host:GRPCホスト
wxdata_port=GRPCポート
wxdata_user='ibmlhapikey' ←固定値
wxdata_apikey=watsonx.dataに接続できるAPIキー ←パスワードとして使用します。
wxdata_host='xxxxxxxxxxxxxxxxxxxxxxx.lakehouse.appdomain.cloud'
wxdata_port='xxxxx'
wxdata_user='ibmlhapikey'
wxdata_apikey='xxxxxxxxxxxxxxxxxxxxxxx'
接続するDB名(ここではdefault)と作成するコレクション名(ここではspss_pdf)も指定しておきます。
db_name ="default"
collection_name = "spss_pdf"
そしてコレクション名以外は、辞書形式にしてmilvus_connection_argsに保存しています(以前はhostとportの指定で動きましたが、langchain_milvus==0.1.7ではuriでの指定が必要でした)。
milvus_connection_args ={
'db_name':db_name,
'uri': "https://"+wxdata_host+":"+wxdata_port,
'user':wxdata_user,
'password':wxdata_apikey,
'secure':True
}
2-2. embeddingsの指定
次にページ内容をベクトル化するembeddingsを指定します。
watsonx.aiにもembeddingsはありますが、ここではhuggingfaceのsentence-transformers/paraphrase-multilingual-mpnet-base-v2を使います。
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2")
2-3. PDFの読み込み
PDFを読み込み、ページ分割します。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./ModelerScriptingAutomation.pdf") #ダウンロードしたPDFを指定
# PDF ドキュメントの内容をページで分割する
pages = loader.load_and_split()
2-4. コレクションの作成
Milvus.from_documentsでコレクションを作成し、指定したembeddingsでページデータをベクトル化して挿入します。
一度に全ページを挿入しようとしたところ「RPC error: [batch_insert], <MilvusException: (code=65535, message=Broker: Message size too large: Please try with a smaller batch size.)>, <Time:{'RPC start': '2024-09-13 17:25:30.070110', 'RPC error': '2024-09-13 17:25:32.530650'}> Failed to insert batch starting at entity: 0/500」のエラーが発生したので、n=10ページずつ挿入しました。
from langchain_milvus import Milvus
# 一度に大量データを読み込むとエラーになるのでn件ごとにINSERTする。
n=10
vector_store = Milvus(
embeddings,
connection_args=milvus_connection_args,
drop_old=True, #既存コレクションは削除
auto_id=True,
collection_name = collection_name
)
for i in range(0,len(pages),n):
vector_store.add_documents(documents=pages[i: i+n])
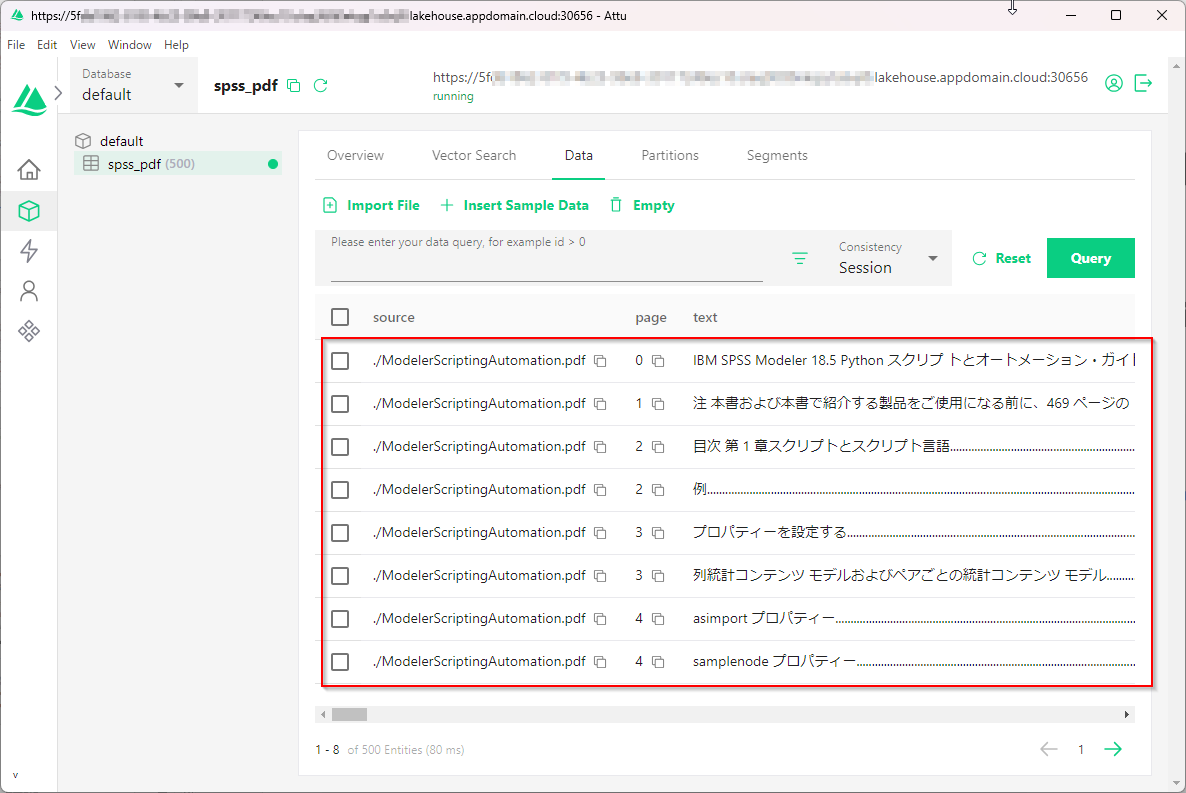
Attuで確認すると以下のようにマニュアルのPDFがコレクションに保存されたことがわかります。
2-5. 検索テスト
マニュアルの類似箇所が検索できるかをsimilarity_searchでテストします。
query="""可変長ファイルノードで"$CLEO_DEMOS/DRUG1n"を読み込み、ヒストグラムノードをつないで、Age列のヒストグラムを表示するModelerスクリプトをpythonで書いてください。"""
docs = vector_store.similarity_search(query,k=5)
for doc in docs:
print({"content": doc.page_content[0:1000], "metadata": doc.metadata} )
以下のような結果になっています。
{'content': '表 26. ノードおよび出力\nノード名 出力名 コンテナ ID\ntable table "table"\nスクリプトの例\nstream = modeler.script.stream()\nfrom modeler.api import StorageType\n# Set up the variable file import node\nvarfilenode = stream.createAt("variablefile", "DRUG Data", 96, 96)\nvarfilenode.setPropertyValue("full_filename", "$CLEO_DEMOS/DRUG1n")\n# Next create the aggregate node and connect it to the variable file node\naggregatenode = stream.createAt("aggregate", "Aggregate", 192, 96)\nstream.link(varfilenode, aggregatenode)\n# Configure the aggregate node\naggregatenode.setPropertyValue("keys", ["Drug"])\naggregatenode.setKeyedPropertyValue("aggregates", "Age", ["Min", "Max"])\naggregatenode.setKeyedPropertyValue("aggregates", "Na", ["Mean", "SDev"])\n# Then create the table output node and connect it to the aggregate node\ntablenode = stream.createAt("table", "Table", 288, 96)\nstream.link(aggregatenode, tablenode)\n# Execute the table node and capture the resulting table output object\nresults = []\ntablenode.run(results)\ntableoutput = re', 'metadata': {'source': './ModelerScriptingAutomation.pdf', 'page': 66, 'pk': 454326554572151249}}
{'content': 'サポート・ベクトル・マシン・モデル\nノードのスクリプト・プロパティー 307\n散布図ノード\nプロパティー 208\nサンプリング・ノード\nプロパティー 135\nシーケンス・モデル\nノードのスクリプト・プロパティー 297, 347\n時間区分ノード\nプロパティー 174\n時間的因果モデル\nノードのスクリプト・プロパティー 308\n識別子 19\n時空間予測ノード\nプロパティー 300\n時系列グラフ・ノード\nプロパティー 211\n時系列ノード\nプロパティー 166\n時系列モデル\nノードのスクリプト・プロパティー 313, 321, 348, 349\n自己学習応答モデル\nノードのスクリプト・プロパティー 299, 347\nシステム\nコマンド・ラインの引数 66\n実行順序\nスクリプトによる変更 51\n自動クラスタリング・ノード\nノードのスクリプト・プロパティー 226\n自動クラスタリング・モデル\nノードのスクリプト・プロパティー 334\n自動数値モデル\nノードのスクリプト・プロパティー 228, 334\n自動分類ノード\nノードのスクリプト・プロパティー 224\n自動分類モデル\nノードのスクリプト・プロパティー 332\nシミュレーション生成ノード\nプロパティー 107\nシミュレーションの当てはめノード\nプロパティー 394\nシミュレーション評価ノード\nプロパティー 393\n集計棒グラフ・ノード\nプロパティー 192\n主成分分析モデル\nノードのスクリプト・プロパティー 249, 339\n出力オブジェクト\nスクリプト名 455\n出力ノード\nスクリプトのプロパティー 381\n順序ノード\nプロパティー 169\n条件抽出ノード\nプロパティー 137\n数学メソッド 21\n数値予測ノード・プロパティー 228\nスーパーノード\nスクリプト 1, 5, 6, 27, 451\nストリーム 27\nプロパティー 451\nプロパティーの設定 451\nparameters 451\nstreams 27\nスクリプト\n以前のバージョンとの互換性 55\nエラーのチェック 54\n概要 1, 15\n共通のプロパティー 76\nグラフ作成ノード 191\n構文 15–17, 19–21, 23–26\nコマンド・ラインから 54\nコンテキスト 28\n実行 11\n従来のスクリプト 458, 459, 463, 465, 466', 'metadata': {'source': './ModelerScriptingAutomation.pdf', 'page': 483, 'pk': 454326554572151708}}
{'content': '表 269. tsnenode プロパティー (続き)\ntsnenode プロパティー データ型 プロパティーの説明\noutput_to string Screen または Output を指定します。\nデフォルトは Screen です。\nfull_filename string 出力ファイル名を指定します。\noutput_file_type string 出力ファイル形式。 HTML または Output\nobject を指定します。 デフォルトは\nHTML です。\nxgboostlinearnode のプロパティー\nXGBoost Linear© は、線型モデルを基本モデルとして使用する勾配ブースティング・\nアルゴリズムの高度な実装です。 ブースティング・アルゴリズムでは、弱い分類子に\n繰り返し学習させ、それを最終的な強い分類子に追加します。 スポス モデラー の\nXGBoost Linear ノードは Python で実装されています。\n表 270. xgboostlinearnode のプロパティー\nxgboostlinearnode のプロパテ\nィー\nデータ型 プロパティーの説明\nTargetField\nバージョン 18.2.1.1 以降は\ntarget に名前変更されています。\nフィールド\nInputFields\nバージョン 18.2.1.1 以降は\ninputs に名前変更されています。\nフィールド\nalpha DOUBLE アルファ線型ブースティング パラメー\nタ。 0 以上の任意の数値を指定してくだ\nさい。 デフォルトは 0 です。\nlambda DOUBLE ラムダ線型ブースティング パラメータ。\n0 以上の任意の数値を指定してください。\nデフォルトは 1 です。\nlambdaBias DOUBLE ラムダ バイアス線型ブースティング パラ\nメータ。 任意の数値を指定します。 デフ\nォルトは 0 です。\nnumBoostRound\nバージョン 18.2.1.1 以降は\nnum_boost_round に名前変更さ\nれています。\ninteger モデル作成用の num boost round 値。 1\nから 1000 の間の値を指定します。 デフ\nォルトは 10 です。\n440\xa0\xa0IBM SPSS Modeler 18.5 Python スクリプト', 'metadata': {'source': './ModelerScriptingAutomation.pdf', 'page': 449, 'pk': 454326554572151670}}
{'content': '表 12. ノードを作成するためのメソッド (続き)\n方法 戻り値の型 説明\ns.createAt(nodeType,\nname, x, y)\nノード 指定したデータ型のノードを作成\nして、指定したストリームの指定\nした場所に追加します。 x < 0 ま\nたは y < 0 の場合、場所は設定さ\nれません。\ns.createModelApplier(mode\nlOutput, name)\nノード 提供されたモデル出力オブジェク\nトから派生したモデル・アプライ\nヤー・ノードを作成します。\n例えば、ストリーム内に新しいデータ型ノードを作成するには、以下のスクリプトを使用できます。\nstream = modeler.script.stream()\n# Create a new type node\nnode = stream.create("type", "My Type")\nノードのリンクとリンク解除\nストリーム内に新しいノードを作成する場合、そのノードを使用するにはノードのシーケンスに接続する\n必要があります。 ストリームには、ノードをリンクおよびリンク解除するための多くのメソッドがありま\nす。 これらのメソッドを次の表に要約します。\n表 13. ノードをリンクおよびリンク解除するためのメソッド\n方法 戻り値の型 説明\ns.link(source, target) 適用外 入力ノードとターゲット・ノード\nの間に新しいリンクを作成しま\nす。\ns.link(source, targets) 適用外 入力ノードと指定されたリスト内\nの各ターゲットの間に新しいリン\nクを作成します。\ns.linkBetween(inserted,\nsource, target)\n適用外 他の 2 つのノード・インスタンス\n(入力ノードとターゲット・ノー\nド) の間にノードを接続し、 挿入し\nたノードの位置がこれらのノード\nの間になるように設定します。\n入力ノードとターゲット・ノード\nの間の直接リンクが最初に削除さ\nれます。\ns.linkPath(path) 適用外 ノード・インスタンスの間の新し\nいパスを作成します。 最初のノ\nードが 2 番目のノードにリンクさ\nれ、2 番目のノードが 3 番のノー\nドにリンクされ、以下同様にリン\nクされます。\ns.unlink(source, target) 適', 'metadata': {'source': './ModelerScriptingAutomation.pdf', 'page': 41, 'pk': 454326554572151221}}
{'content': '第 9 章 入力ノードのプロパティー\n入力ノードの共通プロパティー\nすべての入力ノードに共通するプロパティーを次に一覧にします。その後に、特定のノードに関する情報\nが続きます。\n例 1\nvarfilenode = modeler.script.stream().create("variablefile", "Var. File")\nvarfilenode.setPropertyValue("full_filename", "$CLEO_DEMOS/DRUG1n")\nvarfilenode.setKeyedPropertyValue("check", "Age", "None")\nvarfilenode.setKeyedPropertyValue("values", "Age", [1, 100])\nvarfilenode.setKeyedPropertyValue("type", "Age", "Range")\nvarfilenode.setKeyedPropertyValue("direction", "Age", "Input")\n例 2\nこのスクリプトは、指定されたデータ ファイルに、複数行の文字列を表す Region というフィールドが含\nまれていることを前提とします。\nfrom modeler.api import StorageType\nfrom modeler.api import MeasureType\n# Create a Variable File node that reads the data set containing\n# the "Region" field\nvarfilenode = modeler.script.stream().create("variablefile", "My Geo Data")\nvarfilenode.setPropertyValue("full_filename", "C:/mydata/mygeodata.csv")\nvarfilenode.setPropertyValue("treat_square_brackets_as_lists", True)\n# Override the storage type to be a list...\nvarfilenode.setKeyedPropertyValu', 'metadata': {'source': './ModelerScriptingAutomation.pdf', 'page': 90, 'pk': 454326554572151275}}
以下のページが最も近いと判断したようです。

ここまででwatsonx.dataのMilvusのコレクションを作成し、Modelerスクリプトのマニュアルを投入することができました。
3. サンプル・プログラム
4. 参考
20241127SPSS秋02_東日本旅客鉄道 堀様資料
RAGを使ってModelerスクリプトを生成②スクリプト生成 #SPSS_Modeler - Qiita
watsonx.aiのLLMでLangChainとMilvusを使ってPDFの内容をQ&Aしてみた(=RAG)