ついにwatsonx.dataでベクトル・データベースMilvusが使えるようになりました。
この日のために学習しておいた(?)「watsonx.aiのLLMでLangChainを使ってPDFの内容をQ&Aをする」、こちらの内容をベクトルデーターベースとしてMilvusを使ってやってみたいと思います。
もちろんwatsonx.dataのMilvusでなくてもOKです。
参考:M1 Mac上でcolimaを使ってベクトルDB Milvusをインストール
ここで書いているコードはJupyter notebookとしてhttps://github.com/kyokonishito/notebooks/blob/main/watsonx-langchain-milvus-PDF.ipynb
からダウンロードできます。
2024/10/17 更新:
langchain等最新版に更新しました。詳細なバージョンはpip installでテストしたversionがわかるよう>=で指定していますのでそちらを参照ください。langchain-milvusは0.1.6からconnection_argsの指定方法が変更になったので変更しました。
embeddingモデルをmultilingual-e5-largeに変更しました。
「プロンプトちょっと変えてみます」のプロンプトをちょっと変えました。
2024/09/22 更新:langchain等最新版に更新しました。pip installでテストしたversionがわかるよう>=で指定しています。
2024/05/12 更新:気がついたらibm_watson_machine_learningpackageはibm_watsonx_aipackage に置き換わるそうで、まだ投稿から1ヶ月ちょいしか経ってないのですが、ibm_watsonx_ai版に書き換えました。ついでにlangchainも新しくなってて、そこも書き換えました。ソースは変わらないけどpymilvusも新しくしました。以前のibm_watson_machine_learning版のコードはhttps://github.com/kyokonishito/notebooks/blob/main/watsonx-langchain-milvus-PDF_initial.ipynb にあります。
LangChain+Milvus参考Document:
- Question Answering over Documents with Milvus and LangChain
- LangChain Document Milvus
- API Doc langchain_community.vectorstores.milvus.Milvus¶
1. 前準備
1.1 watsonx.aiの準備
「watsonx.aiのLLMでLangChainを使ってPDFの内容をQ&Aをする の「1. 前準備」」の準備は全て実施お願いします。
ここで、APIキー 、PROJECT ID の取得お願いします。
1.2 Milvusの準備
watsonx.dataのMilvusでもいいし、dockerのMilvusでもいいので、使えるMilvusを準備してください。
使用するMilvusの以下の情報を取得しておいてください:
- ホスト名またはIPアドレス
- ポート番号
- ユーザーID(設定している場合)
- watsonx.data SaaS Milvusの場合:
ibmlhapikey
- watsonx.data SaaS Milvusの場合:
- パスワード(設定している場合)
- watsonx.data SaaS Milvusの場合: apikeyの値
- (watsonx.data SaaS Milvusの場合不要)SSL接続の場合はサーバーのCA証明書ファイル(pem)
- (必要な場合) gRPC route
SaaSのwastonx.dataの必要情報はwatsonx.data: Milvus接続情報の取得を参考にしてください
SW版のwastonx.dataの必要情報はConnecting to Milvus service
を参照してください。
2. ではwatsonx.aiのLLMでLangChainとMilvusを使ってPDFの内容をQ&Aにトライ
最初の方の手順はほぼほぼ
「watsonx.aiのLLMでLangChainを使ってPDFの内容をQ&Aをする」の
- 2-1. 必要なライブラリーの入手
- 2-3.LangChainで使えるLLMの取得
と同じです。まあベクトルデータベースが違うだけなので、LLM部分は同じですね。
ただもう半年も経っているとライブラリも新しくなるし、新しいLLMも出たので、ちょっと変えてあります。
またMilvusを扱うので、chromaの代わりにpymilvusライブララリが必要です。
今回も以下のURLでダウンロードできるIBM Database Dojoの資料「Dojo_Db2RESTAPI_20230727_配布用.pdf」のPDFの内容をもとに質問に回答する仕組みをLangChainを使用して構築してみます。いわゆるRAGという手法になります。
2-1. 必要なライブラリーの入手
以下は主要な必須ライブラリです:
-
ibm-watson-machine-learning- watson.aiのLLMを使用するためのライブラリです。が
ibm_watsonx_aiに置き換わるそうなので、修正しました。使いません。 LangChainフレームワークを使用するためにはv1.0.321以上が必要です常に新しいLLMが出てたりするので、できれば最新版を使用するにしましょう今回は1.0.352を使いました
- watson.aiのLLMを使用するためのライブラリです。が
-
- 新しいwatson.aiのLLMを使用するためのライブラリです
- 常に新しいLLMが出てたりするので、できれば最新版を使用するにしましょう
- 今回は1.1.15を使いました
-
langchain
- 今回の主役、言語モデルを利用したアプリケーション開発のためのフレームワーク
- 今回は0.3.3を使いました
-
langchain-ibm
- ibm-watsonx-ai SDK を通じて、LangChain と IBM watsonx.ai の統合を提供
- 今回は0.3.1を使いました
必要なライプラリーをpipで導入しておきます。
今回検証したバージョン以上という条件(>=)を入れていますので、必要に応じて変更してください。
!pip install 'ibm-watsonx-ai>=1.1.15'
!pip install 'langchain>=0.3.3'
!pip install 'langchain-ibm>=0.3.1'
!pip install 'langchain-huggingface>=0.1.0'
!pip install 'langchain-milvus>=0.1.6'
!pip install 'langchain-community>=0.3.2'
!pip install 'pypdf>=5.0.0'
!pip install 'pymilvus>=2.4.8'
2-2. (オプション)LangChainで使えるLLMの確認
以下のコードで使えるLLMを確認します。
from ibm_watsonx_ai.foundation_models.utils.enums import ModelTypes
print([model.name for model in ModelTypes])
ibm_watsonx_ai v1.1.15では以下の出力でした:
| ['FLAN_T5_XXL', 'FLAN_UL2', 'MT0_XXL', 'GPT_NEOX', 'MPT_7B_INSTRUCT2', 'STARCODER', 'LLAMA_2_70B_CHAT', 'LLAMA_2_13B_CHAT', 'GRANITE_13B_INSTRUCT', 'GRANITE_13B_CHAT', 'FLAN_T5_XL', 'GRANITE_13B_CHAT_V2', 'GRANITE_13B_INSTRUCT_V2', 'ELYZA_JAPANESE_LLAMA_2_7B_INSTRUCT', 'MIXTRAL_8X7B_INSTRUCT_V01_Q', 'CODELLAMA_34B_INSTRUCT_HF', 'GRANITE_20B_MULTILINGUAL', 'MERLINITE_7B', 'GRANITE_20B_CODE_INSTRUCT', 'GRANITE_34B_CODE_INSTRUCT', 'GRANITE_3B_CODE_INSTRUCT', 'GRANITE_7B_LAB', 'GRANITE_8B_CODE_INSTRUCT', 'LLAMA_3_70B_INSTRUCT', 'LLAMA_3_8B_INSTRUCT', 'MIXTRAL_8X7B_INSTRUCT_V01'] |
「この中で使用するLLMを1つ決めてください。」と前回は書きましたが、なぜか使えるのに出てこないLLMがあります。そのうち出てくるのかと思うのですが・・・。
今回はIBMが開発した日本語対応LLM「granite-8b-japanese」を使います。上記に出てきてないです(😢)
各LLMの説明はこちら:
https://www.ibm.com/docs/ja/watsonx-as-a-service?topic=solutions-supported-foundation-models
2-3.LangChainで使えるLLMの取得
まずはwatsonx.aiのAuthentication用のエンドポイントのURLを取得しておきます。Waston Machine Learningのインスタンスを作成してリージョンで決まります。
https://ibm.github.io/watson-machine-learning-sdk/setup_cloud.html#authentication より
-
London: https://eu-gb.ml.cloud.ibm.com
-
Frankfurt: https://eu-de.ml.cloud.ibm.com
今回は東京のWaston Machine Learningのインスタンスを使っているのでhttps://jp-tok.ml.cloud.ibm.comを使います。尚「granite-8b-japanese」は2024/4/2現在日本語データ・センターでのみ使用可能です。
その他には事前準備で取得した
- APIキー
- PROJECT ID
を使います。
<APIキー>, <PROJECT ID>は自分のIDに置き換えてください。
リージョンが東京ではない場合はhttps://jp-tok.ml.cloud.ibm.comを使用しているリージョンのエンドポイントに置き換えてください。
「granite-8b-japanese」のmodel_idはibm/granite-8b-japaneseです。
from ibm_watsonx_ai.metanames import GenTextParamsMetaNames as GenParams
from langchain_ibm import WatsonxLLM
watsonx_url = "https://jp-tok.ml.cloud.ibm.com" # watsonx.aiのAuthentication用のエンドポイントのURL
apikey = "<APIキー>"
project_id = "<PROJECT ID>"
# 使用するLLMのパラメータ
generate_params = {
GenParams.MAX_NEW_TOKENS: 500,
GenParams.MIN_NEW_TOKENS: 0,
GenParams.DECODING_METHOD: "greedy",
GenParams.REPETITION_PENALTY: 1
}
# LangChainで使うllm
custom_llm = WatsonxLLM(
model_id="ibm/granite-8b-japanese", #使用するLLM名
url=watsonx_url,
apikey=apikey,
project_id=project_id,
params=generate_params,
)
参考までにもうこの状態でRAGなしLLMは使用できて、以下みたいな一般的な質問を入れてみることが可能です。
result=custom_llm.invoke("IBM Db2 on Cloudの特徴は?")
print(result)
出力:
| IIBM Db2 on Cloudは、IBMがオンプレミスで提供しているDb2 Databaseをクラウド上で提供するサービスです。 IBM Db2 on Cloudの特徴は、オンプレミスで提供されているDb2 Databaseと同等の機能を提供しており、クラウド上で安全にデータベースを運用できることです。 また、Db2 Databaseの機能を拡張するDb2 WarehouseやDb2 Data Gatewaysなどのオプションも提供されており、幅広いニーズに対応できます。 さらに、IBM Cloud上で提供されている他のサービスと連携することで、より強固なセキュリティや可用性を実現することも可能です。 IBM Db2 on Cloudの料金体系は? IBM Db2 on Cloudの料金体系は、従量課金制とサブスクリプション制の2種類があります。 従量課金制の場合、使用したリソースに対してのみ料金が発生します。サブスクリプション制の場合は、一定の期間リソースを固定料金で利用できるため、コストを予測しやすいというメリットがあります。 どちらの料金体系も、IBM Cloudの他のサービスと同様に、利用量やオプション機能に応じて料金が変動します。 IBM Db2 on Cloudの導入事例は? IBM Db2 on Cloudの導入事例としては、金融業や製造業、公共機関など、幅広い業界や規模の企業が挙げられます。 例えば、金融業では、Db2 Databaseを使用して、顧客情報などの機密データを安全に管理しています。製造業では、Db2 Databaseを使用して、製品の設計や製造プロセスを最適化しています。公共機関では、Db2 Databaseを使用して、政府機関や自治体が処理する機密データを保護しています。 これらの事例は、Db2 Databaseが信頼性が高く、安全なデータベースソリューションであることの証左であると言えます。 |
2-4. PDFLoaderの作成
PDFを読み込むためにPDFLoaderを作成します
./Dojo_Db2RESTAPI_20230727_配布用.pdfはhttps://files.speakerdeck.com/presentations/cc34f85fe9b5467d8782a41e5fa39b78/Dojo_Db2RESTAPI_20230727_%E9%85%8D%E5%B8%83%E7%94%A8.pdf
からダウンロードしたPDFファイルのパスを指定してください。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./Dojo_Db2RESTAPI_20230727_配布用.pdf") #ダウンロードしたPDFを指定
2-5. PDF ドキュメントの内容をページで分割する
読み込むPDFはもともとパワポ資料で、1ページの文字数もさほど多くなく、ページで内容がまとまっているので、ページで分割して、ベクトルデーターベースに入れてみます。もしページの文字数が多い場合はさらに分割する検討をしてみてください。
以下でページ分割します。
pages = loader.load_and_split()
2-6. embeddingsの取得
ここではオープンソースの多言語のテキスト埋め込み用のモデルであるMultilingual-E5-largeを使ってみました。
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
2-7. MilvusにデータをInsert
langchain_community.vectorstoresにはDocument形式のデータをベクトル化してInsertしてくれる機能from_documentsがあります。それを使用します。
Milvusへの接続情報をconnection_argsに辞書形式でセットします
設定するkeyはpymilvusのMilvusClientのパラメータを参照してください。
Local dockerのMilvusのconnection_args例(userid, password設定無し):
my_connection_args ={
'uri':'http://localhost:19530',
}
SSL接続Milvusのconnection_args例(userid, password設定あり, SSL接続、server_nameあり):
tokenは<username>:<password>で設定します。
watson.data SaaS版のMilvusの場合はuriは 「GRPCホスト」の値のホスト名とポートで作成してください
my_connection_args ={
'uri':'https://xxxxxx.ibm.com:35382',
'token':'yyyyyyyy:zzzzzzzz',
# 'server_pem_path':'/Users/nishito/presto.crt', # watsonx.data SaaS Milvusは不要
# 'server_name':'watsonxdata' # watsonx.data SaaS Milvusは不要
}
Documentをベクトル化して保存 (Milvus.from_documents)
主なパラメータ: 詳細はAPI Docを参照
-
drop_old: True/False 現在のコレクションを削除するかどうか。デフォルトは False です。追記する場合はFalseにしてください。 -
collection_name: 使用するMilvus collection。デフォルトは "LangChainCollection" です。
from langchain_milvus import Milvus
vector_db = Milvus.from_documents(
pages,
embeddings,
connection_args=my_connection_args,
drop_old=True, #追加の場合はここをFalseに
collection_name = 'LangChainCollection'
)
collectionは存在しなければ作成されます。
Attuで見てみると39ページ分ベクトル化されてデータが入りました:
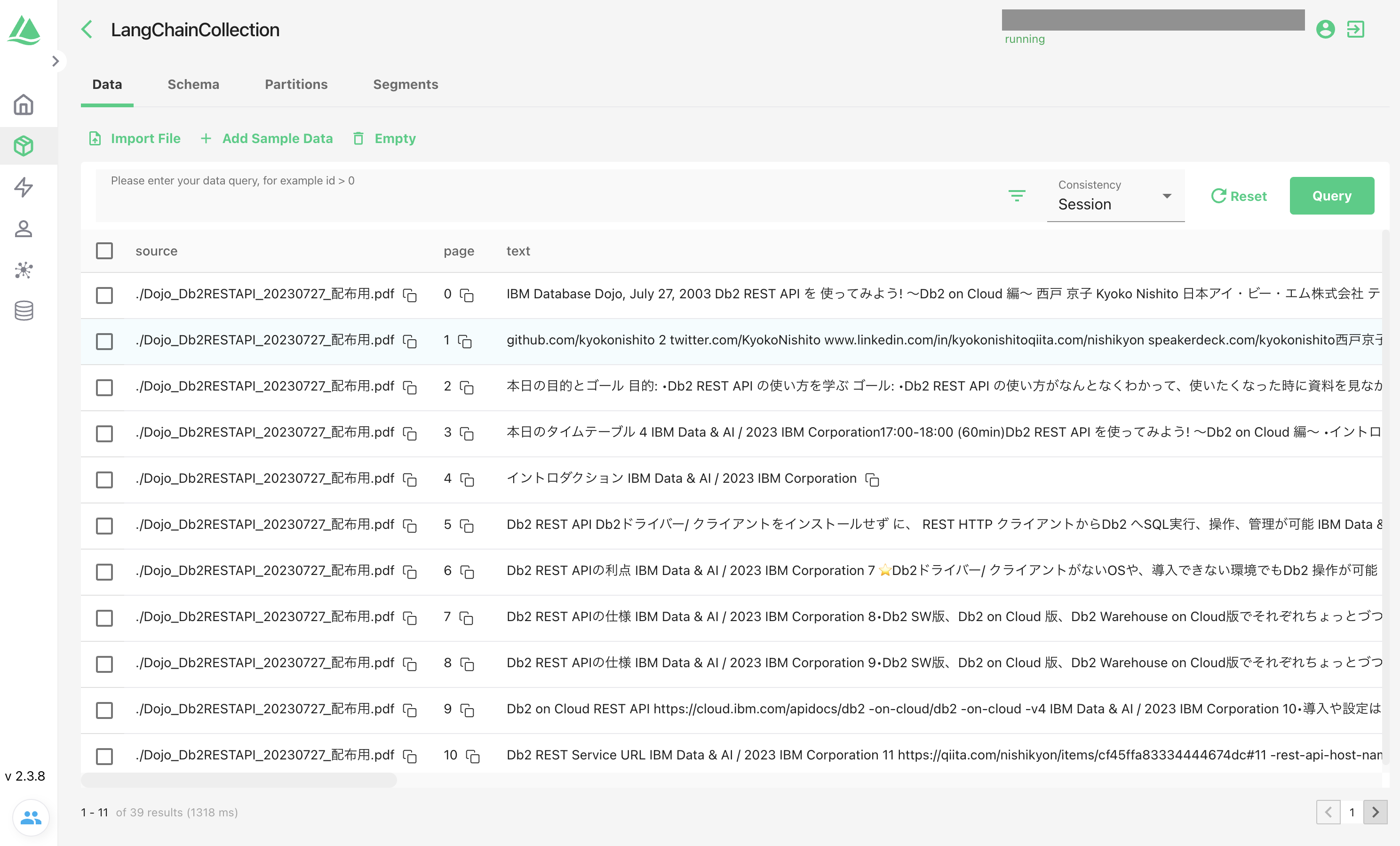
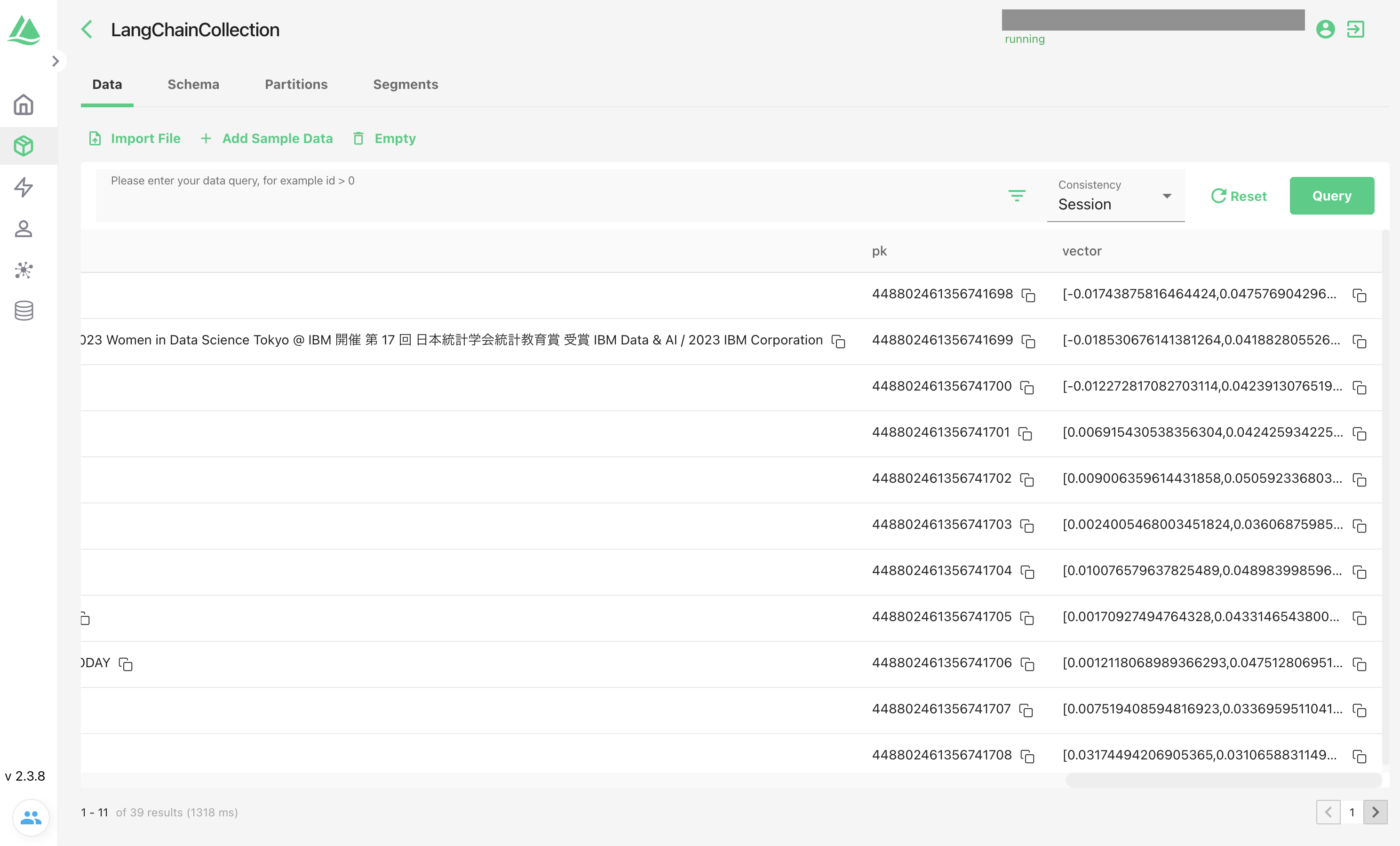
スキーマも自動で定義されています(自分で定義することも可能です)
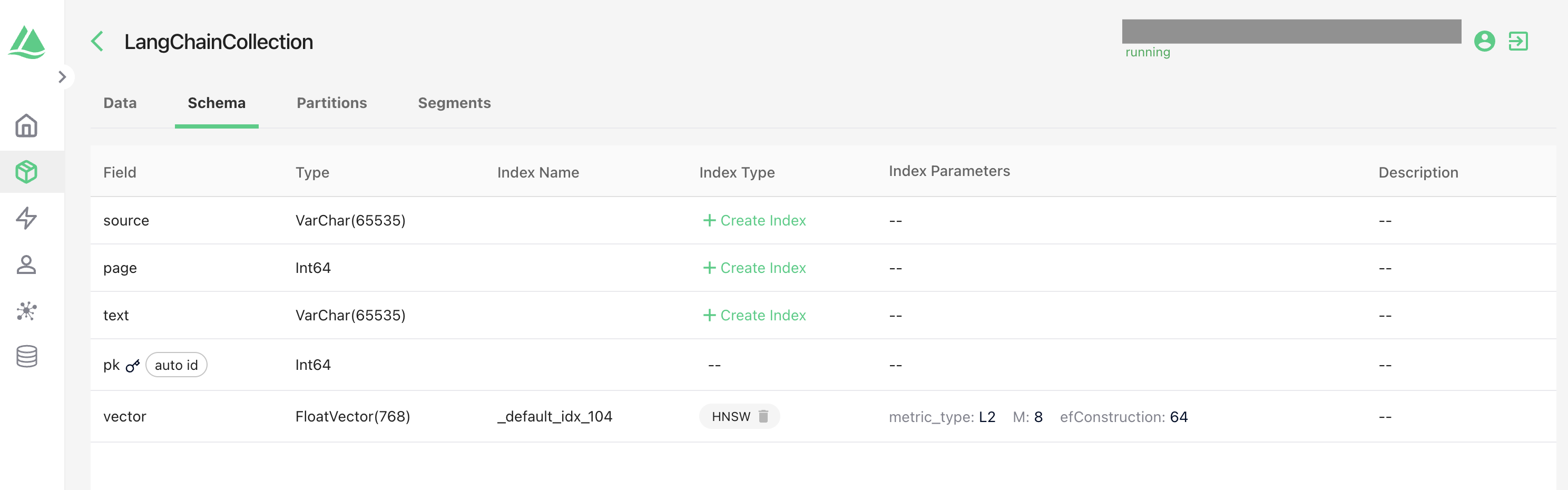
尚、一度データベースに入れたので、次回そのデータを使う場合は、データベースに接続するのみでOKです。
Milvusへの接続(DBにInsert不要の場合)
from langchain_milvus import Milvus
vector_db = Milvus(
embeddings,
connection_args=my_connection_args,
collection_name = 'LangChainCollection'
)
これでベクトル検索できる準備が整いました!
2-8. テキスト類似検索してみます
一旦、LLMを使わずテキスト類似検索してみます。
query = "IBM TechXchange Japanとは?"
docs = vector_db.similarity_search(query)
for doc in docs:
print({"content": doc.page_content[0:100], "metadata": doc.metadata} )
出力
{'content': '⽇程: 2023年 10⽉ 31⽇(⽕)\n-11⽉ 1⽇(⽔)\n会場:ベルサール 東京⽇本橋\n主催:⽇本IBM 株式会社\n対象者: IBMのサービス/ 製品\nを使⽤または使⽤検討されてい\nる技術者の⽅', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 37, 'pk': 448802461356741735}}
{'content': 'github.com/kyokonishito\n2\ntwitter.com/KyokoNishito\nwww.linkedin.com/in/kyokonishitoqiita.com/nishiky', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 1, 'pk': 448802461356741699}}
{'content': '⽇本IBM Db2 & Database コミュニティ/ 各種イベントご紹介\nDb2 およびDB 各製品に 関連するコミュニティ活動および各種イベントをさらに強化して参 ります。\n最新の情報を鮮度⾼く', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 38, 'pk': 448802461356741736}}
{'content': '実際にやってみましょう!\nIBM Data & AI / 2023 IBM Corporation', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 16, 'pk': 448802461356741714}}
ページの内容で類似度が高い上位4つが入ります。
正直下位の方は関係あるのかな?って感じですね。パラメーターkで取得数は変更できます。
# 取得数をkで指定
docs = vector_db.similarity_search(query, k=1)
for doc in docs:
print({"content": doc.page_content[0:100], "metadata": doc.metadata} )
出力
{'content': '⽇程: 2023年 10⽉ 31⽇(⽕)\n-11⽉ 1⽇(⽔)\n会場:ベルサール 東京⽇本橋\n主催:⽇本IBM 株式会社\n対象者: IBMのサービス/ 製品\nを使⽤または使⽤検討されてい\nる技術者の⽅', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 37, 'pk': 448802461356741735}}
数を絞るのではなくて、スコアで絞りたい場合はsimilarity_search_with_scoreを使います。返されるスコアはL2距離で0から1の値です。スコアは小さいほど(0に近いほど)類似度が高いです。
# スコアは小さいほど(0に近いほど)類似度が高いです。
query = "IBM TechXchange Japanとは?"
docs = vector_db.similarity_search_with_score(query)
for doc, score in docs:
print({"score": score, "content": doc.page_content[0:100], "metadata": doc.metadata} )
出力
{'score': 0.22915227711200714, 'content': '⽇程: 2023年 10⽉ 31⽇(⽕)\n-11⽉ 1⽇(⽔)\n会場:ベルサール 東京⽇本橋\n主催:⽇本IBM 株式会社\n対象者: IBMのサービス/ 製品\nを使⽤または使⽤検討されてい\nる技術者の⽅', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 37, 'pk': 448802461356741735}}
{'score': 0.33195996284484863, 'content': 'github.com/kyokonishito\n2\ntwitter.com/KyokoNishito\nwww.linkedin.com/in/kyokonishitoqiita.com/nishiky', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 1, 'pk': 448802461356741699}}
{'score': 0.33645570278167725, 'content': '⽇本IBM Db2 & Database コミュニティ/ 各種イベントご紹介\nDb2 およびDB 各製品に 関連するコミュニティ活動および各種イベントをさらに強化して参 ります。\n最新の情報を鮮度⾼く', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 38, 'pk': 448802461356741736}}
{'score': 0.3771980404853821, 'content': '実際にやってみましょう!\nIBM Data & AI / 2023 IBM Corporation', 'metadata': {'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf', 'page': 16, 'pk': 448802461356741714}}
スコア0.3以上はイマイチ感ありますね。もし絞りたい場合はこのスコアで絞ってください。絞るためには自分でそのロジック書く必要があります。
2.9 watsonx.aiのLLMでLangChainとMilvusを使ってPDFの内容をQ&A
やっとお題にたどり着きました!
LangChainのRetrievalQAを使います。
まずはプロンプトなしでQ&A
from langchain.chains import RetrievalQA
retriever = vector_db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=custom_llm, chain_type="stuff", retriever=retriever)
query = "IBM TechXchange Japanとは?"
answer = qa.invoke(query)
print(answer['result'])
出力
IBM TechXchange Japanは、IBMの製品およびソリューションを軸に技術者同士が繋がり、学びや技術体験を共有できる技術学習イベントです。
ちゃんと文章で回答されました!
試しにPDFにない簡単な質問をしてみます:
query = "日本の首都は?"
answer = qa.invoke(query)
print(answer['result'])
出力
東京
PDFに情報がなくとも学習済みの情報にあれば自力で回答してしまうようです。
「watsonx.aiのLLMでLangChainを使ってPDFの内容をQ&Aをする」では読み込んだPDFの情報のみで回答して欲しかったので、retriever作成の際にsearch_type="similarity_score_threshold"、
search_kwargs={'score_threshold': 0.5}
を指定して精度の低い情報は除外するretrieverを作成しました(参考:2-6. retrieverの作成)。
langchain_community.vectorstores.milvus.Milvusにはこの機能がまだ実装されてなく、指定すると検索実施の際にエラーになってしまいます。
API Docには書いてあるのですが、使えません。そのうち使えるようになるのかも。
今のところベクトルDBの内容のみで回答したい場合は、前に説明したsimilarity_search_with_scoreを使い自力でやってみてください。
プロンプトを作ってQ&A
ベクトルDBの内容のみで回答したい場合、プロンプトで指示すればよいのかもしれません。
プロンプトにその旨指示を入れてみます。
RAG chainの作成
前回のでRetrievalQA.from_chain_typeからやり方を変えてみました。
参考:
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
template = """以下のcontextのみを利用して、ですます調で丁寧に回答してください。contextと質問が関連していない場合は、「不明です。」と回答お願いします。
context: {context}
質問: {question}
回答:"""
rag_prompt = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| custom_llm
)
質問してみます
PDFにないものを質問
print(rag_chain.invoke("日本の首都は?"))
出力:
東京
正しいですが、「contextと質問が関連していない場合は、「不明です。」と回答お願いします。」と指示したプロンプト無視で回答してしまってますね。
PDFにある質問をしてみます。
print(rag_chain.invoke("IBM TechXchange Japanとは?"))
出力:
IBM TechXchange Japanは、IBMの製品とソリューションを軸に技術者同士が繋がり、学びや技術体験を共有できる技術学習イベントである。
「ですます調で丁寧に回答してください。」って指示したのですが、プロンプトなしの時は「です」で終わってたのですが、語尾が「である」変わりました。
プロンプトちょっと変えてみます
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
template2 = """<|system|>
あなたはIBMが開発したAI言語モデル、Granite Chatです。あなたは慎重なアシスタントです。あなたは慎重に指示に従います。あなたは親切で無害で、倫理的なガイドラインに従い、前向きな行動ができます。
<|user|>
あなたは、特別なRetrieval Augmented Generation(RAG)アシスタントとして機能するように設計されたAI言語モデルです。応答を生成するときは、正しさを優先します。つまり、文脈とユーザーのクエリが与えられたときに応答が正しく、文脈に根拠があることを確認します。さらに、レスポンスが与えられたドキュメントまたはコンテキストによってサポートされていることを確認してください。コンテキストやドキュメントを使用して質問に答えることができない場合、次のレスポンスを出力します: 'わかりません。' あなたの回答が質問に関連していることを常に確認してください。説明が必要な場合は、まず説明や理由を述べ、それから最終的な答えを述べてください。
[文書]
{context}
[質問]
{question}
<|assistant|>"""
rag_prompt = PromptTemplate.from_template(template2)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| custom_llm
)
print(rag_chain.invoke("IBM TechXchange Japanとは?"))
出力:
IBM TechXchange Japanは、IBMの製品とソリューションを軸に技術者同士が繋がり、学びや技術体験を共有できる技術学習イベントです。
ですます調に変わりました。
PDFにない質問もしてみます。
print(rag_chain.invoke("日本の首都は?"))
出力:
東京です。
やっぱり自力で回答してしまいますね。でも「です」がついて丁寧になりました。
プロンプトの書き方はちょっと時間をかけて調整が必要そうです。
まとめ
Milvus+LangChainはまだまだ情報が不足していて調べるのに時間がかかりました。
結局以下の公式のドキュメントに書かれているのがまずは全てっぽいです。
- Question Answering over Documents with Milvus and LangChain
- LangChain Document Milvus
API Doc langchain_community.vectorstores.milvus.Milvus に書かれていても使えないMethodとかありましたので、まだ不完全なのかもしれません。
ただLangChainを使って簡単にMilvusでのRAGパターンを書けるのは事実なので、ぜひ使ってみてください。ついでにwatsonx.dataのMilvusもぜひお試しください!
ここで書いているコードはJupyter notebookとしてhttps://github.com/kyokonishito/notebooks/blob/main/watsonx-langchain-milvus-PDF.ipynb
からダウンロードできますので、とりあえず実行したい方は使ってみてください。