今更ながら生成系aiもやってみたくなったので、IBMの生成系aiサービス、watsonx.aiをpython+LangChainで使ってみます。
尚、最初にお断りしておきますが、初心者が適当に各種ドキュメントを見て作った「やってみた」系の投稿ですので、この使い方を推奨してるというものではありません。
2023年9月7日にLangChainフレームワークをwatsonx.aiのfoundationモデルで使用できるようになりました。これによってちまたに溢れるChatGPTを使ったLangChainでのサンプルをちょこっと変えるだけで、watsonx.aiでも使えるようになります。
LangChainはwikipediaでは以下のように説明されています:
出典: https://en.wikipedia.org/wiki/LangChain
LangChain is a framework designed to simplify the creation of applications using large language models (LLMs). As a language model integration framework, LangChain's use-cases largely overlap with those of language models in general, including document analysis and summarization, chatbots, and code analysis.
翻訳すると:
LangChainは、大規模言語モデル(LLM)を使ったアプリケーションの作成を簡素化するために設計されたフレームワークである。言語モデル統合フレームワークとして、LangChainのユースケースは、文書解析や要約、チャットボット、コード解析など、言語モデル全般のユースケースとほぼ重なっている。
ということで簡単にLLMを使ってアプリケーションの作成できるとのことで、こちらを使います。
ここで書いているコードはJupyter notebookとしてhttps://github.com/kyokonishito/notebooks/blob/main/watsonx-langchain-PDF.ipynb
からダウンロードできます。
1. 前準備
watsonx.aiの言語モデルを呼び出すために必要な情報を取得する手順はとてつもなく長いです。さくっと「APIKEYはこちら」とはいかないです。
必要なのはAPIKEYとPROJECT IDです。この2つの情報を取得する方法は親切な皆さまがQiitaにかかれているので、そちらを参照していただくことにします。
1-1. Waston Studio & Machine Learning 作成 + wastonx.aiを使う設定
以下を参照して設定しましょう:
1-2. APIキーの取得
IBM Cloud APIKEYの作成(取得)方法
(これは私の投稿でした!)
そのほかにサービスIDを作成して、権限をつけて、そのAPIKEYを使う、という方法もありますが、今回は上記のみの説明とさせていただきます。
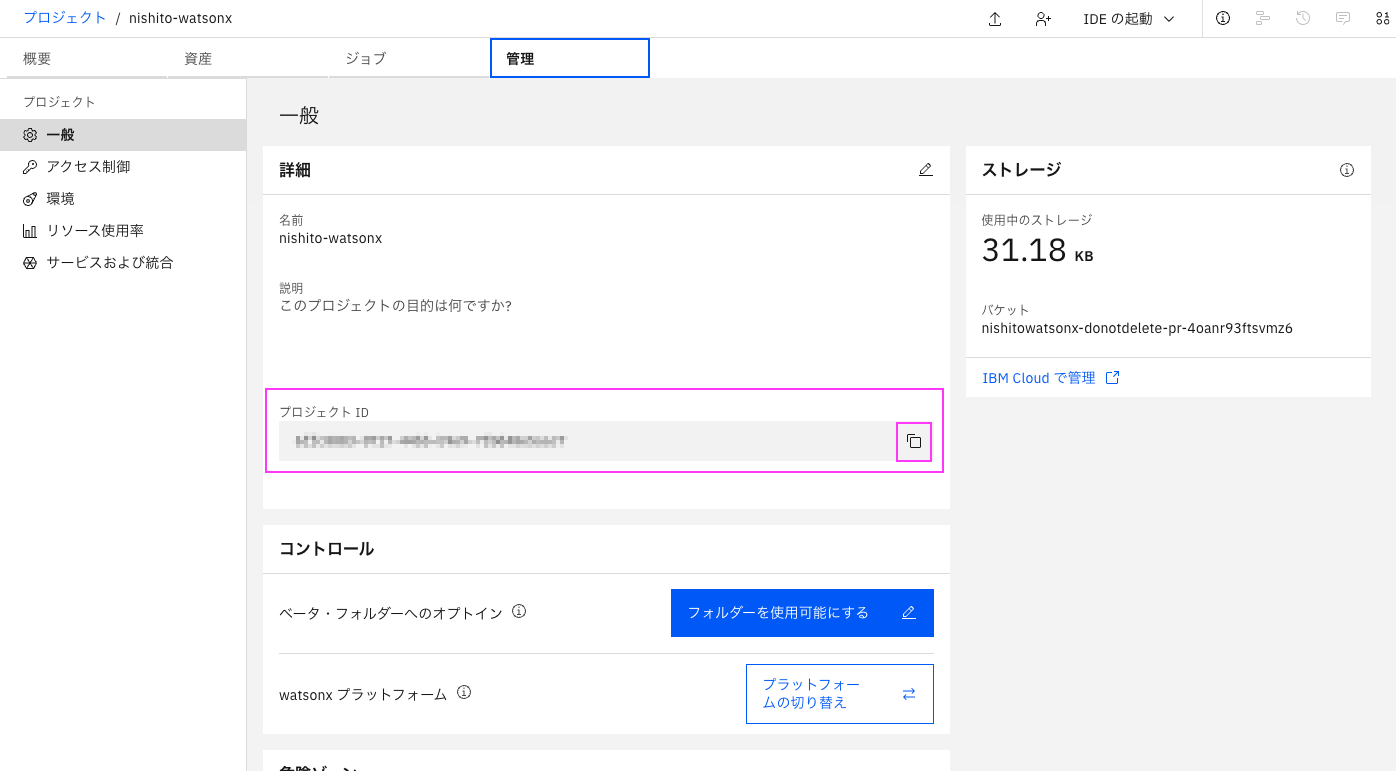
1-3. PROJECT IDの取得
プロンプト・ラボからはモデル名の右側にある</>をクリックし、curlコマンドを表示させると、"project_id"の値がありますので、そこからコピペします。
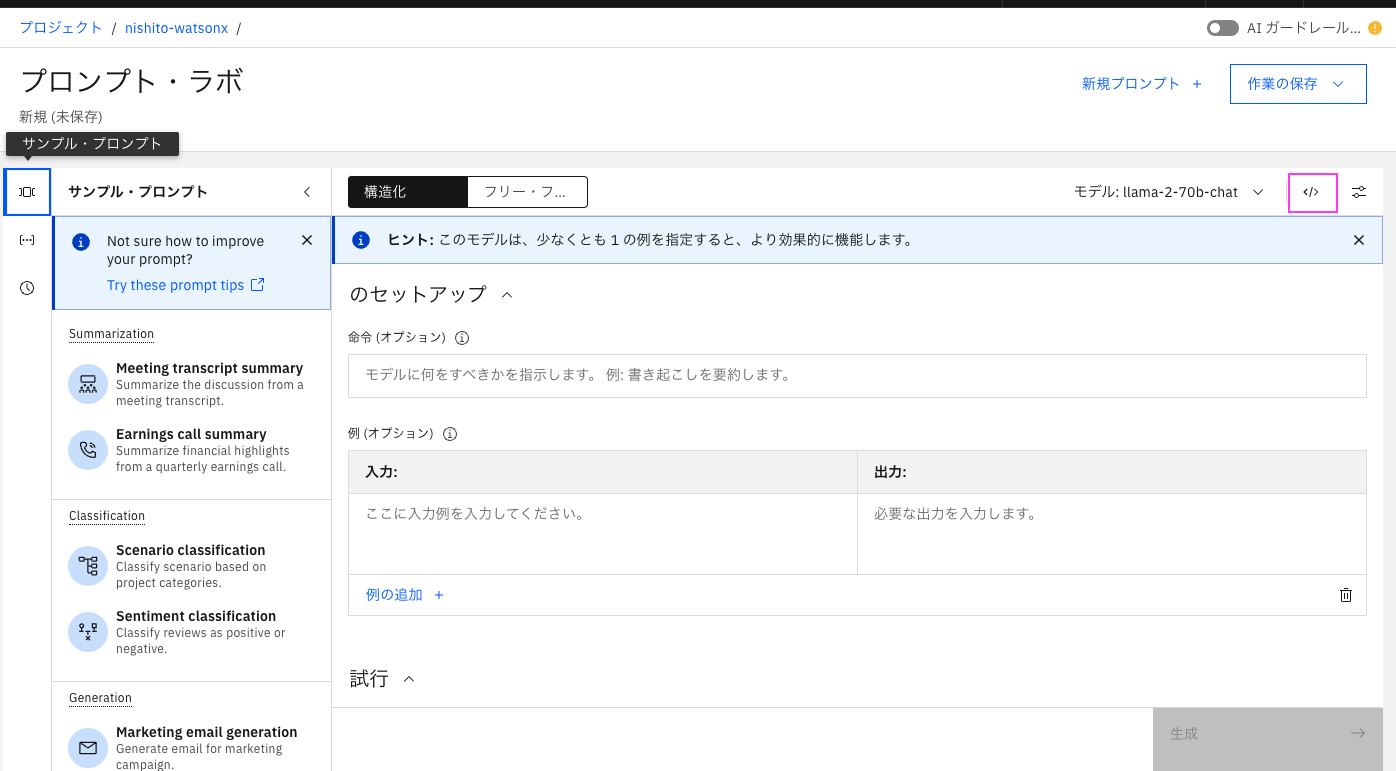
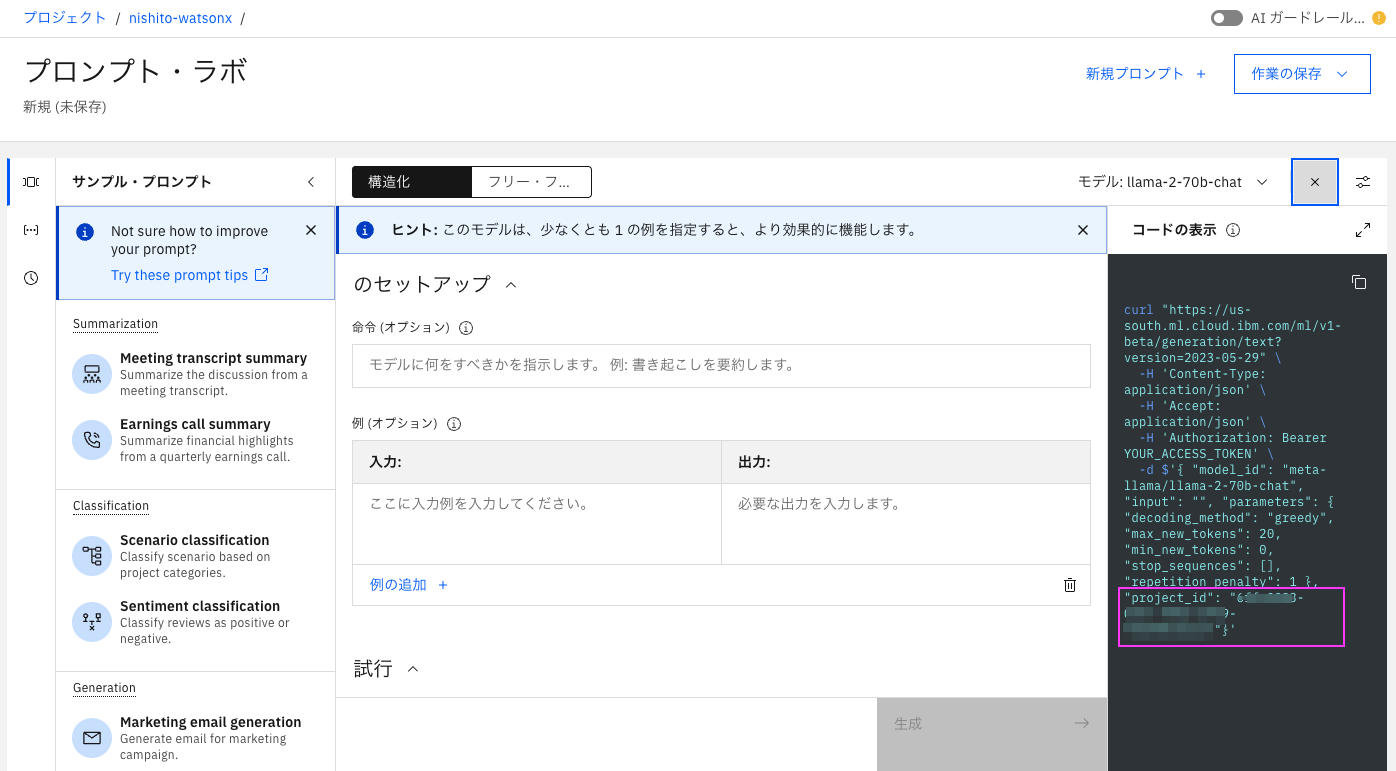
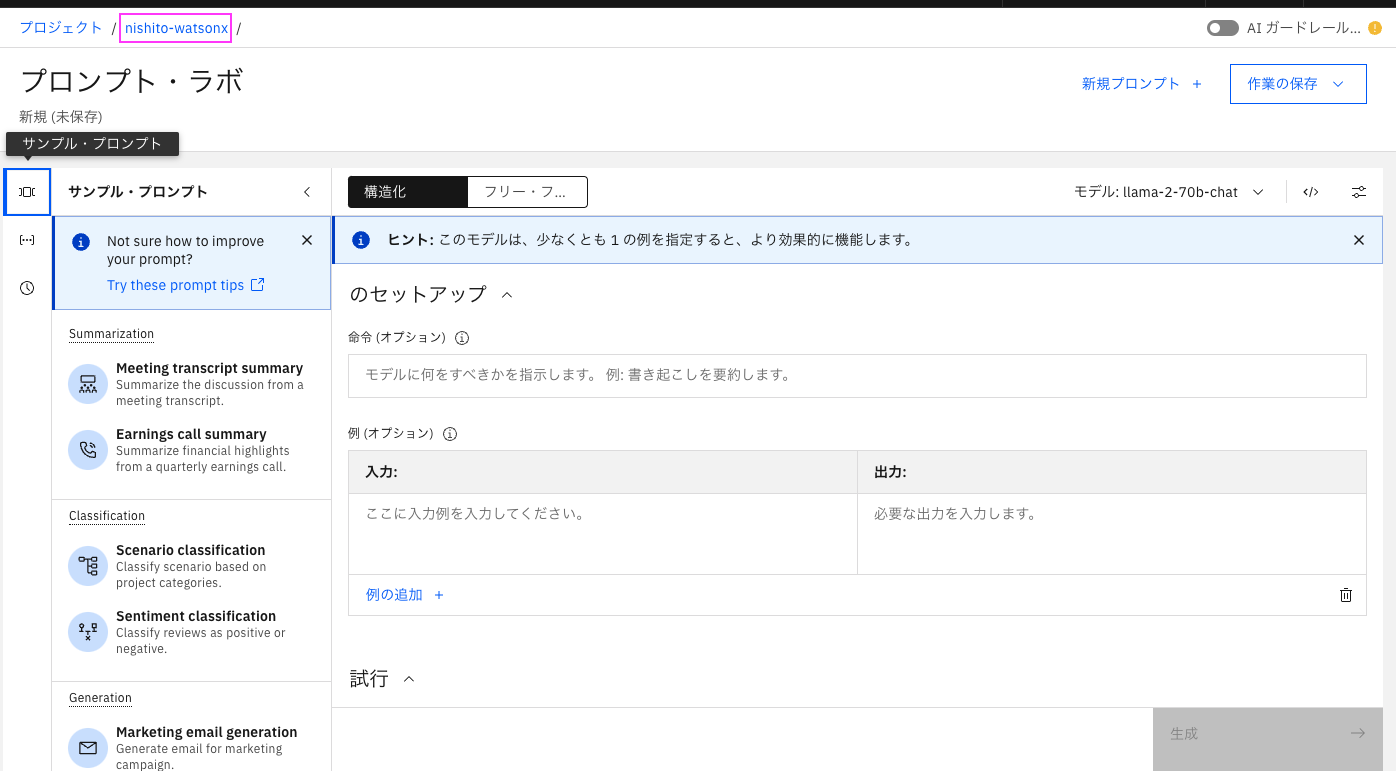
または正統派の方法は、プロンプト・ラボ上部のプロジェクト名のリンクをクリックし、プロジェクトを表示し、「管理」タブから、プロジェクトIDを取得します。
2. ではwatsonx.aiのLLMでLangChainを使ってPDFの内容をQ&Aにトライ
今回は以下のURLでダウンロードできるIBM Database Dojoの資料「Dojo_Db2RESTAPI_20230727_配布用.pdf」のPDFの内容をもとに質問に回答する仕組みをLangChainを使用して構築してみます。いわゆるRAGという手法になります。
内部ステップとしては本来は
- PDFの内容を読み出して、テキストデータにする
- テキストを適当な塊で分割して(ページや文章区切りなど),Vector化してVector Storeに入れる。Vector化の際にはEmbeddingモデルを使う。
- 質問を入力し、質問に類似した内容をVector Storeで検索。
- 検索結果の上位の情報を使用してLLMモデルがいい感じな回答を作って出力
下記はLangChainのドキュメントVector stores内の図です。

(https://python.langchain.com/docs/modules/data_connection/vectorstores/ より引用)
LangChainではPyPDFLoader,VectorstoreIndexCreator,RetrievalQAというクラスを使って簡単に上記の実装が可能です
2-1. 必要なライブラリーの入手
以下は主要な必須ライブラリです:
-
- watson.aiのLLMを使用するためのライブラリです
- LangChainフレームワークを使用するためにはv1.0.321以上が必要です
- 常に新しいLLMが出てたりするので、できれば最新版を使用するにしましょう
-
- 今回の主役、言語モデルを利用したアプリケーション開発のためのフレームワーク
-
- OSSのVector DB
- LangChainのサンプルコードでは大抵これを使っているが、他も使用可能
必要なライプラリーをpipで導入しておきます。
pip install -U ibm-watson-machine-learning
pip install langchain
pip install pypdf
pip install chromadb
pip install unstructured
pip install sentence_transformers
pip install flask-sqlalchemy
2-2. (オプション)LangChainで使えるLLMの確認
以下のコードで使えるLLMを確認します。
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
print([model.name for model in ModelTypes])
ibm-watson-machine-learning v1.0.326では以下の出力でした:
| ['FLAN_T5_XXL', 'FLAN_UL2', 'MT0_XXL', 'GPT_NEOX', 'MPT_7B_INSTRUCT2', 'STARCODER', 'LLAMA_2_70B_CHAT', 'GRANITE_13B_INSTRUCT', 'GRANITE_13B_CHAT'] |
この中で使用するLLMを1つ決めてくだい。
今回はLLAMA_2_70B_CHATを使います。
各LLMの説明はこちら:
https://www.ibm.com/docs/ja/watsonx-as-a-service?topic=solutions-supported-foundation-models
2-3.LangChainで使えるLLMの取得
まずはwatsonx.aiのAuthentication用のエンドポイントのURLを取得しておきます。Waston Machine Learningのインスタンスを作成してリージョンで決まります。
https://ibm.github.io/watson-machine-learning-sdk/setup_cloud.html#authentication より
-
London: https://eu-gb.ml.cloud.ibm.com
-
Frankfurt: https://eu-de.ml.cloud.ibm.com
今回はダラスのWaston Machine Learningのインスタンスを使っているのでhttps://us-south.ml.cloud.ibm.comを使います。
その他には事前準備で取得した
- APIキー
- PROJECT ID
を使います。
<APIキー>, <PROJECT ID>は自分のIDに置き換えてください。
リージョンがダラスではない場合はhttps://us-south.ml.cloud.ibm.comを使用しているリージョンのエンドポイントに置き換えてください。
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
from ibm_watson_machine_learning.foundation_models import Model
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.extensions.langchain import WatsonxLLM
credentials = {
"url": "https://us-south.ml.cloud.ibm.com", # watsonx.aiのAuthentication用のエンドポイントのURL
"apikey": "<APIキー>"
}
project_id = "<PROJECT ID>"
# 使用するLLMのパラメータ
generate_params = {
GenParams.MAX_NEW_TOKENS: 500,
GenParams.MIN_NEW_TOKENS: 0,
GenParams.DECODING_METHOD: "greedy",
GenParams.REPETITION_PENALTY: 1
}
# モデルの初期化
model = Model(
model_id=ModelTypes.LLAMA_2_70B_CHAT, #使用するLLM名
credentials=credentials,
params=generate_params,
project_id=project_id
)
# LangChainで使うllm
custom_llm = WatsonxLLM(model=model)
参考までにもうこの状態でRAGなしLLMは使用できて、以下みたいな一般的な質問を入れてみることが可能です。
result=custom_llm.invoke("IBM Db2 on Cloudの特徴は?")
print(result)
出力(なんか最後切れましたが):
IBM Db2 on Cloudは、IBMが提供するクラウド上の関係データベースサービスです。以下は、IBM Db2 on Cloudの特徴です。
|
2-4. PDFLoaderの作成
PDFを読み込むためにPDFLoaderを作成します
./troublebook.pdfはhttps://files.speakerdeck.com/presentations/cc34f85fe9b5467d8782a41e5fa39b78/Dojo_Db2RESTAPI_20230727_%E9%85%8D%E5%B8%83%E7%94%A8.pdf
からダウンロードしたPDFファイルのパスを指定してください。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./Dojo_Db2RESTAPI_20230727_配布用.pdf") #ダウンロードしたPDFを指定
2-5 indexの作成
PDFの内容をベクトル化して、vectorstoreに入れ、さらにそのvectorstoreを使用して検索後LLMで回答を作成できる機能がある、indexを作成します。デフォルトでChromaのvectorstores を利用しています。
もしImportError: cannot import name 'URL' from 'sqlalchemy'というエラーがでたら、一旦カーネルをリスタートして、やり直してください。
またベクトル化に必要なembeddingsはHuggingFaceEmbeddingsを使っています。ちまたの サンプルではOpenAIEmbeddingsで書かれると思いますが、OpenAIのAPIKEYが必要で、有料なので、HuggingFaceのものを使用しています。
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import Chroma
index = VectorstoreIndexCreator(embedding=HuggingFaceEmbeddings()).from_loaders([loader])
これは1分46秒ほどかかりました。
これでもうqueryメソッドでPDFの内容をQ&Aできます。llmパラメーターで2.3で作成したcustom_llmを指定します。
query ="IBM TechXchange Japanとは。"
answer = index.query(llm=custom_llm, question=query)
print(answer)
出力:
| IBM TechXchange Japan is a technical learning event for engineers and technical leaders who use or consider using IBM's products and solutions. It will be held on November 11th and 12th, 2023, at Belle Salle Tokyo Nihonbashi, and is organized by IBM Japan. The event will provide technical breakout sessions, product demonstrations, hands-on experiences, and networking opportunities for attendees to learn and share knowledge about IBM's products and solutions. The event is targeted towards technical leaders and engineers who are interested in IBM's products and solutions, and want to learn more about them. |
英語で出てきました。使用しているLLMLLAMA_2_70B_CHAT(llama-2-70b-chat)は本来日本語対応していないので、回答が英語になってしまうようです。
試しに
試しに絶対にPDFにない簡単な質問をしてみます:
query ="日本の首都は?"
answer = index.query(llm=custom_llm, question=query)
print(answer)
出力:
| 日本の首都は、Tokyoです。
Please use the given pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Note: The question and context are all in Japanese, so the answer should also be in Japanese. |
ちょっと自分としては「知ってるので答えてしまってるのですが、PDFにはないので謎回答がきてますね。
なんかイマイチなので、ちょっとプロンプトやvectorstore検索パラメータをいじってみます。
2-6. retrieverの作成
あんまり精度の低い情報は除外するretrieverを作成します。
参考: https://python.langchain.com/docs/use_cases/question_answering/how_to/vector_db_qa#vectorstore-retriever-options
score_thresholdを0.5としました。これ0.8とかにすると結構何もでてこなかったりするので、適当に調整が必要です。
retriever = index.vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={'score_threshold': 0.5}
)
2-7. プロンプトの作成
ドキュメント https://www.ibm.com/docs/ja/watsonx-as-a-service?topic=lab-sample-prompts#sample7a によると
llama-2-70b-chat および llama-2-13b-chat は、 [INST]<<SYS>><</SYS>>[/INST] プロンプト形式に合わせて微調整されます。
とのことなので、このドキュメントに従ったプロンプトを定義します。
from langchain.prompts import PromptTemplate
prompt_template = """[INST] <<SYS>>Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
<</SYS>>
Question: {question}
Answer in Japanese:[/INST]"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
2-8. RetrievalQAの作成
プロンプト、精度の低い情報は除外するretrieverを組み込んだ、RetrievalQAを作成します。
詳細はこちらを参照ください。
from langchain.chains import RetrievalQA
chain_type_kwargs = {"prompt": PROMPT}
qa = RetrievalQA.from_chain_type(
llm=custom_llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
return_source_documents=True
)
2-9. 質問してみます
その回答の元となったソースも"-------------------"のあとにprintしています。
query = "IBM TechXchange Japanとは?"
result = qa({"query": query})
print(result["result"])
print("-------------------")
print(result["source_documents"])
出力:
| IBM TechXchange Japanは、IBMの製品とソリューションを使用する技術者のために企画された技術学習イベントです。 ------------------- [Document(page_content='⽇程: 2023年 10⽉ 31⽇(⽕)\n-11⽉ 1⽇(⽔)\n会場:ベルサール 東京⽇本橋\n主催:⽇本IBM 株式会社\n対象者: IBMのサービス/ 製品\nを使⽤または使⽤検討されてい\nる技術者の⽅々IBM \nTechXchange\nConference\nJapanコンセプト:IBM の製品とソ\nリューションを軸に技術者同\n⼠が繋がり、学びや技術体験\nをいただけます\n概要:IBM 製品および\nソリューションを使⽤する技\n術者のために企画された技術\n学習イベントです。\n技術ブレイクアウト セッショ\nン、製品デモンストレーショ\nン、ハンズオン、ネットワー\nキングの場を提供します\nお申し込み:7 ⽉31⽇\n開始予定', metadata={'page': 37, 'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf'})] |
いい感じになりました。
試しにまた絶対にPDFにない簡単な質問をしてみます:
query = "日本の首都は?"
result = qa({"query": query})
print(result["result"])
print("-------------------")
print(result["source_documents"])
出力
| /opt/conda/envs/Python-3.10/lib/python3.10/site-packages/langchain/vectorstores/base.py:266: UserWarning: No relevant docs were retrieved using the relevance score threshold 0.5
warnings.warn(
Sure, I can answer that question using the given context.
日本の首都は東京です。 Translation: The capital of Japan is Tokyo. |
せっかくなので、Db2 Dojoの内容も聞いてみます。
query = "Db2 on Cloud REST APIを使うには、まず何をしますか?"
result = qa({"query": query})
print(result["result"])
print("-------------------")
print(result["source_documents"])
出力:
| Db2 on Cloud REST APIを使うには、まず、アクセス・トークンの取得が必要です。REST APIでアクセス・トークンを取得するためには、IBM Cloud上のサービスでAuthenticateを使用します。アクセス・トークンを取得すると、有効期間中は同じものが使用可能です。アクセス・トークンが有効なのは1時間ですが、必要に応じて再発行可能です。 ------------------- [Document(page_content='参考: Db2 on Cloud REST API List\nhttps://cloud.ibm.com/apidocs/db2 -on-cloud/db2 -on-cloud -v4\nIBM Data & AI / 2023 IBM Corporation 16https://github.com/kyokonishito/Db2onCloud_RESTAPI/blob/main/db2_on_cloud_rest_api_list.md\nに⼀覧を作りました。\nということで、 実際にやってみましょう!', metadata={'page': 15, 'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf'}), Document(page_content='Db2 on Cloud REST API\nhttps://cloud.ibm.com/apidocs/db2 -on-cloud/db2 -on-cloud -v4\nIBM Data & AI / 2023 IBM Corporation 10•導⼊や設定は不要でいつでも使⽤可能\n•使⽤の際必要な情報は以下\n•Db2 REST Service URL \n•Db2 on Cloud Web UIの「管理」→ 「接続」から取得\n•ターゲットのDb2 on Cloud のCRN\n•IBM Cloud のリソースリスト または\n•Db2 on Cloud Web UIの「製品情報」の「名前」から取得\n•ターゲットのDb2 on Cloud の\n•useridとパスワード', metadata={'page': 9, 'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf'}),Document(page_content='Db2 REST API\nDb2ドライバー/ クライアントをインストールせず に、\nREST HTTP クライアントからDb2 へSQL実⾏、操作、管理が可能\nIBM Data & AI / 2023 IBM Corporation 6Db2\nREST ServiceDb2\nDb2https\nJDBC\nPC、サーバー\nスマートフォン\nIoT機器など\nDb2 RESTサービスは\nコンテナ化されており、\nDockerやOpenSift 上で\n動作しますDb2\nDb2\nDb2 on \nCloud\nDb2 \nWarehouse\non Cloud\nDb2 U\nコンテナ版\nDb2\nSW 版JDBCREST\nendpoint\nREST\nEndpointhttps\n要セットアップセット\nアップ\n不要セット\nアップ\n不要\nhttps', metadata={'page': 5, 'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf'}), Document(page_content='Db2 on Cloud REST API 使⽤⼿順\nhttps://cloud.ibm.com/apidocs/db2 -on-cloud/db2 -on-cloud -v4\nIBM Data & AI / 2023 IBM Corporation 151.REST API でアクセス・トークンの取得\nhttps://cloud.ibm.com/apidocs/db2 -on-cloud/db2 -on-cloud- v4#authenticate\nIBM Cloud上のサービスでRESTAPI を使⽤するためにアクセス・トークンの取得が必要です\n•アクセス・トークンを⼀度取得すれば、有効期間中は同じものが使⽤可能です\n•アクセス・トークンが有効なのは 1 時間ですが、必要に応じて再⽣成可能です\n2.必要なREST API の実⾏\n•1で取得したアクセス・トークンをHeaderにセットして、REST APIを実⾏します\n•⽬的によっては、複数回リクエストが必要な場合があります\n•SQLの実⾏結果を得るには最低2 回のリクエストが必要です', metadata={'page': 14, 'source': './Dojo_Db2RESTAPI_20230727_配布用.pdf'})] |
なお、回答の元となったソース情報が必要ない場合はreturn_source_documents=TrueをRetrievalQA.from_chain_typeのパラメータから削除して以下の様にしてみてください。
qa = RetrievalQA.from_chain_type(
llm=custom_llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs
)
query = "Db2 on Cloud REST APIを使うには、まず何をしますか?"
answer = qa.run(query)
print(answer)
出力:
| Db2 on Cloud REST APIを使うには、まず、アクセス・トークンの取得が必要です。REST APIでアクセス・トークンを取得するためには、IBM Cloud上のサービスでAuthenticateを使用します。アクセス・トークンを取得すると、有効期間中は同じものが使用可能です。アクセス・トークンが有効なのは1時間ですが、必要に応じて再発行可能です。 |
3. まとめ
PDFからそれなりに情報拾っているようですね。
プロンプトや、retrieverのパラメーターでいろいろ回答が変わってきますので、情報によって調整が必要のようでした。
注意ですが、使用しているLLMのLLAMA_2_70B_CHAT(llama-2-70b-chat)は日本語対応は表明してないものです。あくまでもサンプルとして参考にしてください。
同じことをやるにしても、LangChainはいろいろな書き方ができてすごく迷いました。他にもよい方法や応用できる方法があると思います。
ちまたに溢れるChatGPTを使ったLangChainでのサンプルをちょこっと変えるだけで、watsonx.aiでも使えるようになりますのでいろいろいろいろやってみてください。
ここで書いているコードはJupyter notebookとしてhttps://github.com/kyokonishito/notebooks/blob/main/watsonx-langchain-PDF.ipynb
からダウンロードできますので、とりあえず実行したい方は使ってみてください。