2-17 OLAPノード
1.ノードの目的
@OFFSET関数を使わずに以下のようなことが可能です。
- グルーピングして合計を各行に入れる
- グルーピングして累積合計を各行に入れる
- グルーピングしてランキングを各行に入れる
- グルーピングしてパーセンタイルを各行に入れる
- グルーピングして通し番号を各行に入れる
さらに、SQLプッシュバックが可能です。RDBが持つOLAP関数を利用するノードです。
Modeler19.0からの機能です。
2.解説動画(60秒)
TBD
3.クイックスタート
3.1. グルーピングして合計を各行に入れる
CUSTIDごとの売上金額を各行に表示します。
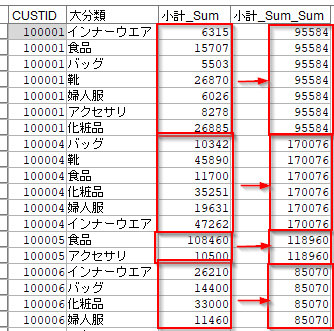
[OLAP]ノードに以下の設定をします。
- グループ化のキーフィールドに
CUSTIDを選びます - ソートには何も設定しません
- モードを
集約にします - 集計フィールドに
小計_Sumを選び、合計にチェックをします
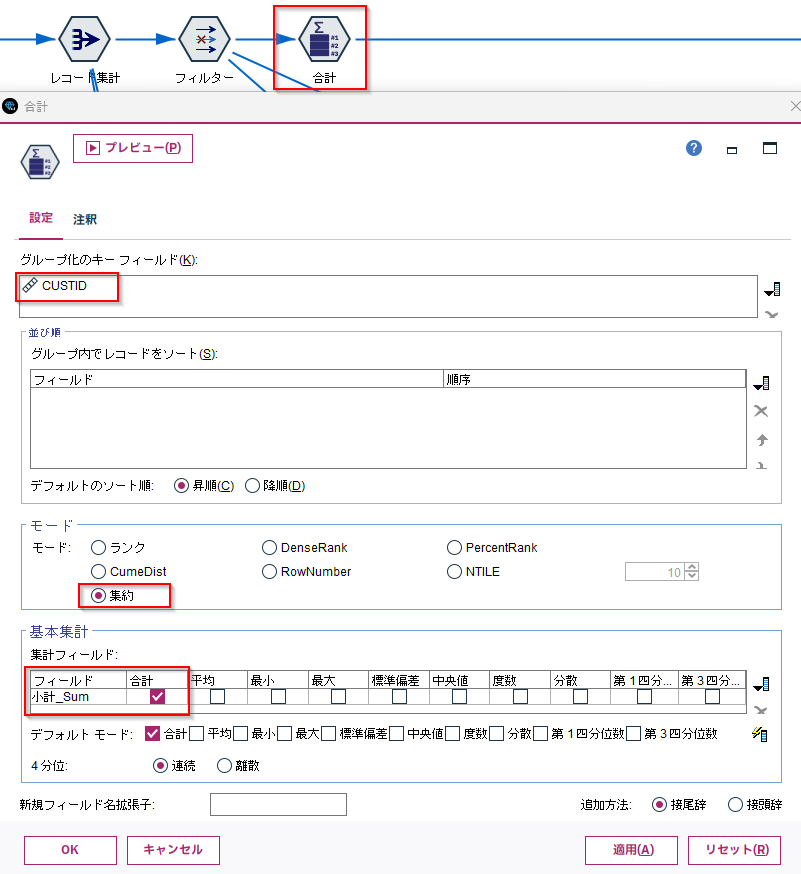
応用例:大分類割合
以下のようなフィールド追加ノードと組み合わせることで大分類割合を求めることができます。以下の例ではCUSTID100001は、靴での購入の割合が28.1%あることがわかります。
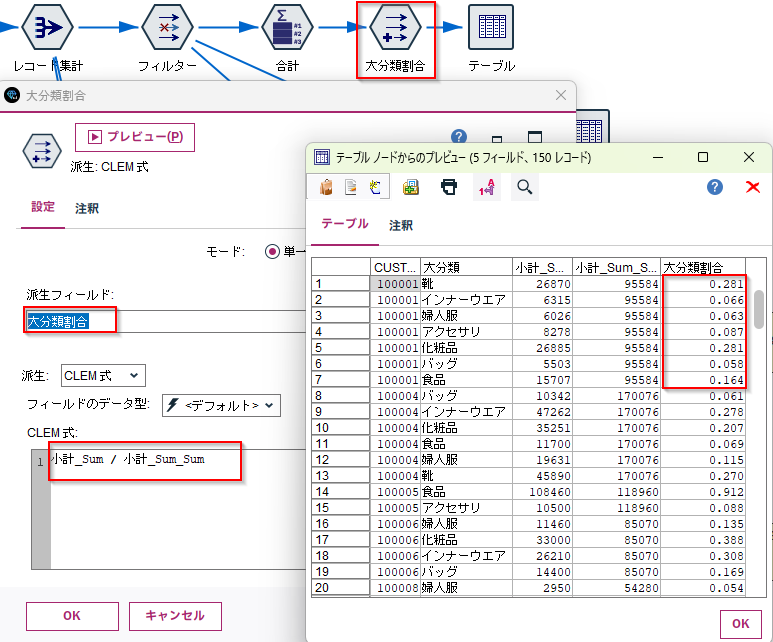
従来の方法:集計をとって結合する
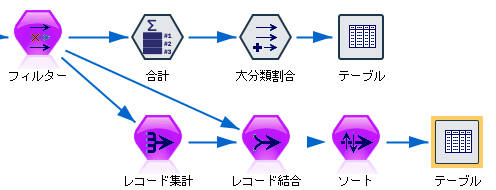
まず集計ノードでCUSTIDごとの小計_Sumの合計をとって、レコード結合でつなげ直していました。
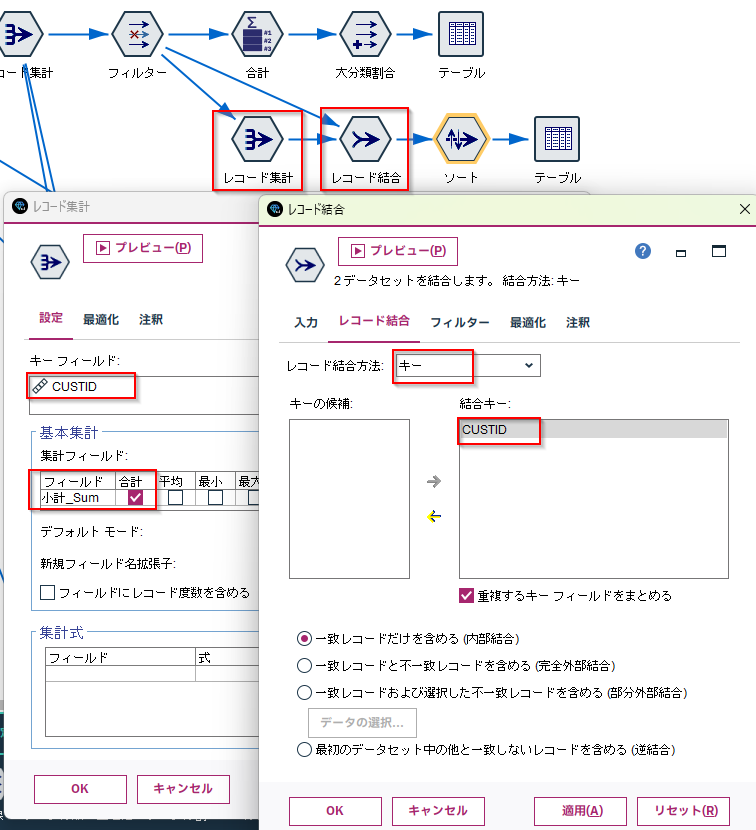
この方法でもSQLプッシュバックは可能です。
3.2. グルーピングして累積合計を各行に入れる
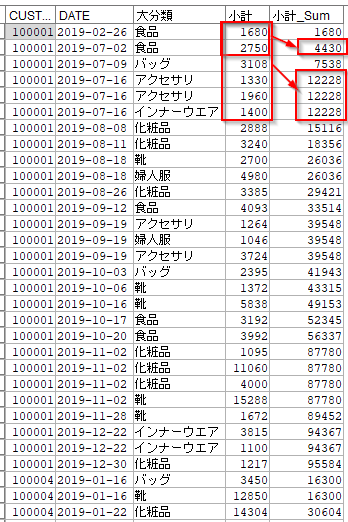
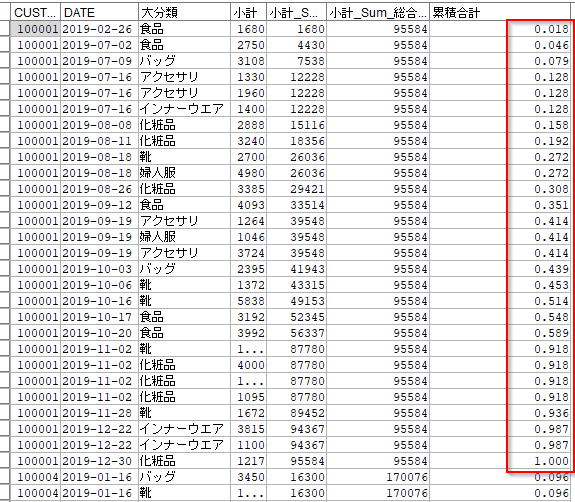
CUSTIDごとDATEで並び替えて、累積購入金額を計算します。
以下の例では、2019-02-26の1680円と2019-07-02の2750円を足して4430円が求められています。
また、2019-07-16には三点の購入があったのでその日までの累計12228が求められています。
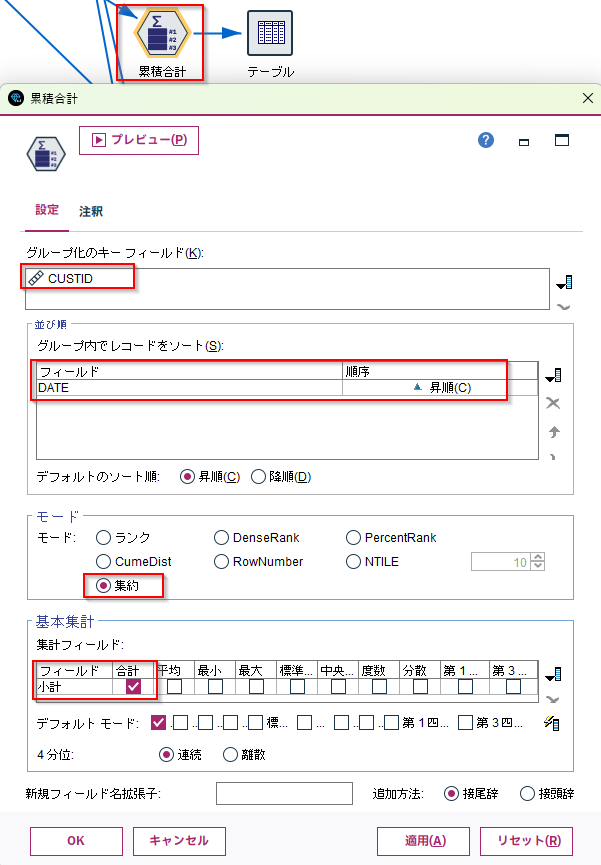
[OLAP]ノードに以下の設定をします。
- グループ化のキーフィールドに
CUSTIDを選びます - ソートでフィールドに
DATEを選び、昇順にします - モードを
集約にします - 集計フィールドに
小計_Sumを選び、合計にチェックをします
応用例:累積比率
以下のように、もう一つのOLAPノードとフィールド追加ノード、ソートノードと組み合わせることで、累積比率を求めることができます。
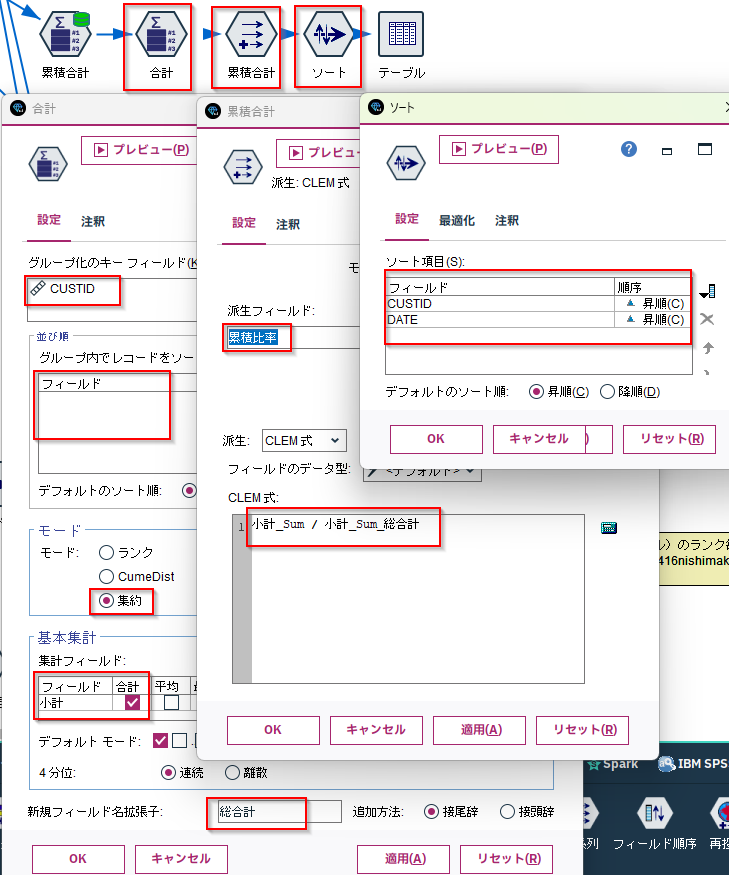
従来の方法:@OFFSETで取得する
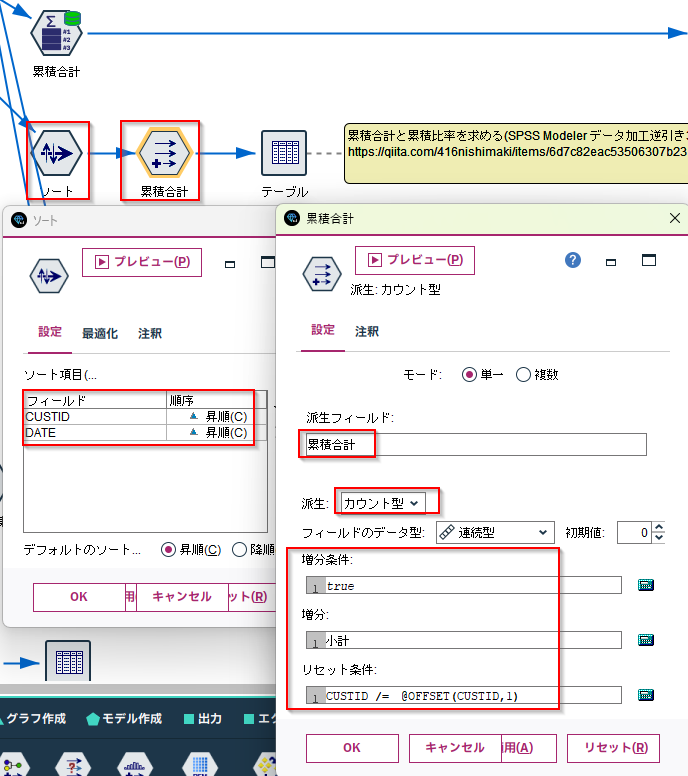
まずソートノードでCUSTIDとDATEでソートしてから、カウント型のフィールド追加ノードで@OFFSETを使う必要があります。この処理は@OFFSETがあるためSQLプッシュバックできません。
累積合計と累積比率を求める(SPSS Modeler データ加工逆引き3-4)で詳しく紹介されています。
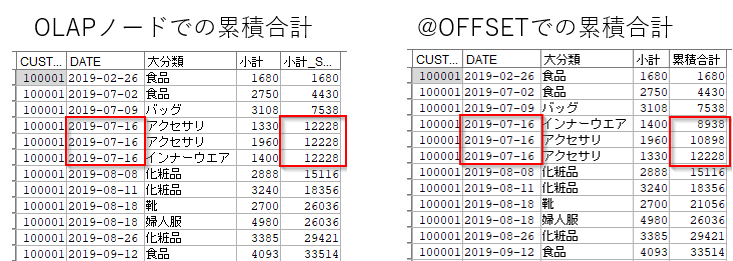
ただ、同じ日付のデータが複数ある場合は結果が異なります。OLAPノードでは同一日付の合計を計算します。@OFFSETの場合は、ソート順に別に累計していきます。以下の例では、2019-07-16の累積は最終的に12228円ですが、@OFFSETではソート順に累積しています。
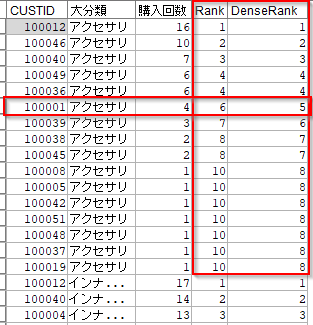
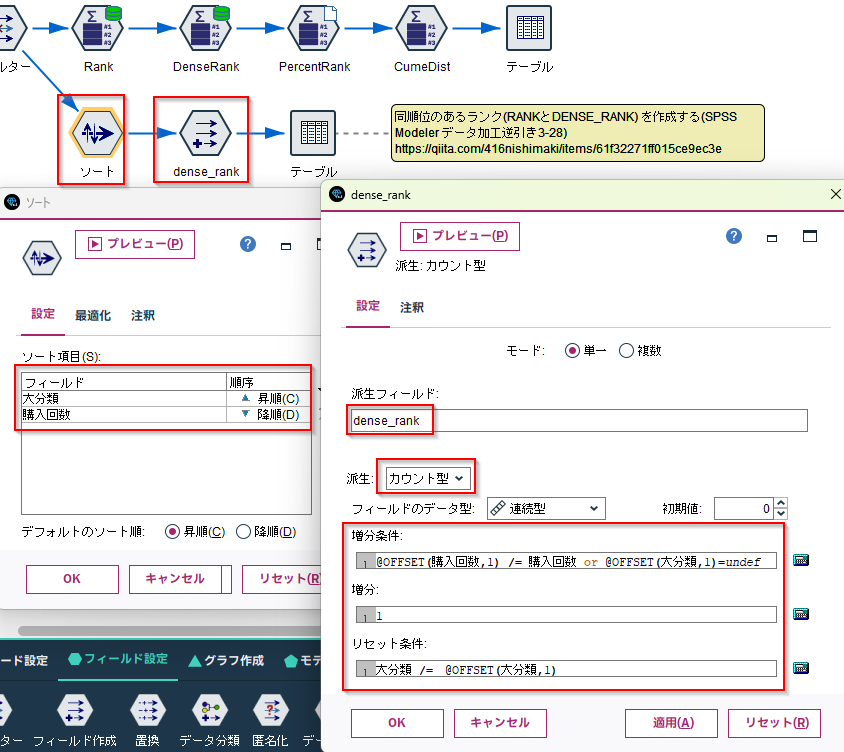
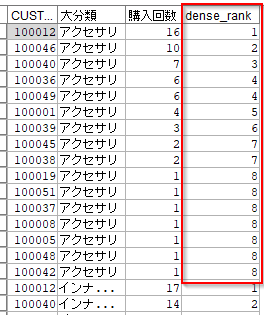
3.3. グルーピングしてランキングを各行に入れる
大分類ごとに購入回数の高いCUSTIDのランキングを計算します。
RankとDenseRankがあります。同一順位があった場合、Rankは次の順位は飛び番にし、DenseRankは飛ばしません。以下の例では4位が2名います。次点のCUSTID100001は、Rankだと6位でDenseRankだと5位になります。
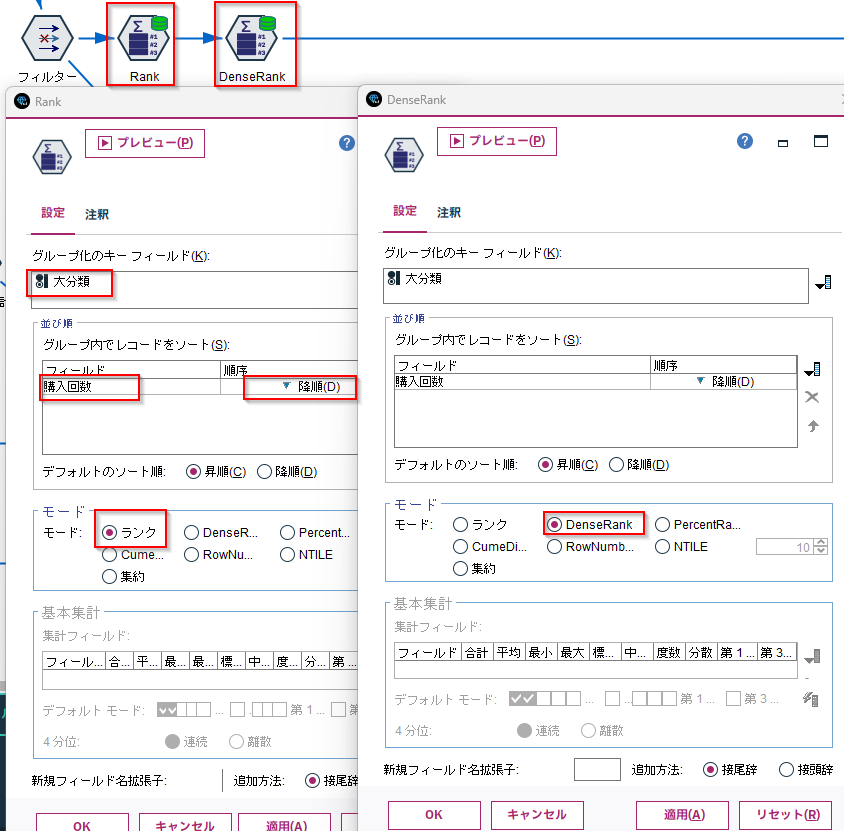
[OLAP]ノードに以下の設定をします。
- グループ化のキーフィールドに
大分類を選びます - ソートでフィールドに
購入回数を選び、降順にします - モードを
RankもしくはDenseRankにします
応用例:PercentRank(百分率での順位)とCumeDist(累積割合)
以下のように、OLAPノードではPercentRank(百分率での順位)とCumeDist(累積割合)も求めることができます。
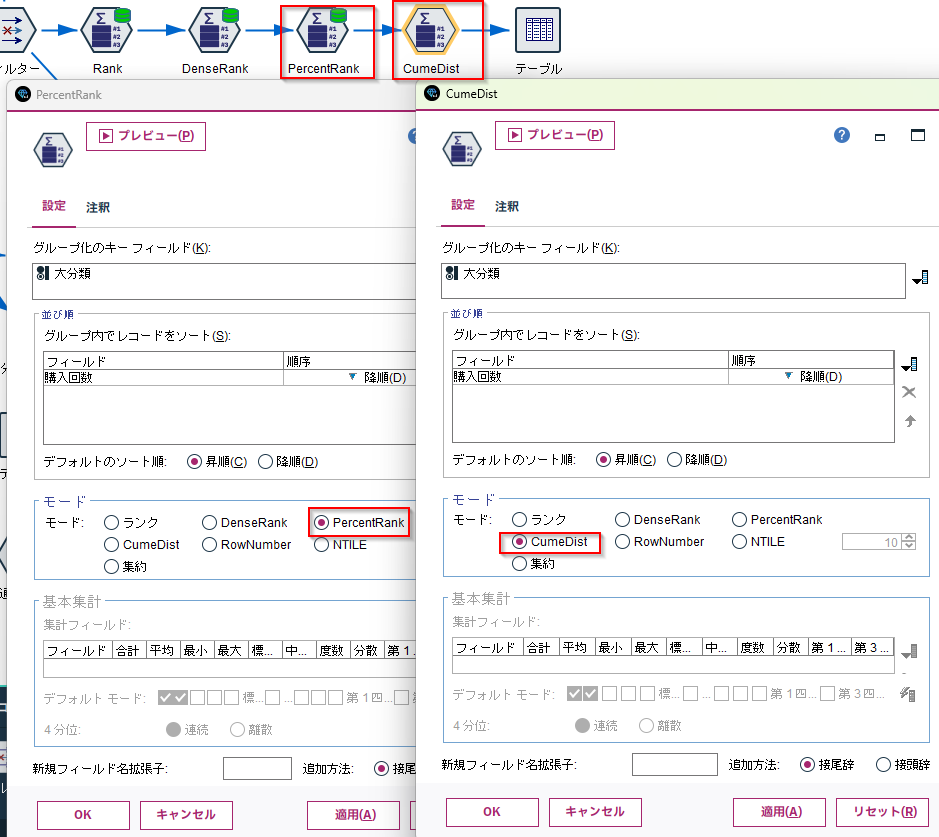
式で表すと以下です。
- PercentRank(百分率での順位) = ( RANK関数で計算した順位 - 1 ) / ( 全体のデータ数 - 1 )
- CumeDist(累積割合) = その値以下のデータ数 / 全データ数
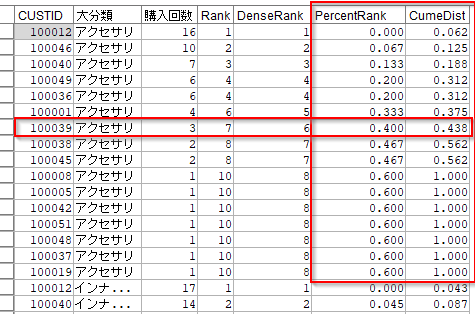
以下の例のCUSTID100039は次のようになります。
- PercentRank(百分率での順位)0.400 = ( 7 - 1 ) / ( 16 - 1 )
- CumeDist(累積割合)0.438 = 7 / 16
従来の方法:@OFFSETでDenseRankを取得する
まずソートノードで大分類と購入回数でソートしてから、カウント型のフィールド追加ノードで@OFFSETを使う必要があります。この処理は@OFFSETがあるためSQLプッシュバックできません。
同順位のあるランク(RANKとDENSE_RANK) を作成する(SPSS Modeler データ加工逆引き3-28)で詳しく紹介されています。
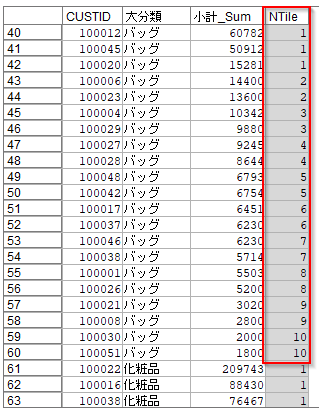
3.4. グルーピングしてパーセンタイルを各行に入れる
大分類ごとに売上の高い順にならべて10分位に分けています(デシル分析)。
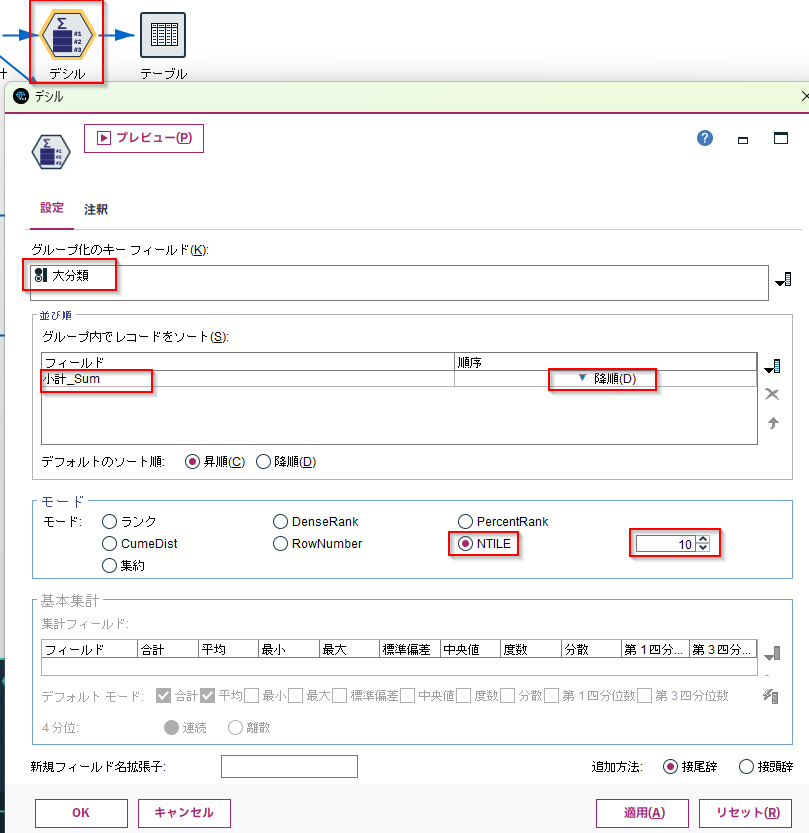
[OLAP]ノードに以下の設定をします。
- グループ化のキーフィールドに
大分類を選びます - ソートでフィールドに
小計_Sumを選び、降順にします - モードを
NTILEにし、10分位を指定します
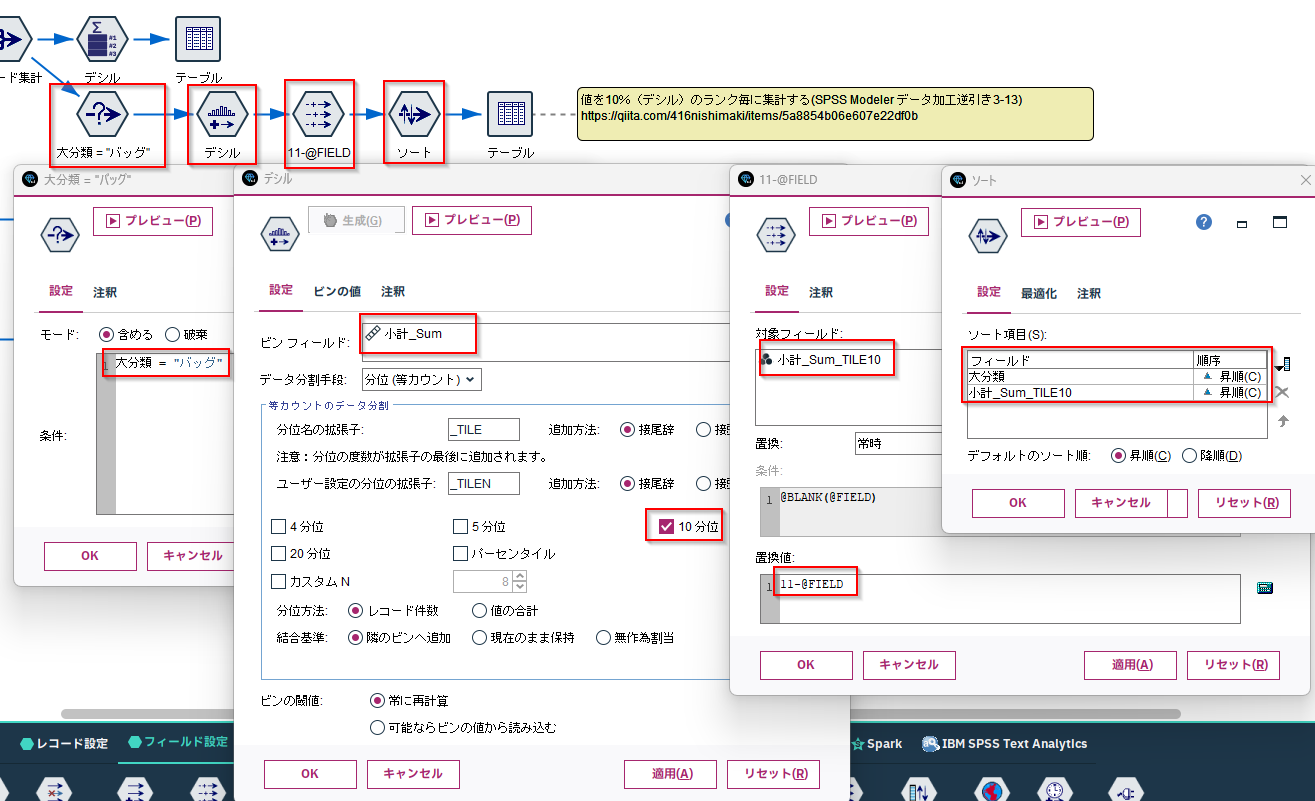
従来の方法:データ分割ノードでデシル分析をする
まず、条件抽出ノードで、大分類 = "バッグ"で絞り込みます。その後、データ分割ノードで10分位をつくり、置換ノードで順位を反対にしてから、ソートで並べ替えます。
値を10%(デシル)のランク毎に集計する(SPSS Modeler データ加工逆引き3-13)で詳しく紹介されています。
大分類でグルーピングしてデシル分析をする場合、各大分類ごとに同じ処理を作る必要があります。
この処理はSQLプッシュバック可能です。
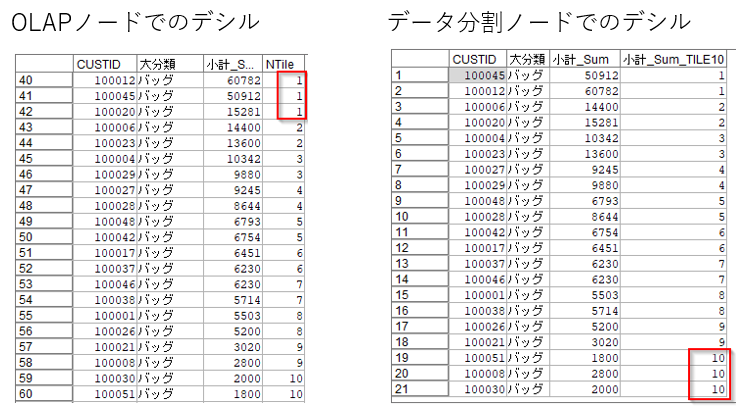
なお、OLAPノードとデータ分割ノードでは各パーセンタイルへの割当順序が若干異なりました。以下の例では21件のデータを10分位で分けたので、1分位だけ1件多く割り当てられます。OLAPノードは1位の分位が3件、データ分割ノードでは10分位が3件になっています(パーセンタイルが売上昇順で作られ、後で逆順にしたためです)。実際にはもっと多い件数で行うので問題にはならないと思います。
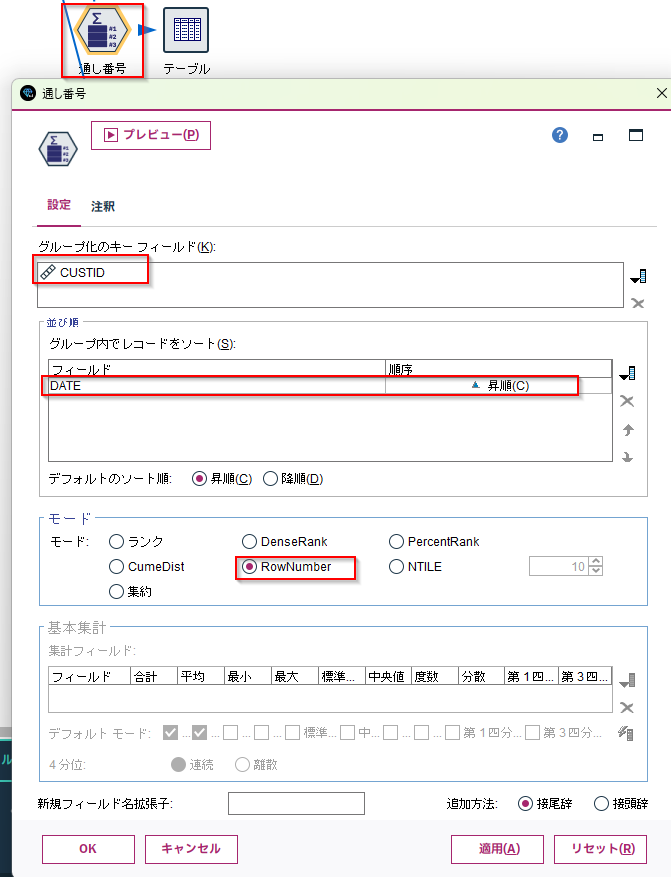
3.5. グルーピングして通し番号を各行に入れる
CUSTIDごとにDATE順にならべて、通し番号を振っています。
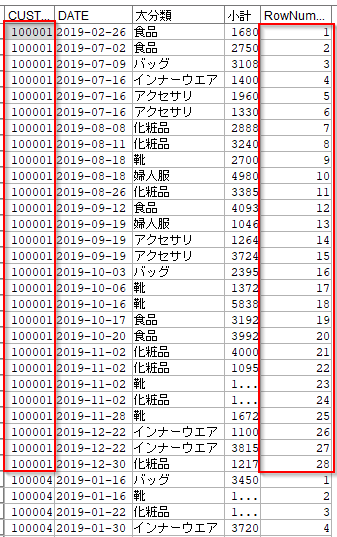
[OLAP]ノードに以下の設定をします。
- グループ化のキーフィールドに
CUSTIDを選びます - ソートでフィールドに
DATEを選び、昇順にします - モードを
RowNumberに指定します
従来の方法:@OFFSETで通し番号を振る
まずソートノードでCUSTIDとDATEでソートしてから、カウント型のフィールド追加ノードで@OFFSETを使う必要があります。この処理は@OFFSETがあるためSQLプッシュバックできません。
全レコード/設備毎に通し番号を振る(SPSS Modeler データ加工逆引き4-1) で詳しく紹介されています。
なお、OLAPノードとデータ分割ノードでは各パーセンタイルへの割当順序が若干異なりました。以下の例では21件のデータを10分位で分けたので、1分位だけ1件多く割り当てられます。OLAPノードは1位の分位が3件、データ分割ノードでは10分位が3件になっています(パーセンタイルが売上昇順で作られ、後で逆順にしたためです)。実際にはもっと多い件数で行うので問題にはならないと思います。
4.Tips
- 以前のバージョンでのパレットの設定が残っていると、OLAPノードやOFFSETノードがノード・パレットに現れません。以下の「18.4」の部分を「_18.4」などに変更してください。
C:\Users\<USERNAME>\AppData\Roaming\IBM\SPSS\Modeler\18.4
- OLAPノードやOFFSETノードはSQLプッシュバック専用ノードであり、RDBとの連携が必須です。RDBとの接続がないと「実行に失敗しました。 サポートされていない操作です」のエラーになります
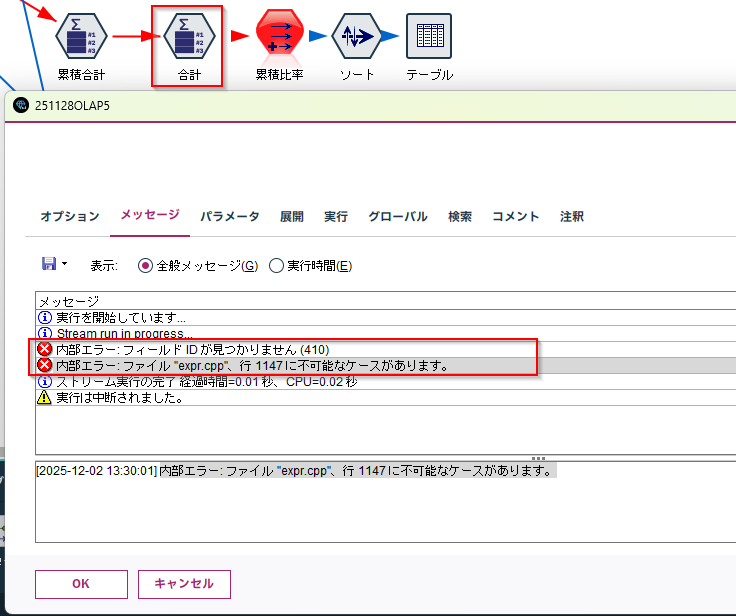
- OLAPノードの後にOLAPノードをいれるなどの加工によっては「内部エラー: フィールド ID が見つかりません (410)」「内部エラー: ファイル "expr.cpp"、行 1147 に不可能なケースがあります。」というエラーが起きることがありました。回避するにはOLAPノードをキャッシュして一旦SQLを途切れさせることが有効でした

5.参考情報
サンプルストリーム
ノードのヘルプ OLAPノード - IBM Documentation
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次