基準となる平均と標準偏差を元に複数列のZスコアを計算する
zスコアの計算例は過去の記事にもありますが、
zスコアを計算する際に基準となる平均と標準偏差を、異常値による影響を避けるために、例えば前日の値に固定したいようなことがあります。
1.想定される利用目的
- 異なる尺度をもつフィールド(列)間の比較
- 特徴量への変換(予測アルゴリズムに応じて)
- 異常値の監視
2.サンプルストリームとデータのダウンロード
ストリーム
データ
3.サンプルストリームの説明
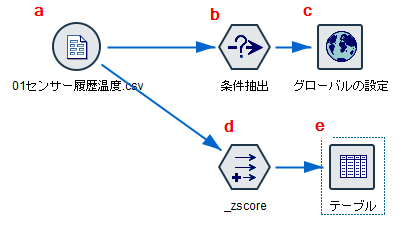
a.入力するデータは以下の通りです。
タイムスタンプと温度1と温度2の列があります。
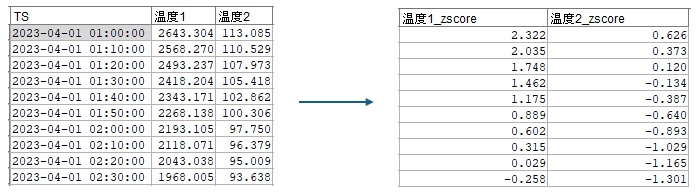
2023-04-01の平均値と標準偏差を基に温度1と温度2のzスコアを計算したいと思います。
2023-04-01の平均値と標準偏差をグローバル値として計算します
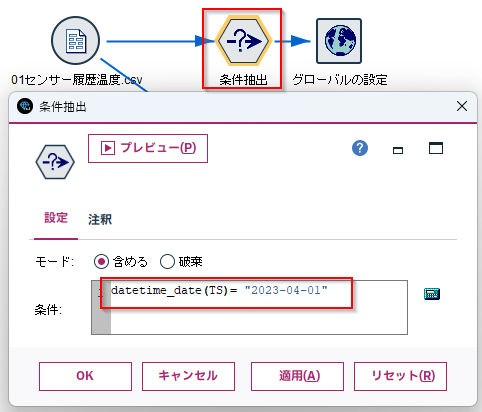
b.[条件抽出]ノードを編集します。
以下の式で「2023-04-01」のデータに絞り込みます。
datetime_date(TS)= "2023-04-01"
c.[グローバルの設定]ノードで温度1と温度2を選択し、「平均」と「標準偏差」を選びます。
値を上書きしないように念のために「実行前にすべてのグローバル値を消去」のチェックは外しておき、実行します。

ストリームのプロパティの「グローバル」タブを見ると平均値と標準偏差が計算されています。

Zスコアに変換する
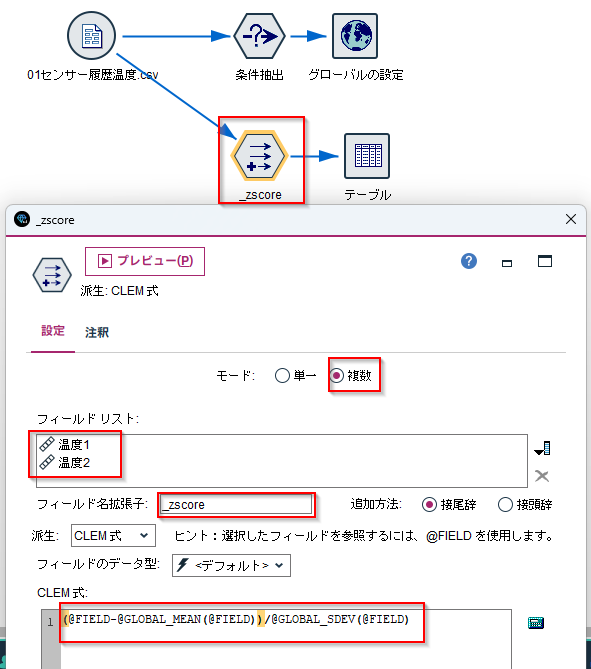
d.[フィールド作成]ノードを編集します。
「モード」を「複数」にします。
「フィールドリスト」に温度1と温度2を選択します。
「フィールド名拡張子」には「_zscore」を入れました。
そしてCLEM式に以下を入れます。@FIELDでグローバル値を参照しているので、複数列の計算が一度に行えます。
(@FIELD-@GLOBAL_MEAN(@FIELD))/@GLOBAL_SDEV(@FIELD)
e.[テーブル]ノードで結果を見ます。
2023-04-01の平均値と標準偏差を基に温度1と温度2のzスコアが計算できています。

4.参考情報
値をZスコアに標準化する(SPSS Modeler データ加工逆引き3-11) #SPSS_Modeler - Qiita
SPSS ModelerでZスコアを扱った記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)