概要
少量の学習データ(Few-Shot)でも精度が出る深層学習手法が登場してきています。
その一つがSetFitです。テキスト分類向けのFew-Shot学習手法です。
本記事では、SetFitを使うとよい(使わない方がよい)場面を見極めるために、リアルな問題に近い日本語ニュースジャンル分類タスクをお題に、学習データ数を変えながらそこそこ強い日本語T5と戦わせてみます。
忙しい方向けに最初に結論をまとめ、その後にSetFitの使い方の説明を兼ねて実験を再現するためのコードの解説をしていきます。
結論
Livedoor news記事のジャンル分類タスク(9分類タスク)について、クラスあたりのデータ数を2倍ずつ変えながら、SetFitと日本語T5それぞれについて分類精度を計測しました。
結果は下図のとおりです。

なお、クラスあたりのデータ数は全クラスで同一(均衡)になるようにランダムサンプリングしています。
64個のところで優劣が逆転していることが見て取れますね。
従って、このタスクの場合には、次のことが言えます。
- クラスあたりのデータ数が64個未満(合計576個未満)ならSetFitを使おう。
- クラスあたりのデータ数が64個以上(合計576個以上)ならT5モデルを使おう。
優劣逆転が起こるデータ数はタスクによって異なるでしょうが、逆転が起こること自体は一般的な事象であることが予想されます。
また、学習時間(バリデーション処理を除く、訓練処理のみの時間)は下図のようになりました。学習にはGoogle ColaboratoryのT4 GPUを利用しました。
SetFitの方がT5より約3倍長いことが分かります。
この点でもデータ数が多い場合はT5を使った方がよいと言えますね。

SetFitとは
SetFitアルゴリズムの要点について説明します。
- ブログ: SetFit: Efficient Few-Shot Learning Without Prompts
- 論文: Efficient Few-Shot Learning Without Prompts
- リポジトリ: https://github.com/huggingface/setfit
SetFitは、Sentence-BERTモデル(意味が近い文に対して近いベクトルを割り当てるという文埋め込みモデル。日本語モデルはこちら)を個別の分類タスクのよい特徴量になるように調整することで、few-shotでも高い分類精度を出せる学習アルゴリズムです。
下図のように2段階で学習を進めます。
- ST Fine tuning: 学習済みSentence-BERTモデルを個別の分類タスク用にファインチューニングします。同じクラスの文を正例に、別のクラスの文を負例にした距離学習により、同じクラスの文同士では文ベクトルが近く、別のクラスの文とは遠くなるようにファインチューニングします。負例は、正例と同数になるように(ダウン)サンプリングされるため、クラス数が増えるほどクラスあたりのデータ数が必要になることが予想されます。
- Classification head training: 1のファインチューニングにより個別の分類タスクに適した文ベクトルを作れるようになったことから、それを特徴量に用いて分類用のニューラルネットワークを学習します。分類用のネットワーク自体には何も新しい点はありません。つまり、1の文ベクトルのファインチューニングがfew-shot性能を高めるためのメインアイディアであるとわかります。
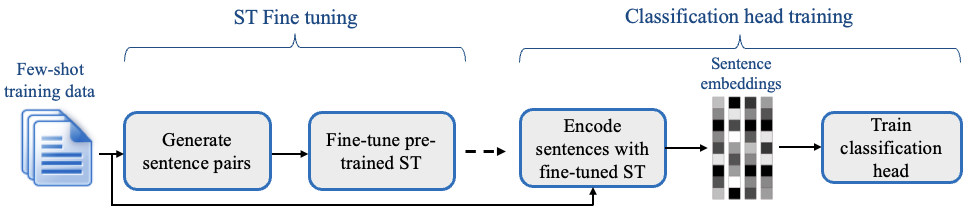
(図の出典: SetFitのリポジトリ)
(拙作の)以下の学習済み日本語Sentence-BERTモデルや日本語T5モデルを使えば日本語文章の分類が可能です。
- 日本語Sentence-BERTモデル
- 日英Sentence-BERTモデル
- 日本語T5モデル
- 日英T5モデル
実験コードの解説
本記事の実験結果を再現するためのコード(Colab notebook)を以下に公開しました。
- SetFitを用いた分類: https://colab.research.google.com/github/sonoisa/misc/blob/main/nlp/SetFit_japanese_document_classification.ipynb
- T5を用いた分類: https://colab.research.google.com/github/sonoisa/misc/blob/main/nlp/t5_japanese_classification_fewshot.ipynb
今回、比較実験に選んだお題は、Livedoor news記事のジャンル分類タスク(9分類タスク)です。
実業務の場面では多クラス分類が多いでしょうし、学習データの不足やら不均衡やらに苦しめられることも多いでしょうから、それに近いものとして、この分類タスクを選びました。
日本語T5モデルを用いたジャンル分類は以前書いた「【日本語モデル付き】2021年に自然言語処理をする人にお勧めしたい事前学習済みモデル」とほぼ同じため、その記事をご参照いただくということで省略いたします。
それでは本記事ではSetFitにフォーカスしてコードを解説していきます。
まず、必要なライブラリをインストールします。setfitがSetFitライブラリ、fugashiとipadicは日本語Sentence-BERTに必要なライブラリです。
!pip -q install setfit fugashi ipadic
学習に用いるデータはディレクトリ /content/data に、学習済みモデルは /content/model に格納するようにします。
!mkdir -p /content/data /content/model
前述のとおり、日本語Sentence-BERTモデルにはいくつかありますが、今回はsonoisa/sentence-bert-base-ja-mean-tokens-v2を利用します。
# 事前学習済みモデル
PRETRAINED_MODEL_NAME = "sonoisa/sentence-bert-base-ja-mean-tokens-v2"
# 転移学習済みモデルを保存する場所
MODEL_DIR = "/content/model"
次にLivedoor newsコーパスのダウンロード、正規化、学習に利用しやすいフォーマットへの変換を行いますが、それは過去記事「【日本語モデル付き】2021年に自然言語処理をする人にお勧めしたい事前学習済みモデル」とほぼ同じため省略します。
コードで言うとセクション「SetFit用の訓練データ作成」までお進みください。
この時点でサンプリング前のデータセットであるtrain_full.json(とdev.json、test.json)が出来ているはずです。
次のコードを実行してfew-shot学習データを作成します。
変数samples_per_classはクラスあたりのデータ数です。この値を変えながら実行することで、few-shot学習の精度を計測することができます。このコードでは各クラス8個に指定してあります。
クラスあたりのデータ数を同一(均衡)にすることが精度アップに重要ですので、クラスごとにデータを絞り込んでその中からsamples_per_class個のデータをサンプリングするようにしています。
few-shot学習データはtrain_fewshot.jsonに保存されます。
import json
from datasets import load_dataset
class_labels = list(range(9)) # 分類ラベルのリスト
samples_per_class = 8 # クラスあたりのデータ数
train_dataset = load_dataset("json", data_files="/content/data/train_full.json")["train"]
train_dataset = train_dataset.shuffle(seed=5678)
with open("/content/data/train_fewshot.json", "w", encoding="utf-8") as f_out:
for class_label in class_labels:
class_data = train_dataset.filter(lambda x: x["label"] == class_label).select(range(samples_per_class))
assert len(class_data) == samples_per_class
for data in class_data:
f_out.write(json.dumps(data, ensure_ascii=False))
f_out.write("\n")
説明不要なレベルのコードですが、次のコードで学習と評価に用いるデータセットを読み込みます。
コメントに書かれているとおりですが、全データセットを用いて学習を行う場合はtrain_full.jsonを読み込むようにしてください。
# 全データを利用する場合
# train_dataset = load_dataset("json", data_files="/content/data/train_full.json")["train"].shuffle(seed=42)
# サンプリングされたデータを利用する場合
train_dataset = load_dataset("json", data_files="/content/data/train_fewshot.json")["train"].shuffle(seed=42)
eval_dataset = load_dataset("json", data_files="/content/data/test.json")["train"]
print(f"train_dataset: {len(train_dataset)}")
for sample in train_dataset:
# print(sample)
pass
これで準備は完了です。次のコードでSetFitアルゴリズムを用いた学習を実行します。
実行は素晴らしく簡単で、SetFitTrainerのtrain()を呼ぶだけです。
ハイパーパラメータはデフォルトの値を用いています。
なお、ハイパーパラメータを変えながら何度か実験したのですが、精度の変化は誤差レベルだったため、結局デフォルト値に落ち着きました。
クラスあたりのデータ数が8個のとき、学習はT4 GPUを用いて1分43秒前後で完了します。
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
model = SetFitModel.from_pretrained(PRETRAINED_MODEL_NAME)
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
batch_size=16,
num_iterations=20,
num_epochs=1,
learning_rate=2e-5,
seed=42,
)
trainer.train()
精度評価をするだけなら不要ですが、次のコードを実行すれば学習済みモデルを保存できます。
trainer.model.save_pretrained(MODEL_DIR)
それでは学習済みモデルの精度(Accuracy)を評価します。
クラスあたりのデータ数が8個では63.5%前後になります。
metrics = trainer.evaluate()
print(metrics)
{'accuracy': 0.6354545454545455}
クラスあたりのデータ数を変えながら実験を繰り返すことで以下の結果が得られます。
精度は多少上下するかもしれません。
| データ数/クラス | SetFit | T5 |
|---|---|---|
| 8 | 63.8% | 2.9% |
| 16 | 67.9% | 3.4% |
| 32 | 73.1% | 40.5% |
| 64 | 77.2% | 86.9% |
| 128 | 80.4% | 91.8% |
| 256 | 85.6% | 94.3% |
| 570.4 | 89.5% | 96.2% |
これをプロットにすると下図のようになります。
クラスあたりのデータ数が32〜64個のところに境界があることが分かります。
まとめ
リアルな状況に近い多クラス分類タスクを題材に選び、データ量を変えながらfew-shot学習手法SetFitとT5モデルを競い合わせてみることで、それぞれが活きるデータ量を明らかにしました。
実験を再現するコードもほぼそのまま他の問題に活用できるものになっているかと思います。
これらのコードと分析結果を、何かの問題解決にご活用いただけたら幸いです。