2023/03/20 追記
Studio Ousia様によるLUKEモデルをベースに学習したSentence-LUKEモデルを公開しました。
- Sentence-LUKEモデル: https://huggingface.co/sonoisa/sentence-luke-japanese-base-lite
手元の非公開データセットでは、日本語Sentence-BERTモデル(バージョン2)と比べて定量的な精度が同等〜0.5pt程度高く、定性的な精度は本モデルの方が高い結果でした。
2021/12/14 追記
MultipleNegativesRankingLossを用いて学習した改良版モデルを公開しました。
- 改良版(バージョン2)のモデル: https://huggingface.co/sonoisa/sentence-bert-base-ja-mean-tokens-v2
手元の非公開データセットでは、バージョン1よりも1.5〜2ポイントほど精度が高い結果が得られています。
実験したところ、MultipleNegativesRankingLossはSoftmaxLossを用いる場合と比べて1/10程度で同等の精度になる傾向がありました。
2021/12/06 追記
本モデルの応用例として「いらすとや」さんの画像を検索するアプリをHuggingFace Spacesに公開しました。
2021/07/22 追記
- FloydHubの閉鎖に伴い、学習済みモデルの置き場所をHuggingFace model hubに変更しました。
- GitHubリポジトリのチェックアウトを不要にし、学習済みモデルをより簡単に利用できるようにしました。
要点
- Sentence-BERT(論文、実装)の日本語モデルを作り、公開しました。
- この日本語モデルを使うことで、誰でも簡単に高品質な文ベクトルを作れるようになります。ご活用ください。
- Sentence-BERTとは、事前学習されたBERTモデルとSiamese Networkを使い、高精度な文ベクトルを作る手法です。
- 英語版の精度評価(STSbenchmarkを用いたコサイン類似度と正解ラベルのspearmanの順位相関係数。1に近いほど良い)では、素朴な単語ベクトル(GloVe)の平均を用いる方法では0.58、今回作った規模相当のモデルでは0.85前後です(論文のTable 2参照)。
- なお、素のBERTのCLSベクトルを用いると精度は0.17、BERTの埋め込みの平均を用いると0.46となり、単語ベクトルの平均の結果(0.58)よりも悪い結果になります(論文のTable 1と2参照)。BERTの原論文にも書かれているとおり、これらを文ベクトルとして使うことは適切ではありません。
イメージ
はじめに
(日本語において)品質の高い、つまり、字面ではなく文脈を踏まえた文の意味が近いほど近いベクトルになるという性質を持ったベクトルを作る話です。
趣味や実務で意味が近い文を探すなどの目的で、文ベクトルを作るということをしている人は一定数いると思います。
しかし、単語ベクトルの平均でも悪くはないけれども、いまいちな場面が出てきて、気がつくとヒューリスティクスという名の迷路に迷い込んだりしていないでしょうか(特定の単語や品詞をストップワードにしてみたり、謎の重み付けを加えてみたり。え、根拠は?と)。
他にも、単語ベクトルの平均では多義語が扱えずに困ったり、文脈が考慮されないため「そこじゃない」という単語に着目した類似文検索になったり。
一方、Universal Sentence Encoderのような既存の深層ニューラルネットワークを用いた文ベクトルモデルの学習は計算コストが高すぎて、自分で学習させるのは辛かったりも。
こういう悩みを抱えている同志向けに、論文 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networksで提案された手法を使い高品質な日本語文ベクトルモデルを作り、公開します。
前提知識
- 現代的な自然言語処理の基礎知識
- BERTとは何か
- 文ベクトル(文の分散表現)とは何か
- Google Colaboratoryの使い方
- 文ベクトルを実際に使った経験がある
日本語文ベクトルモデルの使用例
Sentence-BERTの技術的な解説の前に、使い方から説明します。簡単です。
例では次の2つを行います。これらの例はGoogle Colaboratoryで実際に試せます。
- 与えられたクエリ文に意味が近い文を検索する。
- タイトル文の潜在意味空間をUMAPで可視化する。
- Colaboratory Notebook: https://colab.research.google.com/github/sonoisa/sentence-transformers/blob/master/sentence_transformers_ja.ipynb
※GPUが必要です。TensorBoardを使用するためChromeで開いてください。
セットアップ
関連するライブラリをインストールします。
!pip install -q transformers==4.7.0 fugashi ipadic
- transformers: BERTを含むTransformer系モデルの実装を提供してくれるライブラリ
- fugashi: Pythonから形態素解析器MeCabを利用するためのラッパー
- ipadic: 形態素解析辞書
日本語Sentence-BERTクラス定義
推論用の日本語Sentence-BERTクラスを定義します。
処理は非常にシンプルです。日本語Sentence-BERT用に転移学習したBERTを用いて各トークンの埋め込みを求め、それを平均したものが求める文の埋め込みです。
from transformers import BertJapaneseTokenizer, BertModel
import torch
class SentenceBertJapanese:
def __init__(self, model_name_or_path, device=None):
self.tokenizer = BertJapaneseTokenizer.from_pretrained(model_name_or_path)
self.model = BertModel.from_pretrained(model_name_or_path)
self.model.eval()
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(device)
def _mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
@torch.no_grad()
def encode(self, sentences, batch_size=8):
all_embeddings = []
iterator = range(0, len(sentences), batch_size)
for batch_idx in iterator:
batch = sentences[batch_idx:batch_idx + batch_size]
encoded_input = self.tokenizer.batch_encode_plus(batch, padding="longest",
truncation=True, return_tensors="pt").to(self.device)
model_output = self.model(**encoded_input)
sentence_embeddings = self._mean_pooling(model_output, encoded_input["attention_mask"]).to('cpu')
all_embeddings.extend(sentence_embeddings)
# return torch.stack(all_embeddings).numpy()
return torch.stack(all_embeddings)
日本語モデルの読み込み
日本語Sentence-BERTクラスを定義します。
HuggingFaceに格納された日本語モデル名 sonoisa/sentence-bert-base-ja-mean-tokens を引数にSentenceTransformerインスタンスを生成すれば、モデルの読み込み完了です。
model = SentenceBertJapanese("sonoisa/sentence-bert-base-ja-mean-tokens")
文ベクトルの計算
文ベクトルを計算します。ただ、model.encode(文のリスト)を呼び出すだけです。
この例では文として、別の記事で公開している「いらすとや」さんのタイトル(を少し加工したもの)を用いることにします。
(本当はもう数倍は長い文章の方が効果を示すのにいいのですが、すぐ用意できなかったため、ひとまずタイトルで。もっと適切な文章を用意できたら説明を追加します)
# 出典: https://qiita.com/sonoisa/items/775ac4c7871ced6ed4c3 で公開されている「いらすとや」さんの画像タイトル抜粋(「のイラスト」「のマーク」「のキャラクター」という文言を削った)
sentences = ["お辞儀をしている男性会社員", "笑い袋", "テクニカルエバンジェリスト(女性)", "戦うAI", "笑う男性(5段階)",
...
"お金を見つめてニヤけている男性", "「ありがとう」と言っている人", "定年(女性)", "テクニカルエバンジェリスト(男性)", "スタンディングオベーション"]
sentence_vectors = model.encode(sentences)
文ベクトルの計算はこれだけです。
意味が近い文を検索する
計算した文ベクトルを用いて、意味が近い文(いらすとのタイトル)を検索してみます。
文ベクトルのコサイン距離が小さいものを探します。
import scipy.spatial
queries = ['暴走したAI', '暴走した人工知能', 'いらすとやさんに感謝', 'つづく']
query_embeddings = model.encode(queries).numpy()
closest_n = 5
for query, query_embedding in zip(queries, query_embeddings):
distances = scipy.spatial.distance.cdist([query_embedding], sentence_vectors, metric="cosine")[0]
results = zip(range(len(distances)), distances)
results = sorted(results, key=lambda x: x[1])
print("\n\n======================\n\n")
print("Query:", query)
print("\nTop 5 most similar sentences in corpus:")
for idx, distance in results[0:closest_n]:
print(sentences[idx].strip(), "(Score: %.4f)" % (distance / 2))
以下、出力結果です。
暴走 ≒ 戦い、武器と捉えられるので、自然な結果になっていると思います。
心を持つと確かに暴走しうるとも捉えられますね。
======================
Query: 暴走したAI
Top 5 most similar sentences in corpus:
戦うAI (Score: 0.1521)
心を持ったAI (Score: 0.1666)
武器を持つAI (Score: 0.1994)
人工知能・AI (Score: 0.2130)
画像認識をするAI (Score: 0.2306)
AIを人工知能に言い換えました。結果が変わりました。
表記が近いものの方が上位にくる傾向はあるようです。
======================
Query: 暴走した人工知能
Top 5 most similar sentences in corpus:
仕事を奪う人工知能 (Score: 0.1210)
人工知能と喧嘩をする人 (Score: 0.1389)
人工知能 (Score: 0.1411)
成長する人工知能 (Score: 0.1482)
人工知能・AI (Score: 0.1629)
感謝 =「ありがとう」ということを分かっていますね。
======================
Query: いらすとやさんに感謝
Top 5 most similar sentences in corpus:
「ありがとう」と言っている人 (Score: 0.1381)
福笑いのおたふく (Score: 0.1693)
福笑い(ひょっとこ) (Score: 0.1715)
福笑い(おかめ) (Score: 0.1743)
笑いをこらえる人(男性) (Score: 0.1789)
文ではなく、単一の単語でも近い文を探せています。
======================
Query: つづく
Top 5 most similar sentences in corpus:
いろいろな映画の「つづく」 (Score: 0.1878)
シンギュラリティ (Score: 0.2703)
愛想笑い (Score: 0.2811)
ありがた迷惑 (Score: 0.2881)
ハリセン (Score: 0.2931)
TensorBoardで潜在意味空間を可視化する
以下のコードを実行し、ColaboratoryのTensorBoard拡張を使って、文ベクトルの空間を低次元空間にマップして可視化してみます。
※Chromeでないと表示されないことがあります。
%load_ext tensorboard
import os
logs_base_dir = "runs"
os.makedirs(logs_base_dir, exist_ok=True)
import torch
from torch.utils.tensorboard import SummaryWriter
import tensorflow as tf
import tensorboard as tb
tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
summary_writer = SummaryWriter()
summary_writer.add_embedding(mat=np.array(sentence_vectors), metadata=sentences)
%tensorboard --logdir {logs_base_dir}
- TensorBoardが起動したら、右上のメニューからPROJECTORを選択してください。
- 可視化アルゴリズム(TensorBoardの左下ペイン)はUMAPの2D、neighbors(TensorBoardの右ペイン)は10に設定すると見やすいでしょう。
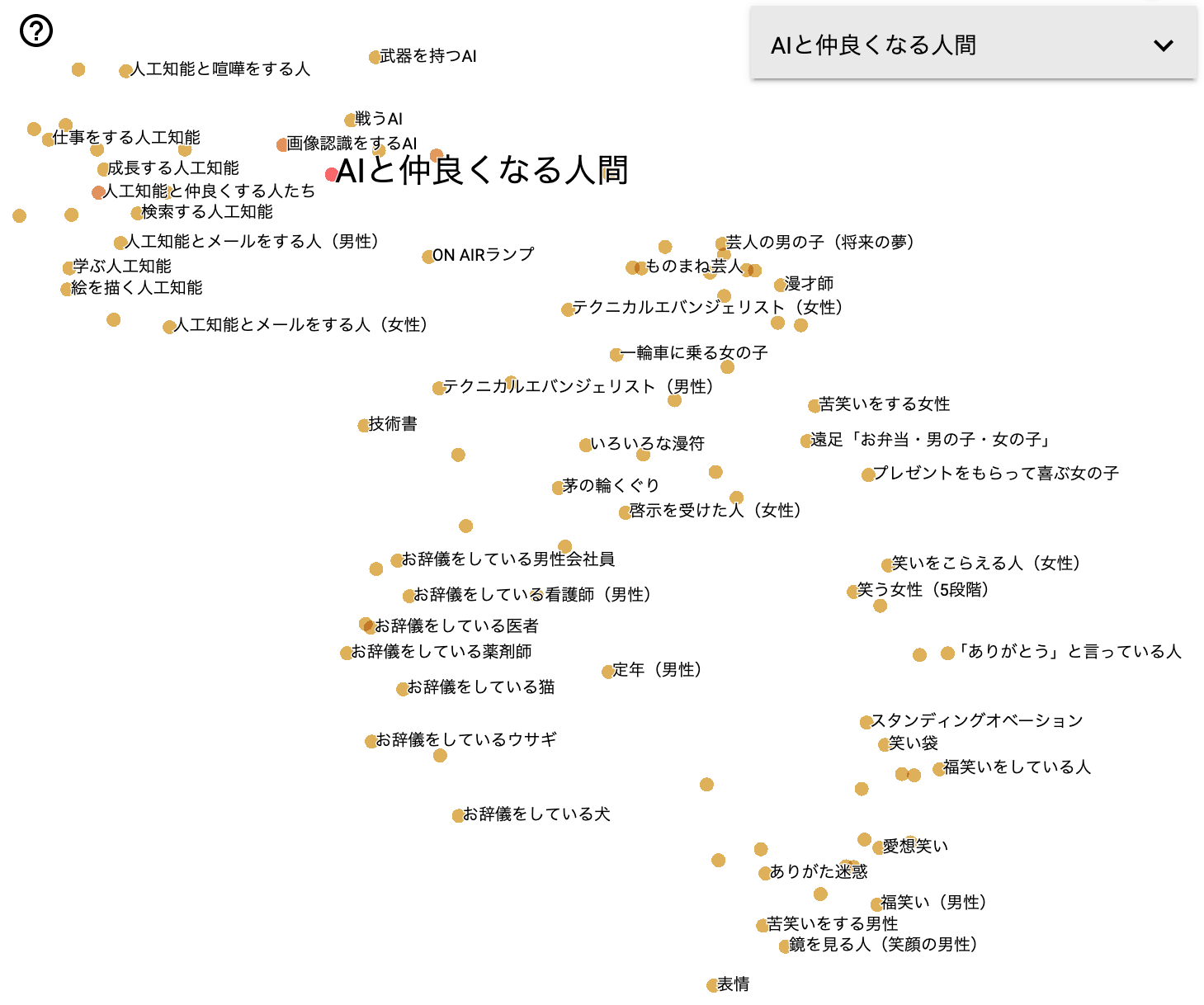
うまくいけば文ベクトルの空間が次のように可視化されます。
左上に「人工知能」系がありそのすぐ右に「AI」系の塊が見えます。
左下には「お辞儀」系、中央はその他少数の雑多なもの、右には「女性」系、下には「男性」系の塊が見えます。

Sentence-BERTの概要
(とても読みやすい論文ですので、解説不要な気がしますが)
- 論文: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- オリジナル実装: UKPLab/sentence-transformers (※オリジナル実装では日本語版モデルは動かないので注意)
一言で言えば、BERTでトークンを埋め込み、mean poolingすることで作る文ベクトルをSiamese Networkを使い距離学習(finetune)させるというものです。シンプルですね。
以下に引用した論文のFig.1と2を見れば大体分かると思います。

論文では他の方法も色々実験されていますが、日本語モデル構築では、最高性能だったこのネットワーク構造を採用しています。
以下に引用したTable 2のように、英語版の精度評価(STSbenchmarkを用いたコサイン類似度と正解ラベルのspearmanの順位相関係数。1に近いほど良い)では、素朴な単語ベクトル(GloVe)の平均を用いる方法では0.58、今回作った規模相当のモデルでは0.85前後です。

また、論文のTable 1によれば、素のBERTのCLSベクトルを用いると精度は0.17、BERTの埋め込みの平均を用いると0.46となり、単語ベクトルの平均の結果(0.58)よりも悪い結果になります。BERTの原論文にも書かれているとおり、これらを文ベクトルとして使うことは適切ではないことが分かります(想像以上に悪いですね)。
日本語版のモデルの作成において、huggingface/transformers(モデルは東北大学 乾・鈴木研究室様作)の日本語版BERTモデルを用いています。
そして今回の日本語モデルの学習方法(学習に用いたデータセット、精度評価方法)ですが、、、すみませんが諸般の事情により秘密です。結果としては、英語版と遜色ない、文脈を加味した文ベクトルを作れているようにみえています。
日本語版ソースコードとモデルのダウンロード
上記の例でも用いた、日本語版のソースコードとモデルは以下からダウンロードすることができます。
免責事項
著者は本記事を掲載するにあたって、その内容、機能等について細心の注意を払っておりますが、内容が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。
本記事内容のご利用により、万一、ご利用者様に何らかの不都合や損害が発生したとしても、著者や著者の所属組織(日鉄ソリューションズ株式会社(NSSOL、旧新日鉄住金ソリューションズ株式会社))は何らの責任を負うものではありません。
まとめ
Sentence-BERTの日本語版コードとモデルを作りました。
これで誰でも簡単に高品質な文ベクトルを作れるようになります。
ご活用ください。