「ビルトインモジュールが色々あってぜんぜん分からない。俺達は雰囲気で並列処理を使っている」という状態だったので、良くないと思ってPythonの並列処理と並行処理をしっかり調べてみました。
少し長めです。細かいところまで把握するためのもので、仕事などの都合でさくっと調べて使いたい方は別の記事をご確認ください。
使った環境
- Python 3.6.1 :: Anaconda 4.4.0 (64-bit)
- Ubuntu
- Jupyter notebook(一部マジックコマンドなども利用しています)
※Windowsの場合、マルチプロセスなどで直接Jupyter上で動いてくれない(.pyファイルを経由すると動く)などのケースがあります。
参考 : Jupyter notebook never finishes processing using multiprocessing (Python 3)
並行処理
- マルチスレッド。
- 複数の関数を1つのプロセス(コア)内で動かすことができる。
- Pythonでは、メモリを安全に扱うためのGIL(Global Interpreter Lock)という排他ロックの仕組みが使われており、安全・快適に実装ができる一方で、並行処理では基本的に速くならないことが多い。(もし関数の中でスリープやリクエストなどのレスポンス待ちなどがあれば話は変わってくる)
- ロックでの切り替えなどのオーバーヘッドで、むしろ遅くなったりする。
- GILをPython環境のまま回避するのは大分ハードらしい。回避したければ、C/C++とかを絡ませるか、NumPyなどのライブラリを活用するのが現実的。
- ※CPythonはGILに縛られる。JythonやIronPythonなどは縛られないそうだけど、職場などでの周りの方で使っている方もいないし、互換性的なところもあるらしい。
- 並列処理を車線を増やす対応、並行処理は十字路で、GILという信号機があるのをイメージすると少し分かりやすいかもしれない。
- 信号機を守ったほうが安全だけど、信号待ちで結局各車のトータルの走行距離は短くなったりする。車線を増やした場合は普通にトータルの走行距離は長くなる(信号無視したほうが速いけど危険)。
どんなときに向いているのかの一例(GILがある前提)
- たとえば、非常に処理時間の長い処理があった際に、ずっとそこで止まっているのとフリーズしているように見えてしまうかもしれない。並行処理で、関数を切り替えてライトな処理を消化したりしていた方が、UX的には親切になるかもしれない。
- マルチプロセスにするとメモリ上のデータのやり取りがネックになってくる。そういったやりとりによる負担を抑えつつ、複数の関数の処理を同時に進めたい場合など。
- 処理が待ちになる(スリープとか)場合には、CPUなどのリソースが空くので、その間に別の関数に切り替わったほうがトータルで速くなるケース。
- そもそもコアが1つしかなくてマルチプロセスが使えない(でも、一つの処理で長時間ブロックされたくない)ようなケース(今のご時勢ほぼない気もする・・)。
並行処理の各モジュール
thread
- 古いPython2系のバージョンだとこのモジュールしかなかったりするものの、基本的には使い勝手が悪いので使わない。
- Python3系では間違って使わないように、_threadとアンダースコアがつけられているらしい。
threading
- thread上位互換。並行処理のベーシックなビルトインモジュール。
- インターフェイスが大分親切になった。
- Python3系はもちろんのこと、2.7系とかでももう使えるので、基本的にはthreadを使うくらいならthreadingを使うことになる。
concurrent.futures
- Python3.2以降に登場。基本的にthreadingよりもさらに優秀。
- なお、futureは並列処理のFutureパターンに由来する。(1960~1970年代などに発展し、提案された結構昔からあるもの)
カール・ヒューイットは、2つの点で future の方が promise よりも適した用語であるとしている。第一に promise(約束)は必ずしも将来の時点のことを意味しないため、future(未来)よりも曖昧である。第二に promise は単なる言語表現だが、future は現物(actuals)に対する先物(futures)という意味もある(つまり、実際の物に対する代用品)。
Wikipedia Future パターン より
- スレッド数の上限を指定して、スレッドの使いまわしなどをしたりしてくれるらしい。
最初に同時に動かす最大数 max_workers を決めるとスレッドを使いまわしてくれるので上で紹介した普通のスレッドよりかしこいです。
Pythonの並列・並行処理サンプルコードまとめ
- また、マルチスレッドとマルチプロセスの切り替えも1行変える程度で、このモジュールで扱えるので、途中で変えたくなったり比較してみる際などにも便利。
したがってCPUバウンドなピュアPythonコードを threading でマルチスレッド化しても速くならない。 subprocess による外部プログラム実行やI/OなどGIL外の処理を待つ場合には有効。
一方 multiprocessing は新しいインタプリタを os.fork() で立ち上げるので、 CPUバウンドなPythonコードもGILに邪魔されず並列処理できる。 ただし通信のため関数や返り値がpicklableでなければならない。
それらの低級ライブラリを使いやすくまとめたのが concurrent.futures (since 3.2) なので、とりあえずこれを使えばよい。
concurrent.futures — 並行処理 in Python
- threadingとどちらを使うか、という点に関しては、concurrent.futuresが使える環境(Python2.7.xなど)であればそちらを、使えない古い環境であればthreadingという選択で良さそう。
threadingのコードサンプル
- startでスレッドを開始して、joinで一通りのスレッドの処理が終わるまで待つという、他のモジュールでよく見かける書き方となる。
- 継承してrunの中に処理を書くか、threading.Threadのコンストラクタのtarget引数で処理の関数を指定したりして使う。
import random
import time
import threading
class SampleThreading(threading.Thread):
def __init__(self, thread_name):
self.thread_name = str(thread_name)
threading.Thread.__init__(self)
def __str__(self):
return self.thread_name
def run(self):
print('Thread: %s started.' % self)
sleep_seconds = random.randint(5, 10)
time.sleep(sleep_seconds)
print('Thread: %s ended.' % self)
thread_list = []
for i in range(4):
thread = SampleThreading(thread_name=i)
thread.start()
thread_list.append(thread)
for thread in thread_list:
thread.join()
Thread: 0 started.
Thread: 1 started.
Thread: 3 started.
Thread: 2 started.
Thread: 1 ended.
Thread: 2 ended.
Thread: 0 ended.
Thread: 3 ended.
- 上記の通り、処理の開始や終了の順番はループを回した順番とは一致しない結果となる。
concurrent.future(並行処理)のコードサンプル
- マルチスレッドの際にはThreadPoolExecutorクラスを指定する。マルチプロセスに切り替えたい場合にはこれをProcessPoolExecutorに変更するだけで切り替えができる。
- max_workersの引数に、最大スレッド数(もしくはプロセス数)を指定する。
- 指定を省略した場合、CPU数から算出されたスレッド数が指定されるらしい。
デフォルトの max_workers=None では 5 * os.cpu_count() になるらしい。
concurrent.futures — 並行処理 in Python
- ファイル操作などと同じように、withステートメントを挟むことで安全にスレッドの停止などがされる。
with 文を使用することで、このメソッドを明示的に呼ばないようにできます。 with 文は Executor をシャットダウンします
公式ドキュメントの concurrent.futures -- 並列タスク実行 より。
- submitで第一引数に処理対象の関数と第二引数以降にその関数に渡す引数を指定する(キーワード引数などで指定することも可能)。
- as_completedがthreadingなどにおけるjoinに該当する。引数にはsubmitで返却された処理対象のリストを指定する。
from concurrent import futures
import time
import random
def sample_func(index):
print('index: %s started.' % index)
sleep_seconds = random.randint(2, 4)
time.sleep(sleep_seconds)
print('index: %s ended.' % index)
future_list = []
with futures.ThreadPoolExecutor(max_workers=4) as executor:
for i in range(20):
future = executor.submit(fn=sample_func, index=i)
future_list.append(future)
_ = futures.as_completed(fs=future_list)
print('completed.')
index: 0 started.
index: 1 started.
index: 2 started.
index: 3 started.
index: 1 ended.
index: 4 started.
index: 2 ended.
index: 5 started.
index: 4 ended.
index: 0 ended.
index: 3 ended.
index: 6 started.
index: 7 started.
index: 8 started.
index: 5 ended.
index: 9 started.
index: 6 ended.
index: 10 started.
index: 7 ended.
index: 11 started.
index: 8 ended.
index: 12 started.
index: 9 ended.
index: 13 started.
index: 10 ended.
index: 14 started.
index: 12 ended.
index: 15 started.
index: 13 ended.
index: 16 started.
index: 11 ended.
index: 17 started.
index: 15 ended.
index: 18 started.
index: 14 ended.
index: 19 started.
index: 16 ended.
index: 17 ended.
index: 19 ended.
index: 18 ended.
completed.
- サンプルでmax_workers=4を指定しているので、最初に4つ動き始めていることが分かる。
- それ以降は、スレッドのどれかが終わった直後に次のスレッドが開始していることが分かる。
並列処理
- マルチプロセス。
- 複数のコアで計算を行う。
- 並行処理がGILによって高速化面で制限がある一方で、こちらは基本的に制限がかからないので高速化が期待できる。
- ただし、メモリをダイレクトに共有することができない。そのままだとプロセス間で変数などをやりとりする際にはpickle化されてコピーが生成され受け渡しがされる。つまり、大きなデータを渡したりするとメモリを瞬間的に膨大に消費したり、pickle化などのオーバーヘッドで期待したほど速くならないケースもある。
- これを改善するためには、ビルトインの共有メモリ(shared memory)の機能を使ったり、共有メモリ用のライブラリなどを利用する。同時に更新したりしないように注意は必要になるものの、pickle化を省けるので処理時間が短くなり省メモリで扱える。
- プロセス生成などにある程度オーバーヘッドがあるので、一瞬で終わるようなタスクに対してプロセスを分けたりすると逆に遅くなるケースがある。
- モジュールは基本的にmultiprocessingもしくはconcurrent.futuresを利用する。
- multiprocessingにはさらにProcessやPoolといったように複数の選択肢がある。
multiprocessingのProcessとPoolのどちらを使うべきか
ProcessとPoolで、それぞれ以下のような特徴がある。
- Processのほうが生成コストが低い
- Processのほうは並列化して実行する関数ごとにオブジェクトが生成される。そのため、呼び出す関数の数が膨大だとその生成コストが高くなったりメモリを食ったりする。
- 一方で、Poolのほうは基本的には引数でコア数などでworker数を指定して、各worker数ごとにタスクの処理が開始し、1つの処理が終わったらキューにある次のタスクの処理を開始する。そのため、呼び出す関数が膨大でもProcessのように膨大にオブジェクトが作られたりはしない。
上記を踏まえ、以下のような判断ができる。
- 呼び出す関数の数が膨大で、1つ1つのタスクがライトな場合 -> Processで大量にオブジェクトを生成するのはコストが高いのでPoolを使う。
- 呼び出す関数は少ないけど、1つ1つの関数の処理時間が長い場合 -> 単体の生成コストが低いProcessを使う
※そもそも、一度に大量にProcessオブジェクトを走らせ始めるとエラーで怒られる。そういった制限も含め、呼び出す関数の数が多くなる場合にはPoolのほうが制御がシンプルになりそう。
...
---> 66 parent_r, child_w = os.pipe()
67 self.pid = os.fork()
68 if self.pid == 0:
OSError: [Errno 24] Too many open files
また、他にもPool側が「前のタスクが終わるまで次のタスクに移らない」という挙動なため、IO関係の操作(ファイル操作など)で重いものがあるとProcessのほうが有利な場合があるらしい。
たとえば、Processで20個同時にファイルを開いたりして操作ができたりする一方で、Poolでworkerの数を4にした場合には4個までしか同時には開かれない。
そのため、IO関係での待ち時間が結構ある場合にはProcessを使ったほうが速くなるケースがある・・らしい。
参考 : Python Multiprocessing: Pool vs Process – Comparative Analysis
並列処理のコードサンプル
multiprocessing.Processのサンプルと速度確認
- 基本的にProcessのコンストラクタのtarget引数で対象の関数を指定し、startで処理を開始、joinで各プロセスが終わるのを待つ形となる。
- コンストラクタのargsにリスト、もしくはkwargsにキーワード引数としての辞書を指定することで、対象の関数に引数を渡すこともできる。
単純な、1000万回ループを回してインクリメントするだけのサンプル :
def sample_func(process_index):
print('process index: %s started.' % process_index)
num = 0
for i in range(10000000):
num += 1
print('process index: %s ended.' % process_index)
普通に並列化せずにループを回すと約4秒かかった。
%%timeit
for i in range(10):
sample_func(process_index=0)
1 loop, best of 3: 4.21 s per loop
続いて、並列化するサンプル。
from multiprocessing import Process
%%timeit
process_list = []
for i in range(10):
process = Process(
target=sample_func,
kwargs={'process_index': i})
process.start()
process_list.append(process)
for process in process_list:
process.join()
...
process index: 9 ended.
process index: 7 ended.
process index: 0 ended.
1 loop, best of 3: 1.23 s per loop
ぼちぼち速くなった。
返却値が必要な場合には、Managerクラスを使って、プロセス間で共有される変数を使って、そちらに設定する必要がある。このあたりはPoolの方がシンプルで直感的に感じる。
辞書の共有される変数を使用して結果をメインのプロセスで参照するサンプルは以下のようになる。
from multiprocessing import Manager
def sample_func(initial_num, returned_dict, process_index):
for i in range(100):
initial_num += 1
returned_dict[process_index] = initial_num
manager = Manager()
returned_dict = manager.dict()
process_list = []
for i in range(4):
process = Process(
target=sample_func,
kwargs={
'initial_num': 50,
'returned_dict': returned_dict,
'process_index': i,
})
process.start()
process.join()
大体通常の辞書の感覚で使えるものの、型は特殊なクラスになっている。
type(returned_dict)
multiprocessing.managers.DictProxy
メインのプロセス内でprintで出力してみると、正常に別プロセスの結果が設定されていることが分かる。
print(str(returned_dict))
{0: 150, 1: 150, 2: 150, 3: 150}
multiprocessing.Poolのサンプルと速度確認
- Poolのコンストラクタで、最大のプロセス数を指定する。使う環境のCPUのコア数などに応じて設定する。
- concurrent.futuresと同じように、withステートメントで扱うとシンプルに利用できる。
- 処理の指定にはmap、map_async、starmap、starmap_asyncといった複数のメソッドが存在する。それぞれ、以下のように使い分ける。
- 単体の関数を何度も実行するケースで、且つその関数が1つの引数のみを受け取る場合 -> map
- 複数の関数を何度も実行するケースで、且つその関数が1つの引数のみを受け取るケース -> map_async
- 単体の関数を何度も実行するケースで、且つその関数が複数の引数を必要とする場合 -> starmap
- 複数の関数を何度も実行するケースで、且つその関数が複数の引数を必要とする場合 -> starmap_async
※starmap関係はPython3.3以降で導入された。それ以前のバージョンではmapを使う必要がある。
※starmapのstarは、おそらく*args的な、複数の引数展開がされるmap、という名前の由来なのかな、という印象。
参考 :
-
mapメソッドなどに渡す引数のための配列の件数に応じて、対象の関数が呼ばれる。たとえば、その関数を100回呼ぶ必要があるケースでは、リストの件数を100にする必要がある。
Processのサンプルと比べて、呼び出し回数が多く1回の関数の処理がライトなケースを想定してサンプルを試してみる。
from multiprocessing import Pool
def sample_func(initial_num):
for i in range(100):
initial_num += 1
まずはPoolを使わないケースで100万回関数を呼び出す形で試してみる。
%%timeit
for i in range(1000000):
sample_func(initial_num=i)
1 loop, best of 3: 3.48 s per loop
続いて、100件のリストを用意して、Poolを使って処理してみる。
%%timeit
initial_num_list = list(range(1000000))
with Pool(processes=4) as p:
p.map(func=sample_func, iterable=initial_num_list)
1 loop, best of 3: 1.14 s per loop
Processのときのサンプルと似たような感覚で、こちらも速くなった。
なお、関数側に返却値が設定されている場合には、map関数での返却値にリストが渡されるので返却値が必要な場合にはそちらを利用する。
返却値のリストの件数と順番は、map関数に指定した配列の件数と順番そのままに設定される(10件のリストを設定すれば返却値も10件のリストとなる)。
def sample_func(initial_num):
for i in range(100):
initial_num += 1
return initial_num
initial_num_list = list(range(10))
with Pool(processes=4) as p:
result_list = p.map(func=sample_func, iterable=initial_num_list)
print(result)
[100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
Processのときよりも、返却値周りは直感的でシンプルに感じる。
続いてmap_asyncのサンプル。以降では、引数や処理順の確認のためにprint文を挟むため、timeitの計測は省き、関数呼び出し回数も少なめで扱う(printの出力が膨大になってしまうため)。
def sample_func_1(initial_num):
print('sample_func_1', ', initial_num:', initial_num, 'started.')
for i in range(10000):
initial_num += 1
print('sample_func_1 ended.')
return initial_num
def sample_func_2(initial_num):
print('sample_func_2', ', initial_num:', initial_num, 'started.')
for i in range(10000):
initial_num += 1
print('sample_func_2 ended.')
return initial_num
initial_num_list = list(range(5))
with Pool(processes=4) as p:
map_result_1 = p.map_async(
func=sample_func_1, iterable=initial_num_list)
map_result_2 = p.map_async(
func=sample_func_2, iterable=initial_num_list)
result_list_1 = map_result_1.get()
result_list_2 = map_result_2.get()
※どうやら、getメソッドを呼ばないと関数の内容が実行されない模様。返却値が不要なケースでも、呼ばないとprintの内容が出力されなかった。
sample_func_1 , initial_num: 1 started.
sample_func_1 , initial_num: 3 started.
sample_func_1 , initial_num: 0 started.
sample_func_1 , initial_num: 2 started.
sample_func_1 ended.
sample_func_1 ended.
sample_func_1 , initial_num: 4 started.
sample_func_1 ended.
sample_func_1 ended.
sample_func_2 , initial_num: 0 started.
sample_func_2 , initial_num: 1 started.
sample_func_2 , initial_num: 2 started.
sample_func_2 ended.
sample_func_1 ended.
...
1つ目の関数と2つ目の関数で、入り乱れる形で実行されていることが分かる。
concurrent.futuresでの並列処理のサンプル
並行処理のconcurrent.futuresのサンプルのThreadPoolExecutorの箇所をProcessPoolExecutorに変えるだけなので割愛。
multiprocessingのPoolとconcurrent.futuresのどちらを使うべきかという点に関しては、基本はconcurrent.futuresの方が使えるPythonのバージョンであればそちらでいいような気はしている。ただし、multiprocessing側も大分使いやすいインターフェイスであり、正直困らないのでどちらでもいいような気はしている。
CPUのコア数を取得する
マルチプロセスであればPoolのprocesses引数 やconccurent.futures、マルチスレッドでもconccurent.futuresのmax_workersなど、コアの数に依存する指定が必要になるケースがある。
マルチプロセスであればコア数が指定されることが各ライブラリで多いような印象があるのと、マルチスレッドのconcurrent.futuresであれば、指定しなかった場合には前述の通りコア数 * 5のスレッド数が設定される。
そのため、ノートなどでマルチプロセスなどのコードを書く際には、ハードコーディングでprocessesなどの数を指定するよりも、将来PCが変わった際や他の方にノートを共有したりした際に環境に応じて変動したほうが好ましい。
その指定のための、現在の環境のCPU数はosモジュールのcpu_count関数で取得することができる。環境に応じて4や8といった値が表示される。
import os
os.cpu_count()
8
共有メモリ
- マルチプロセスではそのままでは別のプロセス上の変数などが参照できない。
- そのため、他のプロセスに大きなデータを渡したり、戻したりする際に、pickleなどのフォーマットでコピーされて別のプロセスのメモリに渡されたりしている。大きい変数などだと、メモリを大きく使ったりコピー時にCPU負荷がかかったりしてしまう。
- また、ビルトインのものだとNumPyなどのオブジェクトをそのままやりとりしたりが難しいケースがある(単純なスカラー値やシンプルな配列などは問題ない一方で、NumPyなどの配列をやりとりしたい場合にはManager.dictでの返却値設定やPoolの引数設定をしても、エラーで怒られる)。
- そういったメモリやコピー時の負荷を避けるためには、メモリをまたいで共有される特殊な型の変数を使ったりする必要がある。
- multiprocessingのビルトイン内だったり、NumPyの機能だったり、さらにはサードパーティのライブラリなどいくつも選択肢がある。
以下でメモリなどを確認しつつ、色々試してみる。
※メモリの確認には、以前遊びで作ったプロットライブラリを利用。
まずはマルチプロセスなどを使わずに、メインのプロセスで大きなリストを作って、別の関数に渡してリストを返却する処理を考える。別のプロセスにコピーしたりはしないので、最初のリスト生成のタイミングだけ使用メモリが増えていることが分かる。
(※NumPy配列だとこの書き方だと怒られるので、このサンプルではリストに変換して扱っている)
from multiprocessing import Pool
import time
import numpy as np
def sample_func(big_list):
for i, value in enumerate(big_list):
big_list[i] *= 2
return big_list
big_list = np.random.randint(
low=0, high=100, size=(100000000,)).tolist()
big_list[:5]
[34, 70, 38, 31, 40]
big_list = sample_func(big_list=big_list)
big_list[:5]
[68, 140, 76, 62, 80]
関数自体はリスト内の値を2倍するだけ。

続いて、一度Jupyterのノートのカーネルを再起動してメモリを開放した後に、今度はPoolを使って別のプロセスで試してみる。
with Pool(processes=1) as p:
result_list = p.map(func=sample_func, iterable=[big_list])
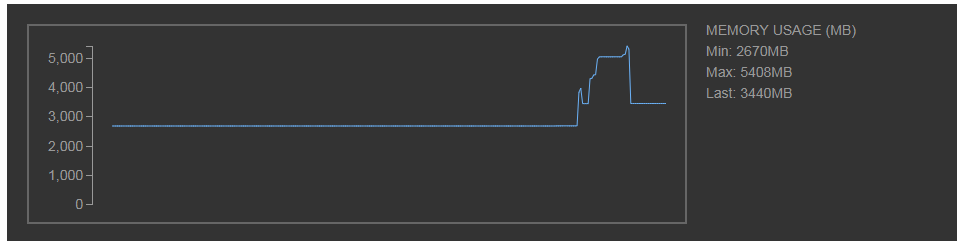
先ほどの別のプロセスを使わないケースに比べて、リスト生成時・別のプロセスへの値のコピー・返却時のコピー時の都合で瞬間的な最大メモリ使用量が大分多くなっていることが分かる。
その後は、使い終わったプロセスが終了してメモリが開放されるので、最終的にはマルチプロセスを使わないケースと同じくらいのメモリ使用量に落ち着いている。
最終的なメモリ使用量は同じくらいにはなるものの、瞬間的に最大メモリ使用量が跳ねるのは好ましくない(瞬間的にメモリが足りなくなったり等)。
また、速度に関しても測ってみる。
まずは別のプロセスを使わないケースを試してみる。
%%timeit
sample_func(big_list=big_list)
1 loop, best of 3: 8.05 s per loop
続いて別のプロセスを使用するケース。
%%timeit
with Pool(processes=1) as p:
p.map(func=sample_func, iterable=[big_list])
1 loop, best of 3: 18.1 s per loop
コピーなどがされる都合、大分遅くなった。
今回は別の1つのプロセスしか使っていないものの、実際には4や8といったプロセスを使うと思うので、これでもまだ早くなるケースはある。(それぞれのプロセスに大きな変数をコピーさせるケースではなく、それぞれのプロセスのために変数を小さくするケースなど)
とはいえ、これでは想定していたよりもあまり速くならない結果になるケースもあり、さらに言えばコピーするデータのサイズによっては逆に遅くなったりメモリ面が問題になったりするケースがあるかもしれない。
multiprocessingのValueとArray
まずはビルトインのmultiprocessingのValueとArrayによる、共有メモリによる機能を使ってみる。
- Valueは単一の値の変数を共有メモリ上で扱うためのクラス。
- Arrayは配列を共有メモリ上で扱うためのクラス。
まずはValueの方から見ていってみる。
コンストラクタの引数では、typecode_or_typeに型の指定が必要になる。ctypesモジュール内の定義か、もしくはiやdといった文字列を指定する必要がある。
ctypes内の各型の定義は公式ドキュメントに色々書いてある。
ctypes --- Pythonのための外部関数ライブラリ

from multiprocessing import Value, Pool
import ctypes
shared_value = Value(typecode_or_type=ctypes.c_int64)
shared_value
<Synchronized wrapper for c_long(0)>
そのまま出力すると、上記のように表示される模様。(0)の部分で値が表示されるようで、今回はint型を指定したので初期値は0になっている。
値の更新はvalue属性に値を指定する必要がある。直接イコールで指定するとそのままint型などになってしまう。(当たり前な点ではあるものの、稀にうっかりミスしそうではある)
shared_value.value = 10
shared_value
<Synchronized wrapper for c_long(10)>
Poolで値の更新をしてみる。共有されるオブジェクトとなるので、引数で渡したり返却値に指定したりは不要。
def sample_func(x):
shared_value.value += 1
with Pool(processes=1) as p:
p.map(func=sample_func, iterable=[0])
shared_value
<Synchronized wrapper for c_long(11)>
正常に、mapで呼び出した関数内での更新がメインのプロセスで参照しても更新されていることが分かる。
続いてArrayに関して試してみる。
引数にValueのときと同様に型を指定するtypecode_or_typeの引数と、配列の長さもしくは初期値として指定するsize_or_initializerの引数がある。
size_or_initializerのほうは、整数のスカラー値で指定した場合には配列の長さとなり(初期値はintであれば0となる)、タプルなどを指定するとそれが初期値になる。
sizeの挙動がNumPyなどとは異なるので注意。たとえば、(3, 5)と指定すると3行5列の行列にはならず、[3, 5]という値を格納した2件の配列となる。
size_or_initializer が整数なら、配列の長さを決定し、その配列はゼロで初期化されます。別の使用方法として size_or_initializer は配列の初期化に使用されるシーケンスになり、そのシーケンス長が配列の長さを決定します。
公式ドキュメント : multiprocessing --- プロセスベースの "並列処理" インタフェースより
よって、ベクトル的に扱うのが基本となる。入れ子にしたりすれば行列的な扱いもできるかもしれないけれども、それなら後述するNumPyだったりサードパーティの共有メモリライブラリなどを使ったほうが楽で直感的な印象がある。
from multiprocessing import Array
shared_array = Array(
typecode_or_type=ctypes.c_int64,
size_or_initializer=(3, 5))
shared_array
<SynchronizedArray wrapper for <multiprocessing.sharedctypes.c_long_Array_2 object at 0x7fd2414fb1e0>>
c_long_Array_2 の末尾の数字は、どうやら配列の件数によって設定される模様。2件の配列の初期値を与えたので2となっている。
len(shared_array)
2
shared_array[0]
3
上記のように、NumPyのsizeやshapeといった引数と異なり、3 x 5の行列になったりはしない。
size_or_initializerの引数にスカラー値を指定した場合はその件数の配列となる。
shared_array = Array(
typecode_or_type=ctypes.c_int64,
size_or_initializer=5)
len(shared_array)
5
shared_array[0]
0
大きな配列を作って、Poolで値の更新をした際のメモリが配列初期化時以外変動しないこと(別のプロセス使用時にコピーなどがされていないこと)を確認してみる。
import random
from multiprocessing import Pool, Array
import ctypes
shared_array = Array(
typecode_or_type=ctypes.c_int64,
size_or_initializer=20000000)
def sample_func(x):
shared_array[100] = 100
shared_array[200] = 100
shared_array[300] = 100
with Pool(processes=1) as p:
p.map(func=sample_func, iterable=[0])
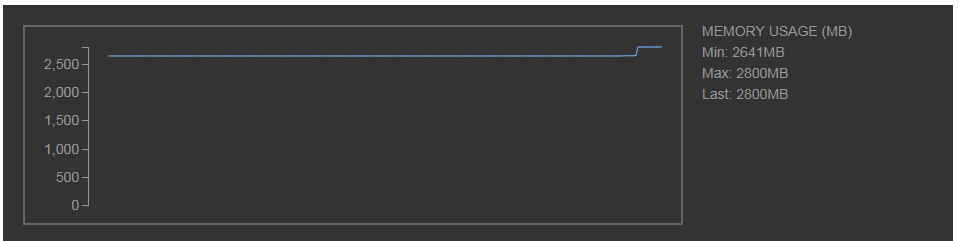
メインのプロセスでの大きな配列生成時以外はメモリがほぼ変動していないので、他のプロセスでの操作でデータがコピーがされていないことが分かる。
今回はサンプルなので別のプロセスは1つだけで対応したものの、実際の用途で、インデックス範囲で、2つ目のプロセスはここからここまでの範囲の値を更新、3つ目のプロセスはここからここまでの範囲の値を更新(もしくはデータを分散して読み込んで反映)・・といったような使い方は必要になったりするかもしれない(同じ範囲を更新するとロックなど面倒なことになるので、被らないようにしつつ)。
また、コピーが走らないので、コピーで何秒もかかってしまうことを考えると大分処理は早くなる(Pool自体である程度オーバーヘッドはあるものの)。
timeitのマジックコマンドで前述のmapの箇所を実行すると以下のようになった。
10 loops, best of 3: 110 ms per loop
参考 : Pythonでプロセス間の値の共有
NumPyやPandasでの共有メモリ
前述までのビルトインの共有メモリの書き方で、NumPy配列などを渡そうとするとエラーで怒られる(Managerのdictなど)。
一方で、実務だと生のベクトル的なlist形式のデータ以外にも、行列やそれ以上のサイズのテンソルなどをNumPyやPandasなどで扱うケースがかなり多い。
それらのオブジェクトを扱う際にはどうすればいいのか。
いくつかやり方はある模様。
- 【1】 ビルトインの機能を使う
ベクトルの形式であれば、frombufferなどのNumPyの関数と、multiprocessingのget_objなどを組み合わせてやりとりができる模様。ベクトルではないケースでも、場合によってはflattenさせてあとでreshapeさせることで使えるかもしれない(ただ、結構コードが煩雑になったりが気になる)。
参考: Use numpy array in shared memory for multiprocessing
- 【2】サードパーティーのライブラリを使う
「NumPy shared memory pypi」などとググるといくつか選択肢が出てくる。実務でも一部触ってみたこともある。

ただし、各ライブラリであまりGithubでスターが付いておらず(数件~20件未満など)あまりシェアを得ている感じでもないのと、READMEにdeprecatedと書かれているライブラリも目に付く。
長期的に見ると更新が止まりそうで少し怖い感じがある。
- 【3】Blazeエコシステムを使う
いわゆるDaskとかも含めた、Blazeのエコシステムを使う案。
参考: The Blaze Ecosystem
Blazeのリポジトリもスターがこの記事を書いている時点で2600件を超えているし、Daskのリポジトリの方はスター4800くらいになっており人気が伺える。
その分contributorの方も多く、アップデートの面で無難な印象はある。
(また、【2】のサードパーティーに関してはBlazeがあるので更新をとめた的な記述をREADMEにしているライブラリもあった)
Daskなどに触れだすとかなり長くなるのとキャッチアップも足りていないのでここでは割愛。ちゃんと勉強して、機会があれば別の記事で触れます。
asyncioとかは?
Node.jsとかを触っている方には馴染みのある、ノンブロッキングなどの面の話で、並列処理に近いもので非同期処理のasyncioなどの機能もPython3.4とかで追加されたり、3.7とかでも大きくアップデートされたりと、比較的新しい機能として存在する。(concurrent.futuresも非同期処理に絡んできたりもする)
そちらも奥が深いのでまとめると大分長くなるので、機会があれば別の記事でまとめます。
他にもPythonなどを中心に色々記事を書いています。そちらもどうぞ!
今までに投稿した主な記事たち
参考文献まとめ
- Advanced Python Programming: Build high performance, concurrent, and multi-threaded apps with Python using proven design patterns
- Pythonの並列・並行処理サンプルコードまとめ
- concurrent.futures — 並行処理 in Python
- Jupyter notebook never finishes processing using multiprocessing (Python 3)
- concurrent.futures -- 並列タスク実行
- Future パターン
- Jupyter notebook never finishes processing using multiprocessing (Python 3)
- Python Multiprocessing: Pool vs Process – Comparative Analysis
- starmapでPythonでの並列処理の結果をリストで受け取る
- Mulitprocess Pools with different functions
- How can I recover the return value of a function passed to multiprocessing.Process?
- Pythonでプロセス間の値の共有
- ctypes --- Pythonのための外部関数ライブラリ
- multiprocessing --- プロセスベースの "並列処理" インタフェース
- MultiprocessingとMultithreading?
- Use numpy array in shared memory for multiprocessing
- The Blaze Ecosystem