著者: 伊藤 雅博, 株式会社日立製作所
はじめに
本稿ではApache Kafkaを構成するコンポーネントの1つである、Kafka Streamsの概要とユースケースを紹介します。Kafka Streamsのより詳細なアーキテクチャや具体的な構築手順については、次回以降の記事で紹介します。
記事一覧:
- Kafka_Streamsの概要とユースケース(本稿)
- Kafka Streamsのアーキテクチャとチューニングポイント
- Kafkaクラスタを構築してKafka Streamsを試す(Podmanコンテナ環境編)
Kafka Streamsの位置づけ
Apache Kafkaは以下のようなコンポーネントで構成されています。メッセージキューを構成するKafka Brokerを中心に、メッセージを格納・参照するクライアントとなるコンポーネント群があります。本稿ではKafkaのコンポーネントの1つであるKafka Streamsについて解説します。
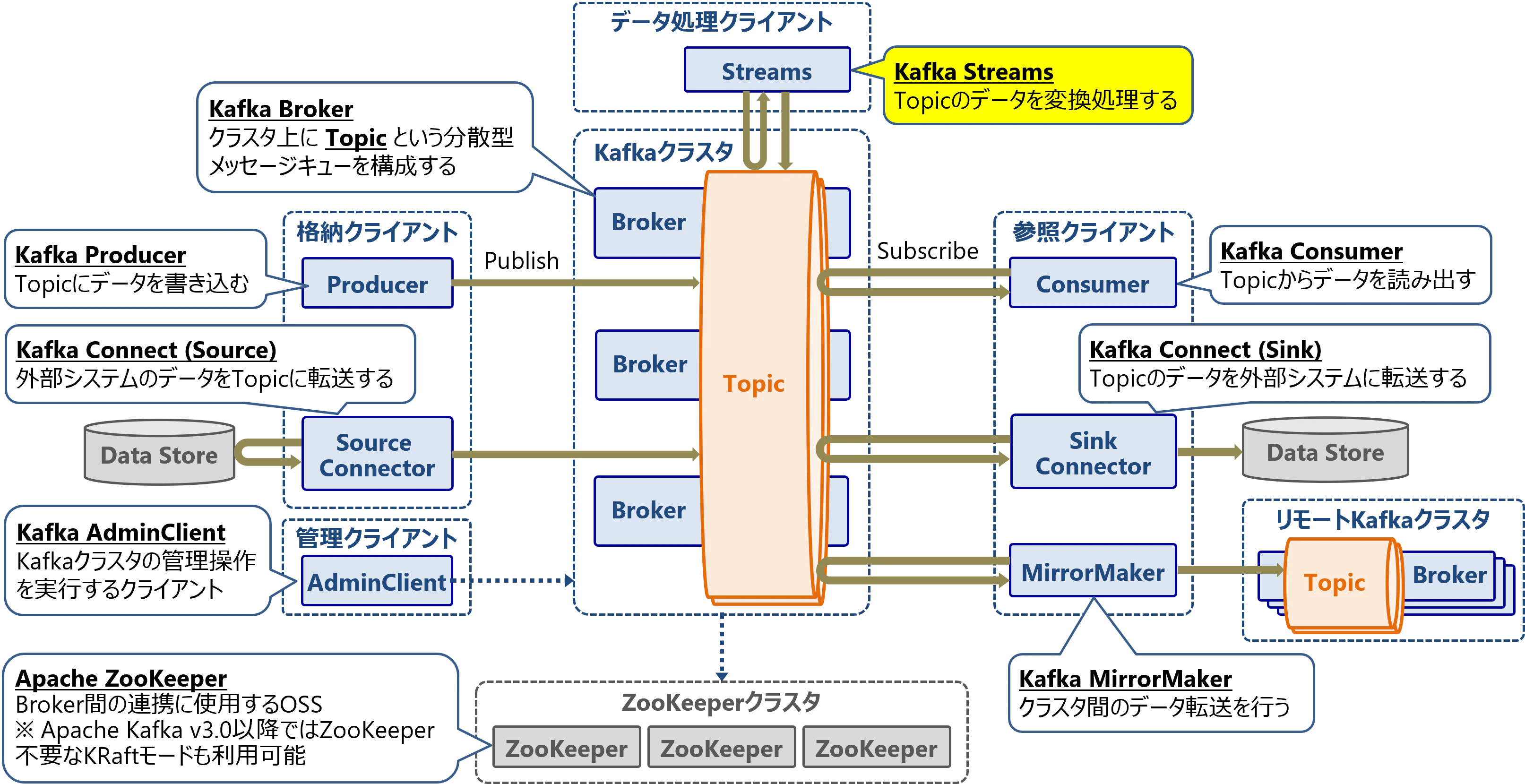
なお、Apache Kafkaの概要については以下をご参照ください。
Kafka Streamsの概要
Kafka Streamsは、KafkaのTopicに格納されたメッセージをストリーム処理するためのフレームワークです。Topicからメッセージをリアルタイムに読み出して、任意の変換処理を行い、別のTopicに書き戻すようなストリーム処理アプリケーション(Streamアプリケーション)を作成できます。Kafka Streamsは、JavaまたはScala言語で利用できるライブラリとして提供されます。
なお、Kafkaのメッセージはキーバリュー形式であり、レコードとも呼びます。キーとバリューは共に任意のテキストまたはバイナリデータを格納できます。キーは空でも問題ありません。レコードのサイズは、Brokerのデフォルト設定だと最大1MBとなります。
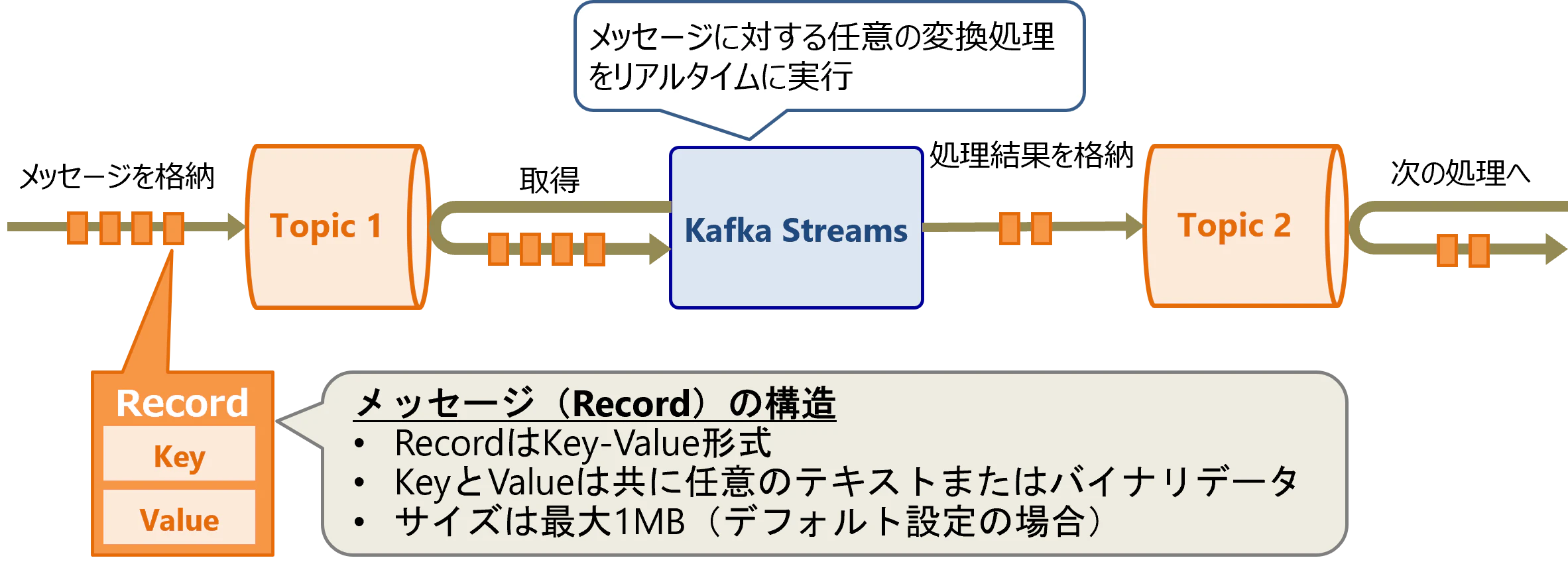
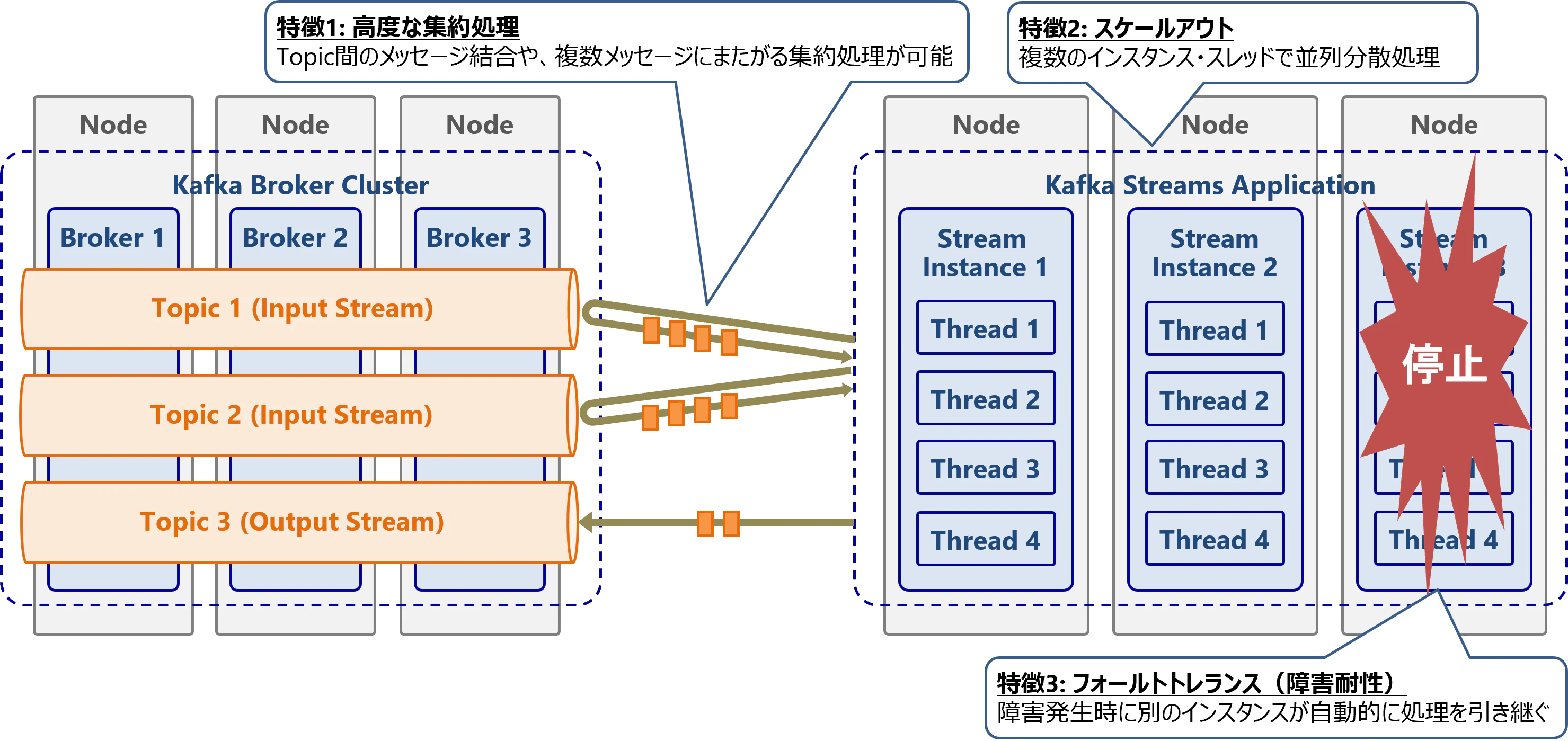
Kafka Streamsには以下の特徴があります。
-
高度な集約処理
メッセージ単位の変換処理だけでなく、複数メッセージにまたがる集約や結合、ウィンドウ処理などが可能 -
スケールアウト
複数インスタンス(サーバ)、複数スレッドで並列分散処理が可能 -
フォールトトレランス(障害耐性)
処理中にサーバ障害が発生しても、自動的に別のサーバにあるインスタンスが処理を引継ぎ
Kafka Streamsのユースケース
ストリーム処理/イベント駆動型アプリケーションの構築
Kafka Streamsを活用することで、大量発生するデータをリアルタイムに処理するアプリケーションを構築できます。例えば以下の図ような、コネクテッドカーのセンサーデータを変換または抽出するようなアプリケーションを構築できます。

扱うデータ量が増加した場合は、Kafka BrokerとKafka Streamsのサーバ台数を増やすことで、処理性能をスケールアウトすることが可能です。
マイクロサービスの構築
マイクロサービス間のデータ連携を行うメッセージブローカーにKafka Brokerを利用すると、各サービスの処理をKafka Streamsで実装できます。例えば以下の図ような、マイクロサービス化された注文処理システムを構築できます。
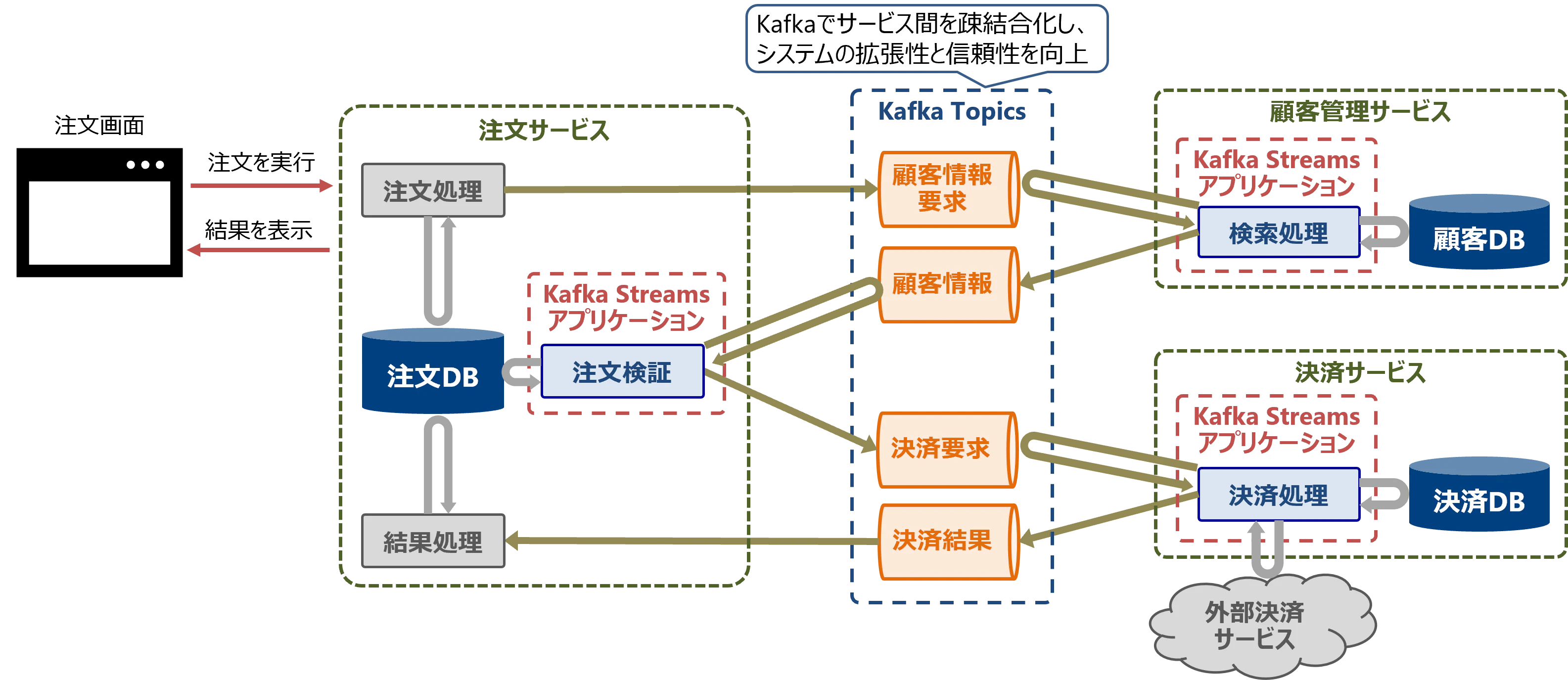
Kafkaを介してサービス間の通信を非同期化することで、以下のようなメリットがあります。
- サービス間の通信経路をKafkaに集約することで、サービスの追加や削除が容易になり、システムの拡張性が向上
- キューイングによりデータ流量を平準化し、受信側サービスの負荷増大を抑制
- 一部サービスの稼働停止による連鎖障害を回避し、信頼性とメンテナンス性を向上
なお、複数のサービスにまたがる分散トランザクションが必要となる場合は、Sagaパターンなどで実装する必要があります。
Kafka Streamsのデータ処理モデル
Processor Topologyとは
Streamアプリケーションの処理ロジックは、Processor Topologyというグラフ構造で定義します。Processor Topologyのグラフ構造は、以下の抽象化した要素で構成されます。
- Stream Processor
- データの変換処理を示すノード
- Stream
- データ(メッセージの集合)を示すエッジ
- State Store
- 過去のメッセージに含まれる情報(状態)を保持するデータストア
単純なProcessor Topologyの例を以下に示します。

入力元のTopicはInput Stream、出力先のTopicはOutput Streamと呼びます。
Processor Topologyは処理内容によっては複雑なグラフ構造になります。Processor Topologyの概念について、より詳しく知りたい場合は以下をご参照ください。
Processor Topologyの定義方法
Processor Topologyは、JavaまたはScala言語で以下のいずれかのAPIを使用して定義します。
-
Kafka Streams DSL (Domain Specific Language)
- 一般的なデータ変換操作(map、filter、join、aggregateなど)や、複数のメッセージにまたがるウィンドウ処理などを提供する高レベルAPI
- 各データ変換操作は適切なStream Processorの集合に変換して実行される
-
Processor API
- 独自の処理をStream Processorとして実装できる低レベルAPI
基本的には、Kafka Streams DSLで処理を定義することを推奨します。もしDSLで実現できない変換処理が必要な場合は、Processor APIで処理を実装します。Processor APIでは任意の処理を実装できるため、例えばメッセージの処理中に外部のサービスと通信したり、処理結果をTopicではなく外部のデータベースに書き込むことも可能です。
なお、Kafka Streams DSLの各データ変換操作は、Stream Processorと1:1で対応するとは限りません。DSLは抽象的なデータ操作を示していますが、Processor Topologyは実際の処理構造を示しています。そのため、DSLの1つのデータ変換操作が複数のStream Processorに変換されることもあります。
Kafka Streams DSLによる定義方法は後ほど説明しますが、より詳しく知りたい場合は以下をご参照ください。
Kafka Streamsのサンプルアプリケーション
Streamアプリケーションのサンプルを例に処理を解説します。
- 例1: LineSplit(単語分割)
- メッセージの文字列(英文)をスペースで単語に分割する処理
- メッセージ単位で処理が完全に独立している、Statelessな処理
- Kafka Streams DSLで記述
- 例2: WordCount(単語の出現回数カウント)
- メッセージの文字列(英文)に含まれる、各単語の出現回数をカウントする処理
- 過去のメッセージに含まれていた単語の出現回数を保持して利用する、Statefulな処理
- Kafka Streams DSLで記述
これらのサンプルについて、より詳しく知りたい場合は以下もご参照ください。
LineSplit(単語分割)
LineSplitはメッセージの文字列(英文)をスペースで単語に分割する処理です。以下のように、入力メッセージの文字列が単語毎のメッセージとして出力されます。
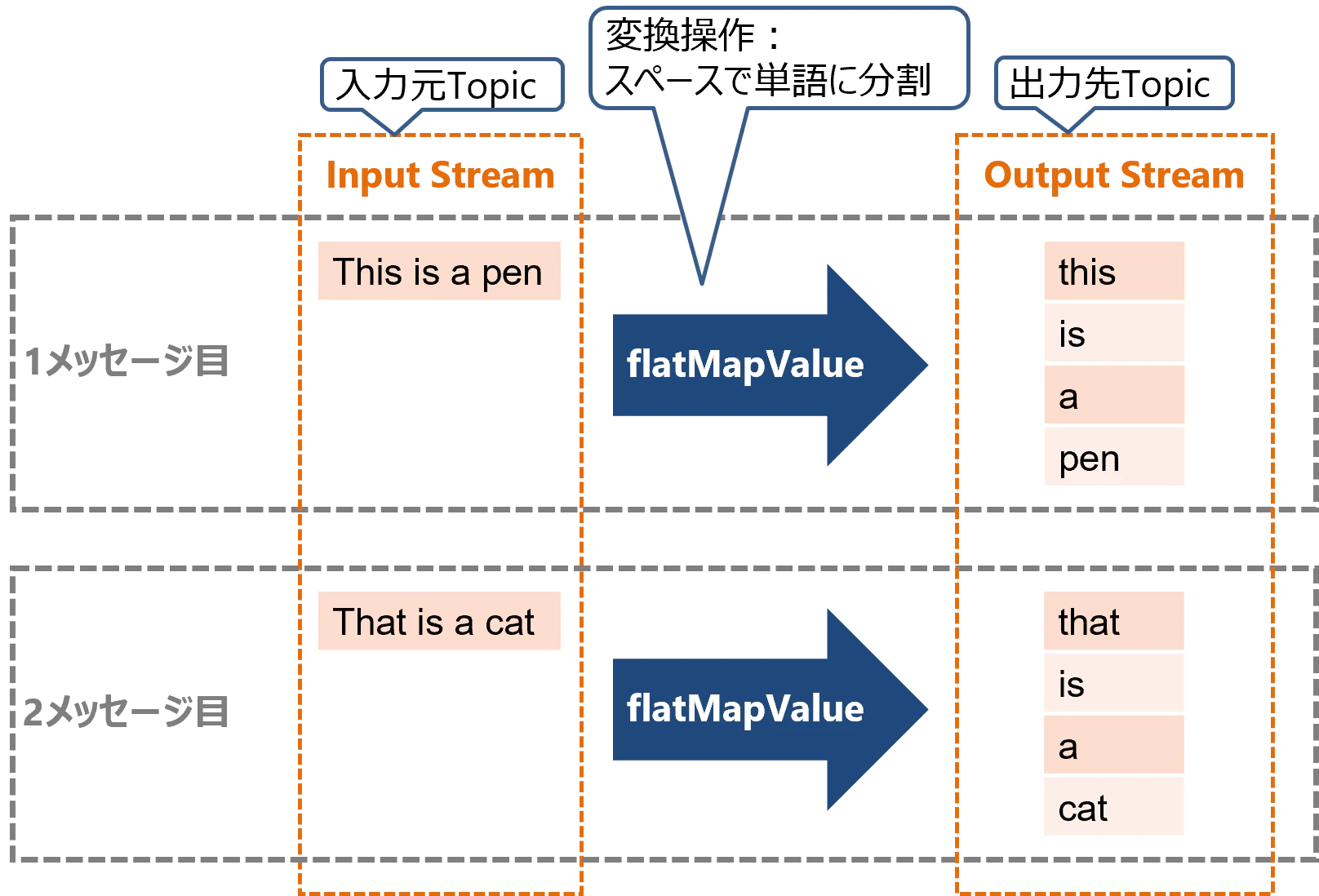
この処理は過去のメッセージに含まれる情報(状態)を保持する必要がなく、各メッセージの処理は他のメッセージの処理から完全に独立しています。そのため状態を持たないStatelessな処理に分類されます。
Kafka Streamsライブラリを使用したソースコードの例を以下に示します。
LineSplit.java:
// 設定
final Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit"); // アプリケーションID
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // 初期接続先Broker
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// Kafka Streams DSLで処理ロジックを定義する
final StreamsBuilder builder = new StreamsBuilder();
// 入力元Topicのメッセージ(文字列)を、スペースで単語分割して、出力先Topicに転送
builder.<String, String>stream(“streams-plaintext-input”) // 入力元Topic
.flatMapValues(value -> Arrays.asList(value.split(“\\W+”))) // 文字列をスペースで分割
.to(“streams-linesplit-output”); // 出力先Topic
// 処理ロジックをProcessor Topologyに変換
final Topology topology = builder.build();
// Streamアプリケーションを実行開始
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
例2: WordCount(単語の出現回数カウント)
WordCountはメッセージの英文に含まれる各単語の出現回数を数える処理です。以下のように、入力メッセージの文字列の単語に分割して、これまでの各単語の出現回数を出力します。

この処理は過去のメッセージに含まれていた単語の出現回数をTableとして保持します。そのため、状態を保持するStatefulな処理に分類されます。
※ 上記の図の変換操作はProcessorと必ずしも1:1対応するわけではありません。groupBy操作は、selectKeyとfilterという2つのProcessorで処理されます。またcount操作は、aggregateというProcessorで処理されます。
以下にソースコードの例を示します。
WordCount.java:
// 設定
final Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount"); // アプリケーションID
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // 初期接続先Broker
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// Kafka Streams DSLで処理ロジックを定義する
final StreamsBuilder builder = new StreamsBuilder();
// 入力元Topicのメッセージ(文字列)を、スペースで単語分割して、単語の出現回数をカウントして出力先Topicに転送
builder.<String, String>stream(“streams-plaintext-input”) //入力元Topic
// 小文字化してスペースで分割
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
// 単語でグループ化
.groupBy((key, value) -> value)
// 各単語の個数をカウントして、StateStoreのデータテーブル(KTable)に実体化
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(“counts-store”))
// StateStoreのテーブル(KTable)から、ストリーム(KStream)に戻す
.toStream()
// 出力先Topicに(単語, 出現回数)のペアを書込み
.to(“streams-wordcount-output”, Produced.with(Serdes.String(), Serdes.Long()));
// 処理ロジックをProcessor Topologyに変換
final Topology topology = builder.build();
// Streamアプリケーションを実行開始
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
他のストリーム処理フレームワークとの違い
Kafka Streamsのようなストリーム処理フレームワークは他にもいくつか存在します。
Kafkaに格納されたメッセージのストリーム処理に対応しているフレームワークもいくつか存在し、代表的なフレームワークとしてはSparkとFlinkが挙げられます。ここではKafka StreamsとSpark/Flinkの違いを説明します。
高度なデータ変換処理
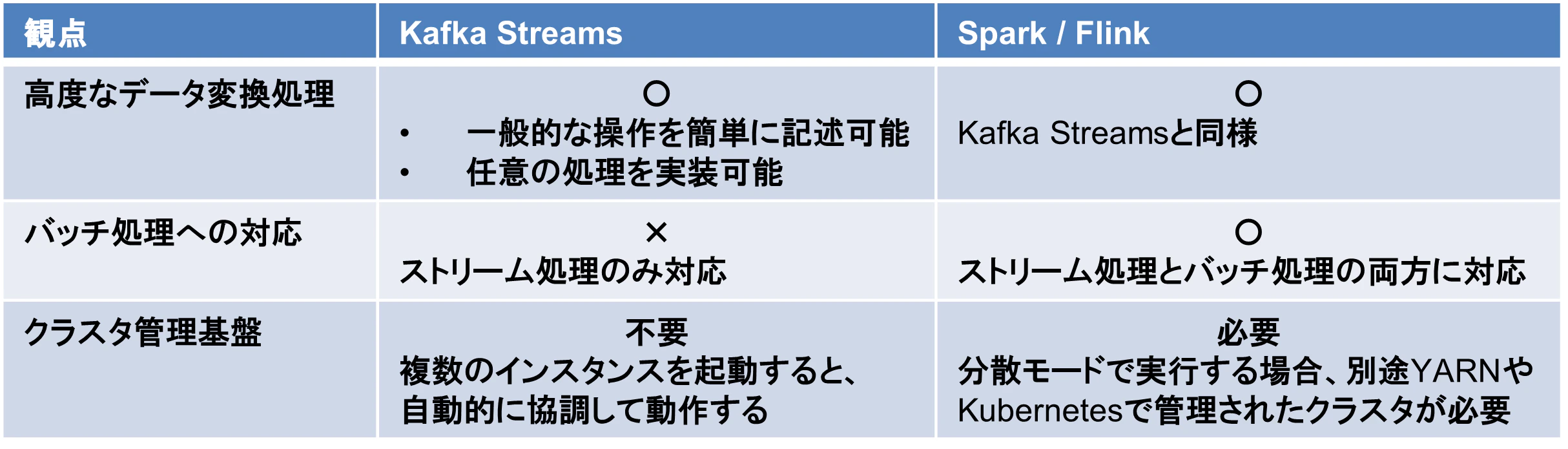
いずれのフレームワークも任意のデータ変換処理に対応しており、出来ることはほぼ同じです。Kafka StreamsはDSLで一般的なデータ変換操作(map、filter、join、aggregateなど)が可能なだけでなく、Processor APIを使用すれば任意の変換処理を実装可能です。
バッチ処理への対応
Kafka Brokerはデータをディスクに永続化するため、以下のようなストリーム処理とバッチ処理のいずれにも対応しています。
- Topicに書き込まれたメッセージを逐次読み出してストリーム処理する
- Topicに一定期間分(1日分など)のメッセージを蓄積しておき、まとめて読み出してバッチ処理する
SparkとFlinkはストリーム処理とバッチ処理の両方に対応していますが、Kafka Streamsはストリーム処理のみ対応しています。ただし、ストリーム処理はバッチ処理を内包しているため、出来ることに実質的な違いはありません。
クラスタ管理基盤
Kafka Streamsは専用のクラスタ管理基盤を用意せず、複数台のサーバ上でインスタンスを起動するだけで、Broker経由で自動的に協調して動作します。Processor Topologyとして定義した処理を、インスタンス間で適切に分担して並列分散処理します。
一方、SparkとFlinkはクラスタ管理基盤(Hadoop YARNやKubernetesなど)の上で動作します。一応スタンドアローンで動作することも可能ですが、分散処理には向いていません。
Kafka Streamsはシンプルな構成で実行できることがメリットです。一方で、Kafka Streams単体では以下のような高度な運用はできないというデメリットもあります。
- Streamアプリケーションの負荷に合わせて、インスタンス数を自動的にスケーリングする
- サーバ障害発生時に、自動的に別のサーバで新しいインスタンスを起動する
- CPUコアやメモリの使用率が低いサーバを自動的に探してインスタンスを起動する
より高度なリソース管理が必要な場合は、コンテナ化したStreamアプリケーションをKubernetes上で実行し、Kubernetesのリソース管理機能で上記を実現するという手段もあります。Kubernetes上でKafkaを実行したい場合は、以下のプロジェクトもご参照ください。
おわりに
本稿ではKafka Streamsの概要とユースケースなどを紹介しました。次回はKafka Streamsのより詳細な内部構造と動作の流れ、およびチューニングのポイントを紹介します。