(株)日立製作所 研究開発グループ サービスコンピューティング研究部の栗原です。
今回、Kafkaを用いたSagaパターンのデモ構築(PostgreSQL+Debezium+Kafka)をし、動作検証したので、記事にしたいと思います。
1.Apache Kafka
Kafkaとは、分散イベントストリーミングプラットフォームのOSSです。高スケーラビリティ、高信頼性が特徴で、活用事例・応用分野も多く、ソフトウェア選定の際によく選ばれるソフトウェアの1つだと思います。
Apache Kafka: https://kafka.apache.org/
2.マイクロサービスのSagaパターン
マイクロサービスでは、複数のサービスにまたがってデータ更新するときの設計が難しくなります。あるサービスの中で処理が正常に進みトランザクションがコミットされたとしても、別のサービスの中で異常発生した場合、全体として処理は取り消される必要があるためです。
この全体の処理を1つのトランザクション中で実施することは難しいため、結果整合性での解決が図られます。この解決方法を実現するアーキテクチャとして、TCC(Try-Confirm/Cancel)パターンとSagaパターンの2種類が代表的です。
TCCパターンは、RDBの2相コミットのように、まず各サービスで更新可能であるかを確認した上で(Try)、全てのサービスで更新可能である場合に更新(Confirm)、そうでなければキャンセル(Cancel)という方法です。
一方Sagaパターンは、一旦は各サービスで処理を確定させてしまい、異常発生時は補償処理によってその結果を打ち消していくという方法です。
ここで疑問になったのが、あるサービスでの異常発生時に対する結果整合性の担保方法です。
TCCパターンは関連する全サービスから更新可能のレスポンスを得るまで処理が確定しないので、いずれかのサービスで異常が発生したとしても、デメリットが小さいように思います。
一方Sagaパターンでは、途中のサービスで異常発生しても他のサービスでの処理は止まらないため、データ更新と他サービスへの通知には結果整合性を持たせる必要があるとされています。
参考:
- Saga Orchestration for Microservices Using the Outbox Pattern: https://www.infoq.com/articles/saga-orchestration-outbox/
- Chris Richardson (2019), Microservices Patterns, Manning Publications
3.RDB+Debezium+Kafka
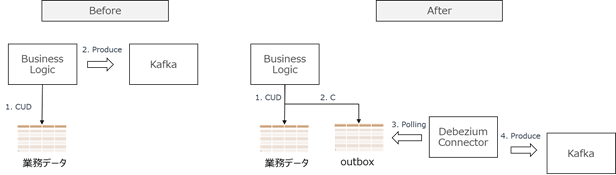
マイクロサービスで複数のサービスにまたがってデータ更新する際は、各サービスにおいてデータソース(RDB)の更新と、その更新内容を他のサービスに通知するという処理が必要です。
このデータ更新と他サービスへの通知に結果整合性を持たせる1つの方法は、DBへの更新データをキャプチャするための分散プラットフォームであるDebeziumを利用して、Transactional Outboxパターンを構築することです。
Debezium: https://debezium.io/
Transactional Outboxパターンでは、RDBに業務データのテーブルと、通知用のoutboxテーブルを用意して、両方のテーブルを1つのトランザクションでアトミックに更新します。Debeziumはoutboxテーブルの変更を検知して、それをKafkaのTopicに送信・通知します。つまり、アプリはRDBのみを更新し、メッセージ送信はDebeziumがRDBの変更を捕捉して行う事で、結果整合性を確保する仕組みです。
4.サンプル構築
実際に PostgreSQL+Debezium+Kafkaを用いたSagaパターンのサンプルを構築して、動作を検証してみます。
幸いなことにこの構成の構築例がGitHubに公開されているため、それを利用します。
なお、Sagaパターンの確認をするのが目的なので説明は省略しますが、このサンプルはオーケストレータ型の例となっています。
https://github.com/debezium/debezium-examples/tree/master/saga
簡単にサンプルの処理内容を説明するとフロントエンドとしてOrderサービスがクレジット支払いの注文を受け付け、バックエンドサービスであるCustomerサービスとPaymentサービスとでそれぞれユーザ情報の更新と決済情報の更新をする、というものです。

出典:https://github.com/debezium/debezium-examples/blob/master/saga/solution-overview.png
環境構築の前提条件はmavenとdocker-composeがインストールされていることで、docker-composeのバージョンは1.29.2で確認しています。
この例の中で重要な要素となるのは、2つあります。
1つはJavaで実装されたビジネスロジック側のライブラリで、もう1つはDebeziumのKafka Connectorです。
(1) debezium-quarkus-outboxライブラリ
Javaで実装されたビジネスロジック側では、debezium-quarkus-outboxというライブラリを使用しています。このライブラリは、他サービスへの通知をする機能と、通知を受け取る機能を提供しています。
他サービスへの通知をする機能として、監視対象のテーブル(業務データのテーブル)に対してCUD(Create/Update/Delete)操作が加えられた際に、その操作内容をJavaプログラムから指定されたテーブルであるoutboxeventテーブルにも同時に書き込む際の処理が実装されています。
加えて他サービスからの通知をKafka経由で受け取る機能も実装されており、このサンプルでは、バックエンドサービスである、決済情報の記録を模擬するPaymentサービスと、顧客の与信情報の記録を模擬するCreditサービスからそれぞれレスポンスを受け取っています。
Debezium Documentation>Integrations>Outbox Quarkus Extension:
https://debezium.io/documentation/reference/integrations/outbox.html
order-service/src/main/resources/application.propertiesがこのライブラリの設定ファイルです。オプション内容はリンク先で確認できます。
https://debezium.io/documentation/reference/integrations/outbox.html#_configuration
quarkus.datasource.db-kind=postgresql
quarkus.datasource.jdbc.url=jdbc:postgresql://localhost:5432/orderdb
quarkus.datasource.username=orderuser
quarkus.datasource.password=orderpw
quarkus.hibernate-orm.log.sql=true
quarkus.hibernate-orm.database.generation=drop-and-create
# quarkus.hibernate-orm.database.generation=update
quarkus.hibernate-orm.database.default-schema=purchaseorder
quarkus.log.level=INFO
quarkus.log.min-level=INFO
quarkus.log.console.enable=true
quarkus.log.console.format=%d{HH:mm:ss} %-5p [%c] %s%e%n
mp.messaging.incoming.paymentresponse.connector=smallrye-kafka
mp.messaging.incoming.paymentresponse.topic=payment.response
mp.messaging.incoming.paymentresponse.bootstrap.servers=localhost:9092
mp.messaging.incoming.paymentresponse.group.id=order-service
mp.messaging.incoming.paymentresponse.key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.incoming.paymentresponse.value.deserializer=io.debezium.examples.saga.order.facade.serdes.PaymentDeserializer
mp.messaging.incoming.paymentresponse.interceptor.classes=io.opentracing.contrib.kafka.TracingConsumerInterceptor
mp.messaging.incoming.creditresponse.connector=smallrye-kafka
mp.messaging.incoming.creditresponse.topic=credit-approval.response
mp.messaging.incoming.creditresponse.bootstrap.servers=localhost:9092
mp.messaging.incoming.creditresponse.group.id=order-service
mp.messaging.incoming.creditresponse.key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
mp.messaging.incoming.creditresponse.value.deserializer=io.debezium.examples.saga.order.facade.serdes.CreditDeserializer
mp.messaging.incoming.creditresponse.interceptor.classes=io.opentracing.contrib.kafka.TracingConsumerInterceptor
# Tracing configuration
quarkus.jaeger.service-name=order-service
今回はoutboxのデータも見たかったため、outboxへのINSERT後にデータが削除されないように以下を加えました。
quarkus.debezium-outbox.remove-after-insert=false
(2) Debezium Connector
DebeziumのKafka Connectorについてどのように動いているか確認します。この設定は3つのサービスで類似であるためOrderサービス向けの設定ファイルであるregister-order-connector.jsonだけ見てみると、以下のようになっています。
{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "order-db",
"database.port": "5432",
"database.user": "orderuser",
"database.password": "orderpw",
"database.dbname" : "orderdb",
"database.server.name": "dbserver1",
"schema.include.list": "purchaseorder",
"table.include.list" : "purchaseorder.outboxevent",
"tombstones.on.delete" : "false",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"transforms" : "saga",
"transforms.saga.type" : "io.debezium.transforms.outbox.EventRouter",
"transforms.saga.route.topic.replacement" : "${routedByValue}.request",
"poll.interval.ms": "100"
}
ポーリングするDBへのアクセス情報やKafka Connectorとしての設定情報が書かれています。注目する点は、Produce先となるKafkaのトピック名です。${routedByValue}となっており、これはoutboxテーブルのaggregateTypeで変数指定され、outboxへINSERTされたデータの内容によってProduceされるKafkaへのトピックが変わります。
5.検証
検証では以下の3つの観点で確認を行い、実案件での運用にあたっての課題がないかを確認します。
(1) 外部から見えるDBの更新がKafkaにProduceされる動作
(2) プログラム内部の動き
(3) 挙動を監視するためのトレーシングの仕組み
(1)外部から見えるDBの更新がKafkaにProduceされる動作
正常処理となるリクエストを実行したときの挙動について検証します。
$ http POST http://localhost:8080/orders < requests/place-order.json
バックエンドサービスの1つであるCustomerサービスへのトピックにProduceされたメッセージは次のコマンドで調べられます。
$ docker run --tty --rm --network saga-network debezium/tooling:1.1 kafkacat -b kafka:9092 -C -o beginning -q -f "{\"key\":%k, \"headers\":\"%h\"}\n%s\n" -t credit-approval.request
結果はこのようになりました。
{"key":57974d15-a2f5-49a7-b18a-71c636193bdd, "headers":"uber-trace-id=76d506f0a064b52d:edc3f04e96eac235:5c944ec803ae2b47:1,id=f9a78388-883a-45d7-b4f6-7d47f8c89187,uber-trace-id=76d506f0a064b52d:4f0ef2e07d4263d4:edc3f04e96eac235:1"}
{"order-id":3,"customer-id":456,"payment-due":4999,"credit-card-no":"xxxx-yyyy-dddd-aaaa","type":"REQUEST"}
"order-id"、"customer-id"、"payment-due"、"credit-card-no"、"type"といったデータがKafkaにProduceされたことが確認できます。
一方で、もう片方のバックエンドサービスであるPaymentサービスへのトピックにProduceされたメッセージを同様のコマンドで調べてみます。
$ docker run --tty --rm \
> --network saga-network \
> debezium/tooling:1.1 \
> kafkacat -b kafka:9092 -C -o beginning -q \
> -f "{\"key\":%k, \"headers\":\"%h\"}\n%s\n" \
> -t payment.request
結果は次のようになりました。
{"key":57974d15-a2f5-49a7-b18a-71c636193bdd, "headers":"uber-trace-id=76d506f0a064b52d:59e20a8698815bdb:221d613d33da9539:1,id=89b3769c-2c57-4da7-ac1e-69972a273fed,uber-trace-id=76d506f0a064b52d:13b0ea2fef3c4c2d:59e20a8698815bdb:1"}
{"type":"REQUEST","order-id":3,"customer-id":456,"payment-due":4999,"credit-card-no":"xxxx-yyyy-dddd-aaaa"}
さきほどと同じ"order-id"、"customer-id"、"payment-due"、"credit-card-no"、"type"のデータがKafkaにProduceされていることが確認できます。
次に、デフォルト設定から変更して自動的にDeleteされないようにしたOutboxテーブルがどうなっているかを確認します。
orderuser@order-db:orderdb> select * from purchaseorder.outboxevent;
+--------------------------------------+-----------------+--------------------------------------+---------+----------------------------+------------------------------------
--------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------+
| id | aggregatetype | aggregateid | type | timestamp | payload
| tracingspancontext |
|--------------------------------------+-----------------+--------------------------------------+---------+----------------------------+------------------------------------
--------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------|
| f9a78388-883a-45d7-b4f6-7d47f8c89187 | credit-approval | 57974d15-a2f5-49a7-b18a-71c636193bdd | REQUEST | 2021-08-16 07:12:42.605371 | {"order-id":3,"customer-id":456,"pa
yment-due":4999,"credit-card-no":"xxxx-yyyy-dddd-aaaa","type":"REQUEST"} | #Mon Aug 16 07:12:42 GMT 2021 |
| | | | | |
| uber-trace-id=76d506f0a064b52d\:a7c822eda5e59186\:76d506f0a064b52d\:1 |
| 89b3769c-2c57-4da7-ac1e-69972a273fed | payment | 57974d15-a2f5-49a7-b18a-71c636193bdd | REQUEST | 2021-08-16 07:12:42.956002 | {"type":"REQUEST","order-id":3,"cus
tomer-id":456,"payment-due":4999,"credit-card-no":"xxxx-yyyy-dddd-aaaa"} | #Mon Aug 16 07:12:42 GMT 2021 |
| | | | | |
| uber-trace-id=76d506f0a064b52d\:ecbf39660c99535e\:a4e5fb89cc4291a6\:1 |
+--------------------------------------+-----------------+--------------------------------------+---------+----------------------------+------------------------------------
--------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------+
SELECT 6
Time: 0.018s
さきほどKafkaにProduceされたメッセージ内容がpayloadとして記録されていことがわかります。
さらに他の列の情報を見てみると、aggregateTypeが”credit-approval“と”payment”となっている2つのレコードがほぼ同時にINSERTされていることがわかります。
これらのデータにより、credit-approval.requestとpayment.requestのそれぞれのトピックにメッセージがProduceされる挙動となっています。
(2)プログラム内部の動き
(1)で確認された2種類のレコードがどのようにINSERTされたかJavaのプログラムを追うと、
order-service/src/main/java/io/debezium/examples/saga/order/saga/OrderPlacementSaga.javaでの以下のアノテーションに記載されている情報に基づいて動いているようです。
@Saga(type="order-placement", stepIds = {CREDIT_APPROVAL, PAYMENT})
order-service/src/main/java/io/debezium/examples/saga/framework/SagaBase.java
では、アノテーションの”stepIds”で指定された各ステップを順番に処理を実行するように実装されています。正常処理はもちろん、異常処理発生時の補償トランザクションの実行についても、この情報に基づいて順に実行することが可能です。
フォルダの構成から考えると、このframeworkフォルダ以下の処理はビジネスロジックに依存しないように実装されているようです。業務データへのCUD処理を実行する際に、これらのクラスも利用するように実装することで、業務データと同じトランザクション中でoutboxeventテーブルへのINSERTを実行する仕様になっているようです。
このライブラリを利用してサービス間でリクエストとレスポンスを送りあうことを想定した場合、framework以下のフォルダでの処理内容に従えばSagaアーキテクチャのための実装工数が減らせると思います。一方で、サービス全体でこのライブラリを使うように統一しないと、統一できなかった箇所の実装はこのライブラリと互換するように実装する必要が出てきそうです。加えて、このライブラリを使う場合にはビジネスロジック中にライブラリを使用するための実装が必要であり、正しく利用するための学習コストやライブラリの仕様変更に対応する保守コストが必要となります。
(3)挙動を監視するためのトレーシングの仕組み
このサンプルには、分散システムのトレーシングを行うOSSである Jaeger が組み込まれています。これによりマイクロサービスにおけるサービス間のトランザクションの進捗を追跡できます。
Jaegerでトレーシング内容を確認してみると、Orderサービスで注文を受け付けた後、CustomerサービスとPaymentサービスで処理がなされ、最終的に両者の成功後にOrderサービスでの注文状況が完了状態になるまでの処理を一連のシーケンスとして確認することが可能です。
途中にはKafka Connectorでの処理も記録されているので、この部分のコンポーネントが増えたものの、どこで不具合が発生したか調査することは容易であると思われます。

6.まとめと今後の検証
今回は、Kafkaを使ったマイクロサービスのSagaパターンのデモシステム構築、その動作検証結果について紹介しました。
Sagaパターンで、データソースの更新と他サービスへの通知を一貫して実行したい場合、Transactional Outboxパターンによる解決があり、その実現方法として、RDB+Debezium+Kafkaという構成例があります。
その実装例として、debezium-quarkus-outboxというライブラリを用いたシステムの構築を試し、どのようにSagaパターンが実現されているかを確認しました。
そうすると、Javaのコードにもこのライブラリ用の実装箇所が必要なものの、設定ファイルによって実現可能な範囲が多く、工数削減につながる可能性があることがわかりました。
一方で、このライブラリを使う場合は、通信するサービス間で統一的に使用するか、少なくとも互換するように実装をする必要があるのではないかと思われます。
この例を使って今後、サービスからの復旧動作など異常処理時の動作をさらに調べていきたいと思います。