著者: 伊藤 雅博, 株式会社日立製作所
はじめに
本稿ではKafka Streamsの詳細な内部動作と動作の流れ、およびチューニングのポイントを紹介します。Kafka Streamsの概要や全体像については前回の記事で紹介していますので、そちらもご参照ください。
記事一覧:
- Kafka_Streamsの概要とユースケース
- Kafka Streamsのアーキテクチャとチューニングポイント(本稿)
- Kafkaクラスタを構築してKafka Streamsを試す(Podmanコンテナ環境編)
Kafka Streamsの内部構造
Kafka Streamsは、Topicに格納されたメッセージを読み出して変換処理を行い、別のTopicに書き戻すような処理を実装できるフレームワークです。
JavaまたはScala言語で利用できるライブラリとして提供されます。Kafka Streamsを使用して作成したStreamアプリケーションは、Java仮想マシン(JVM: Java Virtual Machine)上で動作します。
Kafkaのメッセージはキーバリュー形式であり、レコードとも呼びます。キーとバリューは共に任意のテキストまたはバイナリデータを格納でき、キーは空でも問題ありません。レコードのサイズは、Brokerのデフォルト設定だと最大1MBとなります。
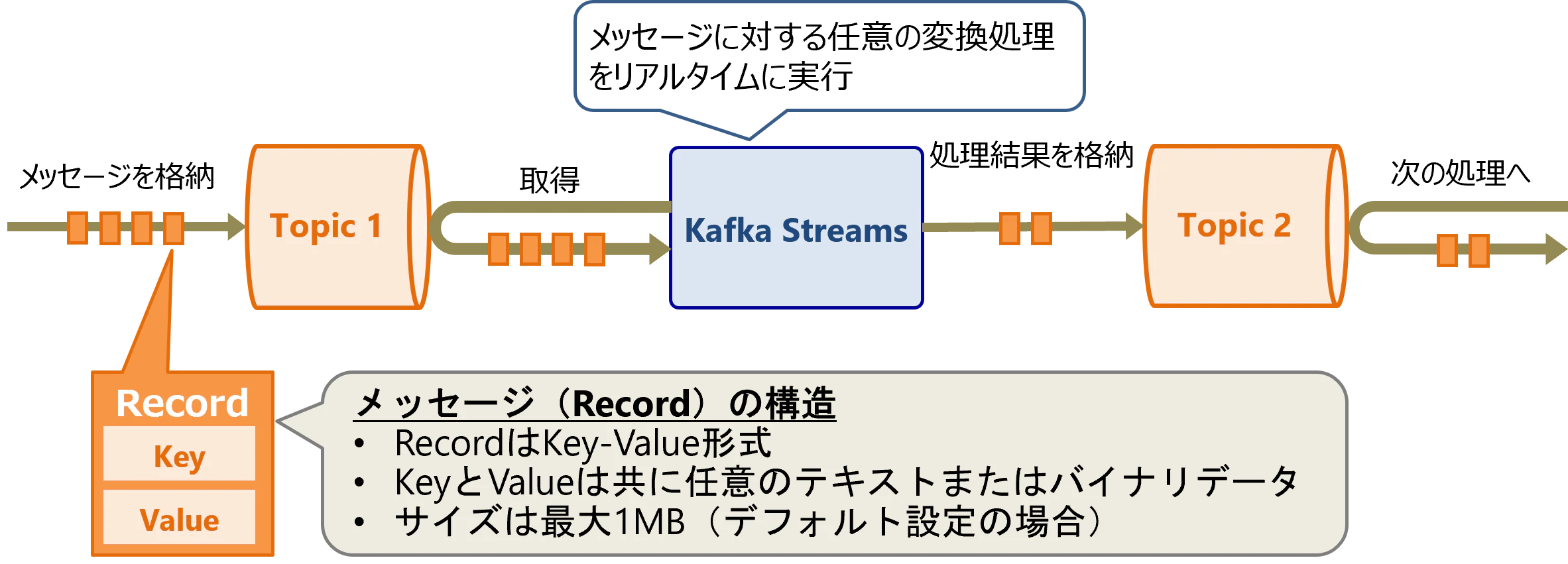
ここではKafka Streamsのより詳しい内部構造を説明します。
並列分散処理の仕組み
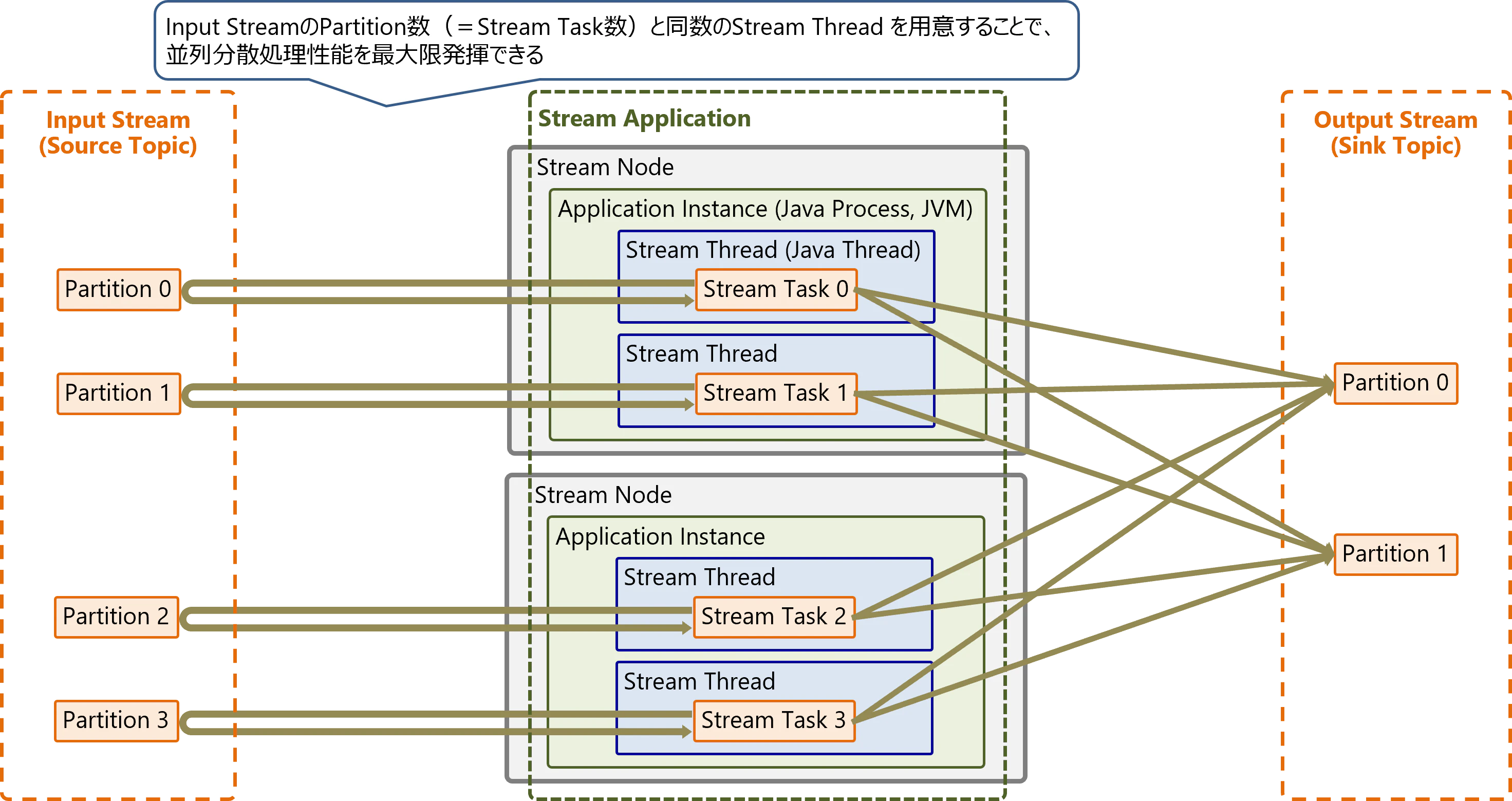
Streamアプリケーションは以下の構成により、データを並列分散処理します。
- Stream Application (アプリケーション)
- 1つのStreamsアプリケーションであり、1つ以上のApplication Instanceが処理を行う
- Application Instance (インスタンス)
- 1つのJavaプロセスであり、1つ以上のStream Threadを実行する
- Stream Thread (スレッド)
- 1つのJavaスレッドであり、1つ以上のStream Taskを実行する
- Stream Task (タスク)
- Processor Topologyで定義したデータの変換処理を実行する
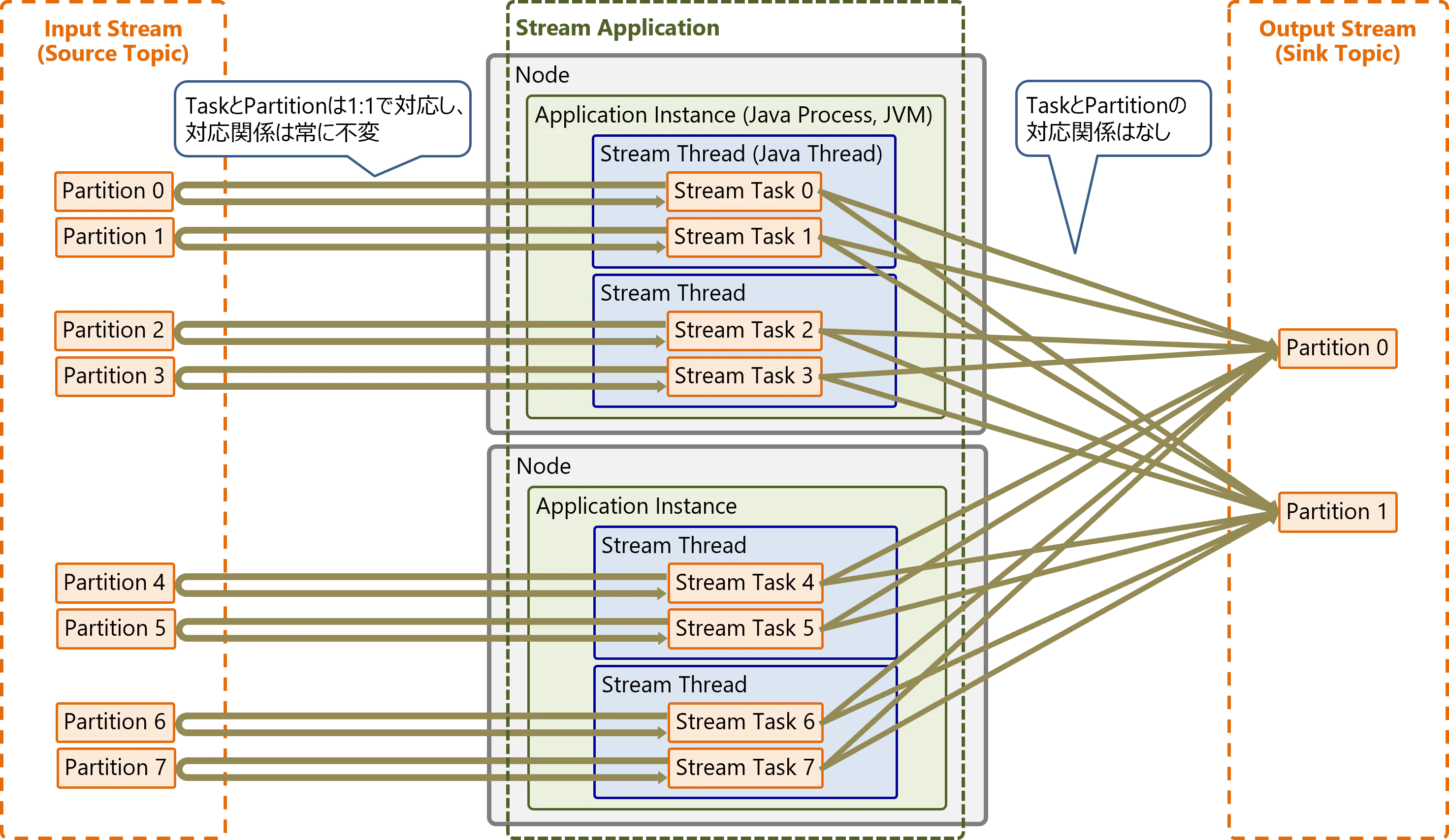
Stream Application(Streamアプリケーション)は、1つ以上のApplication Instanceで構成されます。同じアプリケーションID(application.id)を指定したApplication Instanceを複数起動すると、それらはBroker経由で連携し、同一のStream Applicationを構成するApplication Instanceと認識されます。これにより複数のApplication Instanceによる分散処理を行います。
Application Instanceは、Streamアプリケーションのインスタンスです。これは1つのJavaプロセスであり、1つ以上のStream Threadを実行します。
Stream Threadは、1つのJavaスレッドです。1つ以上のStream Taskを実行します。インスタンスのスレッド数はnum.stream.threadsで指定可能です。初期設定では1スレッドで動作します。
Stream Taskは、Processor Topologyとして定義した変換処理を実行するタスクです。Input StreamのPartitionと1:1で対応するタスクが自動生成されます。
タスクはスケールアウト/スケールイン時や障害発生時に、別のスレッドに移動(リバランス)することがあります。しかしInput StreamのPartitionとタスクの対応関係は不変で、各Partitionは常に同じタスクが処理します。一方、Output StreamのPartitionとタスクの間には、対応関係はありません(処理内容に依存します)。
アプリケーションのデータ処理
インスタンスの処理の流れをもう少し詳しく説明します。以下の図は、1つのインスタンスが1つのスレッドで、2つのタスクを実行する例です。
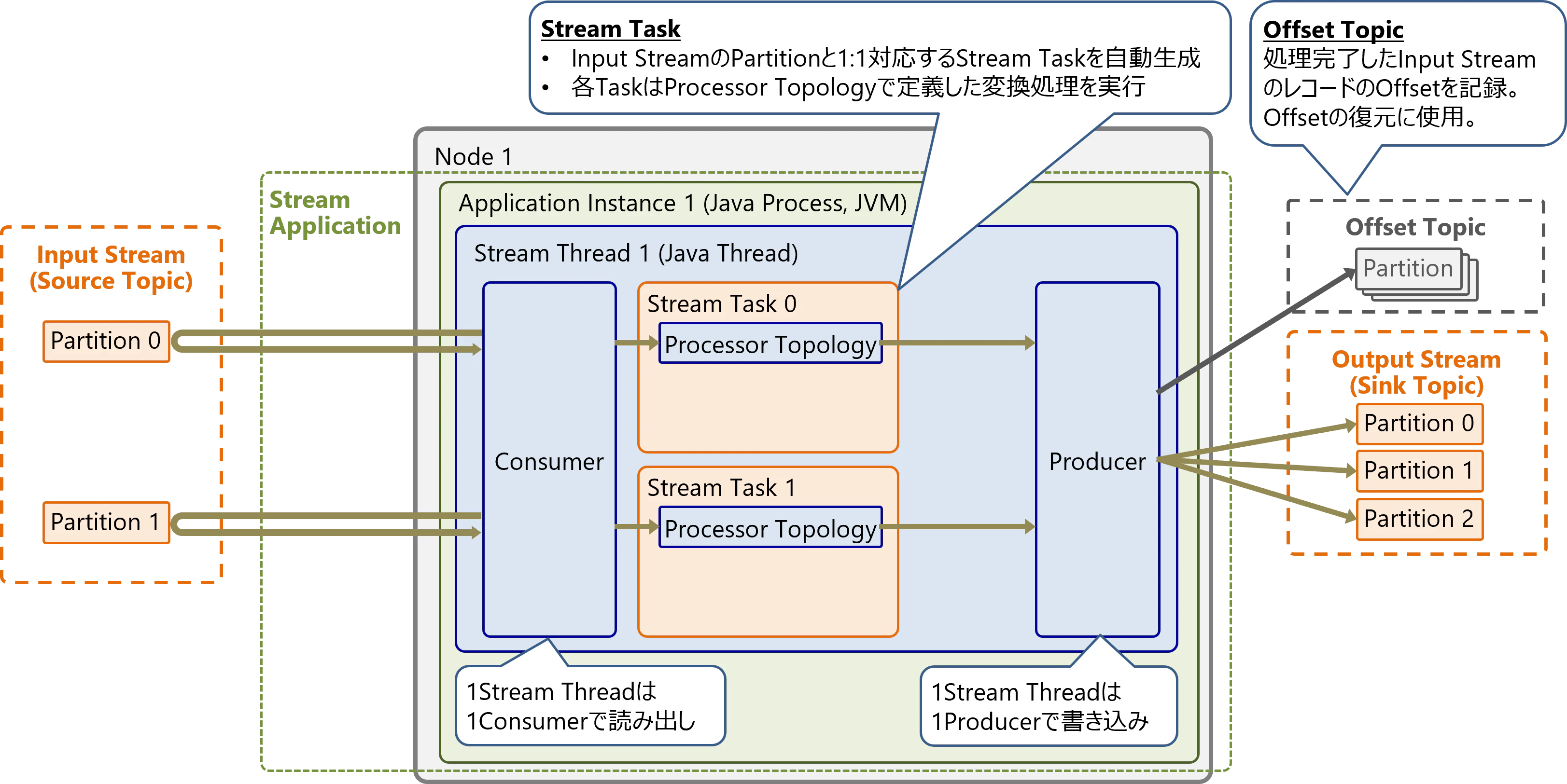
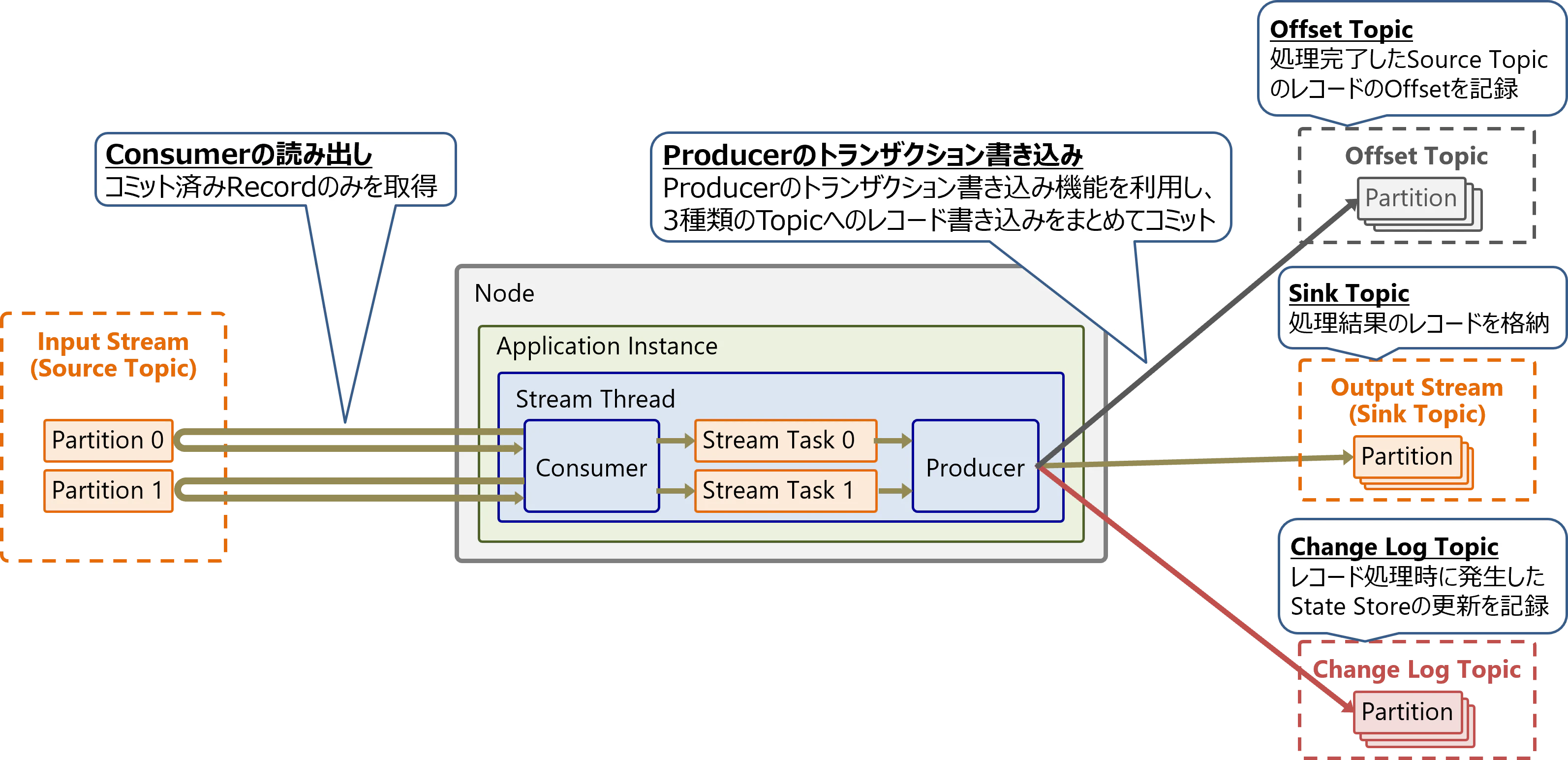
各スレッドはProducerとConsumerを持ちます。ConsumerでInput Streamからデータを読み出し、各タスクでデータを変換処理し、処理結果をProducerでOutput Streamに書き込みます。
処理が完了したレコードは、そのInput StreamのOffsetを、Offset Topicへ定期的に書き込みます(デフォルト設定では30秒間隔)。これにより、Input Streamのレコードをどこまで処理したかを管理します。
サーバ障害やスケールアウト/スケールインが発生すると、タスクは別のインスタンスに移動することがあります。タスクが処理を再開する際は、再開する時点のOffsetをOffset Topicから読み出します。これは一般的なConsumerの動作と同じです。
アプリケーションのデータ管理
集約処理(Aggregate、Count、Reduceなど)や結合処理(Join)は、複数レコードにまたがる状態を保持するStatefulな処理です。このような処理で保持するデータは、State Storeに保存します。State Storeは以下の要素で構成されます。
- State Store
- 各タスクのデータを保持する仮想的なデータストア
- Record Cache
- State Storeのキャッシュメモリ
- Local State Store
- State Storeのデータの実体をローカルディスクに保持するデータストア(RocksDB)
- Change Log Topic
- State Storeの変更ログを追記するTopic
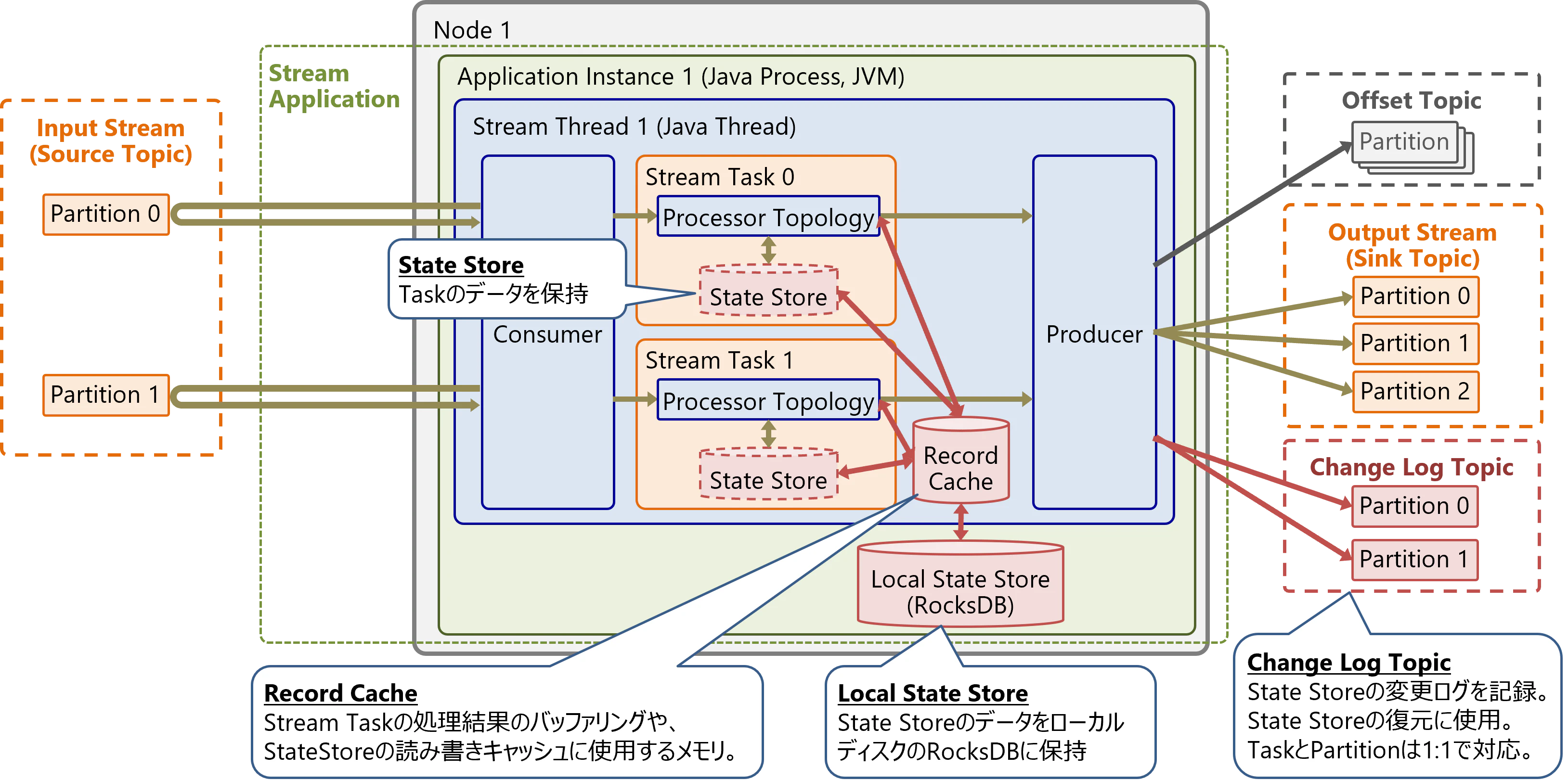
State Storeは各タスクが持っており、Stateful処理用のテーブルデータを保持します。State Storeはタスクだけでなく、外部のアプリケーションからもAPI経由でアクセスも可能です。外部のアプリケーションからは、対話型クエリと呼ばれる機能を通じて、読み取り専用で参照できます。State Storeのデータの実体は、Record CacheおよびLocal State Storeに格納します。
Record Cacheは、スレッドごとにタスク処理結果のバッファリングやState Storeの読み書きキャッシュに使用する、メモリ内ハッシュマップです。この容量はインスタンス単位で指定し、スレッド間で均等に分配されます。この容量はstatestore.cache.max.bytes で指定可能で、初期設定は10485760(10MB)です。
Local State Storeは、State StoreのデータをローカルディスクのRocksDBに保存・永続化します。Local State StoreのRocksDBは、各インスタンスにタスク (State Store)単位で存在します。RocksDBはOSSのキーバリューストアです。なお、Kafka StreamsではオンメモリのState Storeも利用可能であり、その場合はLocal State Store (RocksDB)は使用しません。
Change Log Topicは、State Storeの変更ログを追記するTopicです。サーバ障害やスケールアウト/スケールインが発生すると、タスクは別のインスタンスに移動するためLocal State Storeは利用出来なくなります。Change Log Topicは、移動先のインスタンスでState Storeを復元・再構築するために使用します。Change Log TopicのPartitionはタスクと1:1で対応し、各タスクのState StoreはそのPartitionから復元します。
複雑なデータ処理の動作
タスク間のデータ交換
レコードのグループ化(GroupBy)などの操作では、タスク間のデータ交換(Repartition)が発生します。このような処理の場合、1つのProcessor Topologyが複数のSub Topologyに分割されます。
例えばWordCount(単語の出現回数カウント)アプリケーションは、同じ単語を同じタスクに集めるデータ交換を挟むため、2つのSub Topologyに分割されます。
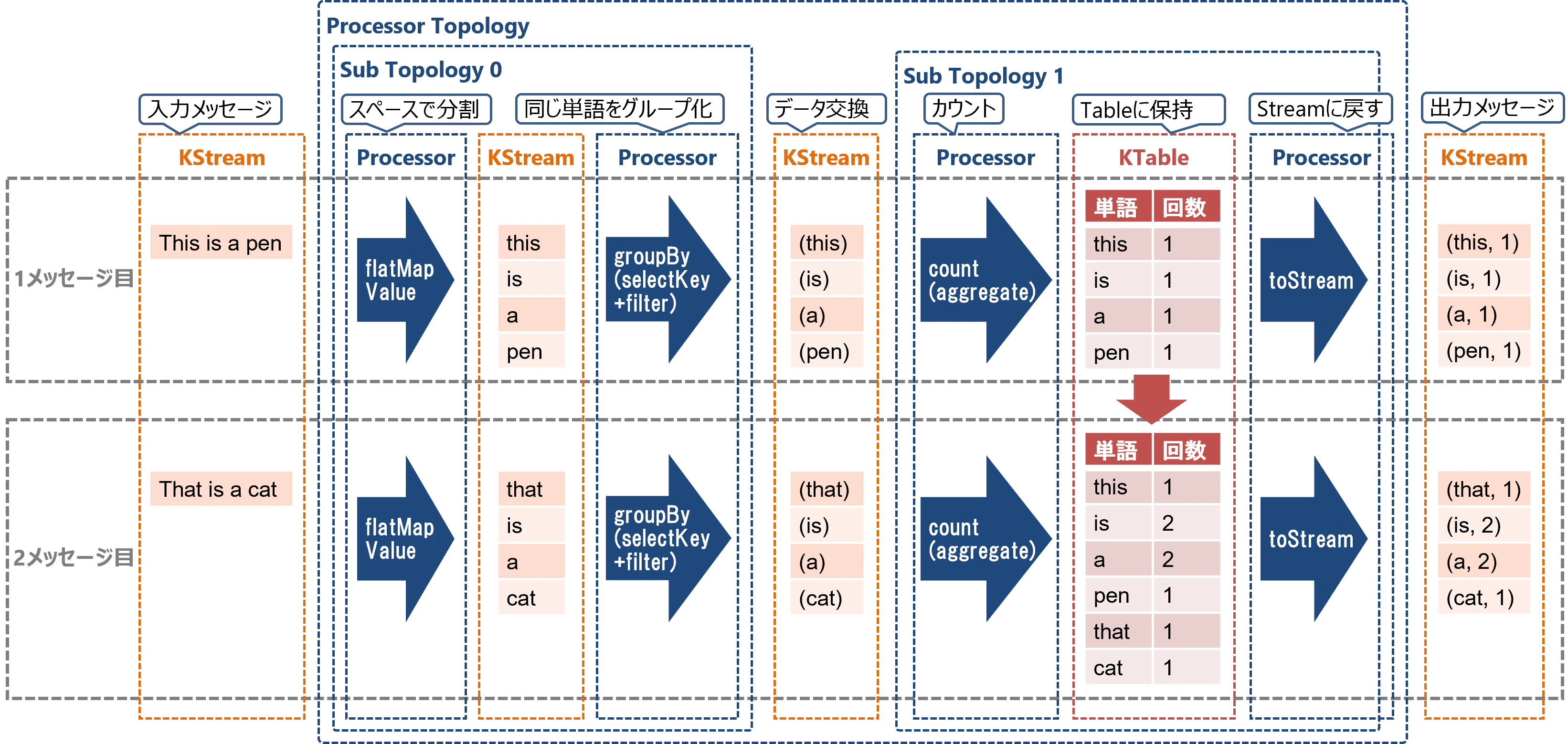
※ 上記の例にあるKafka Streams DSLのgroupBy操作は、正確にはselectKeyとfilterという2つのProcessorで処理されます。またcount操作は、aggregateというProcessorで処理されます。
各Sub Topologyは、以下のように別々のタスクとして動作します。Sub Topologyのタスクは、別々のインスタンスで実行される場合もあります。
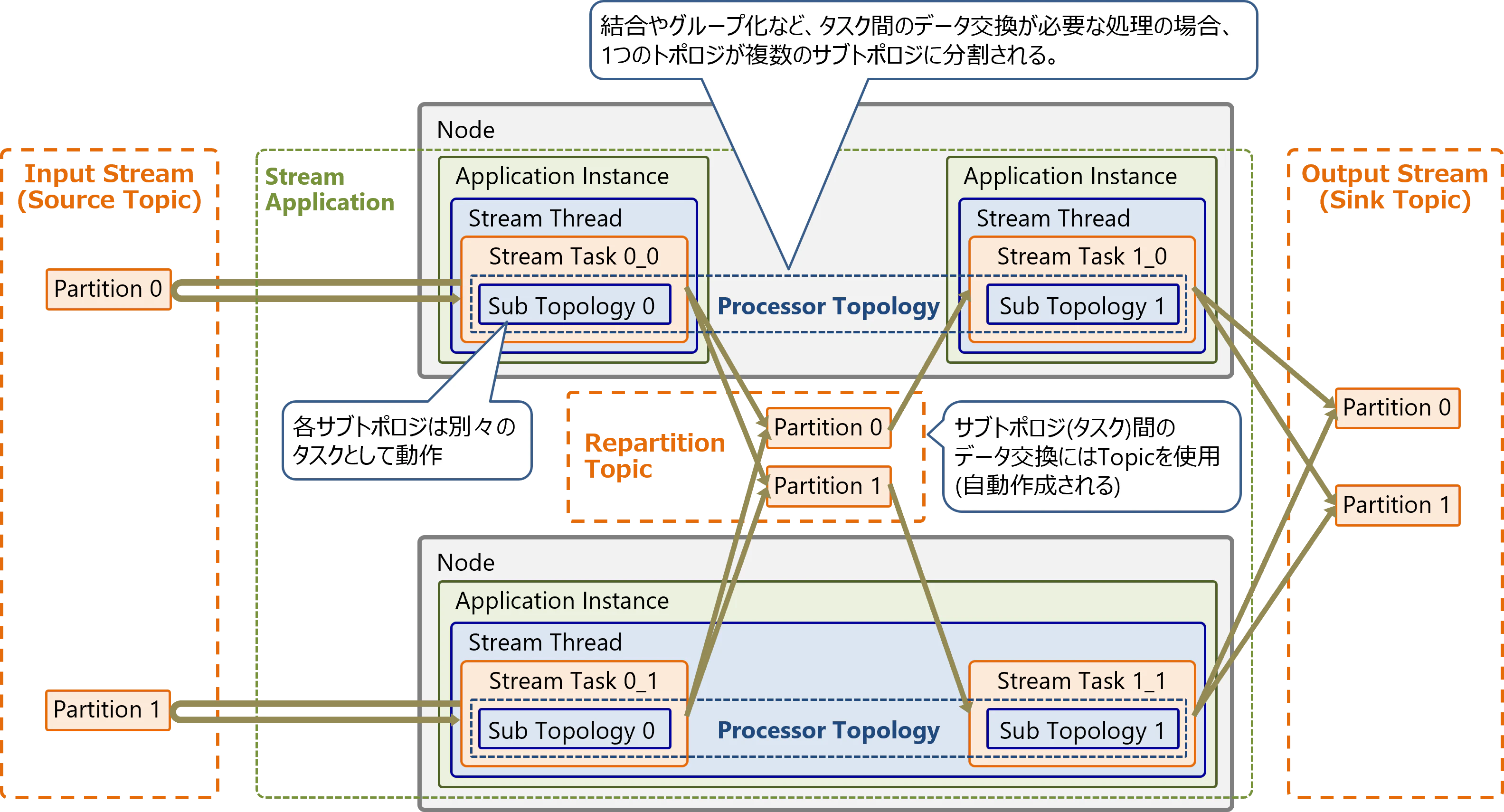
Sub Topology (タスク) 間のデータ交換は、自動生成されるRepartition用のTopicを経由して行います。そのためRepartitionが必要なデータ変換処理は、Topicの読み書きで処理時間が増加します。
複数Topicのデータ結合
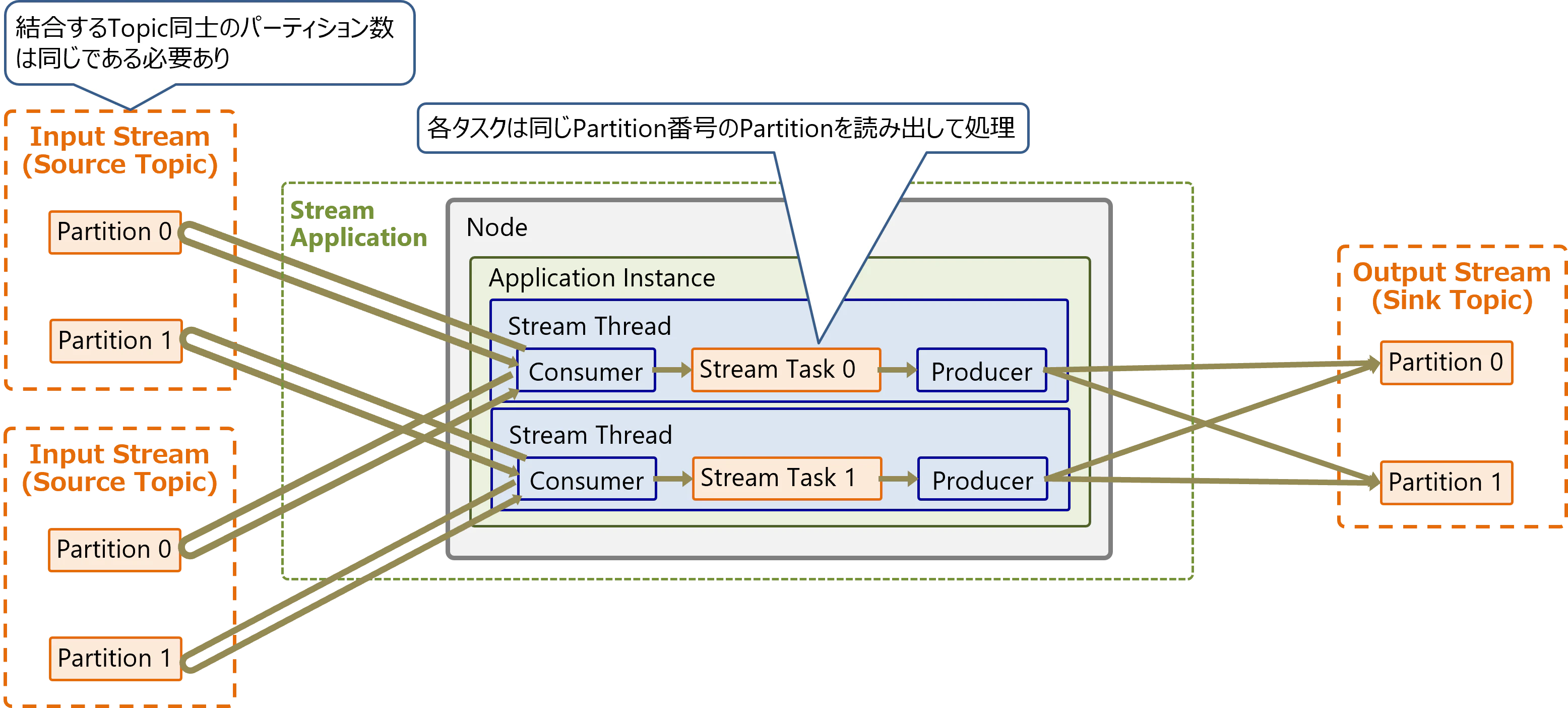
Kafka Streamsでは、2つのTopicのレコードを結合するJoin操作が可能です。
Join操作では、結合するTopic同士のPartition数は同じである必要があります。各タスクは2つのTopicから、同じ番号のPartitionを読み出して、2つのレコードを1つのレコードに結合します。
スケールアウトの仕組み
Streamアプリケーションは、インスタンス数、スレッド数を増やすことでスケールアウトが可能です。初期設定では1インスタンスあたり1スレッドで動作します。
- スレッド数の設定
- インスタンスのスレッド数の設定値(初期設定:
num.stream.threads=1)を変更する
- インスタンスのスレッド数の設定値(初期設定:
- インスタンス数の設定
- 同じアプリケーションID(
application.id)を指定したインスタンスを複数起動する- 同じIDを指定したインスタンス同士はBroker経由で自動的にグループ化され、タスクはグループ内のインスタンスが持つスレッド間で自動的に分散配置される
- 内部ではKafka ConsumerのConsumer Groupの仕組みを利用している
- 同じアプリケーションID(
インスタンス数、スレッド数を増やす際には、合わせてハードウェア(サーバ台数、vCPU数)の増設も必要です。
なお、StreamアプリケーションはJavaが動作する任意のサーバ上で実行できるため、Brokerサーバとの同居も可能です。ただしスケールアウトまで考慮する場合は、Brokerクラスタとは別にStreamアプリケーション用のサーバを用意することを推奨します。
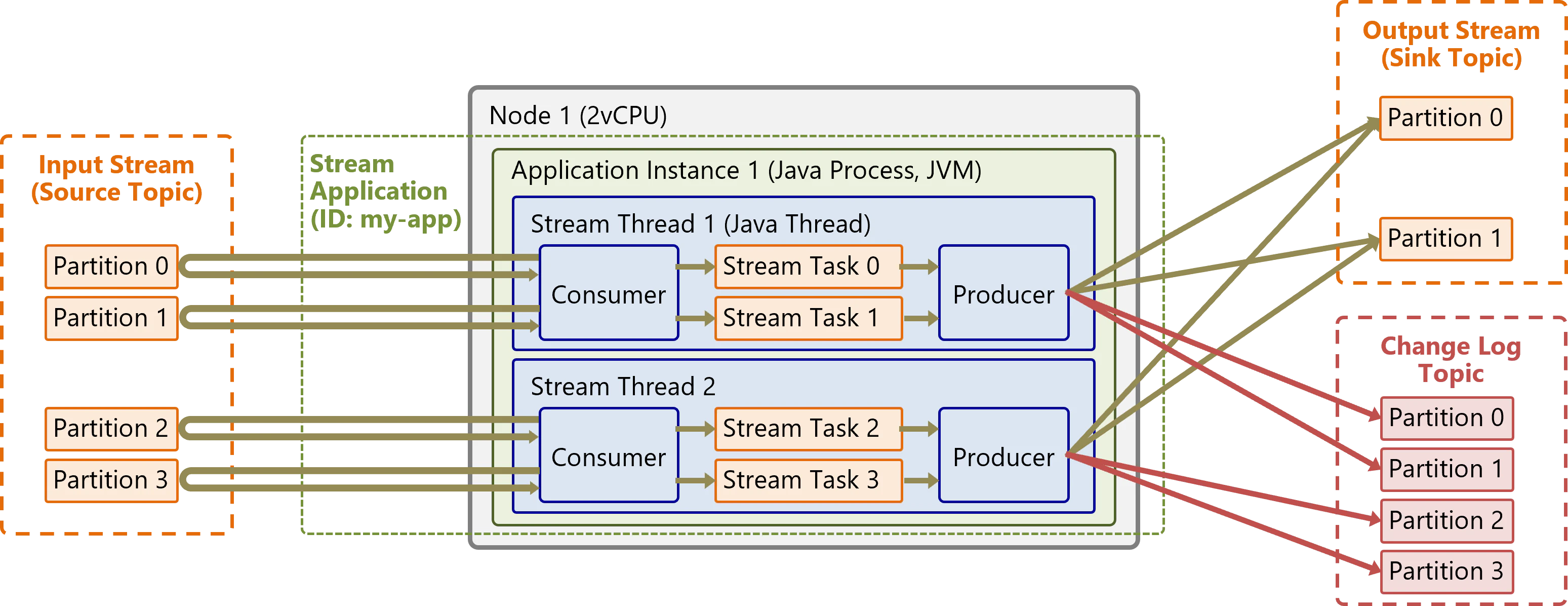
例1: インスタンスのスレッド数を増やす
サーバのvCPU数に合わせて、インスタンスをマルチスレッド構成にします。以下の例では、2つのvCPUを持つ1台のサーバ上で、1インスタンスをスレッド数2で起動します。起動すると、各スレッドにタスクが均等に割当てられて実行されます。
例2: サーバとインスタンス数を増やす
例1の状態から、サーバを増設して追加のインスタンスを実行します。同じアプリケーションID(application.id)を指定したインスタンスを起動すると自動的にグループ化されます。
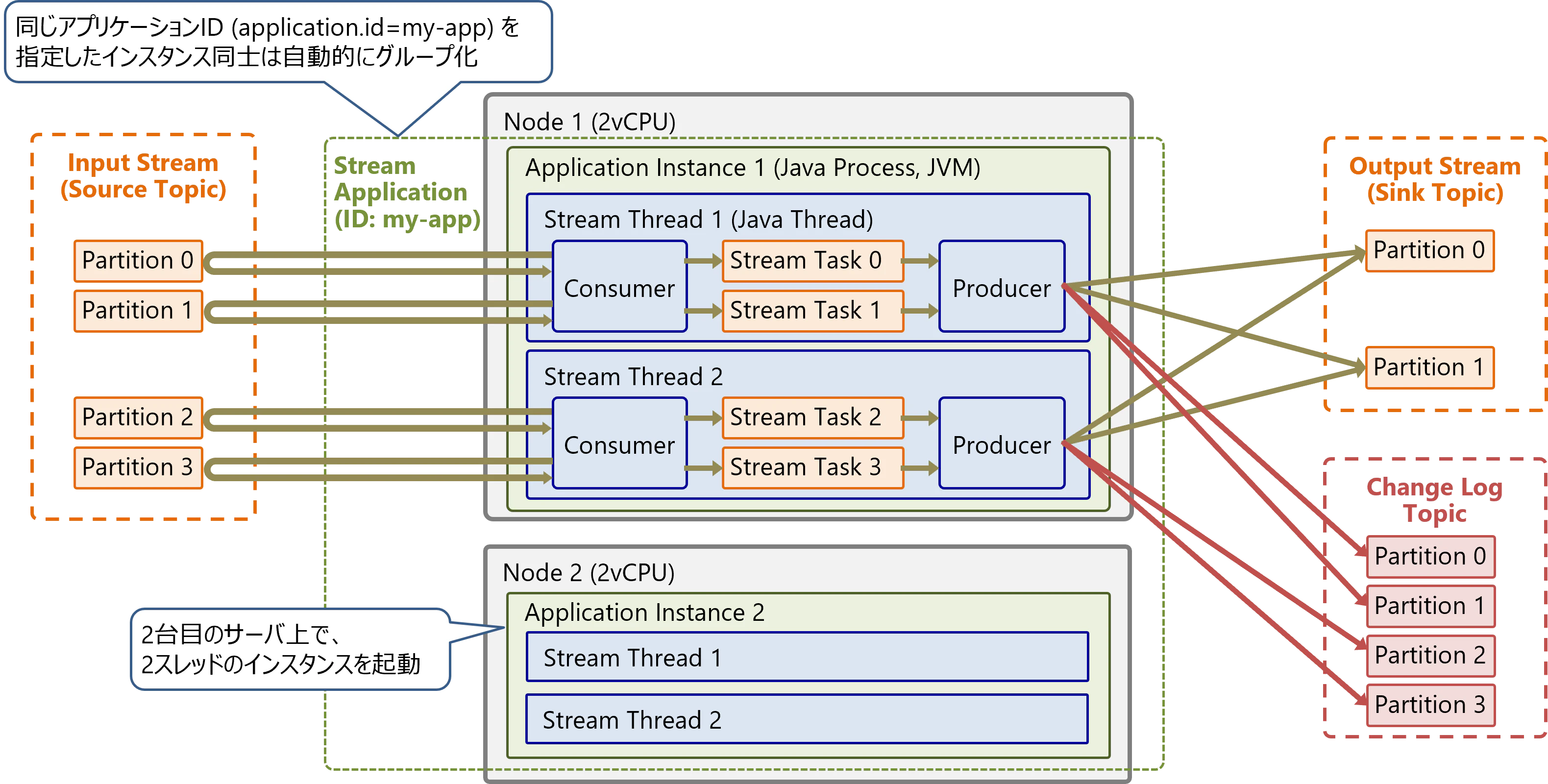
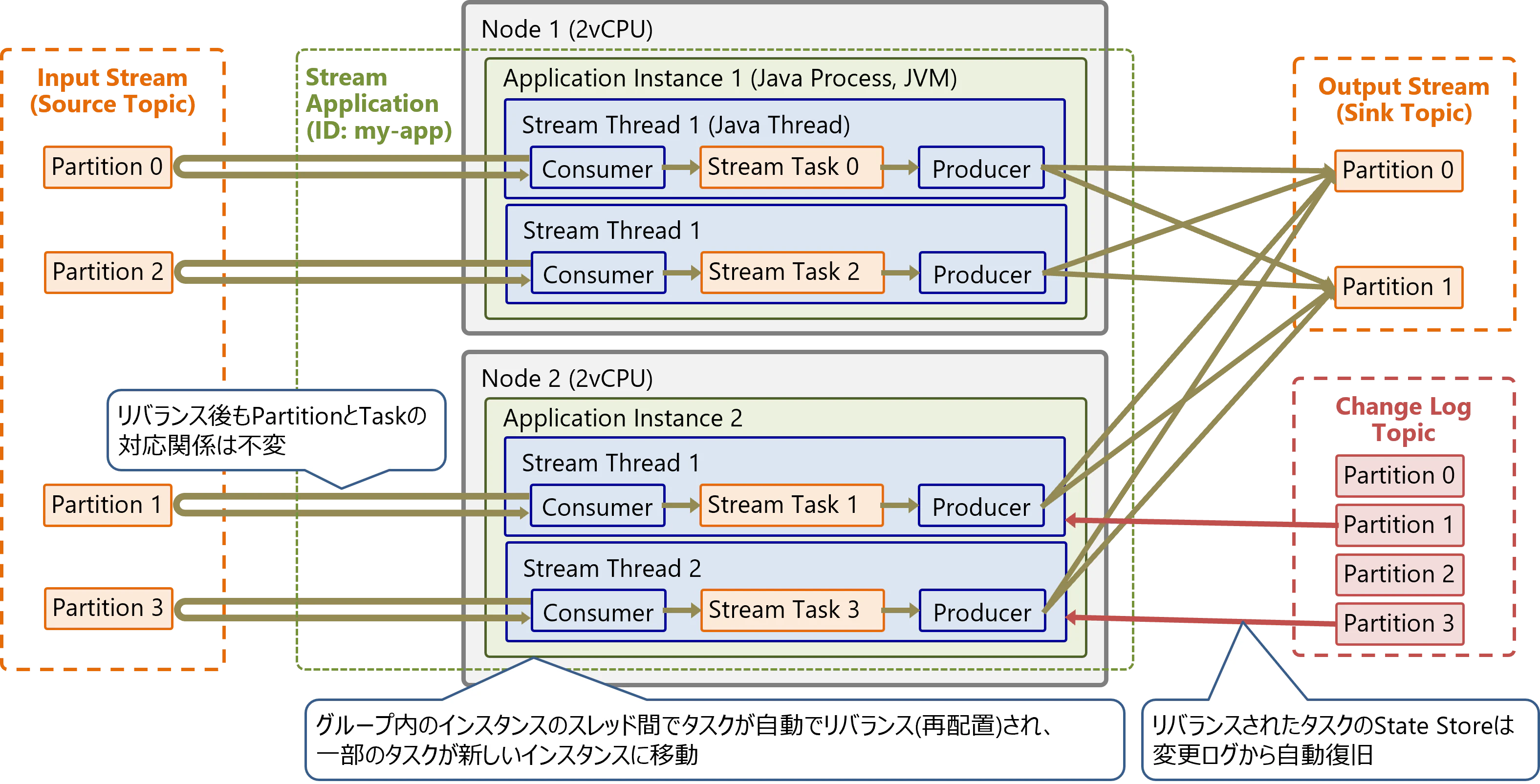
グループ内のインスタンスのスレッド間でタスクが自動でリバランス(再配置)され、一部のタスクが新しいインスタンスに移動します。リバランスされたタスクのState Storeは、Change Log Topicの変更ログから自動的に再構築されます。
リバランスでタスクが別のインスタンスに移動した後も、同じPartitionは同じタスクが担当します。
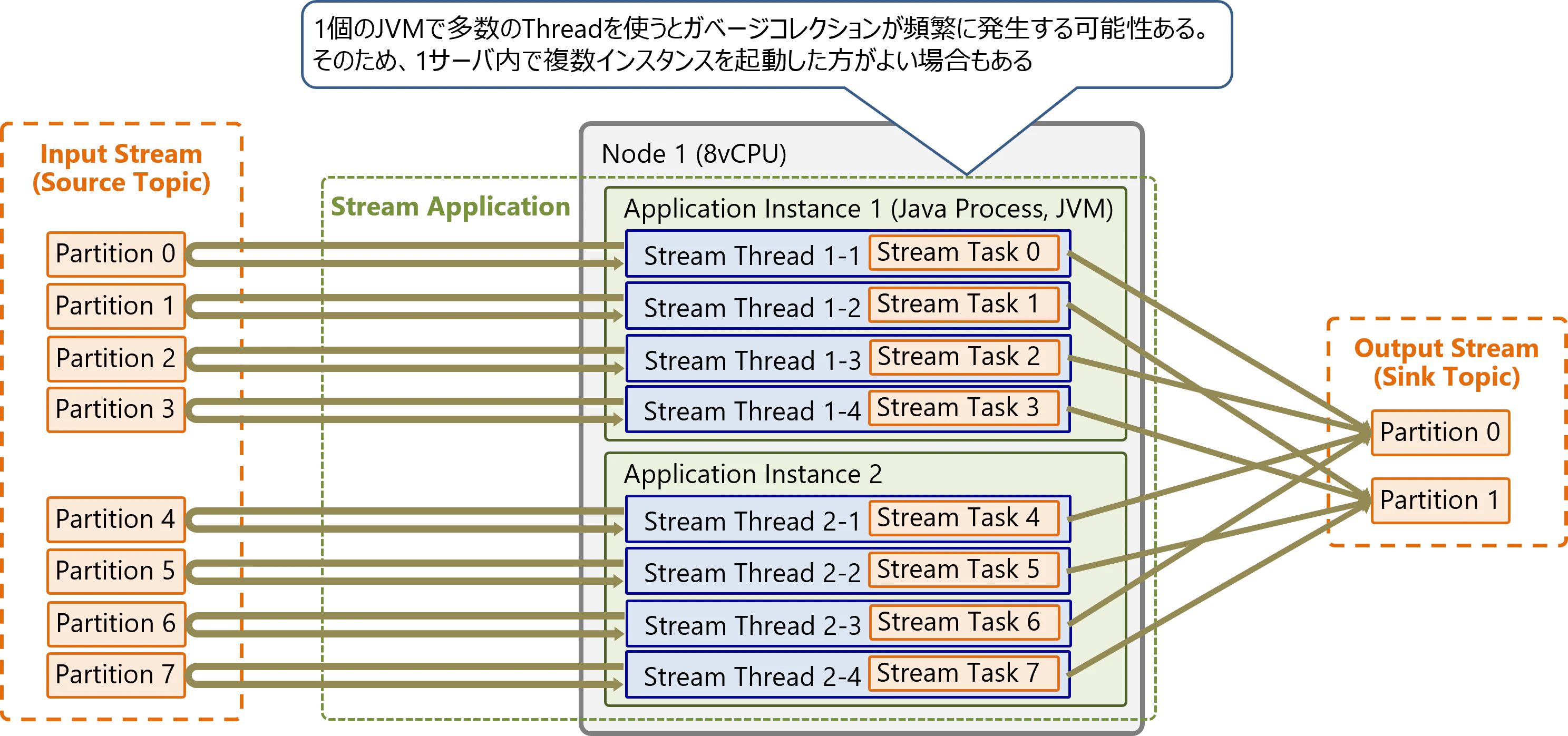
例3: 同一サーバ上で複数インスタンスを起動
1個のJVMで多数のスレッドを実行すると、ガベージコレクションが頻繁に発生する可能性あります。そのためCPU数の多いサーバの場合、1サーバ内で複数のインスタンスを起動した方がよい場合もあります。
1インスタンスあたりの適切なスレッド数は処理内容に依存するため、明確な基準はありません。実際に処理を行い、ガベージコレクションが頻繁に発生するかどうかを確認して判断する必要があります。
フォールトトレランスの仕組み
サーバ障害発生時の自動復旧について説明します。
リバランス
あるインスタンス上のタスクを、別のインスタンスへ再配置することをリバランスと言います。リバランスは以下のようなケースで発生しますが、いずれの場合も動作は同じです。
- スケールアウト(サーバ追加)
- スケールイン(サーバ削減)
- サーバ障害(サーバ削減に相当)
リバランスでは下記2つの処理を行います。
- タスクの再配置
- State Storeの再構築
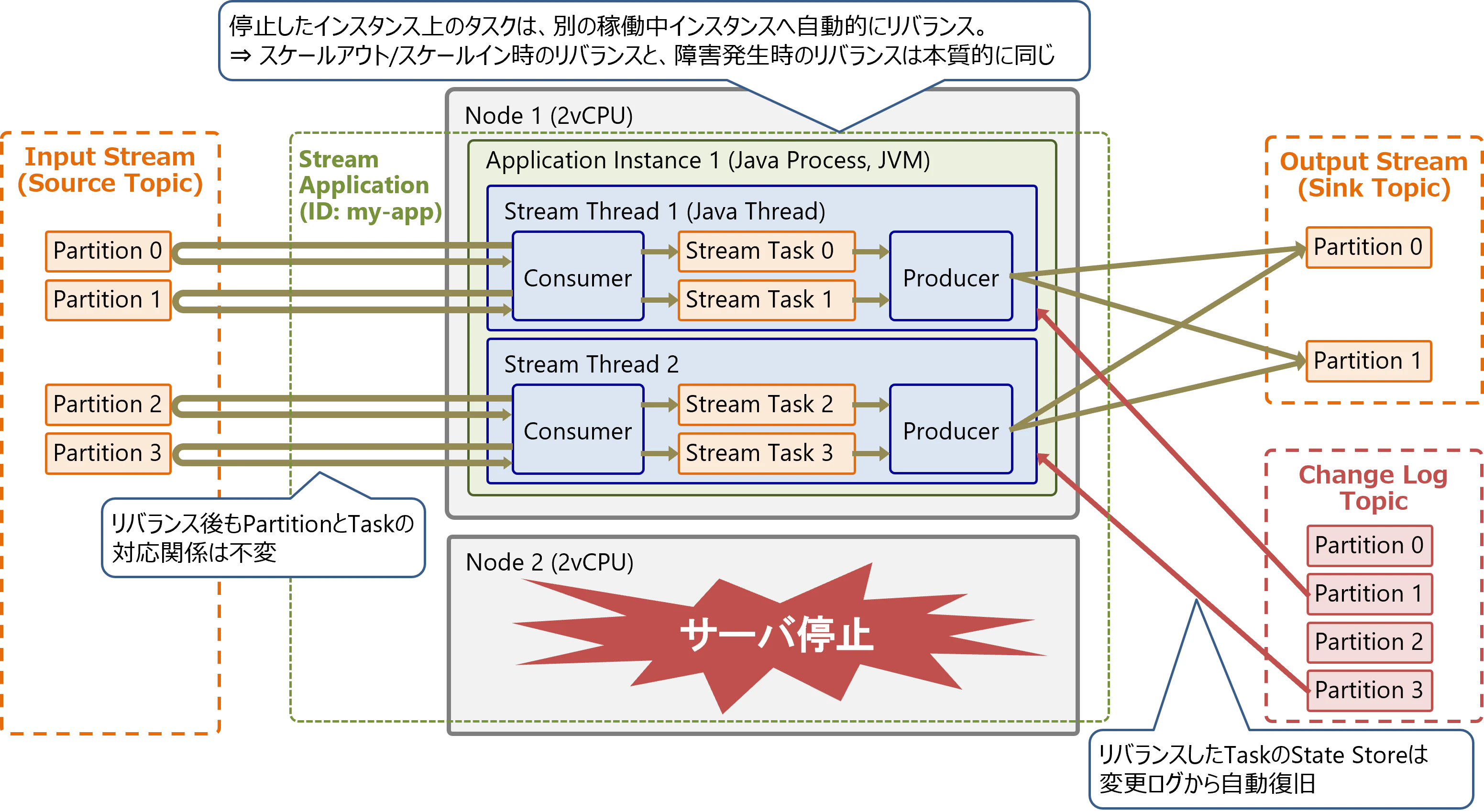
以下のように、Streamsアプリケーションのインスタンスが稼働中のサーバが1台停止したと想定します。
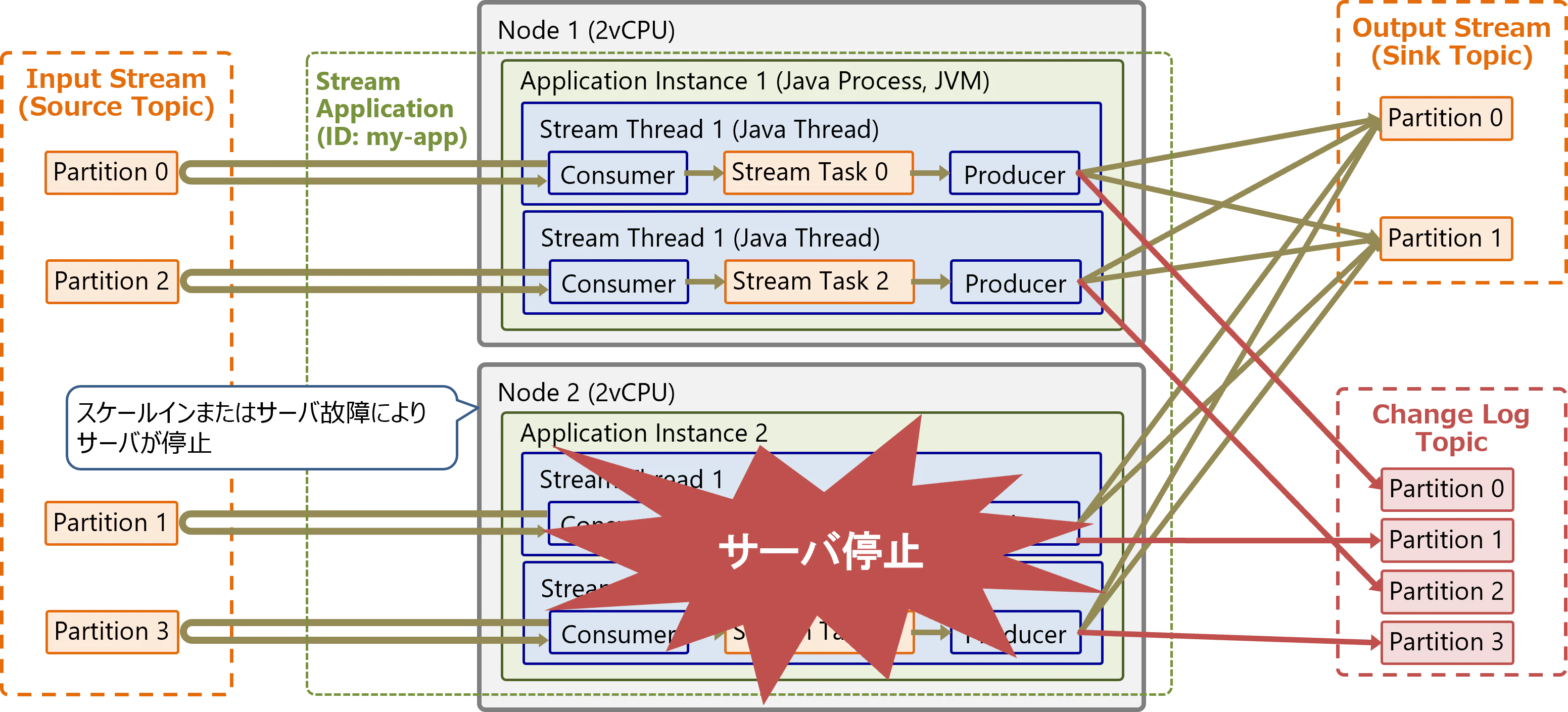
停止したインスタンス上のタスクは、別の稼働中インスタンスへ自動的に再配置されます。再配置したタスクのState Storeは、変更ログ(Change Log Topic)から自動的に再構築されます。リバランス後も同じPartitionは同じタスクが担当します。
State Storeのスタンバイレプリカ
リバランスしたタスクのState Storeを再構築するには、Change Log Topicに保存した変更ログを読み出す必要があります。State Storeのサイズが大きい場合は、この再構築に時間がかかります。
この再構築時間を削減するために、State Storeの複製であるスタンバイレプリカを、別のインスタンス上に用意することが可能です。スタンバイレプリカは、Change Log Topic経由で複製元と同じState Storeを常に維持します。リバランスが発生すると、タスクはスタンバイレプリカが既に存在するインスタンスの1つに割り当てられます。
State Storeの複製数はnum.standby.replicasで指定できます。初期設定は0個です。
- 参考: Fault Tolerance
メッセージ処理のセマンティクス
At-least-onceのメッセージ処理
Kafka Streamsのデフォルト設定では、各レコードが最低でも1回処理されることを保証します(At-least-onceのメッセージ処理)。これは、同じレコードの処理が複数回実行される可能性があるということです。また、これによりState Storeの状態が複数回更新され、意図しない状態となる可能性があります。
これはOffset Topic、Sink Topic、Change Log Topicの書き込みタイミングのズレにより発生します。例えば、あるレコードが処理されてSink TopicとChange Log Topicの書き込みが完了したが、Offset Topicの書き込み前に障害が発生してインスタンスが落ちたとします。落ちたインスタンスのタスクは別のインスタンスに引き継がれますが、このときOffset Topicに記録されたOffset以降のレコードから処理を再開するため、処理済みのレコードがもう一度処理されてしまいます。
Exactly-onceのメッセージ処理
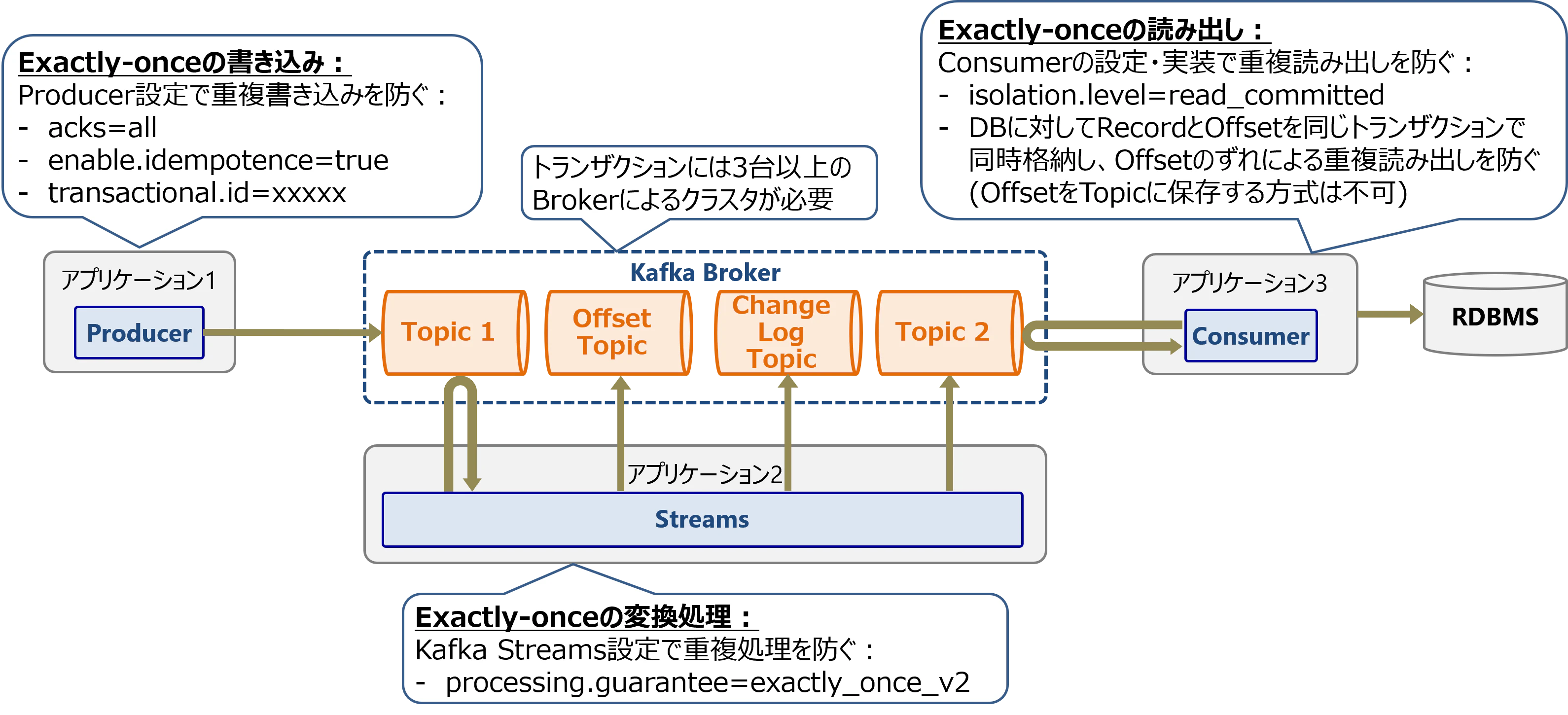
Kafka Streamsではこれを防ぐために、各レコードを確実に一回だけ処理する設定があります(Exactly-onceのメッセージ処理)。これはprocessing.guaranteeをexactly_once_v2に設定することで実現できます。
この設定ではProducerのトランザクション書き込み機能を利用して、複数のTopicとPartitionにまたがる複数レコードの書き込みを、アトミックに実行します。これによりOffset Topic、Sink Topic、Change Log Topicの書き込みをアトミックに行います。また、Consumerはトランザクションでコミット済みのレコードのみを取得します。
exactly_once_v2が有効な場合、Streamsアプリケーションには以下のパラメータが自動設定され、これによりトランザクションを実現します。
- トランザクション用ID
-
transactional.id: 自動生成(<アプリケーションID>-<インスタンスID>-<スレッドID>)- Producerを一意に識別する文字列を指定
-
- レコードの冪等処理
-
enable.idempotence:true- ProducerがRecordにシーケンス番号を付加することで、Broker側で重複排除(冪等処理)する
-
- トランザクションのコミット頻度 (ミリ秒単位)
-
commit.interval.ms:100- トランザクションにおけるレコード書き込みをコミットする間隔
-
- Consumerの分離レベル
-
isolation.level:read_committed- トランザクションでコミット済みのレコードのみを取得する
-
Exactly-onceのメッセージ処理はボトルネックが増えるため、At-least-onceに比べてスループットは低下するトレードオフがあります。
End-to-EndのExactly-onceなメッセージ配信
上記の設定が保証するExactly-onceはStreamsアプリケーションの範囲のみですが、実運用におけるExactly-onceはEnd-to-Endで考える必要があります。
例えば以下のように、ProducerによるTopicへのレコードの格納、Streamsアプリケーションによる変換処理、Consumerによる読み出しなど、全てをExactly-onceで実現する必要があります。
チューニングのポイント
Kafka Streamsのチューニングのポイントを以下に示します。
- スレッド数とインスタンス数
- Record Cacheのメモリ容量
- RocksDBの設定
- スタンバイレプリカの個数
- Exactly-once処理の設定
- ProducerとConsumerの設定
- Topicのデータ複製設定
参考ドキュメント:
- DEVELOPER GUIDE FOR KAFKA STREAMS
- CONFIGURING A STREAMS APPLICATION
- Kafka Documentation - 3. CONFIGURATION
スレッド数とインスタンス数
スレッド数とインスタンス数を増やすことで処理を並列化できます。
設定パラメータ:
- スレッド数
-
num.stream.threads- 初期設定:
1 - 推奨設定: タスク数と同数
- 補足: インスタンスごとに指定する
- 初期設定:
-
- インスタンス数
- 同一のアプリケーションID(
application.id)を指定して起動したインスタンスの個数
- 同一のアプリケーションID(
パラメータ値は、以下の点を考慮して決定します。
- 理想的には、タスク数(≒入力元TopicのPartition数)と同数のスレッドで並列処理すべき
- タスク数を超えるスレッドは使用されないので注意
- タスク数自体を増やしたい場合は、入力元TopicのPartition数を増やす
- サーバにはスレッド数と同数以上のvCPUを用意する
- vCPU数の多いサーバでは複数インスタンスを実行することも検討する
- 1個のJVM(1インスタンス)で多数のスレッドを実行するとガベージコレクションが頻繁に発生するため
Record Cacheのメモリ容量
State StoreのキャッシュであるRecord Cacheのメモリ容量を増やすことで処理を効率化できます。
設定パラメータ:
- Record Cacheのメモリ量
-
statestore.cache.max.bytes- 初期設定:
10485760(10MB) - 推奨設定: 処理内容に依存する
- 補足: インスタンスごとに指定した容量が、インスタンス内のスレッド間で均等に割り当てられる
- 初期設定:
-
Record Cacheのメモリ容量を増やすと、レコードのバッファリング量/キャッシュ量が増加するため、以下の効果があります。
- タスクのデータ処理効率が向上
- Output Stream (Sink Topic) の書き込み頻度が低下(ネットワークI/Oを削減)
- Change Log Topicの書き込み頻度が低下(ネットワークI/Oを削減)
- Local State Storeの読み出し/書き込み頻度が低下(ディスクI/Oを削減)
Record Cacheの詳細は以下をご参照ください。
RocksDBの設定
Local State Storeのデータを保持するRocksDBもチューニング可能です。本稿では説明しませんが、詳しく知りたい場合は以下をご参照ください。
スタンバイレプリカの個数
State Storeのスタンバイレプリカを用意することで、リバランス発生時のState Store再構築時間を短縮できます。
パラメータ設定:
- スタンバイレプリカの個数
-
num.standby.replicas- 初期設定:
0 - 推奨設定:
1
- 初期設定:
-
Exactly-once処理の設定
Streamsアプリケーションにおけるレコードの重複処理を防ぐ。
パラメータ設定:
- 処理保証
-
processing.guarantee- 初期設定:
at_least_once - 推奨設定:
exact_once_v2-
exactly_once_v2を使用するにはKafka バージョン2.5.x以降かつ、3台以上のBrokerが必要
-
- 初期設定:
-
ProducerとConsumerの設定
Kafka Streamsが内部で使用するProducerとConsumerの設定をチューニング可能です。各パラメータの適切な値は処理内容に依存するため、実機で検証することを推奨します。
主な設定:
- Producerのデータ複製確認
-
acks- 初期設定:
all - 推奨設定:
all
- 初期設定:
-
- Producerのバッファメモリ
-
buffer.memory- 初期設定:
33554432(32MB)
- 初期設定:
-
- Consumerのフェッチサイズ
-
fetch.max.bytes- 初期設定:
52428800(50MB)
- 初期設定:
-
- Consumerのフェッチ待機時間
-
fetch.max.wait.ms- 初期設定:
500(500ms)
- 初期設定:
-
- ProducerとConsumerのTCP送信バッファ
-
send.buffer.bytes- 初期設定:
131072(128KB)
- 初期設定:
-
- ProducerとConsumerのTCP受信バッファ
-
receive.buffer.bytes- 初期設定:
32768(32KB)
- 初期設定:
-
- Kafka StreamsがPartitionごとにバッファリングするレコードの最大数
-
buffered.records.per.partition- 初期設定:
1000
- 初期設定:
-
Topicのデータ複製設定
本番環境ではTopicのデータ消失を防ぐために、データ複製の設定は必須となります。データを複製するとデータの耐久性は増加しますが、書き込み性能は低下します。
なお、これらはKafka Streams固有の設定ではありません。
Topicの設定:
- Partitionの複製数
-
replication.factor- 初期設定:
-1(Broker設定を使用) - 推奨設定:
3
- 初期設定:
-
- Recordの最小複製数
-
min.insync.replicas- 初期設定:
1 - 推奨設定:
2
- 初期設定:
-
おわりに
本稿ではKafka Streamsの内部動作とチューニングのポイントを紹介しました。次回はKafka Streamsの具体的な構築手順を紹介します。複数台のサーバでクラスタを構築して、Kafka Streamsのチューニングを行い、スケールアウトとフォールトトレランスの動作を確認します。