「いつか勉強しよう」と人工知能/機械学習/ディープラーニング(Deep Learning)といったトピックの記事の見つけてはアーカイブしてきたものの、結局2015年は何一つやらずに終わってしまったので、とにかく一歩でも足を踏み出すべく、 本質的な理解等はさておき、とにかく試してみる ということをやってみました。
試したのは、TensorFlow、Chainer、Caffe といった機械学習およびディープラーニングの代表的なライブラリ/フレームワーク3種と、2015年に話題になったディープラーニングを利用したアプリケーション2種(DeepDream、chainer-gogh)。

(DeepDreamで試した結果画像)
タイトルに半日と書きましたが、たとえばTensorFlowは環境構築だけなら10分もあれば終わるでしょうし、Chainerなんてコマンド一発なので5秒くらいです。Caffeは僕はハマりましたが、うまくいった最短手順を書いているので、同じ環境の方はすんなりいくかもしれません。
おすすめは、Chaffe & DeepDream(要Caffe)は飛ばして、TensorFlow, Chainer&画風変換を試す コースです。環境構築にハマらないので簡単に終わると思います(実行時間はかかりますが)。僕のように「気にはなってたけど全然触ってない」という方はぜひ今日の昼休みにでもお試しください!
試した環境:
- Mac OS X 10.11.1 El Capitan
- Xcode 7.2 インストール済み
TensorFlow
2015年11月に発表された、Google製の機械学習ライブラリ。「テンソルフロー」と読むそうです。同社のサービスでも実際に使われているとのこと。
よく話を聞く音声認識や翻訳だけでなく、Googleフォトの被写体認識や顔認識、ウェブ検索結果の最適化、Gmailのメール分別、新生メールソフトInboxの自動返信文作成、さらにYouTubeや広告事業まで、ほとんどのプロダクトを支える新たな根幹技術となっています。
TensorFlow の特徴は、データフローグラフとして表せればなんでも処理でき、その気になればローレベルのオペレータも手書きできる汎用性、Googleの実製品で使われる高いパフォーマンス、CPUでもGPUでも走りノートPCから巨大なデータセンターまで同じコードで動きモバイル端末にもデプロイできるスケーラビリティ、計算機科学の研究から実プロダクトまで扱える効率性、ドキュメンテーションやサンプルが揃いPythonでもC++でも書ける扱いやすさなどなど。
オープン化の狙い
ライセンスは商用利用も可能な Apache 2.0 で、自社製品のコアにもなっているこんなすごいものをなぜ Google はオープン化したのか?というところは気になるところです。
TensorFlowをオープンソース化することで、学術研究者からエンジニア、趣味として取り組むユーザーまで、あらゆる人々の機械学習コミュニティーが、研究論文よりも動作するコードを介してアイデアを格段にすばやく交換できるようになると期待している。これが機械学習に関する研究の促進につながり、最終的に技術がすべての人々にとってより適切に機能するものになるだろう。さらに、TensorFlowの応用分野は機械学習だけにとどまらない。タンパク質のフォールディングから宇宙データの処理にいたるまで、非常に複雑なデータの解明に取り組むあらゆる分野の研究者らにとって有用であるかもしれない。
Googleいわく、機械学習はこれからの画期的なプロダクトや技術に欠かせない重要な要素となるもので、世界中で研究が進められているものの、標準となるツールが存在していないことが課題。Google では TensorFlow を研究者から学生、製品開発者まで使える標準ツールとして提供することで、機械学習や機械知能そのものの研究と普及を加速したい考えです。
環境構築手順(所要時間:10分)
OS X El Capitan (10.11.1) へのインストール手順です。
1. pip をインストール
$ sudo easy_install pip
2. Virtualenv をインストール
$ sudo pip install --upgrade virtualenv
3. Virtualenv 環境を作成
$ virtualenv --system-site-packages ~/tensorflow
(上記コマンドだと ~/tensorflow につくられる)
4. つくった環境をアクティベート
$ source ~/tensorflow/bin/activate
→ コマンドプロンプトが変わる
5. TensorFlow をインストール
$ pip install --upgrade tensorflow
$ pip3 install --upgrade tensorflow
Successfully installed appdirs-1.4.0 numpy-1.12.0 packaging-16.8 protobuf-3.2.0 setuptools-34.2.0 tensorflow-1.0.0 wheel-0.29.0
以上です。
動作確認:Hello World を実行してみる
スクリプトを作成し、適当なファイル名で保存します。
import tensorflow as tf
import multiprocessing as mp
core_num = mp.cpu_count()
config = tf.ConfigProto(
inter_op_parallelism_threads=core_num,
intra_op_parallelism_threads=core_num )
sess = tf.Session(config=config)
hello = tf.constant('hello, tensorflow!')
print sess.run(hello)
TensorFlow 環境で実行します。
(tensorflow)$ python {ファイル名}.py
実行結果:
I tensorflow/core/common_runtime/local_device.cc:25] Local device intra op parallelism threads: 4
I tensorflow/core/common_runtime/local_session.cc:45] Local session inter op parallelism threads: 4
hello, tensorflow!
参考ページ:
手書き数字を学習してみる
TensorFlow オフィシャルページに、「MNIST For ML Beginners」という手書き文字データセットを利用したチュートリアルがあります。

(MNISTデータセット)
ここでは一番手っ取り早そうな、公式チュートリアルのコード(GitHubにある)を実行する方法を試すことにします。
ソースコードを clone してきて、
$ git clone --recurse-submodules https://github.com/tensorflow/tensorflow
fully_connected_feed.py の30,31行目を次のように修正します。1
- 修正前
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.examples.tutorials.mnist import mnist
- 修正後
import input_data
import mnist
fully_connected_feed.py を実行します。
$ cd tensorflow/
$ python tensorflow/examples/tutorials/mnist/fully_connected_feed.py
MNISTデータセットを手動でダウンロードしたりする必要はなく、このスクリプトがデータセットの取得からモデルの学習までやってくれます。
実行結果:
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Extracting data/train-images-idx3-ubyte.gz
//中略
Step 0: loss = 2.32 (0.025 sec)
Step 100: loss = 2.19 (0.003 sec)
Step 200: loss = 1.97 (0.003 sec)
//中略
Step 1900: loss = 0.46 (0.004 sec)
Training Data Eval:
Num examples: 55000 Num correct: 49489 Precision @ 1: 0.8998
Validation Data Eval:
Num examples: 5000 Num correct: 4534 Precision @ 1: 0.9068
Test Data Eval:
Num examples: 10000 Num correct: 9019 Precision @ 1: 0.9019
データセットのダウンロード、トレーニング、テストデータでの評価が行われています。最終的な精度は約90%。
参考ページ:
- http://nextdeveloper.hatenablog.com/entry/2015/11/10/204609
- http://qiita.com/sergeant-wizard/items/fdf4d64a0d221a81da34
学習結果を可視化する TensorBoard を試す
なんと、学習結果をグラフにしてくれたり、モデルをビジュアライズして表示してくれる TensorBoard というものも用意してくれているようです。
学習経過のログデータのあるディレクトリを絶対パスで指定 2 して tensorboard コマンドを実行すると、
$ tensorboard --logdir=/Users/xxxx/xxxx/tensorflow/tensorflow/data
TensorBoard が起動します。
Starting TensorBoard on port 6006
(You can navigate to http://localhost:6006)
で、このURLにブラウザからアクセスするとGUIが表示され、
学習回数とxentropy_mean(交差エントロピー)の関係を示すグラフや、
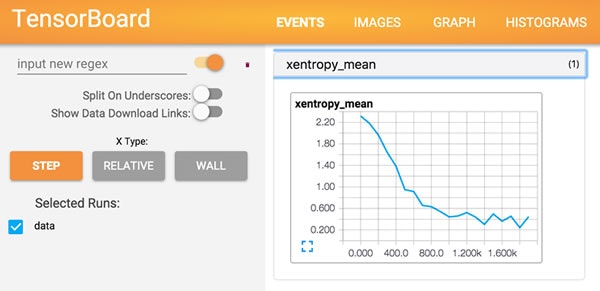
モデル(ニューラルネットワーク)を可視化したものを見ることができます。

More
- http://qiita.com/shuhei_f/items/9251084b00ed9319033e
-
http://qiita.com/uramonk/items/c207c948ccb6cd0a1346
- チュートリアルのコードをコメントで解説してくれています
-
http://qiita.com/haminiku/items/36982ae65a770565458d
- 上級チュートリアルの解説もあり
-
http://d.hatena.ne.jp/sugyan/20151124/1448292129
- 学習結果を使って自分で書いた数字を識別してもらうところまで試されています
- コードも公開
Chainer
Preferred Networks社が開発したニューラルネットワークを実装するためのライブラリ。2015年6月公開。特徴としては、
- Python のライブラリとして提供
- あらゆるニューラルネットの構造に柔軟に対応
- 動的な計算グラフ構築による直感的なコード
- GPU をサポートし、複数 GPU をつかった学習も直感的に記述可能
が挙げられています。
TensorFlow との比較
上記特徴を見ると TensorFlow とポジショニング的には似ているように見えたので、どんな違いがあるのかググッてみました。
たぶんできることそのものに大きな違いはないんだろうけど、Chainerの場合マルチGPUにするときには自分でGPUの管理をしなきゃなんないのが、TenrorFlowだともうちょっとラクなのかなあと思ったりする。
TensorFlow、GPU使うのにリビルドが必要で、そのためにbazelが必要で、そのためにJava8が必要で、しかもGPUにCC3.5以上の制約があるみたいで、使えるなら使えば?感が凄い。同じPythonならChainerの方が敷居が低く感じる。
TensorFlowはDistBeliefの2倍の速いそうなのですが、Chainerはそれを上回っていました。
記述量的にはそこまで変わらないですし個人的にはChainerの方が扱い易いというのが感想です(慣れの問題だとは思いますが。)。
TensorFlow,Chainerとも精度は同じでした。そもそもMNISTは問題が簡単なのでDeep Learningでなくても高い精度が出るそうです。実行時間はChainerの方が速かったのです。
インストール手順(所要時間:5秒)
公式ドキュメントに Install Guide というページがあるのですが、Ubuntu, CentOS 向けに書かれているようなので、Mac向けのはないかなと探してたら、本家Webサイトに QUICK START という項目がありました。
やることは
$ pip install chainer
これだけ。
Successfully installed chainer-1.5.1 filelock-2.0.5
素晴らしい!
手書き数字を学習してみる
公式リポジトリにサンプルが用意されています。cloneしてきてスクリプトを実行するだけ。
$ git clone https://github.com/pfnet/chainer.git
$ python chainer/examples/mnist/train_mnist.py
MNISTデータセットのダウンロードと、学習、テストが行われます。
load MNIST dataset
Downloading train-images-idx3-ubyte.gz...
(中略)
epoch 1
graph generated
train mean loss=0.190947790003, accuracy=0.942850003242
test mean loss=0.0990746175707, accuracy=0.96930000484
(中略)
epoch 20
train mean loss=0.0104963570454, accuracy=0.996966669559
test mean loss=0.102703116325, accuracy=0.982000006437
最終的な識別精度は98%になったようです。
More
- http://cvl-robot.hateblo.jp/entry/2015/06/11/223928
- http://hi-king.hatenablog.com/entry/2015/06/11/021144
- http://hi-king.hatenablog.com/entry/2015/06/27/194630
- http://qiita.com/icoxfog417/items/96ecaff323434c8d677b
- http://qiita.com/mokemokechicken/items/cc9b2c96f6e4a43c123c
- http://d.hatena.ne.jp/shi3z/20150628/1435502562
- http://studylog.hateblo.jp/entry/2015/07/14/000635
Caffe
C++で実装されたディープラーニングのオープンソースライブラリ。カリフォルニア大学バークレー校の研究センターBVLCが中心となって開発、C++・Python・MATLABで利用可能。
具体的な公開日はわかりませんが、ChainerやTensorFlowの登場以前から存在する分、ネットで見つかるおもしろそうなディープラーニングを利用した研究や試みはCaffeをベースにしたものを多く見かける気がします。
環境構築手順(所要時間:約4時間)
所要時間は個人差(環境差)があると思いますが、確実にTensorFlowやChainerよりは時間がかかる と思います。依存ライブラリが多く、その中にはインストールの待ち時間が長いものがありますし、各自の環境に依存した設定を手動で行う必要があるので、そのあたりでハマることもあると思います。また個人的にはnumpyのバージョンが違うというエラーにかなり悩まされました。
GPUが絡むとハマりそうなのでCPUモードで、インストールしていきます。PyCaffeも入れます。
1. 諸々インストール
$ brew install --fresh -vd snappy leveldb gflags glog szip lmdb
$ brew tap homebrew/science
$ brew install hdf5 opencv
$ brew install --build-from-source --with-python --fresh -vd protobuf
$ brew install --build-from-source --fresh -vd boost boost-python
$ brew install openblas
※1 opencv のインストールはかなり時間がかかります。
※2 OpenBLAS は入れなくてもいいそうですが(Macでは標準でBLASが入っているとのこと)、この後の手順で Makefile の BLAS_INCLUDE のパスを修正したりしてから make を実行しても fatal error: 'cblas.h' file not found が出てしまうので、入れることにしました。
2. caffe をclone
$ git clone https://github.com/BVLC/caffe.git
3. Makefile.config 作成
雛形からコピーしてきて、編集します。
$ cd caffe
$ cp Makefile.config.example Makefile.config
-
# CPU_ONLY := 1のコメントアウトを外す -
BLAS := atlasをBLAS := openに変更する - 以下のコメントアウトを外す
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
-
PYTHON_INCLUDEのパスを自分の環境に合わせて書き換える 3- 修正前
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/lib/python2.7/dist-packages/numpy/core/include
- 修正後
PYTHON_INCLUDE := /usr/local/Cellar/python/2.7.11/Frameworks/Python.framework/Versions/2.7/include/python2.7 \
/usr/local/lib/python2.7/site-packages/numpy/core/include/
4. ビルド&テスト
$ make clean
$ make all -j4
$ make test -j4
$ make runtest
ここでエラーがでなければインストール成功です。
[ PASSED ] 927 tests.
5. PyCaffe に必要なライブラリをインストール
caffe/python フォルダに移動し、PyCaffe に必要なライブラリをインストールします。
$ cd python/
$ for li in $(cat requirements.txt); do sudo pip install $li; done
6. PyCaffe のビルド
$ cd ../
$ make pycaffe
$ make distribute
7. 環境変数を設定
Caffe用の環境変数を設定します。~/.bashrc に下記を追記し、
export PYTHONPATH={caffe/pythonのパス}:$PYTHONPATH
source ~/.bashrc で反映します。
8. 動作確認
PythonのインタプリタからCaffeをimportしてみて、問題が起きなければOK。
$ python
>>> import caffe
ちなみに本記事では最終的にうまくいった手順のみを書いていますが、大いにハマったトラブルシューティングの過程 も別記事として書いておきました。
参考ページ:
- http://caffe.berkeleyvision.org/install_osx.html (公式ページ)
- http://qiita.com/t-hiroyoshi/items/3bba01dd11b1241f1336
- http://qiita.com/knao124/items/c76e974cfbaabb5542e8
- http://ichyo.jp/posts/caffe-install/
DeepDream
ここからひとつレイヤーは上がって、ディープラーニングライブラリ/フレームワークを利用した応用アプリケーション的なものをいくつか試してみます。
DeepDream は 2015年7月にGoogleが公開 したOSSで、
画像から少しでも見覚えのある物体を見つけ出し、それを再構成して出力する
人工神経回路網は10~30のレイヤーから構成されており、1枚目のレイヤーは画像の情報をインプットして「角」や「端」を探し、2枚目・3枚目と続くレイヤーは基本的な物体の情報を把握、最終的なレイヤーが情報を組み立てて物体が「何か」を判断する、という仕組みです。
というもの。
環境構築の手順(所要時間:10分)
要Caffe(インストール手順は上述)。Caffeさえ入っていればさっくり試せます。
1. iPython notebook をインストール 4
$ pip install ipython
$ pip install ipython[notebook]
2. DeepDream を clone
Caffe のあるフォルダと同階層に DeepDream のソースを clone します。
$ git clone git@github.com:google/deepdream.git
3. モデルをダウンロード
ここ から学習済みのcaffeモデルをダウンロードし、{caffeのパス}/models/bvlc_googlenet/ に保存します。
試す
cloneしてきたdeepdreamフォルダに移動し、iPython notebookを起動します。
$ cd deepdream
$ ipython trust dream.ipynb
$ ipython notebook
ブラウザが立ち上がるので、dream.ipynb を選択して、上部にある再生ボタンをポチポチ押していき、最後まで到達したらしばらく待っていると・・・ deepdream/frames/ フォルダに結果画像が 0000.jpg, 0001.jpg, ...と出力されていきます。

(左:0000.jpg と、右 0010.jpg)
手っ取り早く好きな画像で試したい場合は、sky1024px.jpg にリネームして同じ場所に置いておけばOKです。または dream.ipynb の画像名を指定している箇所を編集します。
さわやかな食事風景が、

こうなりました。
参考記事:
- http://qiita.com/t-hiroyoshi/items/e556c4ca0e8631556584
- http://qiita.com/icoxfog417/items/175f69d06f4e590face9
画風変換アルゴリズム chainer-gogh
mattya氏が2015年9月に公開した、Deep Neural Networkを使って画像を好きな画風に変換できるプログラム。
Chainerを利用。アルゴリズムの元論文は A Neural Algorithm of Artistic Style 。
環境構築の手順(所要時間:1分)
1. ソースを clone
$ git clone https://github.com/mattya/chainer-gogh.git
2. モデルをダウンロード
モデルを下記URLからダウンロードし、cloneしてきた chainer-gogh フォルダ配下に置きます。
実行する
お手軽にCPU実行してみます。コンテンツ画像(input.png)とスタイル画像(style.png)を用意して chainer-gogh フォルダ配下に置き、スクリプトを実行するだけ。
python chainer-gogh.py -m nin -i input.png -s style.png -o output_dir -g -1

(左:input.png、右:style.png)

(結果画像)
今後の展望
今回は環境構築と既に用意されているサンプルを実行してみただけなので、次のステップとしては、下記記事の例のように、OpenCVを活用して自前データセットつくって、Chainer なり TensorFlow なりで画像識別をやってみたいと思っています。
- http://bohemia.hatenablog.com/entry/2015/11/22/161858
- http://bohemia.hatenablog.com/entry/2015/11/22/174603
ただデータセット収集はそれなりに時間かかりそうなので、下記記事のように既存のデータセットを Chainer および TensorFlow に食わせるところから始めるのが現実的かも。
また、iOSエンジニアとしては、モバイルデバイスでの利用についても模索したいと思っています。
あらかじめ学習済みモデルを用意して識別専用として利用するだけなら可能なのか、学習機能自体をモバイル側でやってみたらどんだけ重いのか(そもそもできるのか)とか。TensorFlow は「モバイル端末にもデプロイ可能」と謳ってますし。
あと、画像以外にも、自然言語処理への利用等も試してみたいです。
おわり。
関連記事
-
これをやらないと、実行時に "ImportError: No module named examples.tutorials.mnist" というエラーが出ます。 ↩
-
パスが間違ってても TensorBoard は起動するのですが、アクセスしてもグラフ等は表示されません。 ↩
-
/usr/includeが最近のOSXでなくなってることに関しては、$ xcode-select --installをすればいいみたいなのですが、古いコマンドラインツールをダウンロードしないといけないっぽく、あまりXcodeまわりの環境をいじりたくないので直接pythonのincludeパスを指定するようにしました ↩ -
なぜか ipython: command not found になったので こちら を参考にインストールしなおしました ↩