「機械学習」というワードになんとなく惹かれつつも、具体的にやりたいことがあるわけでもないので、手を動かすことなくただひたすら**「いつかやる」**ために解説記事やチュートリアル記事を集める日々を過ごしていたのですが、このままじゃイカン!と Machine Learning Advent Calendar に参加登録してみました。
が、やはり何もしないまま当日を迎えてしまったので、お茶濁しではありますが、せめて「機械学習ってどんな手法やライブラリがあって、どんな応用先があるのか?」というあたりをざっくり把握して最初に何をやるのか方向付けをするためにも、たまりにたまった機械学習系の記事をいったん整理してみようと思います。
機械学習の概要
特定のライブラリや手法の話ではなく、機械学習全般に関する解説。
機械学習チュートリアル@Jubatus Casual Talks
冒頭に、
- 初めて機械学習を聞いた⼈人向けです
- 数式を使いません
- ガチな⼈人は寝てて下さい
とある通り、**機械学習ってそもそも何?どう嬉しいの?**というところがスタート地点である自分にとってすごくありがたかったスライド。
ざっくり目次的なものをまとめると(かなり抜粋)、
- 機械学習って何?
- 例: スパム判定、商品推薦、コンピュータ将棋・囲碁・チェス
- その他適用分野
- 機械学習が向かないタスク
- ルールベースとの比較
- 機械学習って何してるの?
- 教師あり・教師なし学習とは?両者の目的の違い
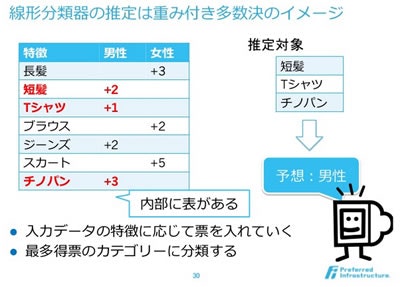
- 線形分類器(図解がわかりやすかった)
Python / scikit-learn
Python で機械学習しよう!(環境構築 on Mac編)
Mac 上に Python で数値計算、機械学習を行うための環境構築の手順。全編スクショ付きですごくわかりやすいです。(が、あくまで環境構築手順だけで、実際に機械学習を行ってみるところまではカバーされていません)
インストールする数値計算、機械学習ライブラリは以下の4つ。
-
NumPy
数値計算を効率的に処理するためのライブラリです
配列の操作がとても簡単になるので、行列計算には必須っぽいです -
SciPy
様々な科学計算が実装されたライブラリです
内部でNumPyを利用しています -
matplotlib
グラフ描画のライブラリです
内部でNumPyを利用しています -
scikit-learn
機械学習に関する様々なアルゴリズムが実装されたライブラリです
機械学習の Python との出会い
NumPy や SciPy などの科学技術計算モジュールの具体的な使い方を学べるチュートリアル。PDF版やePub版も用意されていて、もはや書籍。
前書きにもある通り、機械学習のごくごく初歩的な話とか、Pythonのごくごく初歩的な話は省略されているので、はじめの二歩目ぐらいに目を通すとよさそうです。
このチュートリアルでは,いろいろな機械学習の手法を Python で実装する過程をつうじて,NumPy や SciPy など科学技術計算に関連したモジュールの具体的な使い方を説明します. 機械学習の手法についてはごく簡単な説明に留めますので,詳細は他の本を参考にして下さい. また,クラスなどのプログラミングに関する基礎知識や,Python の基本的な文法については知っているものとして説明します.
目次
-
はじめに
- 本チュートリアルの方針
-
単純ベイズ:入門編
最初に実装するのは,特徴量がカテゴリ変数である場合の単純ベイズ (Naive Bayes) です. この単純ベイズの実装を通じて,NumPy / SciPy を用いた行列・ベクトルの初歩的な扱いについて説明します.
- NumPy 配列の基礎
- 単純ベイズ:カテゴリ特徴の場合
- 入力データとクラスの仕様
- 学習メソッドの実装(1)
- 予測メソッドの実装
-
単純ベイズ:上級編
単純ベイズ:入門編 で実装した NaiveBayes1 クラスを,NumPy のより高度な機能を利用して改良します. その過程で,NumPy の強力な機能であるブロードキャストの機能と,この機能を活用する手順を紹介します.
- クラスの再編成
- 単純ベイズの実装 (2)
- 配列の次元数や大きさの操作
- ブロードキャスト
- クラスの分布の学習
- 特徴の分布の学習
- 実行速度の比較
pythonの機械学習ライブラリscikit-learnの紹介
Python の機械学習ライブラリ scikit-learn のチュートリアル。scikit-learn でできること(機能)がカタログ的に紹介されています。
それぞれの機能について簡単なサンプルコードと実行結果が示されているので、色々とつまみ食い的に試してみるのによさげ。
- サンプルデータの自動生成
sklearnにはIrisなどのトイデータセットやサンプルデータの自動生成などの機能もあります。
(0のデータ)
-
線形SVMによる二値分類
データをトレーニング用とテスト用に分けて、トレーニングデータで訓練したモデルでテストデータを予測してみます。
-
分類結果の評価
分類器で得られた推定結果がテストデータとどれぐらい一致しているかでモデルの評価を行います。
- Confusion Matrix
- Accuracy (正解率)
- Classification Report
- Precision Recall curve
- ROC Curve
-
クロスバリデーション(交差検定)
上のほうで二値分類を試すときにデータをトレーニング用とテスト用に分解しました。しかし、データを分けるとそれぞれに使えるデータが少なくなってしまいます。
クロスバリデーションではデータをいくつかに分割して、1個をテスト用、残りをトレーニング用に使ってスコアの計算をします。このとき分けられたデータのすべてがテストに選ばれるようにくりかえし評価を行い、そのスコアの平均を使って評価をします。 -
グリッドサーチ
適切なパラメータを選ぶのによく使われるのがグリッドサーチという方法で、これはいくつかのパラメータの組み合わせを実際に試して評価関数を計算し、スコアがよかったパラメータを選ぶというものです
-
不均衡データ
ラベルごとのデータ数が大きくアンバランスなデータだと学習がうまくいかないときがあります。たとえば正例:負例=1:100とかだったりすると、十分なデータがあっても訓練したモデルはすべてを負例に分類してしまったりします。こういうときはクラスに対する重み(LinearSVCならclass_weight)を変えたりresample関数を使ってトレーニングデータ内の比率が1:1に近くなるようにアンダーサンプリングやオーバーサンプリングをしたりすると結果がよくなることがあります。
-
特徴量の抽出
分類器のモデルの入力(データのベクトルによる表現)をどうやって作るかという話
scikit-learnを用いた機械学習チュートリアル
scikit-learn のチュートリアルスライド。
スライドというメディアの特性上、コードは少なく図が多いので、上の「pythonの機械学習ライブラリscikit-learnの紹介」に出てくる機能の補助資料として読むとよさそうです。
Deep Learning
はじめるDeep learning
ずっと「ディープラーニング」というキーワードは「何かすごそう」ぐらいに気にはなってて意味はわかってなかったのですが、冒頭の説明が超わかりやすかったです。
つまるところ、Deep learningの特徴は「特徴の抽出までやってくれる」という点に尽きると思います。
例えば相撲取りを判定するモデルを構築するとしたら、普通は「腰回りサイズ」「マゲの有無」「和装か否か」といった特徴を定義して、それを元にモデルを構築することになります。ちょうど関数の引数を決めるようなイメージです。
ところが、Deep learningではこの特徴抽出もモデルにやらせてしまいます。というか、そのために多層、つまりDeepになっています。
具体的には頭のあたりの特徴、腰のあたりの特徴、そしてそれらを複合した上半身の特徴・・・というように、特徴の抽出を並列・多層に行って学習させて、それでもって判定させようというのが根本的なアイデアです
技術の詳細説明はさくっと読み飛ばしてしまいましたが、deep learning の代表的なライブラリも挙げられていました。
- pylearn2
- Caffe
- nolearn
- deepnet
- yusugomori/DeepLearning
通常なら最新の実装も搭載されているpylearn2、画像認識ならCaffeらしいです(経験者談)。
研究やとりあえず試してみる場合に必要になる学習データを提供してくれているサイトのリストもまとめられていて、即ストックさせていただきました。
最後に pylearn2 を用いた実践手順もあり。
Deep learning
いろいろなところからリンクされていたスライド。Deep Learning の手法について図解でわかりやすく解説 ・・・されているはずなのですがちょっとよくわからなかったのでまた読もうと思います。
一般向けのDeep Learning
専門家向けではなく、一般向けに Deep Learning について説明してくれているスライド。
RBMから考えるDeep Learning ~黒魔術を添えて~
たぶん全然はじめの一歩ではないのですが、かなり詳しく書かれていて、実装についても追記される(2014年12月9日現在未完とのこと)なので、deep learning がちょっとわかってきた頃にまたあとで読むと勉強になりそうだなと。
Pythonとdeep learningで手書き文字認識
Python の Deep Learning ライブラリ、THeano を使用して手書き文字認識。前段の Deep Learning 自体の解説も噛み砕かれていて、わかりやすそうです。
Theano の 基本メモ
Deep Learning ライブラリ、THeano のチュートリアル。
Weka
機械学習(データマイニング)ソフトのWeka。Mac版もあり。

とある知り合いの大学院生が使っていて、GUIをポチポチしていくだけであらかじめ実装されている各種アルゴリズムによりデータが自動分類されていくという様子を目の当たりにして、今度自分も試してみよう、と思い記事だけ集めて今に至ります。
※ちなみにデータマイニングと機械学習を混同するのはよくなさそうで、Wekaはどっちかというとデータマイニングの文脈っぽいですが、せっかくなので一緒に整理しておきます。
Weka入門 〜決定木とデータセットの作り方〜
インストール〜実際にデータを分析するまでのチュートリアル。全編スクショ付きで非常にわかりやすそうです。Windows版ですが、たぶんMacでもほぼ同じかと。
決定木をつくる、入力データを用意する、のあたりはあらかじめ用意されているサンプルデータを使用するのですぐに試せるし、分析結果の見方も解説されているので、とりあえずプログラミングなしで体験してみるのによさそうです。
Wekaを起動する
- どうマイニングする?
- 決定木分析①
- 決定木分析②-1
- 決定木分析②-2
- 決定木分析③予測する
- 決定木分析④因果関係を知る
- 記憶ベース推論①
- 記憶ベース推論②
- ニューラルネット
- 複数の分析を行う
- アソシエーション分析①
- アソシエーション分析②
- ROC曲線とlift chart 補足1
- 補足 研究開発部門での使用
- 関連リンク集
- データマイニング入門
リンク先に、これらの内容を再構成してまとめられたPDFもあります。
はじめてのweka勉強会 -修正版-
arff形式のデータをテキストエディタで自分でつくってみる、クラスタリングするプログラムを書いてみる、ちょっとソースをいじって手法を変えてみる、といった方法が説明されていて、Wekaを使う第2歩目ぐらいによさそうです。
応用・実例
機械学習は手法も応用も多岐にわたるので、具体的な応用・実用例も集めています。
Googleの猫認識 (Deep Learning)
ディープラーニングの記事を見ていると、事例として必ず出てくる、Googleの猫認識の話(ネコという概念を、コンピュータがYoutubeの動画を見続けることで自動学習したという話)について、この記事では、Deep Learning がどのように用いられているか、を噛み砕いて解説してくれています。

[機械学習革命2]常識破りのパターン認識
画像認識によって焼きたてパンの種類を判断できるレジ装置
- 購入客がパンをトレーに載せてレジ横にあるカメラの下に置くと、BakeryScanが撮影画像を基に、パンの種類を自動判断
-
準備作業として、パン1種類につき10個分の写真を撮影してBekaryScanに読み込ませる
- BakeryScanが10個分の画像から、あんパンやメロンパンなど種類ごとの「画像モデル」を自動的に生成
- 大きさや形、色、表面の状態、テクスチャーといった画像モデルの「特徴」は、B開発元があらかじめ100種類ほど設定
- 特徴の「重み」については、店が読み込ませたパンの画像データを機械学習して、BakeryScanが自動調整
低解像度の画像から、自動車のナンバープレートのナンバーを識別
- あるナンバープレートの画像について、高解像度のデータと低解像度に圧縮したデータをペアとして読み込ませて機械学習を行い、ナンバープレートの圧縮パターンの「辞書」を作成
- この辞書を逆引きすることで、低解像度の画像から高解像度の画像を類推・生成
- 自動車のナンバープレートのほか、人間の顔の圧縮パターンも機械学習させた
- 低解像度の監視カメラ画像の解像度を高め、写った人物の顔写真を正確に推測
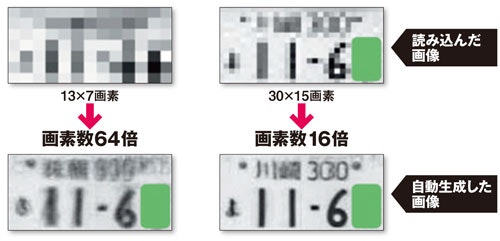
(元記事より)
英文の誤りを見つけ出し、ネイティブが書いたかのような文章に校正
- Lang-8が大量に保有する、非ネイティブである学習者が書いた「誤った文章」と、ネイティブの指導者が校正した「正しい文章」のペアのデータを利用
- これらペアのデータを100万件以上提供してもらい、機械学習させた
- 間違いのパターンや、その正答パターンをモデル化
- こうしたモデルを、新たな「間違った英文」に適用することで、誤り箇所とその正答候補を探し出す
- 現在の校正精度は36.2%
- 言語学者が人力でデータをつくり、機械学習させる従来手法の校正精度は23%程度だった
- データの件数を100倍以上に増やすことで、校正精度を13ポイント高めた
大規模AV画像データベースと類似顔画像検索を用いたAV検索システム
「顔画像をもとに似た顔の人が出ているAVを検索するシステム」について書かれた論文。
類似する顔の検索には、HOG 特徴 という特徴量を使用しているとのこと。
実装言語は Python、使用ライブラリは OpenCV, SciPy, Numpy。
[機械学習革命1]嘆く天才プログラマー
指し手を「機械学習」することで将棋アルゴリズムを自動生成
- 最新の将棋プログラムのアルゴリズムは、コンピュータがプロ棋士による数万局の対局データ(棋譜)を分析し、指し手を「機械学習」することで自動生成されたもの
- 過去の将棋プログラムのアルゴリズムは、プログラマーが将棋の知識と経験を駆使して手作りしていた
-
ある局面の有利さや不利さを、その局面の「特徴」と「重み」の積の合計として数値化
- 特徴とは、駒の種類や数、位置関係、王将の危険度といった要素
- 特徴ごとに重みが設定してあり、「金」なら400点、「飛車」なら700点、王将の近くに敵の駒がある場合はマイナス500点といった具合
- 機械学習によりこれらの重みを自動調整
大量のニュースから興味関心のある話題をベイジアン分類で抽出する
Ruby の naivebayes を使用。
あと、「フィードデータをためる方法」で触れられている Fastladder が気になりました。
金貨が本物かどうか見極める
scikit-learn で線形分離。
食べられるキノコを見分ける
K-Means クラスタリング
ねこと画像処理 part 2 – 猫検出
OpenCV の分類器作成
- Boosting でのモデル作成
- LBP特徴量を使用
ちなみにこのテーマについては前段として昨年書いたこの記事もよろしければ併せてお読みください:
最新記事のいいね!数を予測してみる
言語は Ruby、単語抽出に mecab 使用。
- 記事に含まれる単語をmecabで抽出
- → その記事のいいね!数に応じてその単語にポイントを付与
- → 単語ごとに出現数とポイントをデータベース化して教師データとする
ナイーブベイズでツンデレ判定してみた
twitter streamingAPIで突発的な流行語を抽出
東京都議会議員選挙の党派マニフェストを自動分類したよ
2009年7月12日投開票の東京都議会議員選挙において、主要6党(自民党、民主党、公明党、共産党、幸福実現党、生活者ネットワーク)の会派マニフェストに書いてある内容を品田方式と呼ばれる選挙研究で使う分類カテゴリに従い、分類したもの
分類作業は、stiqが研究している自然言語処理と機械学習*1の方法を用いて自動分類コーディングシステムを構築し、それを使っています。
具体的なシステムの仕組みは、論文にかかれているとのこと。
佐村河内識別システム
近年、自称作曲家・佐村河内守氏と外見の酷似した人物が増加し、彼らと佐村河内氏とを自動的に見分けるシステムの開発が望まれている。一方で、佐村河内氏は作曲時と謝罪会見時で大きく外見的に変化することが知られており、佐村河内氏を見分けるシステムはそのような変化に頑健である必要があるため、実現は容易ではない。本プロジェクトでは、高度なコンピュータ技術を活用し、佐村河内氏を適切に見分けるシステムを開発する。
以下2つの手法を適用したとのこと。
Fisher Vector Faces [Simonyan et al. BMVC 2013] では、一般の物体の認識に用いられる Fisher Vector (FV) と呼ばれる手法を顔画像へと適用し、顔のパーツを明示的にモデリングせずに、高精度の識別結果を記録した。顔の領域を検出し、顔の向きを合わせるなどの前処理を行った後は、ただ通常の物体認識と同様の手続きを適用するのみである。
DeepFace [Taigman et al. CVPR 2014] は Facebook 社の発表した研究であり、「ほぼ人間並みの識別能力を実現した」として大きな注目を集めた。こちらでは、顔検出と向きの補正を行った後に、Deep Convolutional Neural Networks (DCNN) と呼ばれる手法を用いて識別を行う。こちらも一般の物体の認識に用いられる手法であり、一部に独自の改良を施してはいるが、処理の大筋は顔画像に限るものではない。
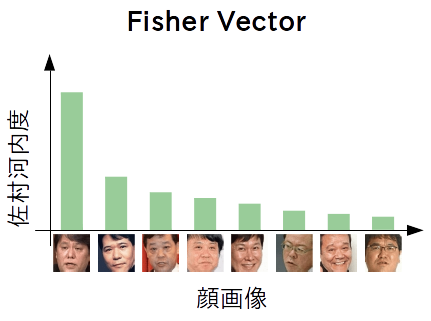
(すごい精度・・・!)