昨日は外部のニュースなどの情報を集めるためにフィードを利用する話をしました。
今日はその中で登場した Fastladder を実際に稼働させて、ニュースをデータベースに蓄積する話をします。
Fastladder を設置する
基本的に README.md を読めば良いです。
現在進行形で継続的に開発が進んでいるので、中途半端に二次三次の情報を参照するより、元のソースコードやドキュメントを読むということが要求されます。
Rails アプリケーションのセットアップ
とはいえざっくりと日本語で書いておきましょう。
まず git clone します。
git clone git://github.com/fastladder/fastladder.git
cd fastladder
一番簡単なのは SQLite かと思います。これをひな形からコピーして中身を適当に編集します。データベースの名前を簡単にしておくと良いでしょう。
cp config/database.yml.sqlite3 config/database.yml
次に Rails アプリのお約束である bundle install をし、データベースのマイグレーションをおこないます。
# vendor/gems を明示するのが筆者のオススメ
bundle install --path=vendor/gems
# データベースのマイグレーション
bundle exec rake db:create db:migrate
# rake のセットアップ
bundle exec rake setup
これで基本的には準備完了です。
foreman でプロセスを並列起動する
README にも書いてある通り、プロセスの起動には、複数のプロセスをとりまとめ並列起動することのできる foreman がオススメです。
foreman は Debian なら apt で入れることもできますが gem install foreman するとディストリビューションに関係なく導入できます。
Fastladder のディレクトリで次のように入力すると Web アプリケーションとクローラーの両方が起動します。
# ポート番号 3000 番にてバックグラウンドで起動する場合
foreman start -p 3000 &
foreman は Procfile に定義されているコマンドを並列実行します。また上記のようにポート番号をしていすると、そこから順番に 1 ずつ増分して並列プロセスを起動します。すなわち、ポート番号の指定は開始番号の指定をすることになるわけです。そこで普通は Web アプリケーションを一番上に定義して、クローラーのようなプロセスをそれに連動して動かすという方法を採ります。
$ foreman start -p 3000 &
23:01:48 web.1 | started with pid 24930
23:01:48 crawler.1 | started with pid 24931
23:01:49 web.1 | I, [2014-10-10T23:01:49.369166 #24930] INFO -- : Refreshing Gem list
23:01:55 web.1 | I, [2014-10-10T23:01:55.138615 #24930] INFO -- : listening on addr=0.0.0.0:3000 fd=10
23:01:55 web.1 | I, [2014-10-10T23:01:55.248082 #24939] INFO -- : worker=0 ready
23:01:55 web.1 | I, [2014-10-10T23:01:55.258821 #24930] INFO -- : master process ready
23:01:55 web.1 | I, [2014-10-10T23:01:55.260603 #24942] INFO -- : worker=1 ready
23:01:55 web.1 | I, [2014-10-10T23:01:55.262163 #24944] INFO -- : worker=2 ready
上記は foreman の起動例です。
この状態で Web アプリケーションが起動しますので、該当のポート番号にブラウザでアクセスします。
Fastladder を使ってみる
まずはブラウザで該当のホストへアクセスします。もしかしたらアドレスは localhost:3000 かもしれません。
すると次のようにログイン画面が表示されます。まだアカウントがありませんので新規アカウントを作成しましょう。
サインアップする
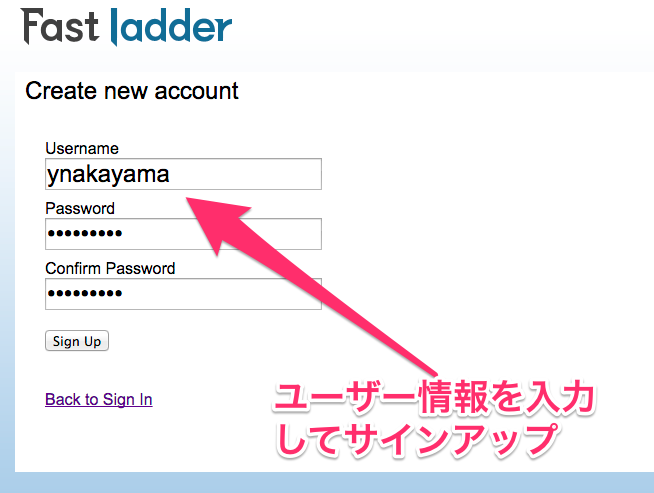
以下のように Create new account をクリックします。

するとサインアップの画面になりますので、自分の名前とパスワードを決めて入力します。
ログインできました。
次回以降はいま決めたユーザー名とパスワードでログインできます。
フィードを購読する
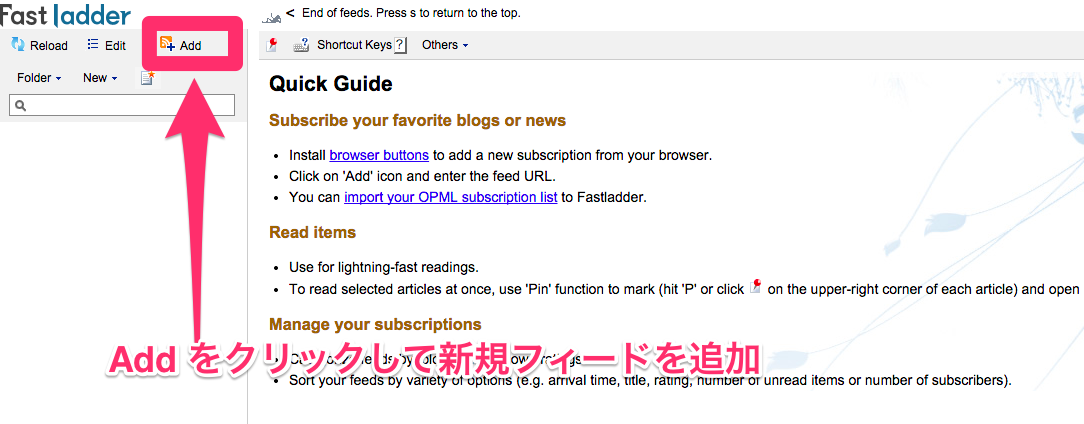
上の画像のように Add をクリックして新規フィードを購読しましょう。たとえば次のようなフィードの URL を入力します。
ライブドアニュース
http://news.livedoor.com/topics/rss.xml
はてなホットエントリー
http://b.hatena.ne.jp/hotentry.rss
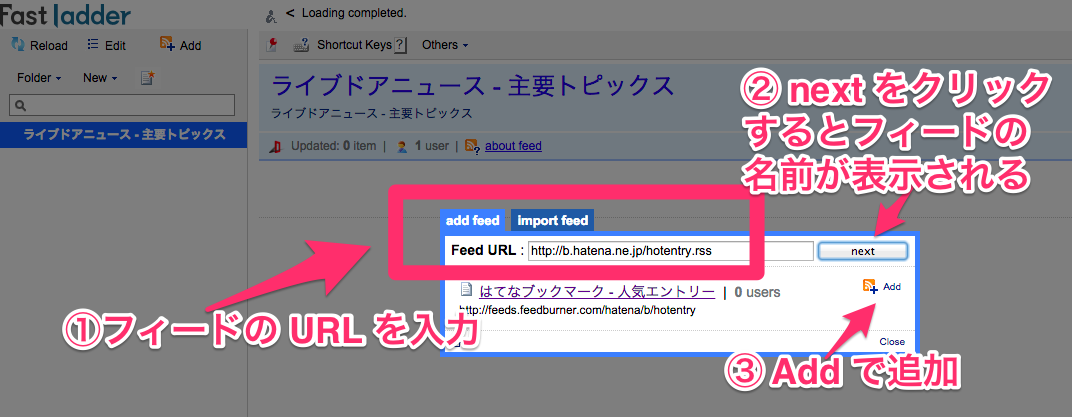
RSS/Atom フィードの URL を入力し next をクリックするとフィードの名前が表示されます。正しければ Add をクリックして購読しましょう。
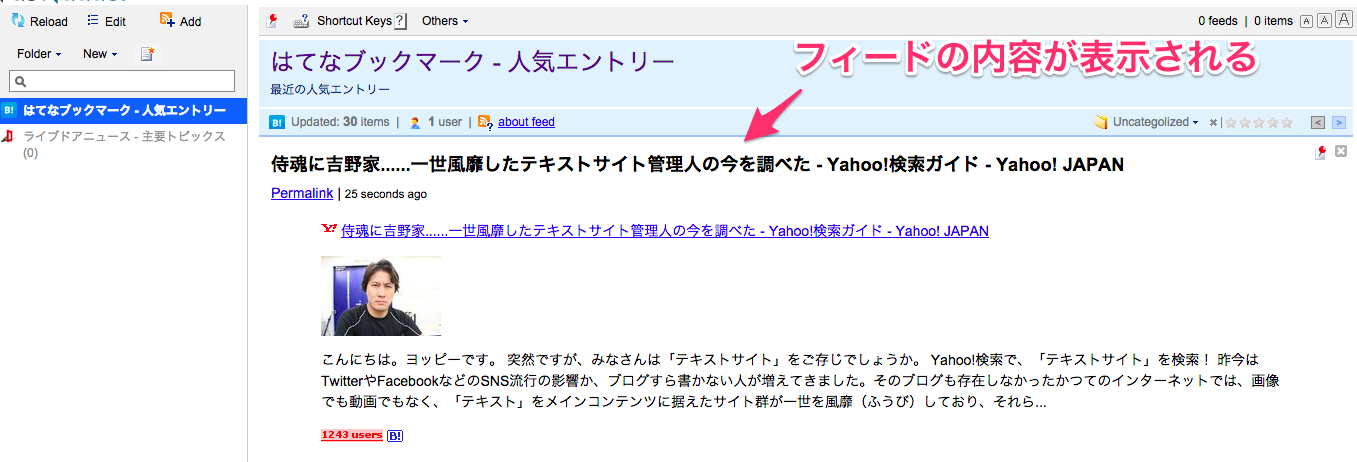
しばらくするとクローラーがバックグラウンドで動作しますから、上のようにフィードの内容を読むことができるようになります。
フィードを高速で読む
livedoor Reader や Google Reader を使ったことのある人にとっては直感的にピンと来るかもしれません。
操作の際、特にオススメなのはキーボード・ショートカットを多用してフィードを読むことです。
キーボードの j/k で次/前の記事へ、 s/a で次/前のフィードへ移動します。とりあえずこれだけ憶えておき、あとはどんどん使ってみると良いでしょう。
大量のデータをどうやって読むか
さて、このあと欲張って何百何千何万という大量のフィードを登録すると、すべて読むのは次第に困難になってきます。まだ読んでいない未読フィードがどんどんたまり、やがて消化しきれなくなって捨てる (一括で既読にする) ようになってしまいます。これではせっかく購読した意味がありません。
朝から晩まで休みなくソーシャルメディアに張り付いたり、または不眠不休で、あるいはそう見せかけて実は中の人が三交替制でインターネットウォッチングをしているような異常なタイプの人は、もしかしたら大量のフィードをすべて高速に読んでいるという人もいるかもしれません。
しかし、一般的なビジネスマンがこのようにたくさんの情報を読むというのは、いくらフィードリーダーがイケてるジャバスクリプトでサクサク高速に動くからといっても、普通は無理です。どう考えても時間がありません。
かといって登録するフィードをごくわずかに絞りますと、あくまで購読した少数のフィードが情報の源泉になるわけですから、観測範囲がせまくなってしまいます。
そこで、まず Fastladder のデータベースにあらかじめ外部のデータを大量に集めておきます。次に、データベースからテキストを直接抽出し、各人の興味嗜好を示す特徴となる情報を外部から与え、適合度の高い情報のみを拾いあげることができればこの問題を解決できそうです。
というわけで、次回はこのように各人の興味嗜好に基づいた情報の拾い上げを、ベイジアン分類と呼ばれる方法で実現するという話をします。