前回、前々回とベイズ統計に少し触れました。キュレーションなどを利用して展開されるインバウンド・マーケティングで取り扱うデータにおいては、不特定多数によって発信される多用なデータを処理するケースが多くなります。このようなシーンでは特にベイズ的なアプローチであるとか、ヒューリスティクな考え方を取り入れることになります。
RSS フィードを使う
インターネットにあふれる情報を入手するにあたり、たとえばニュースフィードを収集するだとか、 Twitter などのソーシャルメディアの発言を分析するといった方法があります。これらの中で最もポピュラーな手段で、古くからあるのが RSS (or Atom) フィードを利用する方法でしょう。
フィードの規格
RSS でよく使われる規格としては主に次の 3 種類があります。
RSS 2.0
http://www.rssboard.org/rss-specification
RSS 1.0
http://web.resource.org/rss/1.0/
RSS 0.91
http://www.rssboard.org/rss-0-9-1-netscape
ひとつ気をつける点としては、これらは単なるバージョンの差異ではなくて、それぞれ独立した規格だということです。歴史的経緯からこのようになっています。
Atom
https://tools.ietf.org/html/rfc4287
Atom も RSS と同様によく使われるフォーマットです。この RSS/Atom をすべてひっくるめてフィードと言います。よく RSS リーダーというふうに言葉で表現してしまいがちなのですが、厳密に言えば Feed Reader のように言ったほうが良いでしょう。
フィードリーダー
かつては無料で利用できるフィードリーダーとして Google Reader と livedoor Reader が二大候補だったのですが、 Google Reader は 2013/7/1 に、 livedoor Reader は 2014/12 にそれぞれ終了となりました。
Google Reader (のお知らせ)
http://www.google.com/reader/about/
livedoor Reader (のサービス終了のお知らせ)
http://blog.livedoor.jp/staff_reader/archives/52170245.html
Fastladder
Fastladder はもともと海外向けの livedoor Reader としてリリースされたのですが、現在ではオープンソースソフトウェアとしてソースコードが公開されており、有志の手によって現在でもメンテナンスや機能追加がおこなわれています。
Fastladder
https://github.com/fastladder/fastladder
livedoor Reader 終了に寄せて: Fastladder オープンソース版は GitHub で開発継続中です
http://blog.kyanny.me/entry/2014/10/03/011303
Fastladder は中身は Ruby on Rails アプリケーションなので、最低限 Rails アプリを開発・運用する知識があれば誰にでも取り扱うことができるでしょう。これをサーバーに設置してクローラーを動かせば、自分だけのフィードリーダーとして利用することもできます。
自前で設置できるので、サービスの終了ということを特に気にしなくて良いというメリットがあります。何もかも自己責任で運用できるのも、人によってはメリットになるかもしれません。
ただし、開発中ということもありじゃっかん荒削りな部分がありますので、セキュリティや信頼性を確保したいという場合は、もうひと工夫したほうが良いのではないかと筆者は思います。
Fastladder の内部スキーマ定義
Fastladder は RDBMS として SQLite/MySQL/PostgreSQL を利用できます。 Rails アプリなので当たり前ですね。どれを利用しても良いのですが、スキーマの定義はざっくりと説明すると次のようになっています。
テーブル構造全体
テーブル構造は次のとおりです。特に重要なのは feeds と items です。
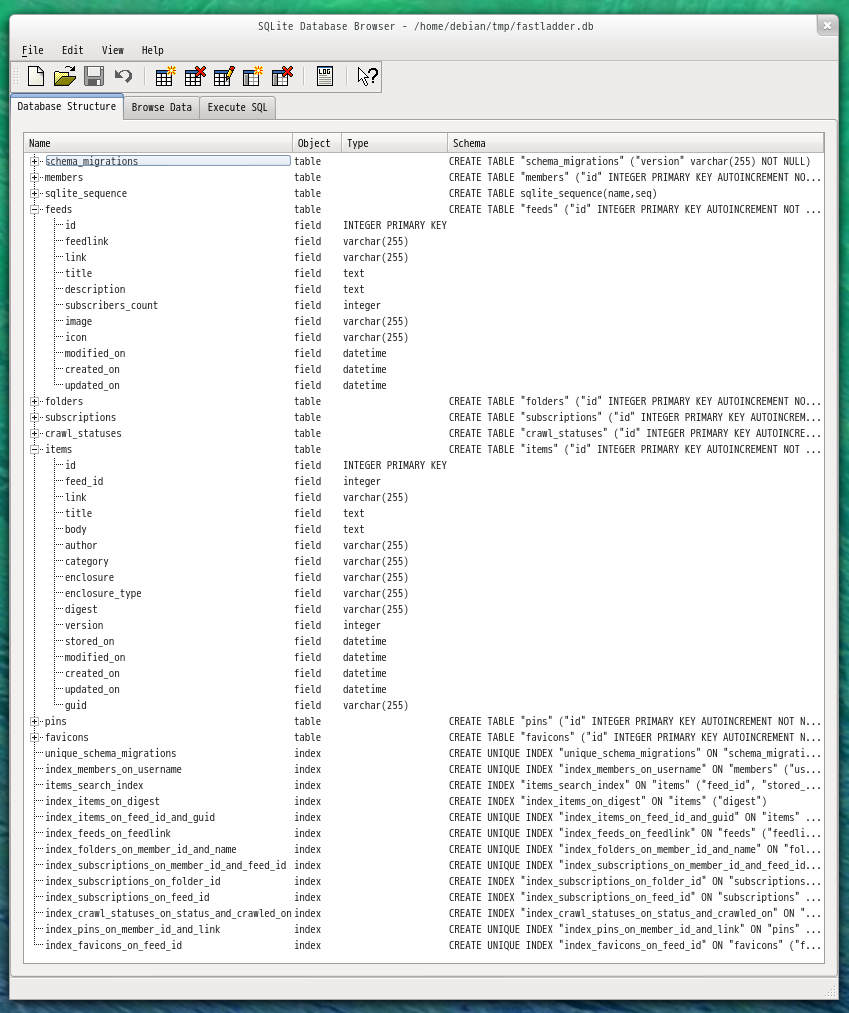
feeds にはクローリングの対象となるフィードが、 items にはクローリングして実際に得られたフィードが格納されることになります。
feeds に格納されるデータ
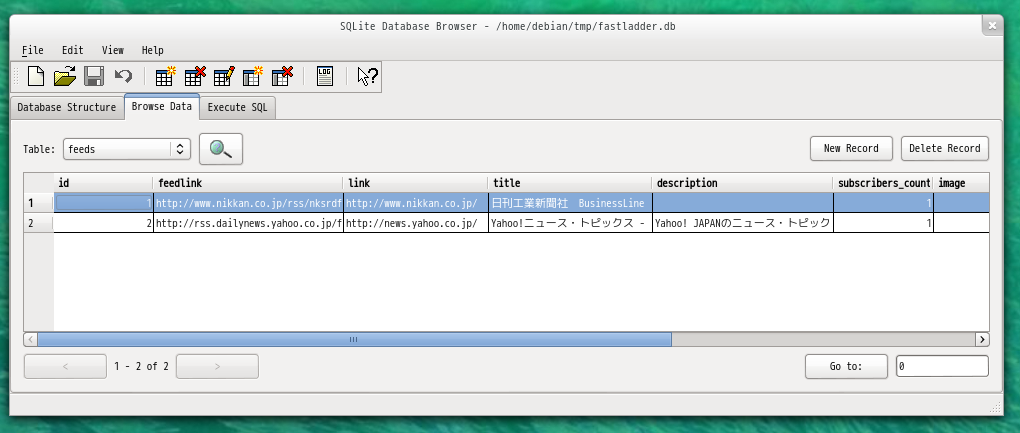
feeds にはこのようにクローラーがどこを見に行くかという情報が格納されます。とくに feedlink がいわゆる RSS/Atom のアドレスとなっています。ここがクローラーの情報取得の対象となる URL になるので一番重要です。
items に格納されるデータ
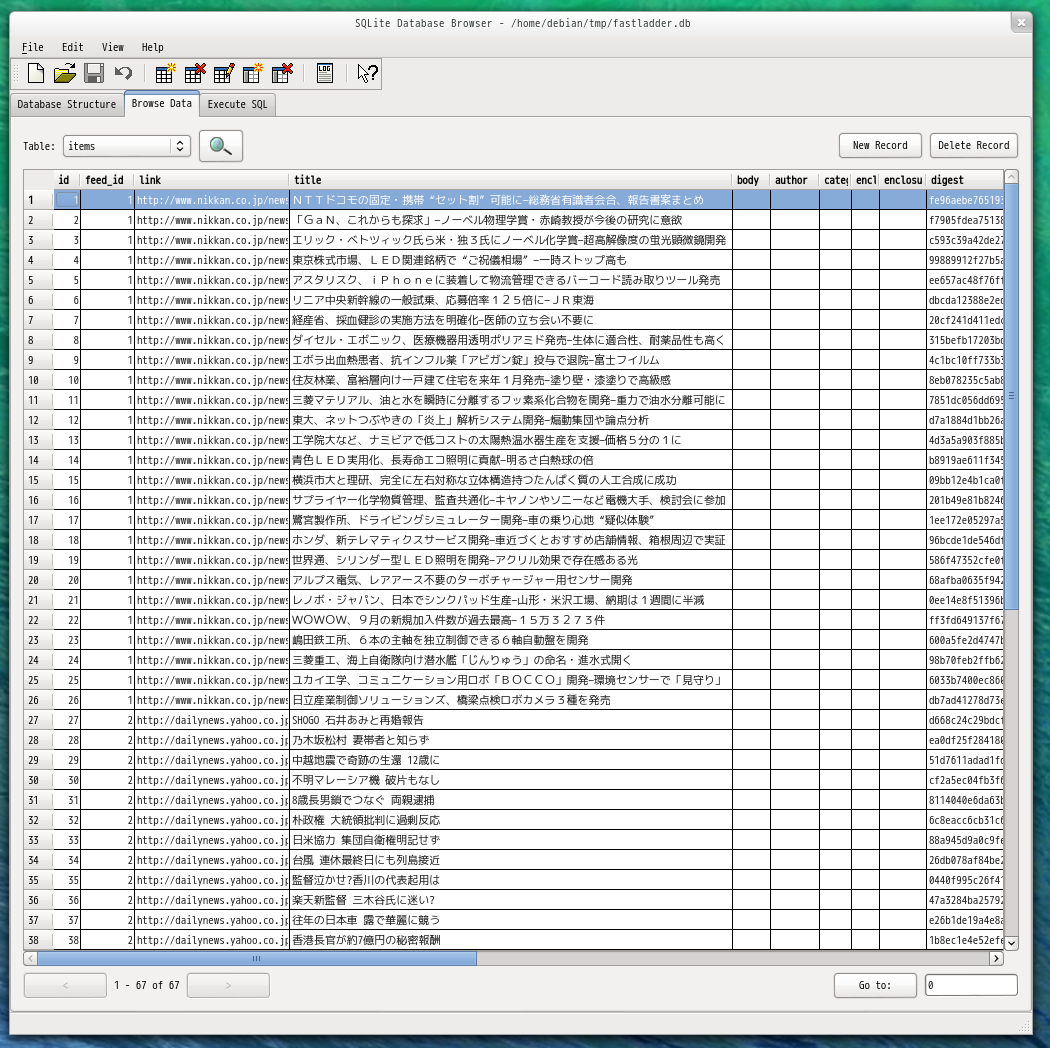
クローリングして得られた記事が格納されます。これらのデータが誰によって購読されているか、あるいは未読かどうか、ピンが立っているか、といったことは別テーブルで管理されます。
外部の情報を単に集めるだけであれば、基本的にこの items テーブルに溜まったデータを読み出せば良いことになります。
Fastladder のクローラー
Fastladder のクローラーは cron で動かすタイプのスクリプトではなく、 Ruby で実装された謹製のものとなっています。詳細はソースコードの lib/fastladder/crawler.rb を参照してください。
上に挙げた通り、データベースのテーブルの構造さえきちんと保てるなら、他のクローラーを実装しても構いません。
フィードアグリゲーター
フィードアグリゲーターとは複数のフィードを取りまとめて多様な出力をするソフトウェアのことです。 Perl で実装された Plagger や Ruby で実装された Automatic Ruby といったものがあります。
これらの特徴としては、プラグイン形式で機能を拡張できるようになっているため、必要な入出力あるいは途中処理の部分だけ実装することで、さまざまな用途に柔軟に利用できるという点が挙げられます。
配信されるフィードの種類
RSS/Atom フィードの生成方法は情報の提供元によってさまざまです。
要約配信
多くのサイトでは、フィードの中に要約情報しか格納していません。フィードは常にクローラーによって問い合わせされるので、これによってフィードのデータサイズをコンパクトにして通信量や負荷を軽減できます。ただし利便性としては当然ながら劣ります。全文を読みたければ、あらためてリンクをたどって元の記事にアクセスしなければなりません。また、実際には本文が空のフィードが多いのも事実です。
全文配信
中にはフィードの中に全文が格納されているものもあります。この場合はわざわざ元の記事にアクセスしなくても、フィードリーダーでそのまま記事全体を読むことができます。このような配信方法だと PV を気にするようなサイトではアクセス数が減ってしまったり、実態としてどういった人が読んでいるのかを把握できなくなったりしてしまうといった面があるため、前述のように部分的な情報だけを配信することになるのです。
代表的なニュースフィード
Google ニュースは RSS/Atom フィードを購読することができます。
GoogleニュースのRSSを取得する方法
http://d.hatena.ne.jp/tessy3/20110115/1295063878
ただしこれは少し気をつけなくてはいけなくて、フィードの link のところが Google のサイトをリダイレクトするようになっています。そのため link の URL をもとに情報を処理しているといったような時には気をつける必要があります。やや囲い込みを狙ったフィードの配信の仕方であると言っても良いでしょう。
その他の代表的なニュースフィードとしては次のようなものがあります。
Google News 及びその他ポータル系のRSS一覧。
http://wataame.sumomo.ne.jp/archives/4618
システム的に利用する場合は、先に挙げた Fastladder などを利用してひとまずフィードを購読し、中身がどのようになっているか吟味すると良いでしょう。
フィードを利用する場合の注意点
システムとして外部のフィードを利用する場合、これらは配信元の都合に左右されますから、柔軟なシステムの開発・運用をする必要があります。基本的にマッシュアップをする場合と似た考え方をすれば良いでしょう。
特に個人のブログなどをフィード購読する場合は、記事が非公開になったり削除されたりといったことも頻繁に起こりがちです。インプットに関して BtoC 的な考え方が必要になると言えばわかりやすいでしょうか。
とはいえ、外部の情報源を扱う方法として最も簡単でまた有力なのはフィードを使う方法です。もちろん他にも、たとえばサイトをごりごりスクレイピングするだとか、あるいは Twitter のデータを購入するなど方法があります。ですが、スクレイピングは開発・運用共に難易度が格段に跳ね上がりますし、単純な情報収集という観点で言えばフィードを利用するほうが良いでしょう。フィードですらある程度のノウハウが必要となるのです。しかし、どうしてもフィードが取得できないようなタイプの情報を集める必要があるときはスクレイピングすることになります。
まとめ
今回は少し趣向を変更し、応用という意味で、キュレーションという観点で主にフィードについてまとめました。これらはヒューリスティクスを適用する例として代表的な分野と言えるでしょう。