マルチクラウド展開にまつわる既成概念を覆すより。
データ転送では、特に長距離の場合にレイテンシ(遅延)が問題になることがありますが、現在はすべてのクラウド・プロバイダーがそれぞれの物理インフラストラクチャを互いの近くに配置(専門用語では「コロケーション」)しているため、これはさほど問題となりません。この近接性(場合によっては同一コロケーション施設内の別の部屋)は、クラウド間のレイテンシがミリ秒単位であることを意味します。それに加え、クラウド・データ・センター・リージョンは世界中で増加しており、クラウド・リージョン間の距離は縮まっています。
ということで、レイテンシ(遅延)についてまとめてみてみます。
■ Agenda
-
 レイテンシ(遅延)とスループット(帯域幅)
レイテンシ(遅延)とスループット(帯域幅)
-
レイテンシとTCPの動作
-
帯域幅遅延積(Bandwidth-Delay Product)
-
TCP Window Size(TCP Buffer Size)の調整とチューニング
-
クラウド・サービスでの考慮
-
レイテンシ(遅延)の机上計算
-
ネットワーク・パフォーマンスの測定
-
必要レイテンシ(遅延)値の事前策定
-
参考情報
この記事では、特に断りがない限り、pingやTCP通信で扱いやすい往復遅延時間(RTT: Round Trip Time)を中心に「レイテンシ(遅延)」として扱います。片道遅延を扱う場合は、その旨を明記します。
ネットワーク性能を見るときは、単純に「帯域幅が大きいから速い」とは考えにくいです。特に長距離通信やクラウド間通信では、次の3つをセットで見ることが重要です。
- レイテンシ(RTT): 1回の要求と応答にかかる時間
- スループット: 実際に転送できるデータ量
- 帯域幅遅延積(BDP): 帯域幅を使い切るために、経路上に流しておく必要があるデータ量の目安
つまり、帯域幅が十分にあっても、RTTが大きく、TCPウィンドウ・サイズやアプリケーションの転送単位が小さいと、期待したスループットが出ないことがあります。
■ レイテンシ(遅延)とスループット(帯域幅)
レイテンシとスループットは、ネットワーク性能を表す代表的な指標です。
・ レイテンシ: 転送要求から応答を受信するまでの応答時間
・ スループット: 一定時間内に転送できるデータの量
TCP通信では、レイテンシが大きくなるとスループットが低下し、通信完了までの時間に大きく影響します。
・参考: ネットワーク遅延対策技術
・イメージ
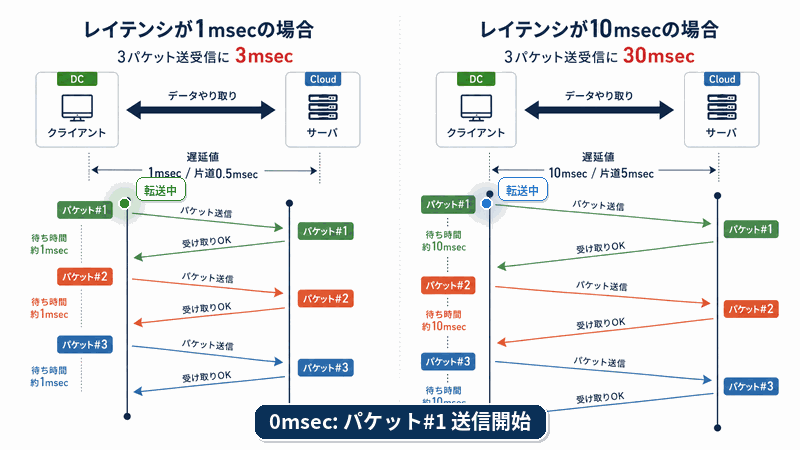
※ わかりやすくするためのイメージです。TCP/IP - TCP 3ウェイ・ハンドシェイク、ウィンドウ・サイズの折衝などは割愛しています。詳しくは以下も参照してください。
・参考: TCP window sizeの仕組み
TCP Window Control / Flow Control
厳密には、帯域幅はネットワーク経路が持つ容量、スループットは実際に転送できたデータ量です。この記事では、帯域幅が十分にあっても、レイテンシやTCPウィンドウ・サイズによって実効スループットが伸びないケースを中心に整理します。
■ レイテンシとTCPの動作
TCPでは、送信側が高速で受信側が低速な場合のオーバーランを防ぐため、ウィンドウ制御という仕組みが使用されます。
この仕組みでは、受信側が一度に受信できるデータ量(ウィンドウ・サイズ)を送信側に通知します。
送信側は、その範囲内で確認応答(ACK)を待たずにデータを送信できます。
このTCPウィンドウにより、送信側システムと受信側システムはメモリーを効率的に使用できます。
また、TCPウィンドウ・サイズは、受信バッファ・サイズ、TCPソケット・バッファ・サイズとも呼ばれます。
TCP接続における一括転送の性能上限は、次の式で表せます。
Throughput <= Window Size / Round Trip Time (RTT)
これは、単一TCP接続の一括転送において、TCPウィンドウ・サイズとRTTから見たスループット上限の目安です。実際のスループットは、輻輳制御、パケットロス、CPU、NIC、暗号化、アプリケーション処理、経路上の装置などにも影響されます。
・参考: 問題: レイテンシとTCPの動作
応用情報技術者過去問題
ビット?バイト? データ量の表し方
ウィンドウ・サイズが64 KB、レイテンシが1 msの場合のスループットは次のようになります。
64 KB / 1 ms = (64 KB) / (1/1000 s)
= 64,000 KB/s
= 64 MB/s
= 512 Mbps
※ ここでは説明を簡単にするため、64 KBおよび1 KB=1,000 bytesとして計算します。TCPの元々のウィンドウ上限は65,535 bytes(64 KiB - 1)です。
このように、TCPを用いるアプリケーションの最大スループットは、往復遅延時間(RTT: Round Trip Time)の影響を受けます。ウィンドウ・サイズが64 KBの場合、TCP最大スループットの理論値は以下のとおりです。

※ MByteは1,000 KByteとします。
・参考: ネットワーク遅延と高速化
■ 帯域幅遅延積(Bandwidth-Delay Product)
帯域幅遅延積(Bandwidth-Delay Product: BDP)は、ネットワーク帯域幅と往復遅延時間(RTT)の積です。
TCPウィンドウ・サイズをBDP以上に設定すると、ネットワーク帯域幅をより効率的に利用できます。
TCPウィンドウ・サイズが小さいと、帯域幅に余裕があっても十分なスループットが出ないことがあります。その場合は、一度に送信できるデータ量を増やすことで改善できる場合があります。
ネットワークの帯域幅が増加するとケーブル(ネットワーク)を流れるデータ量が増加します。
また、ケーブルが長くなるほどデータの受信確認に要する時間も長くなります。
この関係を帯域幅遅延積(Bandwidth-Delay Product: BDP)といいます。
BDPは帯域幅とラウンドトリップ時間(RTT)の積で、パイプにできるだけ多くのデータを流すために必要な送信ビット数の目安になります。
式で表すと、次のようになります。
BDP(bit) = 帯域幅(bit/秒) × RTT(秒)
たとえば、ネットワーク帯域幅が100 Mbps(100,000,000 bps)で、往復時間が5 msの場合、
送受信バッファは少なくとも(100 × 10^6) × (5 / 10^3)ビット、すなわち約62.5 KBになります。
100,000,000 bits 1 Byte 5 ms
-------------------- x --------- x --------- = 62,500 bytes
1 second 8 bits 1000
・参考
- レイテンシとTCPの動作
- 帯域幅遅延積の求め方
先ほどの表にBDPを加えると、次のようになります。

最適なウィンドウ・サイズ(TCP Buffer Size)の値は、ユーザーの環境によって異なりますが、システムのデータ送信が想定される経路におけるBDP(帯域遅延積)の最大値が1つの基準となります。
ネットワーク帯域幅を使い切るための目安として、最大送受信バッファ・サイズをBDP以上、または環境によってはBDPの2〜3倍程度まで検討します。ただし、大きすぎるバッファ・サイズはメモリー使用量やレイテンシ悪化につながる場合があるため、実測しながら調整します。
■ TCP Window Size(TCP Buffer Size)の調整とチューニング
● Path MTU Discoveryの確認
TCP Buffer Sizeを調整する前に、Maximum Transmission Unit (MTU)とPath MTU Discovery (PMTUD)の設定を確認しておきます。
MTUとは、1回のデータ転送で送信可能なIPデータグラムの最大値です。この値は、固定値またはPath MTU Discoveryによる自動検出で設定されます。
自動検出を有効にするには、経路上の最小MTU値をICMP(type 3 code 4)で送信元へ通知し、MTUサイズを自動調整させます。
MTUサイズの不一致によって接続がハングする問題を回避するため、FirewallでICMP(type 3 code 4)を許可しておきます。
なお、上記のICMP type 3 code 4はIPv4の例です。IPv6ではICMPv6 Packet Too BigがPath MTU Discoveryに使用されます。IPv6環境でICMPv6を過度に制限すると、同様にPMTUDが機能せず、通信がハングすることがあります。
・参考:
- Path MTU Discovery
- Window SizeとMSS(≒MTU)との違い
- ハングしている接続
● OSでのTCP Buffer Size調整
アプリケーションのTCP Buffer Sizeを調整する前に、OS側のTCP Buffer Sizeの上限を引き上げる必要があります。まずはOSの設定値を確認し、効果が見込める範囲で調整を試みます。
・ Linux
・ net.core.rmem_max: 最大読み取りソケット・バッファ・サイズを指定
・ net.core.wmem_max: 最大書き込みソケット・バッファ・サイズを指定
・ net.ipv4.tcp_rmem: TCPソケットの最小、デフォルト、最大受信バッファ・サイズを指定
・ net.ipv4.tcp_wmem: TCPソケットの最小、デフォルト、最大送信バッファ・サイズを指定
・ macOS
・ net.inet.tcp.autorcvbufmax
・ net.inet.tcp.autosndbufmax
・ net.inet.tcp.win_scale_factor
・ kern.ipc.maxsockbuf
・ net.systm.kctl.autorcvbufmax
・参考: macOS Tuning
・ Windows
受信ウィンドウ サイズを特定の値に設定するには、Windowsのバージョンに固有のレジストリ・サブキーにTcpWindowSize値を追加します。
・参考: Windows TCP機能の説明
● ソフトウェアでのTCP Buffer Size調整
アプリケーションやソフトウェアによっては、TCP Buffer Sizeを調整することでネットワーク・スループットを上げられるものがあります。
・ ファイル転送ソフトウェア
・ WinSCP
「接続バッファ サイズの最適化」をチェックします。
・参考: The Connection Page (Advanced Site Settings dialog)
・ SFTP
-Bでバッファ・サイズを指定します(デフォルト: 32768バイト)。
・参考: manページ — SFTP
・ SCP
High Performance SSH/SCPは、SSHバッファ・サイズを動的に大きくすることで、スループットを大きく向上させることができます。
・参考: SSHの高速化
・ rclone
--buffer-size=SIZE: バッファ・サイズを指定して、ファイル転送を高速化します。
・参考: rclone.org
・ Oracle Database
- TCPソケット・バッファ・サイズの設定
- REDOデータ転送のネットワーク調整
- パフォーマンスの最適化
- 帯域幅遅延積の求め方
- How to measure Network Latency for Oracle Data Guard Replication
- Doc ID 2064368.1: Assessing and Tuning Network Performance for Data Guard and RMAN
● その他のチューニングによるスループット高速化
スループットを向上させるには、転送回数の削減や転送サイズの縮小なども有効です。
・ 転送回数の削減: 並列処理、効率的なプログラミング・アルゴリズムの使用、など
・ 転送サイズの縮小: データ圧縮、オーバーヘッドが少ない暗号アルゴリズムの選択、など
・ ファイルを分割して並列転送で高速化
ファイル転送でバッファ・サイズを指定できない場合や、効果が足りない場合は、ファイルを分割して並列転送することで転送時間を短縮します。
また、ファイルを圧縮できれば、転送時間をさらに削減できます。
・ scpの複数同時接続
・ 大きなファイルを分割して送信し、そのあとで結合する方法
・ Object Storageのマルチパート・アップロード
・ Curlでマルチパート・アップロード
・ 効率的な暗号アルゴリズムの選択
暗号化にはオーバーヘッドがあり、その大きさはアルゴリズムによって異なります。
scp/sftpの場合、ssh -Q cipherで使用できる暗号方式を確認し、-cオプションで暗号アルゴリズムを選択できます。
・ 大容量ファイルのSCP転送を高速にする方法
・ 次の暗号化オプションのどれがオーバーヘッド/コストを増加させるでしょうか?
・ SSHの公開鍵暗号には「RSA」「DSA」「ECDSA」「EdDSA」のどれを使えばよいのか?
・ 圧縮による転送効率化
ファイルを圧縮して転送サイズを小さくし、転送時間を削減します。
scp/sftpコマンドの場合は -Cオプション、rsyncコマンドの場合は -zまたは--compressでデータを圧縮して転送できます。
・ zipsplitコマンド――ZIPファイルを分割する
・ 大容量ファイルのSCP転送を高速にする方法
Oracleの場合、クエリー・パフォーマンスの改善やネットワーク通信量の削減などの効果が期待できます。
・ Oracle Advanced Compression概要
・ Oracle Advanced Compressionホワイトペーパー
・ 徹底解説! データベース圧縮のすべて~検証結果・事例に基づくベスト・プラクティス~
・ SQL処理を分割並列処理とバルク処理で高速化
SQLを直列ループ処理するようなバッチ処理では、ループ処理を複数に分割して並列化することで帯域幅を有効活用できます。また、バルク処理で1回のフェッチで複数行を取得し、複数行をまとめて処理することで高速化できます。
・ 処理イメージ

・参考:
- BULK COLLECTとFORALLによるバルク処理
- Linux Traffic Controlを使用してレイテンシをシミュレートし、Oracle Databaseのフェッチ・サイズを調査する
・ 輻輳制御の新アルゴリズムTCP BBRを設定
輻輳制御の新アルゴリズムTCP BBRをGCPに導入より。
BBR (Bottleneck Bandwidth and Round-trip propagation time)は、Googleが開発した新しい輻輳制御アルゴリズムです。ネットワークに接続されたすべてのコンピュータ、携帯電話、タブレットで実行され、データの送信速度はこれによって決まります。
BBRは、どのくらいのペースでネットワークにデータを送り出すかを決めるにあたって、そのネットワークがどれくらいの速さでデータを送り届けているかを考慮します。一定のネットワーク接続におけるネットワークの転送速度とラウンドトリップ時間の最近の測定値を用いて、その接続の帯域幅の上限と最小のラウンドトリップ遅延の両方を含むモデルを構築します。BBRはこのモデルを用いて、データの送信速度とネットワークに流し込むデータ量の上限を常に制御します。
BBRの導入により、従来の輻輳制御アルゴリズムであるCUBICと比べて、クラウド・サービス間のスループットは向上し、レイテンシは低くなって、サービスが快適に使えるようになりました。
・ 設定例
BBRと、BBRに必要なFQペーシングを設定します。
1) 事前確認
# cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
2) BBR設定
# vi /etc/sysctl.conf
# cat /etc/sysctl.conf
net.core.default_qdisc=fq
net.ipv4.tcp_congestion_control=bbr
# sysctl -p
3) BBR設定確認
# cat /proc/sys/net/core/default_qdisc
fq
# cat /proc/sys/net/ipv4/tcp_congestion_control
bbr
■ クラウド・サービスでの考慮
● クラウド・サービス機能によるレイテンシ削減
各クラウド・プロバイダーでレイテンシを考慮する際は、システム構成図上の各アイコン(コンポーネント)ごとに、追加のノード・レイテンシが発生すると考えられます。

(1) Availability Domain(AD)/Availability Zone(AZ)
複数あるADまたはAZ間は距離が離れているため、接続するAD/AZによってレイテンシは異なります。
・AWS東京リージョンと大阪リージョンのAZ間レイテンシを比較してみた
・OCI-Azure Interconnectを使用したネットワーク・レイテンシとベスト・プラクティス
また、クラウド・プロバイダーによっては、レイテンシを削減するためのAZや近接配置に関する機能があります。
・AWS Local Zones
・Azure: Proximity placement groups
・Oracle Cloud: Cluster Placement Groups(クラスタ配置グループ)
(2) Gateway
各クラウド・プロバイダーのGatewayが複数ある場合、それぞれ追加されるレイテンシが異なる場合や、高速化のための追加オプションが用意されている場合があります。
・参考: Virtual Network Gateway Ultra Performance
(3) クラウド専用ネットワーク接続
クラウド・プロバイダーによっては、高速化のためのオプションが用意されている場合があります。
・参考: ExpressRoute FastPath
(4) Compute
コンピュートのネットワークを高速化するオプションが用意されている場合があります。
・参考: AWS: Enhanced networking on Linux
AWS Nitro System
LinuxベースのEC2インスタンスのネットワーク・レイテンシを改善する
Azure: 高速ネットワークの概要
Google Cloud: VMごとのTier_1ネットワーキング・パフォーマンスを構成する
Oracle Cloud: Hardware-assisted (SR-IOV) networking
クラスタ配置グループ
これらの考慮ポイントを組み合わせることで、AzureとOracle Cloud Infrastructure(OCI)間の接続で2 ms未満のレイテンシを実現できるケースがあります。
・参考: Oracle Interconnect for AzureをFastPathと高速ネットワークで相互接続して
■ レイテンシ(遅延)の机上計算
コンピュート間のレイテンシは、距離におおむね比例します。
レイテンシに影響する主な要素は、ワイヤー長(距離)と通過ノードです。
データ・センター(Data Center: DC)間が光ファイバー・ケーブルで接続されている場合でも、光ファイバー・ケーブルがユーザーとデータ・センターの間を直線で直接つないでいるとは限りません。ファイバー・ケーブル上の光は、その経路に沿ってノード(機器)を通過します。
・参考: 光遅延計算
そのため、ワイヤー長はきれいな直線ではなく、迂回している場合もあります。ノード・レイテンシも含めると、実際のレイテンシは1.5倍程度になる可能性があると考えられます。
ここでは例として、Oracle CloudのTokyo RegionとOsaka Regionの距離をGoogleマップで調べ、机上計算してみてみます。
● 光ファイバーの速さ
光速は、1秒間に地球を7周半回ることができる速さです。単に「光速」と言う場合は、真空中の光速を示します。
光ファイバー中では光が全反射を繰り返して伝搬するため、伝搬距離は直線距離より長くなります。そのため、一般的には真空中の速度である約30万 km/秒の2/3、約20万 km/秒程度の速度になります。
● 机上計算
1) Googleマップで距離計測
Oracle Cloud Regionのデータ・センターは所在が公開されていないため、FastConnect Location間の距離をGoogleマップで計測してみてみます。
Oracle FastConnectのロケーションはここから確認できます。
・参考: Oracle FastConnectのロケーション

距離が約500 kmであることを確認できます。
2) 往復遅延時間(RTT)計算
RTT (Round Trip Time)の計算式は次のとおりです。
ワイヤー長(距離) / 光ファイバー速度 × 往復 = 往復遅延時間(RTT)
Googleマップの距離と光ファイバー速度から、次のように計算できます。
・ ワイヤー長(距離) = 500 km
・ 光ファイバー速度 = 200,000 km/s
500 km / 200,000 km/s × 2 = 0.005(秒)
= 5 ms
また、以下のWebサイトでも計算できます。
・参考: 光遅延計算
3) 迂回経路とノード・レイテンシ考慮
迂回経路とノード・レイテンシを考慮すると、1.5倍程度になる可能性があると考えられます。
5 ms × 1.5 = 7.5 ms
4) FastConnect LocationからOracle Cloud Region間を考慮
FastConnect Locationのデータ・センターからOCI Region間のレイテンシを1 ms未満とすると、東京側・大阪側を合わせて1 ms程度のレイテンシが追加されると考えられます。
7.5 ms + 1 ms = 8.5 ms
● 確認
Oracle Cloudでのリージョン間レイテンシは、OCIコンソールで確認できます。
1) OCIコンソール
[ネットワーキング] > [リージョン間のレイテンシ]をクリックします。

2) リージョン間のレイテンシ画面
レイテンシを確認したいリージョン(TokyoとOsaka)を入力し、[Show]をクリックします。

結果は8.1 msで、机上計算に近い結果となりました。
● サイト/リージョン間レイテンシ(遅延)情報
サイト間のレイテンシを公開しているプロバイダーの例です。
・Azureネットワーク・ラウンドトリップ待ち時間統計
・Equinix Latency Data
・Megaportネットワーク・レイテンシ
・Oracle Cloud Public Cloud Regions
● 各クラウドのリージョン内(AD/AZ/Zone間・内)レイテンシ
各クラウドでは、リージョン内の冗長化単位の呼び方が異なります。
- AWS / Azure: Availability Zone(AZ)
- Google Cloud: Zone
- OCI: Availability Domain(AD)
ここでは便宜上、AD/AZ/Zone とまとめて表記します。
注意:
以下は、各社公式ドキュメントに記載されている設計目標、一般的な説明、または参考値です。SLAや常時保証値ではありません。
実際のレイテンシは、リージョン、AD/AZ/Zoneの組み合わせ、インスタンス種別、ネットワーク機能、LB、NAT、Firewall、TLS、アプリケーションのホップ数などで変わります。最終的には、必ず実構成で測定する必要があります。
| クラウド 冗長単位 |
AD/AZ/Zone間 | 同一AD/AZ/Zone内 | レイテンシ値の見え方 | 近接配置・高速化機能 | 参照ドキュメント |
|---|---|---|---|---|---|
|
AWS Availability Zone(AZ) |
AZ間は、同期レプリケーションに利用できるよう、1桁ミリ秒(single-digit millisecond)の低レイテンシで接続されると説明されています。 | 同一AZ内のEC2インスタンス間は、Enhanced Networking利用時に通常sub-millisecond RTTと説明されています。 | AZ間は「1桁ミリ秒」。同一AZ内は条件により1ms未満。 | ・Cluster Placement Group ・Enhanced Networking ・Nitro System |
- AWS Fault Isolation Boundaries - Availability Zones - Improving performance and reducing cost using Availability Zone affinity |
|
Azure Availability Zone(AZ) |
AZ間は高パフォーマンス・ネットワークで接続され、ゾーン間通信のround-trip latencyは約2ms未満を目指すと説明されています。 | 汎用的な固定ms値は明記されていません。1つのAZが複数データセンターにまたがる場合があるため、低レイテンシが必要なVMでは近接配置を検討します。 | AZ間ネットワーク・リンクの目標として約2ms未満。ただしアプリケーションから見たRTTは構成に依存。 | ・Proximity Placement Groups ・Accelerated Networking ・ExpressRoute FastPath |
- Azure availability zones overview - Proximity Placement Groups - Accelerated networking overview |
|
Google Cloud Zone |
Zone間は high-bandwidth, low-latency network connections と説明されています。固定のms値は一般値として明記されていません。 | 同一Zone内では、placement policyによりVMの相対的な近接配置を制御できます。Compact placement policyはVM間レイテンシ低減用途として説明されています。 | 固定値よりも、Performance DashboardでZoneペアごとのmedian RTTを確認する形。 | ・Compact Placement Policy ・Tier_1 Networking ・Performance Dashboard |
- Regions and zones - View Google Cloud latency information - Placement policies overview |
|
Oracle Cloud Infrastructure(OCI) Availability Domain(AD) |
AD間は low-latency, high-bandwidth network で接続されると説明されています。Oracle Cloud MAA資料では、複数ADリージョンのAD間について1ミリ秒未満の同期レプリケーション文脈で説明されています。 | AD内はsub-millisecond latencyと説明されています。さらにCluster Placement Groupsにより、同一AD内でリソースを物理的に近い場所へ配置できます。 | 通常のAD間/AD内は低レイテンシ表現。HPC/GPU/RDMA向けCluster Networkでは、数マイクロ秒級の値も説明されています。 | ・Cluster Placement Groups ・Cluster Network ・RDMA ・SR-IOV |
- Regions and Availability Domains - Tune and monitor network performance - Oracle Cloud Infrastructure Platform Overview - Managing cluster networks |
表の読み方
- AWS は、AZ間を「1桁ミリ秒級」、同一AZ内を条件付きで「sub-millisecond RTT」と説明しています。
- Azure は、AZ間ネットワーク・リンクの目標として「約2ms未満」を示しています。
- Google Cloud は、固定の一般値を示すというより、Performance DashboardでZoneペアごとの実測median RTTを確認する考え方です。
- OCI は、AD間/AD内の低レイテンシに加え、Cluster Placement GroupsやCluster Networkにより、用途によってさらに低レイテンシな配置を選択できます。
特に注意したいのは、各クラウドの数値がすべて同じ意味ではない点です。
たとえば、AWSの「1桁ミリ秒」、Azureの「約2ms未満」、OCIの「1ミリ秒未満」、HPC/GPU向けの「数マイクロ秒」は、それぞれ前提となる構成や文脈が異なります。
そのため、この表は単純な優劣比較ではなく、各クラウドでリージョン内レイテンシをどう考えるべきかを整理するための比較表として見るのがよいです。
■ ネットワーク・パフォーマンスの測定
● レイテンシ(遅延)測定
レイテンシ測定は、NetperfまたはSockPerfでICMP/TCP/UDPなどのプロトコル単位で計測します。
クラウドでのネットワーク・レイテンシの測定より。
ネットワークのRTTレイテンシを測定するツールにはping、iperf、netperfなどがありますが、すべてが同じように実装、構成されるわけではないため、ツールによって結果が異なる場合があります。多くの場合、この質問に対する代表的な回答が得られるツールはnetperfであると考えられます。
pingは測定にICMPパケットを使用し、nping、hping、TCPingなどのpingをベースとするツールはTCPパケットを使用します。
レイテンシ・テストを実施する際に忘れてはならないのは、間隔やその他のツール設定を記録、報告することです。特にレイテンシが低い場合は、間隔が大きな違いをもたらします。pingの場合、-i 0.001オプションで間隔を細かく設定できます。クラウド環境ではICMPが低優先度で処理され、RTT測定結果にノイズが入ることがあります。デフォルトの1秒間隔より短い間隔(例: 0.001秒)で実行すると、測定トランザクションが常時キューに存在しやすくなり、ノイズを減らせる場合があります。
また、Azure VM間のRTT測定にICMPを使ってはいけないより、Virtual MachinesのRTT測定には、データ・センター内のネットワーク高速化の仕組み上、TCP/UDPかつ、実際に到達できるポートに対する通信を利用する必要があります。
そのため、LinuxではNetperfまたはSockPerf、WindowsではLatteを使用して、TCP/UDPレイテンシをマイクロ秒(μs)単位で測定します。
pingで報告された平均レイテンシとnetperfで報告された平均レイテンシには、約80マイクロ秒の誤差があります。pingで報告された値はnetperfで報告された値の2倍以上の大きさです。どちらのテストを信用すればいいのでしょうか。
これは主に、デフォルトで使用される間隔が2つのツールで異なることが原因です。pingでは1秒あたり1トランザクションの間隔が使用されますが、netperfではトランザクションが完了するとすぐに次のトランザクションが発行されます。
幸いなことに、どちらのツールでもトランザクション間の間隔を手動で設定できるため、間隔が一致するよう調整して結果を確認することができます。
pingの場合は、-iフラグで秒単位または小数秒単位の間隔を設定します。Linuxシステムでは、粒度は1ミリ秒であるため、ミリ秒単位に切り捨てられます。たとえば、0.00299秒の間隔を指定すると、0.002秒、つまり2ミリ秒に切り捨てられます。1ミリ秒未満の間隔をリクエストすると、pingによって0に切り捨てられ、リクエストが可能な限り早く送信されます。
・Netperf実演デモ
・SockPerf実演デモ
・Latte for Windows実演デモ
How to measure network latency for Oracle Database applications in OCI(Doc ID 3008087.1)より、Oracle Databaseへのレイテンシ測定では、SQLとset timing onを使用してRTTを測定することは不適切であり、よく知られたユーティリティtnspingも使用すべきではありません。これらの方法はいずれも、RTTを正確に測定したり、必要な精度で測定したりすることはできません。
● スループット(帯域幅)測定
iperf3は、TCP/UDPデータ・ストリーム(シングル・スレッドまたはマルチ・スレッド)を作成し、伝送するネットワークのスループットを測定できるネットワーク・テスト・ツールです。
一方のインスタンスをサーバー、もう一方のインスタンスをクライアントとして実行します。
高帯域の経路では、iperf3の単一TCPストリームだけでは帯域を使い切れない場合があります。-Pで並列ストリーム数を増やす、-tで測定時間を長くする、CPU使用率や再送(ss -ti、netstat -sなど)もあわせて確認します。
・参考: ネットワーク・スループットを測定するためのツールの概要
・実演デモ
■ 必要レイテンシ(遅延)値の事前策定
コンピュータ間の距離により、遅延や帯域が変わり、データ転送などにかかる時間も変わることがあります。
tcコマンド(Traffic Control)を使用して、ネットワークのレイテンシ(遅延)とスループット(帯域幅)を制御してテストすることで、既存の処理に影響が出るか、どの程度のネットワーク・パフォーマンスが必要かを確認できます。
そこで、tcコマンドで遅延と帯域を制御できるか確認してみてみます。
・実演デモ
・参考: Linux Traffic Controlを使用してレイテンシをシミュレートし、Oracle Databaseのフェッチ・サイズを調査する
■ 参考情報
・TCP関連
- ネットワーク遅延対策技術
- ネットワーク遅延と高速化
- TCP window sizeとは
- TCP window sizeの仕組み
- TCP Window Control / Flow Control
- 問題: レイテンシとTCPの動作
- Difference between TCP window size & MTU
- HPCユーザーが知っておきたいTCP/IPの話
- レイテンシとは? ネットワーク性能指標の概要と改善方法を解説
・MTU関連
- TCP window sizeの仕組み〜MSS(MTU)との違い
- Path MTU Discovery
- ICMP Type / Code
- ハングしている接続MTU問題と解決策
・光通信関連
- 光速
- 光遅延計算
- SINET5で変わる長距離高速通信テクニック
- 波長分割多重(WDM,CWDM,DWDM)とは
- WDMとは?伝送の仕組みやCWDMとDWDMの違いを解説
・Azure
- Azureネットワーク・ラウンドトリップ待ち時間統計
- Oracle Cloud Public Cloud Regions
・Google
- レイテンシとTCPの動作
- レイテンシの測定
- ネットワーク・パフォーマンスのTCP最適化
- クラウドでのネットワーク・レイテンシの測定
- ネットワーク・スループットを測定するためのツールの概要
・macOS
- macOSのチューニング
・Oracle
- ネットワーク・パフォーマンス
- TCPソケット・バッファ・サイズの設定
- REDOデータ転送のネットワーク調整
- パフォーマンスの最適化
- 帯域幅遅延積の求め方
- How to measure Network Latency for Oracle Data Guard Replication
- Oracle Linux: システム・パフォーマンスを制御するパラメータ
- Doc ID 2064368.1: Assessing and Tuning Network Performance for Data Guard and RMAN
- Linux Traffic Controlを使用してレイテンシをシミュレートし、Oracle Databaseのフェッチ・サイズを調査する
- Oracle Advanced Compression概要
- Oracle Advanced Compressionホワイトペーパー
- 徹底解説! データベース圧縮のすべて~検証結果・事例に基づくベスト・プラクティス~
- Doc ID 3008087.1: How to measure network latency for Oracle Database applications in OCI
・Red Hat
- レイテンシの影響を受けやすいアプリケーションとは
- 高スループットのためのTCP接続のチューニング
・ファイル転送ソフトウェア
- FTPでスループット計測するときの注意事項
- scpの複数同時接続
- 大容量ファイルのSCP転送を高速にする方法
- 大きなファイルを分割して送信し、そのあとで結合する方法
- zipsplitコマンド――ZIPファイルを分割する
- Object Storage Multipart Uploads
- Curlでマルチパート・アップロード
- 次の暗号化オプションのどれがオーバーヘッド/コストを増加させるでしょうか?
- SSHの公開鍵暗号には「RSA」「DSA」「ECDSA」「EdDSA」のどれを使えばよいのか?
・データ・センター間レイテンシ情報
- Azureネットワーク・ラウンドトリップ待ち時間統計
- Equinix Latency Data
- Megaportネットワーク・レイテンシ
- Oracle Cloud Public Cloud Regions
・その他
- ビット?バイト? データ量の表し方
- MbpsとMB/sって何が違うの?
- 応用情報技術者過去問題
■ 解説
■ おまけ
