概要
Azure Virtual Machines の RTT 測定には、Azure Datacenter 内のネットワーク高速化の仕組み上、TCP/UDP かつ、実際に到達できるポートに対する通信を利用する必要がありますよ、という知識まとめです。
同一リージョンの高速ネットワークが有効化された VM 同士で RTT を測ると、平均で 0.0623 ms (62.3 マイクロ秒) 程度であることが今回の実験では確認できましたが、その高速な通信の裏側にある仕組みについても、Microsoft が公開している論文を斜め読みして軽く解説します。
やってみたこと
テスト環境
- Azure 仮想マシン (Standard F4s_v2 (4 vcpu 数、8 GiB メモリ)) x 2 台
- Ubuntu 18.04 LTS
- 東日本リージョン
- 高速ネットワーク : 有効
- 近接配置グループ : 有効
- 仮想ネットワーク
- 2 台の VM を同一サブネットに配置
- 10.33.0.4
- 10.33.0.5
- 2 台の VM を同一サブネットに配置
ICMP で RTT 測定
以下のようにお馴染み ping で RTT を測定すると、「これが高速ネットワーク?」と思う程遅い。
test@10.33.0.4:~$ ping -c 4 10.33.0.5
PING 10.33.0.5 (10.33.0.5) 56(84) bytes of data.
64 bytes from 10.33.0.5: icmp_seq=1 ttl=64 time=0.982 ms
64 bytes from 10.33.0.5: icmp_seq=2 ttl=64 time=1.23 ms
64 bytes from 10.33.0.5: icmp_seq=3 ttl=64 time=1.30 ms
64 bytes from 10.33.0.5: icmp_seq=4 ttl=64 time=1.05 ms
--- 10.33.0.5 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3003ms
rtt min/avg/max/mdev = 0.982/1.145/1.304/0.129 ms
RTT の平均が 1ms を超えている…。
TCP で RTT 測定
実際に TCP でパケットを流して RTT を測るために、今回は netperf を使ってみる。
まずはセットアップ。受信側の VM にも応答用のサービスを入れる必要があるので、送信側、受信側双方の VM で以下のコマンドを実行。
sudo apt-get install netperf
そして、送信側 VM で以下のコマンドを実行。
netperf -t omni -H 10.33.0.5 -- -d rr -T TCP -k MIN_LATENCY,MEAN_LATENCY,P90_LATENCY,P99_LATENCY,MAX_LATENCY,STDDEV_LATENCY
そうするとこんな結果が出てくる。
test@10.33.0.4:~$ netperf -t omni -H 10.33.0.5 -- -d rr -T TCP -k MIN_LATENCY,MEAN_LATENCY,P90_LATENCY,P99_LATENCY,MAX_LATENCY,STDDEV_LATENCY
OMNI Send|Recv TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 10.33.0.5 () port 0 AF_INET : demo
MIN_LATENCY=35
MEAN_LATENCY=62.30
P90_LATENCY=85
P99_LATENCY=117
MAX_LATENCY=4676
STDDEV_LATENCY=28.92
ここで出てくる Latency の結果はマイクロ秒表記になっていますので、平均 62.30 マイクロ秒、つまり 0.0623 ms という結果に。99 パーセンタイルの Latency でも 0.117 ms ということで、ICMP を使って測定したものと比べて大きく違う結果になっています。
Azure の中身について知ってみよう
論文を読む
Microsoft は、Azure の高速ネットワークの内部実装について、IEEE で論文を発表して公開していますので、そちらを参照します。
是非論文を読んでいただきたいのですが、そんな時間もない方のためにざっくりおさらいするとこんな感じ。
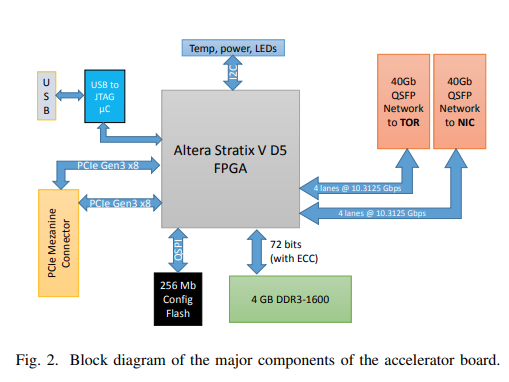
- Azure 仮想マシンをホストする物理サーバーには、FPGA で実装された Network Acceleration 用のハードウェアが PCIe スロットに挿入されている
- 当該ハードウェアでは、TCP と UDP の通信をハードウェアでオフロードして高速化を行っている
- オフロード対象の通信 (TCP/UDP) は PCIe 経由で FPGA を通ってネットワークに出る
- オフロード対象ではない通信 (ICMP 等) はサーバー側の NIC を経由する
- オフロードに際し、FPGA 内では、TCP/UDP の通信を LTL (Lightweight Transport Layer) という独自実装のプロトコルに変換する
- このプロトコルは UDP に ACK/NACK ベースの再送信方式を追加して信頼性を保証したもの
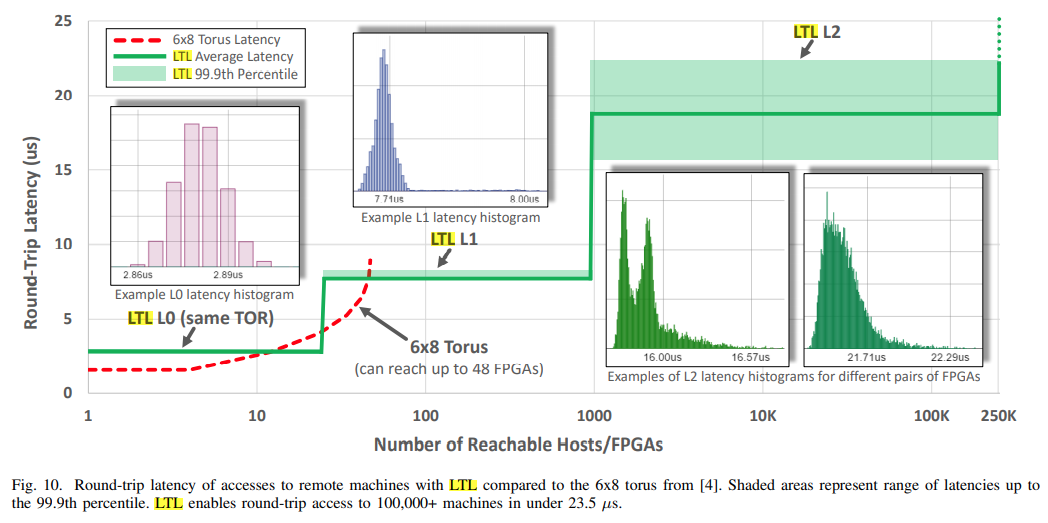
- このプロトコルとハードウェアアクセラレーションを使うことで、99.9 パーセンタイルの通信で以下のような RTT を実現
- 同一ラック内の通信 : 3-4 マイクロ秒
- もう一つ上位のスイッチを介する通信 : 7-8 マイクロ秒
- 更に上位のスイッチを介する通信 : 23.5 マイクロ秒以下
つまり、Azure の仮想マシンでは、VM 間の TCP の通信も内部的には UDP にに近い低遅延のプロトコルに変換されているということ。一方、TCP/UDP の枠組みでないプロトコルは高速化対象ではないため、通常の NIC を介して通信されているようです。
論文から、FPGA のボードの外観を引用。

内部のアーキテクチャはこんな風になっているらしいです。
そして、論文中にあった、DC 内のネットワーク的な距離別の RTT をまとめた表がこんな感じ。250000 台以上の物理サーバーに対して、99.9 パーセンタイルの通信が 23.5 マイクロ秒以下で通信できたよ、という結果が書かれています。
論文の内容を基に、実験結果について考えてみる
最初に紹介した実験では、ICMP を使った ping だと RTT が大きいという結果が出ていました。これは、FPGA + LTL による高速化の対象に ICMP が入っていない (TCP でも UDP でもないから) と考えられます。
一方、netperf を使った方は、TCP で通信を行っていますので、FPGA を経由して LTL に変換されてデータセンター内の通信が行われたことで、UDP に匹敵するような低遅延(かつ今回は RTT の話に絞りたかったのでとりあげませんでしたが、高スループット)の通信が行えていたと考えられます。
まとめ
Azure 仮想マシンにおけるスループット測定や RTT の測定は、実際のワークロードに即したプロトコルや通信内容で行っていただくことで、正しい結果を得ることが可能になります。
「ちょっと遅いな?」と思ったら、tcpdump でパケットを取るなどの作戦もとりつつ、ちゃんと TCP/UDP の通信が行われているかを確認してみるのも良いと思います。
おまけ
到達できないポートへの TCP/UDP 通信も遅い
単純に TCP/UDP を使えればいいだろ、と hping3 を使って適当に到達できないポートに向けて通信を行ったところ、とても遅い結果になりました。
test@10.33.0.4:~$ sudo hping3 -c 4 -p 11111 10.33.0.5
HPING tokawaneer002 (eth0 10.33.0.5): NO FLAGS are set, 40 headers + 0 data bytes
len=46 ip=10.33.0.5 ttl=64 DF id=0 sport=11111 flags=RA seq=0 win=0 rtt=7.9 ms
len=46 ip=10.33.0.5 ttl=64 DF id=0 sport=11111 flags=RA seq=1 win=0 rtt=3.8 ms
len=46 ip=10.33.0.5 ttl=64 DF id=0 sport=11111 flags=RA seq=2 win=0 rtt=3.7 ms
len=46 ip=10.33.0.5 ttl=64 DF id=0 sport=11111 flags=RA seq=3 win=0 rtt=3.6 ms
--- 10.33.0.5 hping statistic ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 3.6/4.8/7.9 ms
tcpdump でパケットトレースを取ってみたところ、相手側の VM のポートがあいていなくても、FPGA 側で RST パケットを返しているらしく、その応答のタイミングで RTT が記録されていることがわかりました。
RTT を測定する際には、使うプロトコル以外にも、到達可能なポートにちゃんと通信が出来ているか、可能であれば TCP の handshake がちゃんとできているかまで、tcpdump の結果を基に確認したほうが、より正確な結果としてみることが出来そうです。是非ご注意ください。