1. Kaggleとは
データ分析を用いて、様々な問題を解くのを競い合って自分の腕を試すサイト。
データセットが貰え、他の人の解説(カーネル)を見ることができるので、データ分析の勉強になります。
2. Titanicとは
Kaggleのコンペティションの1つ。
チュートリアルとして多くの初心者が利用します。
タイタニックに乗っていたどの乗客が生き残ったかを予測します。891人分の乗客データから他の418人の生存を予測するのがお題です。
3.今回やること
一貫してランダムフォレストを用いて提出スコア0.83732(上位1.5%相当)に至るまでのテクニックを初心者向けに解説していきます。
今回は提出スコア0.78468になるまでの解説です。
次回で0.81339までスコアを伸ばし、次次回で上位1.5%に相当する提出スコア0.83732となるように構成しています。
尚、使用したコードは全てGithubに公開しています。今回使用したコードはtitanic(0.83732)_1です。
4.コード詳細
必要なライブラリをimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline,make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings('ignore')
CSVを読み込んで内容を確認
# CSVを読み込む
train= pd.read_csv("train.csv")
test= pd.read_csv("test.csv")
# データの統合
dataset = pd.concat([train, test], ignore_index = True)
# 提出用に
PassengerId = test['PassengerId']
# trainの内容3つ目まで確認
train.head(3)
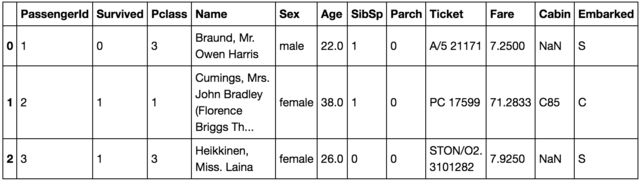
各カラムの簡単な説明をは以下の通り。
・PassengerId – 乗客識別ユニークID
・Survived – 生存フラグ(0=死亡、1=生存)
・Pclass – チケットクラス
・Name – 乗客の名前
・Sex – 性別(male=男性、female=女性)
・Age – 年齢
・SibSp – タイタニックに同乗している兄弟/配偶者の数
・parch – タイタニックに同乗している親/子供の数
・ticket – チケット番号
・fare – 料金
・cabin – 客室番号
・Embarked – 出港地(タイタニックへ乗った港)
さらに各変数の簡単な説明も記載をしておきます。
pclass = チケットクラス
1 = 上層クラス(お金持ち)
2 = 中級クラス(一般階級)
3 = 下層クラス(労働階級)
Embarked = 各変数の定義は下記の通り
C = Cherbourg
Q = Queenstown
S = Southampton
NaNはデータの欠損を表します。
(上の表だとcabinでNaNが2つ確認できます。)
全体の欠損データの個数を確認してみましょう。
# 全体の欠損データの個数確認
dataset_null = dataset.fillna(np.nan)
dataset_null.isnull().sum()
Age 263
Cabin 1014
Embarked 2
Fare 1
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64
Cabinだと1014個もデータに欠損があることがわかります。
次に全体の統計データを確認してみましょう。
# 統計データの確認
dataset.describe()
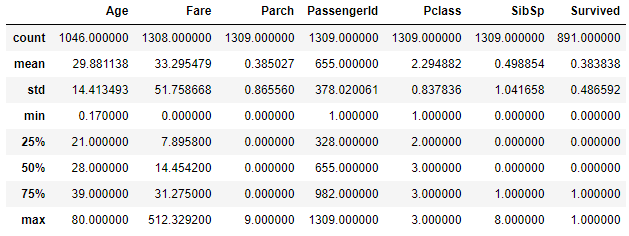
まずは欠損データに中央値などを代入して精度を確認します。
# Cabin は一旦除外
del dataset["Cabin"]
# Age(年齢)とFare(料金)はそれぞれの中央値、Embarked(出港地)はS(Southampton)を代入
dataset["Age"].fillna(dataset.Age.mean(), inplace=True)
dataset["Fare"].fillna(dataset.Fare.mean(), inplace=True)
dataset["Embarked"].fillna("S", inplace=True)
# 全体の欠損データの個数を確認
dataset_null = dataset.fillna(np.nan)
dataset_null.isnull().sum()
Age 0
Embarked 0
Fare 0
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64
これで欠損データはなくなりました。
Survivedの418は、testデータの418個と一致しているので問題ないでしょう。
予測に向け、データを整理します。
まずはPclass(チケットクラス), Sex(性別), Age(年齢), Fare(料金), Embarked(出港地)を使用します。
また、機械が予測できるようにダミー変数に変換します。
(現在、sexの項目はmaleとfemaleがありますが、これを行うことでsex_maleとsex_femaleの2つに変換されます。maleならsex_maleが1、違うなら0が代入されます。)
# 使用する変数のみを抽出
dataset1 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked']]
# ダミー変数を作成
dataset_dummies=pd.get_dummies(dataset1)
dataset_dummies.head(3)

機械に学習をさせていきます。
RandomForestClassifierのn_estimatorsとmax_depthを変えるなかで最も良い予測モデルを作成します。
# データをtrainとtestに分解
# ( 'Survived'が存在するのがtrain, しないのがtest )
train_set = dataset_dummies[dataset_dummies['Survived'].notnull()]
test_set = dataset_dummies[dataset_dummies['Survived'].isnull()]
del test_set["Survived"]
# trainデータを変数と正解に分離
X = train_set.as_matrix()[:, 1:] # Pclass以降の変数
y = train_set.as_matrix()[:, 0] # 正解データ
# 予測モデルの作成
clf = RandomForestClassifier(random_state = 10, max_features='sqrt')
pipe = Pipeline([('classify', clf)])
param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す
'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す
grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10)
grid.fit(X, y)
print(grid.best_params_, grid.best_score_, sep="\n")
{'classify__max_depth': 8, 'classify__n_estimators': 23}
0.8316498316498316
max_depthが8, n_estimatorsが23のとき、トレーニングデータの予測精度が83%となる最も良いモデルだと分かりました。
このモデルでtestデータの予測を行い、提出用ファイル(submission1.csv)を作成します。
# testデータの予測
pred = grid.predict(test_set)
# Kaggle提出用csvファイルの作成
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)})
submission.to_csv("submission1.csv", index=False)
実際に提出してみたところ、スコアは0.78468でした。
いきなり高い予測が出ちゃいました。
今度はParch(同乗している親/子供の数), SibSp(同乗している兄弟/配偶者の数)を加えて予測します。
# 使用する変数を抽出
dataset2 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Parch', 'SibSp']]
# ダミー変数を作成
dataset_dummies = pd.get_dummies(dataset2)
dataset_dummies.head(3)

# データをtrainとtestに分解
# ( 'Survived'が存在するのがtrain, しないのがtest )
train_set = dataset_dummies[dataset_dummies['Survived'].notnull()]
test_set = dataset_dummies[dataset_dummies['Survived'].isnull()]
del test_set["Survived"]
# trainデータを変数と正解に分離
X = train_set.as_matrix()[:, 1:] # Pclass以降の変数
y = train_set.as_matrix()[:, 0] # 正解データ
# 予測モデルの作成
clf = RandomForestClassifier(random_state = 10, max_features='sqrt')
pipe = Pipeline([('classify', clf)])
param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す
'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す
grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10)
grid.fit(X, y)
print(grid.best_params_, grid.best_score_, sep="\n")
# testデータの予測
pred = grid.predict(test_set)
# Kaggle提出用csvファイルの作成
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)})
submission.to_csv("submission2.csv", index=False)
{'classify__max_depth': 7, 'classify__n_estimators': 25}
0.8417508417508418
max_depthが7, n_estimatorsが25のとき、トレーニングデータの予測精度が84%となる最も良いモデルだと分かりました。
先程より高い精度ですが、このモデルでのtestデータ予測(submission2.csv)を提出したところ、スコアが0.76076と下がっていしまいました。
過学習を起こしてしまったようです。
Parch(同乗している親/子供の数), SibSp(同乗している兄弟/配偶者の数)は使用しないほうが良さそうです。
5.まとめ
Kaggleのチュートリアルコンペ Titanic の予測を行いました。
提出最高スコアは0.78468でした。
次回はデータを可視化して提出スコア0.83732への過程を説明していきます。