前回に続き、Kaggle Titanicで上位1.5%(0.83732)へのアプローチを解説していきます。
使用するコードはGithubのtitanic(0.83732)_2です。
今回、提出スコアを0.81339まで伸ばし、次回に0.83732となる準備をしていきます。
また、予測の前に、前回使用したデータの可視化を行い、データを分析していきます。
1.必要なライブラリをインポートし、CSVを読み込む。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline,make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn import model_selection
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings('ignore')
# CSVを読み込む
train= pd.read_csv("train.csv")
test= pd.read_csv("test.csv")
# データの統合
dataset = pd.concat([train, test], ignore_index = True)
# 提出用に
PassengerId = test['PassengerId']
各データの関係性を見ていきます。
2.年齢と生存率に関係を確認
# 年齢と生存率の帯グラフ
sns.barplot(x="Sex", y="Survived", data=train, palette='Set3')
# 性別ごとの生存率
print("females: %.2f" %(train['Survived'][train['Sex'] == 'female'].value_counts(normalize = True)[1]))
print("males: %.2f" %(train['Survived'][train['Sex'] == 'male'].value_counts(normalize = True)[1]))
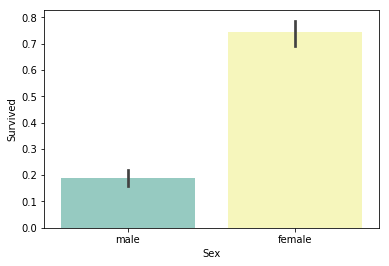
females: 0.74
males: 0.19
女性のほうがはるかに助かってることが分かります。
チケットクラスごとの生存率はどうでしょう?
3.チケットクラスごとの生存率の関係を確認
# チケットクラスと生存の帯グラフ
sns.barplot(x='Pclass', y='Survived', data=train, palette='Set3')
# チケットクラスごとの生存率
print("Pclass = 1 : %.2f" %(train['Survived'][train['Pclass']==1].value_counts(normalize = True)[1]))
print("Pclass = 2 : %.2f" %(train['Survived'][train['Pclass']==2].value_counts(normalize = True)[1]))
print("Pclass = 3 : %.2f" %(train['Survived'][train['Pclass']==3].value_counts(normalize = True)[1]))
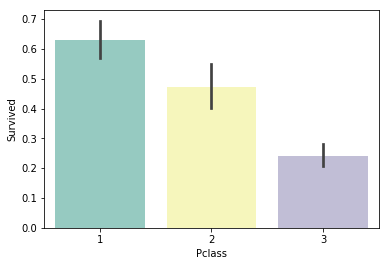
Pclass = 1 : 0.63
Pclass = 2 : 0.47
Pclass = 3 : 0.24
高級なチケット購入者であるほど生存率が高いです。
料金についてはどうでしょう?
4.料金による生存率の関係を確認
# 料金による生存率比較
fare = sns.FacetGrid(train, hue="Survived",aspect=2)
fare.map(sns.kdeplot,'Fare',shade= True)
fare.set(xlim=(0, 200))
fare.add_legend()
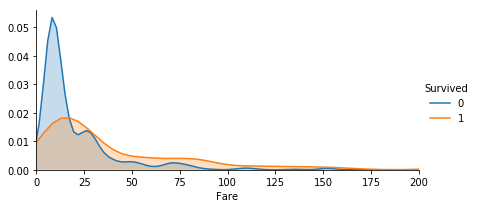
やはりチケット料金が安い人は生存率が低いことが分かります。
5.年齢と生存率の関係を確認
# 年齢による生存率比較
age = sns.FacetGrid(train, hue="Survived",aspect=2)
age.map(sns.kdeplot,'Age',shade= True)
age.set(xlim=(0, train['Age'].max()))
age.add_legend()
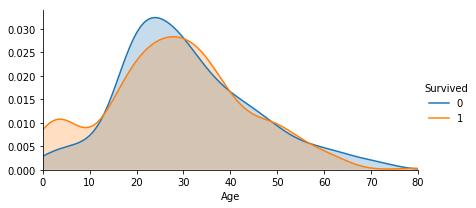
子供が優先的に助けられたのでしょうか?
10才以下の生存率が高いことが分かります。
6.客室と生存率の関係を確認
ここからは、前回使用しなかったデータを確認していきます。
まずは客室情報です。
Cabin(部屋番号)は頭文字に応じて部屋の階層が異なっていたようです。
# 客室階層による生存率比較
dataset['Cabin'] = dataset['Cabin'].fillna('Unknown') # 客室データが欠損している場合はUnknownを代入
dataset['Deck'] = dataset['Cabin'].str.get(0) #Cabin(部屋番号)の頭文字(0番目の文字)取得
sns.barplot(x="Deck", y="Survived", data=dataset, palette='Set3')
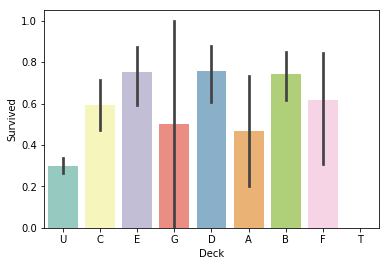
それなりにバラつきがあります。
前回同様、欠損値に中央値を代入して欠損値がないことを確認したら、今回作った'Deck'(客室階層)情報を追加して予測を行います。
6.1 客室情報を追加して前回と同じように予測を行う
# Age(年齢)とFare(料金)はそれぞれの中央値、Embarked(出港地)はS(Southampton)を代入
dataset["Age"].fillna(dataset.Age.mean(), inplace=True)
dataset["Fare"].fillna(dataset.Fare.mean(), inplace=True)
dataset["Embarked"].fillna("S", inplace=True)
# 全体の欠損データの個数確認
dataset_null = dataset.fillna(np.nan)
dataset_null.isnull().sum()
# 使用する変数を抽出
dataset3 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Deck']]
# ダミー変数を作成
dataset_dummies = pd.get_dummies(dataset3)
dataset_dummies.head(3)
# データをtrainとtestに分解
# ( 'Survived'が存在するのがtrain, しないのがtest )
train_set = dataset_dummies[dataset_dummies['Survived'].notnull()]
test_set = dataset_dummies[dataset_dummies['Survived'].isnull()]
del test_set["Survived"]
# trainデータを変数と正解に分離
X = train_set.as_matrix()[:, 1:] # Pclass以降の変数
y = train_set.as_matrix()[:, 0] # 正解データ
# 予測モデルの作成
clf = RandomForestClassifier(random_state = 10, max_features='sqrt')
pipe = Pipeline([('classify', clf)])
param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す
'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す
grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10)
grid.fit(X, y)
print(grid.best_params_, grid.best_score_)
# testデータの予測
pred = grid.predict(test_set)
# Kaggle提出用csvファイルの作成
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)})
submission.to_csv("submission3.csv", index=False)
{'classify__max_depth': 8, 'classify__n_estimators': 22}
0.8327721661054994
提出したスコアは0.78947でした。客室階層の情報を入れたことで、前回より上がりました。
7.チケットと生存率に関係を確認
次にチケット情報を試してみます。
とはいえ、どうグループ分けしましょう?
数字の頭文字や英字を含むか否か、文字数とそれぞれ場合分けしてもよいのですが、むやみに増やしすぎると精度を落とすことになります。
いったんチケットの文字数で分けて確認してみます。
# チケットの文字数による生存率比較
Ticket_Count = dict(dataset['Ticket'].value_counts()) # チケットの文字数でグループ分け
dataset['TicketGroup'] = dataset['Ticket'].apply(lambda x:Ticket_Count[x]) # グループの振り分け
sns.barplot(x='TicketGroup', y='Survived', data=dataset, palette='Set3')
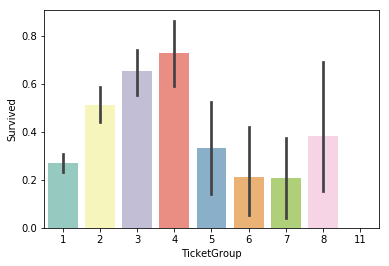
1つ前のCabin(客室階層)分けよりは差が出ています。
7.1 チケットの頭文字情報を追加して予測を行う
# 使用する変数を抽出
dataset4 = dataset[['Survived','Pclass','Sex','Age','Fare','Embarked', 'Deck', 'TicketGroup']]
# ダミー変数を作成
dataset_dummies = pd.get_dummies(dataset4)
dataset_dummies.head(4)
# データをtrainとtestに分解
# ( 'Survived'が存在するのがtrain, しないのがtest )
train_set = dataset_dummies[dataset_dummies['Survived'].notnull()]
test_set = dataset_dummies[dataset_dummies['Survived'].isnull()]
del test_set["Survived"]
# trainデータを変数と正解に分離
X = train_set.as_matrix()[:, 1:] # Pclass以降の変数
y = train_set.as_matrix()[:, 0] # 正解データ
# 予測モデルの作成
clf = RandomForestClassifier(random_state = 10, max_features='sqrt')
pipe = Pipeline([('classify', clf)])
param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す
'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す
grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10)
grid.fit(X, y)
print(grid.best_params_, grid.best_score_, sep="\n")
# testデータの予測
pred = grid.predict(test_set)
# Kaggle提出用csvファイルの作成
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)})
submission.to_csv("submission4.csv", index=False)
{'classify__max_depth': 8, 'classify__n_estimators': 23}
0.8406285072951739
訓練スコアは上がりましたが、Kaggleへの提出スコアは0.77990と下がってしまいました。
そもそも、現実的に考えてチケットの文字数と生存率の相関は薄そうです。
とはいえ、せっかく出た特徴なので、高いグループと低いグループの2つに項目を抑えて学習をしてみます。
7.2 チケットの頭文字情報をグループ分けして予測を行う
# チケットの文字数での生存率が高いグループと低いグループの2つに分ける。
# 高ければ2,低ければ1を代入
def Ticket_Label(s):
if (s >= 2) & (s <= 4): # 文字数での生存率が高いグループ
return 2
elif ((s > 4) & (s <= 8)) | (s == 1): # 文字数での生存率が低いグループ
return 1
elif (s > 8):
return 0
dataset['TicketGroup'] = dataset['TicketGroup'].apply(Ticket_Label)
sns.barplot(x='TicketGroup', y='Survived', data=dataset, palette='Set3')
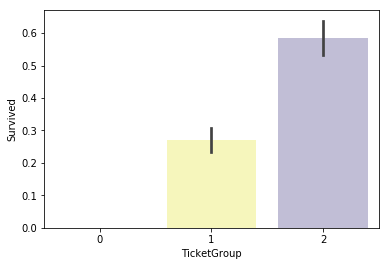
きれいに分かれたように見えます。
# データをtrainとtestに分解
# ( 'Survived'が存在するのがtrain, しないのがtest )
train_set = dataset_dummies[dataset_dummies['Survived'].notnull()]
test_set = dataset_dummies[dataset_dummies['Survived'].isnull()]
del test_set["Survived"]
# trainデータを変数と正解に分離
X = train_set.as_matrix()[:, 1:] # Pclass以降の変数
y = train_set.as_matrix()[:, 0] # 正解データ
# 予測モデルの作成
clf = RandomForestClassifier(random_state = 10, max_features='sqrt')
pipe = Pipeline([('classify', clf)])
param_test = {'classify__n_estimators':list(range(20, 30, 1)), #20~30を1刻みずつ試す
'classify__max_depth':list(range(3, 10, 1))} #3~10を1刻みずつ試す
grid = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='accuracy', cv=10)
grid.fit(X, y)
print(grid.best_params_, grid.best_score_, sep="\n")
# testデータの予測
pred = grid.predict(test_set)
# Kaggle提出用csvファイルの作成
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": pred.astype(np.int32)})
submission.to_csv("submission5.csv", index=False)
{'classify__max_depth': 7, 'classify__n_estimators': 23}
0.8417508417508418
Kaggleへの提出スコアは0.81339と大きく向上しました。
8.まとめ
今回、新たに客室階層の情報とチケットの頭文字による生存率が高いグループと低いグループの2つに分けた情報を加えたことで、前回の提出スコア0.78468から0.81339と向上させました。
次回はいよいよ上位1.5%に相当する提出スコア0.83732へのアプローチを解説していきます。