はじめに
結果を先に申し上げると、うまく学習できていません。アドバイスをいただけると非常に助かります。
本記事は全4回の連載のうちの第2回です。
前回の記事はこちら。
AlphaGoを模したオセロAIを作る(1): SLポリシーネットワーク - Qiita
また、ソースコードの全文はこちらにあります。
さて、前回棋譜を学習させたSLポリシーネットワークを、自己対戦による強化学習でさらに強いRLポリシーネットワークにしていきます。
Supervised LearningにReinforcement Learningを加えるということです。
ライブラリとしてChainerRLを使うのでご用意ください。
$ pip install chainerrl
アルゴリズム
方策関数としてSLポリシーネットワークを用いたREINFORCEアルゴリズムを使います。
REINFORCEは方策勾配法の一種です。
全体の流れと、強化学習アルゴリズムをそれぞれ説明していきます。
全体
全体の流れをフローチャートにしました。
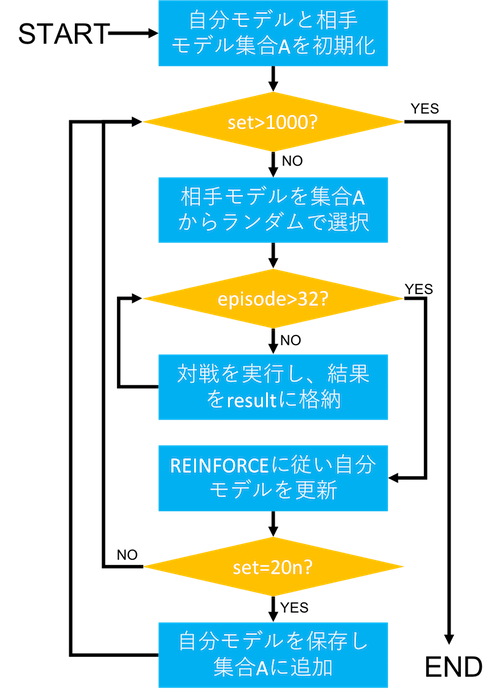
最初に、自分のモデルと相手のモデル集合をSLポリシーネットワークで初期化します。
次に、相手のモデル集合からランダムに選んで相手のモデルを設定します。
同じ相手と32回対戦(先手後手は入れ替える)し、その対戦結果と盤面の履歴からREINFORCEに従って自分モデルを更新します。
この32回の対戦を1セットとして、1000セット繰り返します。
また、20セットごとに自分モデルを保存して相手モデル集合に追加します。こうすることで、相手モデルのバリエーションが少しずつ増えていきます。
方策勾配法
SarsaやQ学習のように行動価値関数を更新するのではなく、期待収益$J(\theta)$を最大化するように、パラメータ$\theta$で定められた方策$\pi_{\theta}$を直接最適化していくという学習の方針です。
方策$\pi_{\theta}$は、ここではSLポリシーネットワークで、パラメータ$\theta$はネットワークの重みです。
$J(\theta)$を最大化するには、$\theta$を勾配$\nabla_{\theta}J(\theta)$に従って繰り返し更新します。
\theta \leftarrow \theta + \eta\nabla_{\theta}J(\theta)
$\eta$は学習率(ステップサイズ)です。
さて、方策勾配定理によると、次の式が成り立ちます。
\begin{eqnarray}
\nabla_{\theta}J(\theta) &=& \textrm{E}\Bigl[ \frac{\partial\pi_{\theta}(a|s)}{\partial\theta}\frac{1}{\pi_{\theta}(a|s)}Q^{\pi}(s,a) \Bigr]\\
&=& \textrm{E}\Bigl[ \nabla_{\theta}\log{\pi_{\theta}}(a|s)Q^{\pi}(s,a) \Bigr]
\end{eqnarray}
$Q^{\pi}$は方策を$\pi$に固定した時の行動価値関数です。$a$と$s$はそれぞれ行動と状態です。
REINFORCE
$Q(s,a)$を、実際にサンプリングした報酬$R_{t}$で近似します。
$t$はステップ、$m$はエピソードの番号を表します。
\nabla_{\theta}J(\theta)\approx \frac{1}{M}\sum_{m=1}^{M}\frac{1}{T}\sum_{t=1}^{T}\nabla_{\theta}\log\pi_{\theta}(a_{m,t}|s_{m,t})R_{m,t}
報酬$R_{m,t}$は、勝ちなら+1、負けなら-1、引き分けなら0とします。
したがって、同じエピソード$m$内では、報酬$R_{m,t}$はステップ数$t$に関わらず同じ値となります。
しかし、このままだと推定値の分散が大きく学習を阻害してしまいます(悪手を指しても、最終的に勝てば良手と判断されるといったことです)。
これを防ぐために、ベースライン除去というテクニックを用いて、期待値をそのままに分散を小さくします。
\nabla_{\theta}J(\theta)\approx \frac{1}{M}\sum_{m=1}^{M}\frac{1}{T}\sum_{t=1}^{T}\nabla_{\theta}\log\pi_{\theta}(a_{m,t}|s_{m,t})(R_{m,t}-b)
ベースライン$b$としては、報酬の平均がよく用いられます。
b = \frac{1}{M}\sum_{m=1}^{M}\frac{1}{T}\sum_{t=1}^{T}R_{m,t}
ただし、今回は$b=0$としました。
以上によって求めた$\nabla_{\theta}J(\theta)$に従って、ネットワークの重み$\theta$を更新していきます。
\theta \leftarrow \theta + \eta\nabla_{\theta}J(\theta)
実装
ChainerRLを使うには、ゲームを実行する学習ループに加えて、報酬や観測する状態を与え行動の結果を反映するための環境クラスが必要になります。
ゲーム環境の定義
環境クラスは、初期化をするreset関数と行動の結果を反映し次の状態と報酬などを返すstep関数が最低限必要です。
なお、報酬はエピソード終了時に判明する試合結果にするので、ステップごとの報酬は0としておきます(終了後に更新します)。
class GameEnv:
def __init__(self, model1, model2):
# 盤面の初期化
self.state = cp.zeros([8, 8], dtype=np.float32)
self.state[4, 3] = 1
self.state[3, 4] = 1
self.state[3, 3] = 2
self.state[4, 4] = 2
# ゲーム内変数の初期化
self.stone_num = 4
self.pass_flg = False
# モデルをセット
self.model1 = model1
self.model2 = model2
def reset(self):
# 盤面の初期化
self.state = np.zeros([8, 8], dtype=np.float32)
self.state[4, 3] = 1
self.state[3, 4] = 1
self.state[3, 3] = 2
self.state[4, 4] = 2
# ゲーム内変数の初期化
self.stone_num = 4
self.pass_flg = False
# 初期状態を返す
X = np.stack([self.state==1, self.state==2], axis=0).astype(np.float32)
obs = chainer.Variable(X.reshape(2,1,8,8).transpose(1,0,2,3))
return obs
def step(self, action):
done = False
positions = self.valid_pos(1)
if len(positions)>0:
position = [action//8+1, action%8+1]
if not position in positions:
# 違法手が入力された場合は合法手からランダムに選びなおす
position = random.choice(positions)
self.place_stone(position, 1)
self.stone_num += 1
self.pass_flg = False
else:
if self.pass_flg:
done = True
self.pass_flg = True
# 相手のターン
positions = self.valid_pos(2)
if len(positions)>0:
position = self.get_position(2, positions)
self.place_stone(position, 2)
self.stone_num += 1
self.pass_flg = False
else:
if self.pass_flg:
done = True
self.pass_flg = True
if self.stone_num>=64:
done = True
X = np.stack([self.state==1, self.state==2], axis=0).astype(np.float32)
obs = chainer.Variable(X.reshape(2,1,8,8).transpose(1,0,2,3))
# 観測された状態、報酬(ダミー)、試合が終了したかどうか、追加情報(なし)
return obs, 0, done, None
# Whole game
def __call__(self):
return self.judge()
学習ループ
次に、強化学習本体のコードを書きます。
import argparse
import glob
import numpy as np
import copy
from tqdm import tqdm
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import serializers, cuda, optimizers, Variable
from chainer.cuda import cupy as cp
from chainer.functions.loss.softmax_cross_entropy import softmax_cross_entropy
import chainerrl
import SLPolicy
import rl_env
def main():
# セット数を設定
parser = argparse.ArgumentParser(description='IaGo:')
parser.add_argument('--set', '-s', type=int, default=1000, help='Number of game sets played to train')
args = parser.parse_args()
N = 32
# モデル定義
model1 = L.Classifier(SLPolicy.SLPolicyNet()) # 更新する方のモデル
serializers.load_npz("./models/rl/model0.npz", model1)
optimizer = optimizers.Adam()
optimizer.setup(model1)
optimizer.add_hook(chainer.optimizer_hooks.WeightDecay(5e-4))
# REINFORCEアルゴリズム(後述)
agent = chainerrl.agents.MyREINFORCE(model1, optimizer, batchsize=2*N,
backward_separately=True)
for set in tqdm(range(args.set)):
# 対戦相手のモデルは集合Aからランダムに選択
model2 = L.Classifier(SLPolicy.SLPolicyNet())
model2_path = np.random.choice(glob.glob("./models/rl/*.npz"))
print(model2_path)
serializers.load_npz(model2_path, model2)
env = rl_env.GameEnv(agent.model, model2)
result = 0 # 勝った数
for i in tqdm(range(2*N)):
obs = env.reset()
if i%2==1:
# iが奇数の時に先手後手を入れ替える
pos = random.choice([[2,4], [3,5], [4,2], [5,3]])
env.state[pos[0], pos[1]] = 2
X = np.stack([env.state==1, env.state==2], axis=0).astype(np.float32)
obs = chainer.Variable(X.reshape(2,1,8,8).transpose(1,0,2,3))
reward = 0
done = False
while not done:
action = agent.act_and_train(obs, reward)
obs, reward, done, _ = env.step(action)
judge = env()
#agentが持つダミーの報酬を対戦結果に基づいて更新する
agent.reward_sequences[-1] = [judge]*len(agent.log_prob_sequences[-1])
if judge==1:
result += 1
# 2*N回対戦したらモデルを更新
agent.stop_episode_and_train(obs, judge, done=True)
# 勝率を出力
print("\nSet:" + str(set) + ", Result:" + str(result/(2*N)))
with open("./log_rl.txt", "a") as f:
f.write(str(result/(2*N))+", \n")
# 保存
if (set+1)%20==0:
model = copy.deepcopy(agent.model)
serializers.save_npz("./models/rl/model"+str((set+1)//20)+".npz", model)
serializers.save_npz("./models/rl_optimizer.npz", agent.optimizer)
if __name__ == '__main__':
main()
ChainerRLを少しだけ書き換える
今のコードで、agent = chainerrl.agents.MyREINFORCEとありますが、これは自分で作成したものです。
もともとはagent = chainerrl.agents.REINFORCEとしていたのですが、このようなエラーが出てしまいました。
Traceback (most recent call last):
File "reinforce.py", line 80, in <module>
main()
File "reinforce.py", line 55, in main
action = agent.act_and_train(obs, reward)
File "C:\Users\XXX\Anaconda3\lib\site-packages\chainerrl\agents\reinforce.py", line 79, in act_and_train
action_distrib = self.model(batch_obs)
File "C:\Users\XXX\Anaconda3\lib\site-packages\chainer\links\model\classifier.py", line 114, in __call__
self.y = self.predictor(*args, **kwargs)
TypeError: __call__() missing 1 required positional argument: 'x'
この原因がわからず、邪道ですがライブラリを書き換えることにしました。
chainerrl/agents/reinforce.pyをコピーして、act_and_train関数を少しだけ書き換えます。
class MyREINFORCE(agent.AttributeSavingMixin, agent.Agent):
'''中略'''
def act_and_train(self, obs, reward):
#batch_obs = self.batch_states([obs], self.xp, self.phi)
action_distrib = distribution.SoftmaxDistribution(self.model.predictor(obs))
batch_action = action_distrib.sample().data # Do not backprop
action = chainer.cuda.to_cpu(batch_action)[0]
'''中略'''
return action
'''後略'''
それから、chainerrl/agents/__init__.pyに今のクラスを追加します。
'''前略'''
from chainerrl.agents.reinforce import REINFORCE # NOQA
from chainerrl.agents.my_reinforce import MyREINFORCE
'''後略'''
これで終わりです!reinforce.pyを実行してみましょう!
結果
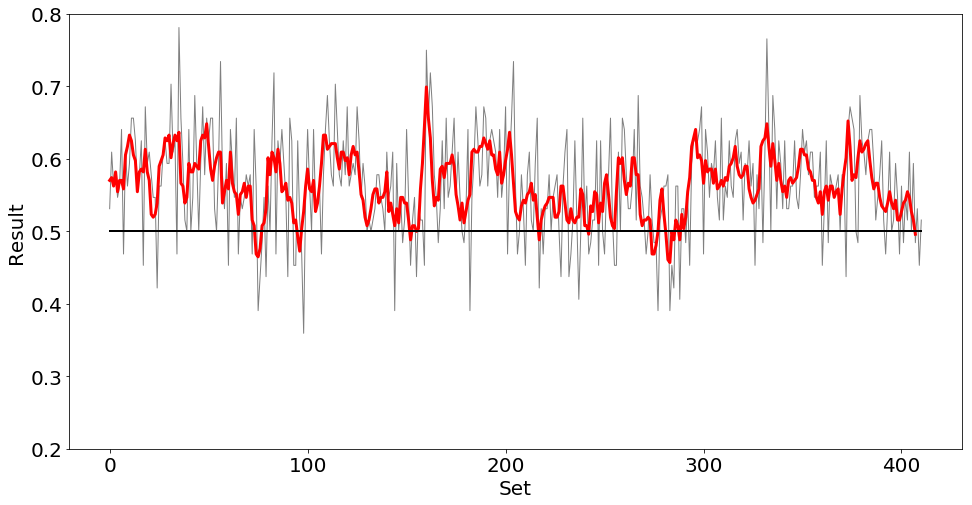
モデルの更新はちゃんと行われていて、強くなっているときもあるようですが、悪い方向に学習してしまうこともしばしばありました。
一度モデルが劣化すると、その後に得られる報酬の質も下がるため、スランプから抜けるのが難しいということがあるようです。
あまりうまくいっていないようなので400セットで学習を打ち切りました。
セットごとの勝率の推移をプロットしたものが次の図です。グレーの線が勝率で、赤線がその4セットの移動平均です。
アドバイスをいただけると幸いです。
次回記事はこちら。
AlphaGoを模したオセロAIを作る(3): バリューネットワーク - Qiita
参考文献
[1] D. Silver et al., "Mastering the game of Go with deep neural networks and tree search," nature, Vol. 529, No. 7587, pp. 484-489, 2016.
DeepMindによるAlphaGoの論文です。
[2] 大槻知史, 三宅陽一郎, 『最強囲碁AI アルファ碁 解体新書 深層学習、モンテカルロ木探索、強化学習から見たその仕組み』, 翔泳社, 2017.
原著論文[1]の解説書です。非常にわかりやすかったです。
[3] 牧野貴樹 他, 『これからの強化学習』, 森北出版, 2016
ディープラーニング以降の強化学習の本でしたら、これが一番いいと思います。
[4] ChainerRLで三目並べを深層強化学習(Double DQN)してみた - Qiita
やりたいことは近いのですが、Double DQNなのでアルゴリズムが違います。
[5]ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
本家Preferred Networksによるスライドです。
[6]将棋でディープラーニングする その29(強化学習【修正版】) - TadaoYamaokaの日記
この方はChainerRLを使わず、Chainerのみで強化学習を実装しています。これを参考に私も試してみましたが、あまり結果は変わりませんでした(ソースコード)。