とあるきっかけで、環境音の認識(歩く音や雨の音、掃除機の音など)について、
論文を調べたので、メモとして残しておきます。
せっかくなので、精度向上の歴史を振り返る形式で、書いていきます。
データセット
精度の基準となるデータセットをご紹介します。画像の認識では、ImageNetという圧倒的な
データセットがあり、性能評価で用いられます。
一方、音の認識はImageNetほど巨大ではありませんが、ESC-50というデータセットが
あります。今回の基準となるESC-50の概要は以下のとおりです。
- 犬の鳴き声やドアのノック音など50種類、2000個の音源を収録
- 音源の長さは5秒間
- 精度評価をするときは、学習用とテスト用に分けて(5-foldなど)それぞれ評価
音の前処理
画像の前処理は、通常255で割れば良く、非常に簡単です。
一方、音の前処理は通常logmelを用います。logmelで処理することにより、音の生波形を
周波数と時間方向で表現でき、音を画像として扱うことができます。
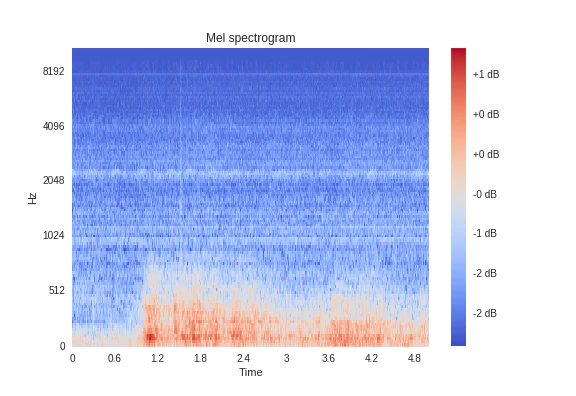
詳しくはこちらをご覧ください。
ただ、logmelで十分なのか?という議論があり、ここは後述するように
精度向上のポイントになってきます。
精度向上の歴史
(精度:64.5%)logmel-CNN
前述したように、音をlogmelにすることで音を画像として扱うことができます。
画像の認識では、畳み込みニューラルネットワーク(CNN)を使うことで認識精度が
一気に向上しました。そして、音でも同じ効果があるのか検証したのが、logmel-CNNです。
ENVIRONMENTAL SOUND CLASSIFICATION WITH CONVOLUTIONAL NEURAL NETWORKS
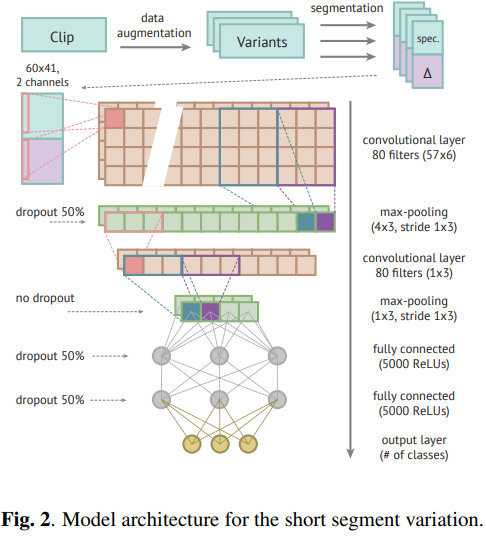
図は[1]より
・CNN2層と全結合層2層、活性化関数はReLU
・Dropoutも使用
・0.95秒ごとに音をlogmelに変換
・さらに入力は、周波数の動的変化を捉えるΔlogmelも加え2chとした(下図参照)


図は[1]より
(精度:71%)EnvNet
冒頭で触れたように、音の前処理はlogmelで良いのか?という疑問に真正面から
挑んだのがEnvNetです。
LEARNING ENVIRONMENTAL SOUNDS WITH END-TO-END CONVOLUTIONAL NEURAL NETWORK

図は[2]より
・logmelを使わずにCNNで直接特徴を抽出させる
・1.5secの窓をスライドさせながら、音を学習させる
・テスト時の評価は、窓をスライドさせながらvotingによって分類させる
・EnvNet単独でlogmel-CNNを上回る精度
・さらに、EnvNetとlogmelを組み合わせ大幅な精度向上に寄与(下の表参照)
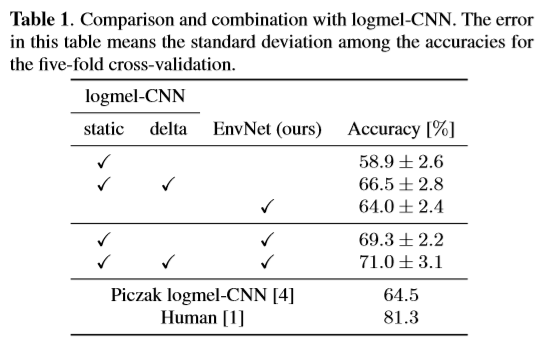
表は[2]より
・学習済のモデルにサインカーブを入れることで、どの周波数帯が反応しているのか調査
・その結果、logmelと似たような特徴抽出ができた(下の図参照)
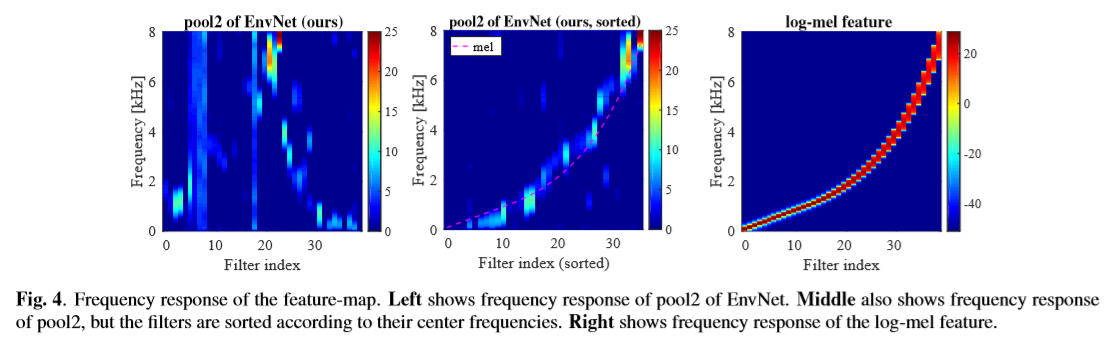
図は[2]より
・ただ、特徴抽出はlogmelと全く同じではなく、そこがlogmelを上回った要因ともいえる
・音以外のデータでも使える可能性を示唆(振動のデータなんかにも使えそう!?)
おまけ
logmelに頼らない手法として以下の研究もあります。
- Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms
- Very Deep Convolutional Neural Networks for Raw Waveforms
(精度:85%)BC learning
画像の認識問題では、データを水増し(拡張)するmixupという手法が一般的になっています。
これにより、精度がかなり向上します。BC learningはこれを音に適用した研究です。
LEARNING FROM BETWEEN-CLASS EXAMPLES FOR DEEP SOUND RECOGNITION
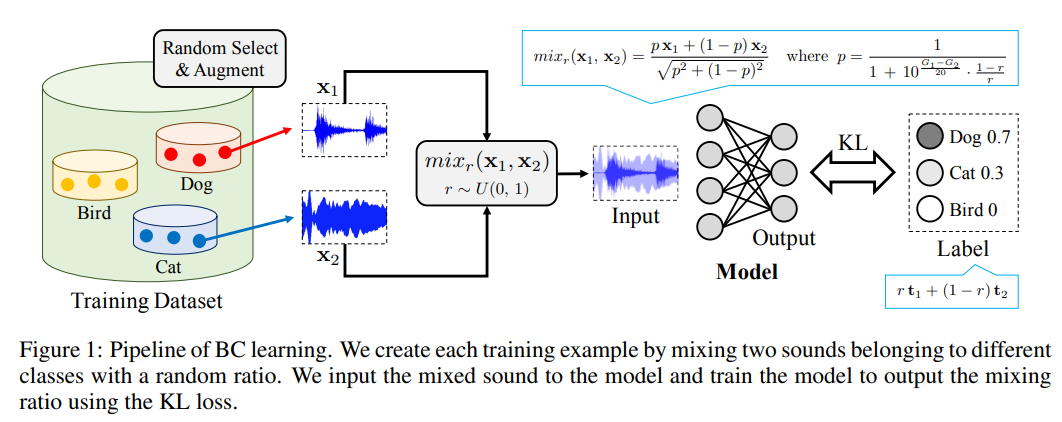
図は[3]より
・音の生波形を混ぜる。ただし、比率は音圧を考慮して決定
・通常の手法に対し、5%ほど精度向上(下の表参照)

表は[3]より(数字はエラー率)
・ただし、表のEnvNet-v2は前述のEnvNetの層をより深くしたもの
・損失関数はクロスエントロピーではなく、KL-divergenceを採用
・間接的に、FISHER’S CRITERION を拡大することに繋がっている(下図参照)
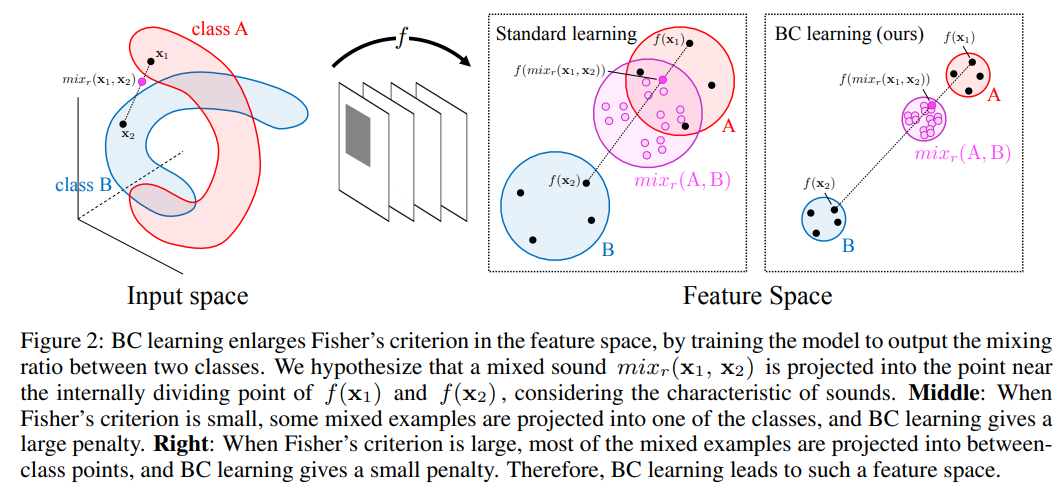
図は[3]より
(精度:95%)PANNs
巨大な音データ(AudioSet)で学習させた学習済モデルを、転移学習(fine-tuning)
させたのがPANNsです。画像では転移学習が有効なことが示されており、音でもそれが
効くのか検証した研究です。
PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
・AudioSet(632種類、200万!の音)で学習したモデルを提案。
・転移学習により、ほとんどのデータセットでSOTAを超える性能。
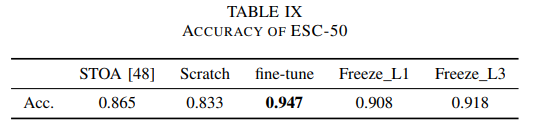
表は[4]より(STOA→SOTAか?)
・入力は「logmel」と「生波形を1D-CNNで処理したもの」を結合(下図参照)
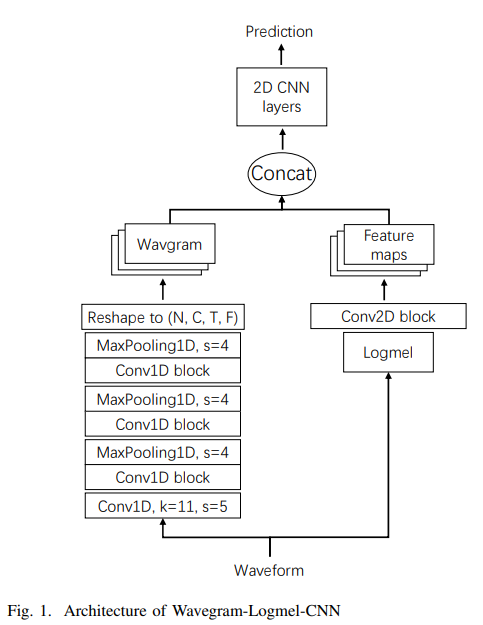
図は[4]より
・データ拡張はmixup + SpecAugment
・その他に、logmelで学習させたMobileNetやResNetを提供。
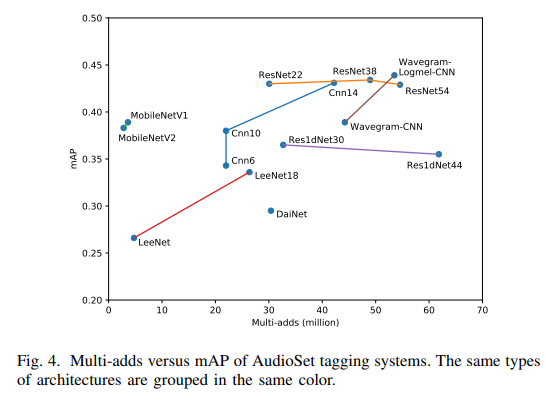
図は[4]より
・図の一番上、Wavegram-Logmel-CNNが提案した新モデル。
学習済モデル
前述したとおり、環境音の認識でも転移学習が有効なことが分かりました。
以下に、転移学習に使えるモデルを示しておきます。
-
VGGish
割と古いモデルらしいですが、最近でも良く使われるようです。
入力時間に縛られない自由度の高さがよいです。 -
PANNs
前述した最先端のモデルです。非常に巨大なデータで学習させたモデルです。
MobileNetからResNet、そして、提案モデルまで様々なモデルがダウンロード可能です。
(考察)mixup vs BC learning
データ拡張は、最新のモデルにおいて mixup + SpecAugmentとなっています。
これは、2019年に行われたKaggleのコンペでも同じ手法が用いられているため、
現在の主流といえます。
ただ、mixupの同じような手法として、BC learningがあります。両者の本質的な
中身は同じですが、どちらを用いた方がよいのでしょうか?これらのメリットを
挙げると以下になるかと思います。
- mixupは生波形を一度logmelにしてしまえば、画像として扱えるためメモリに優しい
- BC learningは前述したように、音圧を考慮しているため、音圧に差があるデータでは有効
まとめると、音圧に差がある場合はBC learningを用いた方が良いかもしれません。
それ以外の場合は、mixupで十分かと思います。SpecAugmentは有効になるケースと
ならないケースがあると思われますが、入れておいて損はないかと思います。
ただ、データ拡張は学習時間が長くなるため、注意が必要です。
まとめ
- やはり転移学習が強い
- そして、データ拡張もなくてはならない技術で、今の主流はmixup + SpecAugment
- logmelで前処理するのが主流だが、1D-CNNで処理する技術も精度向上に貢献している
最後に
冒頭のきっかけとは、DCASE2020のTask2、異常音コンペのことでした。
機械音の異常検知チャレンジ DCASE 2020 Task 2
私事ですが、このコンペに参加することにしました。人生初参加のコンペとなります。
本稿で挙げた技術をゴリゴリ使って精度向上を目指していきます!
ちなみに、本稿でも紹介した以下の外部リソースは、コンペでも使用可能となっています。
これをどう使っていくのか、コンペ攻略のカギになりそうです。
自分のスコアも気になりますが、個人的に専門でやっているところなので、
1st Solutionが一番気になるところです。興味がある人は、是非ご参加ください。
参考文献
[1]Karol J. Piczak. ENVIRONMENTAL SOUND CLASSIFICATION WITH CONVOLUTIONAL NEURAL NETWORKS
[2]Yuji Tokozume, Tatsuya Harada. LEARNING ENVIRONMENTAL SOUNDS WITH END-TO-END CONVOLUTIONAL NEURAL NETWORK
[3]Yuji Tokozume, Yoshitaka Ushiku, Tatsuya Harada.
LEARNING FROM BETWEEN-CLASS EXAMPLES FOR DEEP SOUND RECOGNITION
[4]Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, Mark D. Plumbley. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition