 (DCASEホームページより)
(DCASEホームページより)
はじめに
音を題材とした異常検知のデータセットによる機械学習コンペが始まりました。
音に関するコンペ自体が珍しいなか、タスクとして一般的な分類などでもなく、更に難しい異常検知が設定されました。
個人的に2019年に画像の異常検知に積極的に取り組んだのですが、音声は周波数領域に変換すると画像のように取り扱えることから、チャレンジしたい題材でした。下記は画像にチャレンジしたときの記事です。
- 欠陥発見! MVTec異常検知データセットへの深層距離学習(Deep Metric Learning)応用
- 深層距離学習(Deep Metric Learning)各手法の定量評価 (MNIST/CIFAR10・異常検知)
この記事では、そのコンペ「DCASE 2020 Task 2 Unsupervised Detection of Anomalous Sounds for Machine Condition Monitoring」(機械の状態監視のための教師なし異常音検知)をご紹介したいと思います。
- データの読み解きが主な内容です。
- 解法をいくつか試しましたが、ここでは基本的内容をご紹介します。残念ながらBaselineは超えていません。
- つまり難しいです^^; 面白いですよ!
更新履歴
2020.6.3 テストデータが公開されました! ダウンロードの方法など更新。
2020.4.13 JupyterのカーネルにAnacondaの環境を追加する方法を追記。
2020.4.2 追加のデータが公開されました! ダウンロードの方法など更新。
2020.3.23 Kaggleに用意したコンテンツについて更新。
2020.3.22 初出時データのサンプリングレートを22kHzと記載、バグ発覚し16kHzと判明 → 実験をやり直し記事修正と画像差し替え。
DCASEについて
DCASE = Detection and Classification of Acoustic Scenes and Events ということで、もともと環境音や音声イベントの検知・分類に関する研究コミュニティのようです。毎年タスクを設定してチャレンジして、技術の研鑽を積んでいるようで僕が知ったきっかけはKaggleでの開催でした。
余談: Kaggleでは「Help us better understand COVID-19」と呼びかけられています。余力ある方、こちらもぜひ!

「Freesound General-Purpose Audio Tagging Challenge」は2018年に開催されたコンペ、音を一つのラベルにタグ付け(分類)するもので、画像分類と同じくCNNが有効でした。このKaggleコンペは、DCASE2018のTask 2だったようです。
「Freesound Audio Tagging 2019」が翌年にも開催され、今度はマルチラベルに分類する問題でした。また、ノイズの多いセット、選り抜かれたセット、というデータセット構成で、単なる分類問題にとどまらない難しいものでした。これもDCASE2019ではTask 2でした。
どちらも楽しく参加できて、皆さんの知識共有も盛んで得るものが多かったものです。そして今年のTask 2は!
…残念ながらKaggleでの開催はなく、DCASE Communityのシステムの中だけになりました。とはいえ、題材がさらに面白い内容になっていて、これはぜひ取り組みたいところです。
データセットを読み解く
・データセット: DCASE 2020 Challenge Task 2 Development Dataset
今回のデータセット、珍しいことに日本発なんです。2019年に日本からリリースされた2つの音の異常検知向けデータセット、それらが組み合わさった内容となっています。取り組みたいと思いつつ日常に流されていたら、2つまとまって取り組みやすい形になってくれました。元々のデータセットを見てみましょう。
- ToyADMOS - おもちゃの車・コンベアなどを対象として、製品検査・故障診断を試みるためのデータセットとして開発されたようです。第三者の解説もあります: 【超初心者向け解説】異常検知用データセット「ToyADMOS」の詳細。
- MIMII - 異常のある工業機械の検査・診断のためのデータセット…言葉にすると全然カタイですね。
どちらも言えることですが、とにかく相当でかくて重いのです。大量にデータが有るのはディープラーニングにとって歓迎かもしれないのですが、**マルチチャンネルだったり条件振りすぎ・やりすぎ感のある日本人気質?**でかなり骨が折れそうな内容^^; ちょっと気軽じゃないんですよ、本格的な研究用途ですから…。
今回嬉しいポイントとして、そこがかなり取り扱いやすくなっています。
- データはサンプリングレート16kHz、モノラル、長さ約10秒に統一。※ToyCarだけ11秒。
- 訂正 librosa誤用のバグでした:
16kHzにダウンサンプリングされている、とありますがフォーマットとしては22kHzです。 - 訂正 同上:
ただしデータを見ると、16kHz以降の領域に内容のあるものも有りました。これは…
- 訂正 librosa誤用のバグでした:
- データサイズは約8GB。元々の何十GBと比べて随分手頃になりました。
- 学習サンプルは正常のみ。テストサンプルには正常・異常が含まれる。
- 音は6種類。バルブ、ポンプ、…馴染みありそうに見えますよね、ふふふ。
- Toy-car (ToyADMOS)
- Toy-conveyor (ToyADMOS)
- Valve (MIMII Dataset)
- Pump (MIMII Dataset)
- Fan (MIMII Dataset)
- Slide rail (MIMII Dataset)
- すべての音は、対象の機械音に環境ノイズ音が混ぜられている。
- 環境ノイズ音は全て実際の工場で録音されたもの。
その他、追加のデータが4/1以降配布される予定だったりしますが、シンプルに見ていきたいので現時点では触れないことにします。
まずは聴いてみよう
聴けるサイトがなかったので、soundcloud.comにアップロードして用意しました。
※ データセットのライセンスは CC BY-NC-SA 4.0 です。
「ToyCar」を例に説明します。3種類の音があります。「Test-Anomaly」=テスト用の異常音、「Test-Normal」=テスト用の正常音、「Train-Normal」学習用の正常音。
それぞれの種類で、1サンプルづつ聴けるように用意したのですが…
どうでしょう、聴き分けられました? 私、無理でした^^; つまり一般人の耳にはどれが正常・異常なのか区別がつかないレベルの難しいデータなのです。そもそも音は見えないだけに画像より判別が難しそうに思えます。(これほどまでにオレオレ詐欺に騙されるのも、音の種類をそれほど聴き分けられないことかもしれません)
だとしても、前回までKaggleで取り扱っていたデータは人が聞けば大体わかりました。
今回のデータは、その点では難しいようです。機械に任せましょう。
★ 4/1 追加データが公開されました
追加されたデータはこのように説明されいてます。
This dataset includes around 1,000 normal samples for each Machine Type and Machine ID used in the evaluation dataset and can be used for model training in advance.
- __(とても重要) リーダーボードの評価セットに使われているMachine IDのデータ__です。
- そのうち正常データのみ利用できて、対応する異常データはない。
- 開発時に学習セットとしてだけ使うこともできますが、評価セットと同じ分布であることが期待されるデータです。
- 一部あるいは全て検証セットで利用することで、ローカル検証セットとして強いデータになるはずです。
※正常のみですが。
- 音のIDがこれまで公開済みのデータと異なり、新しい個体のサンプルです。
- データ数が大く、これまで公開されている開発用のデータとほとんど同じです。これを使わないと性能に大きな差が出るでしょう。
EDAをgithubのノートブックで公開しています。また、Kaggleのデータにはこれから追記します。
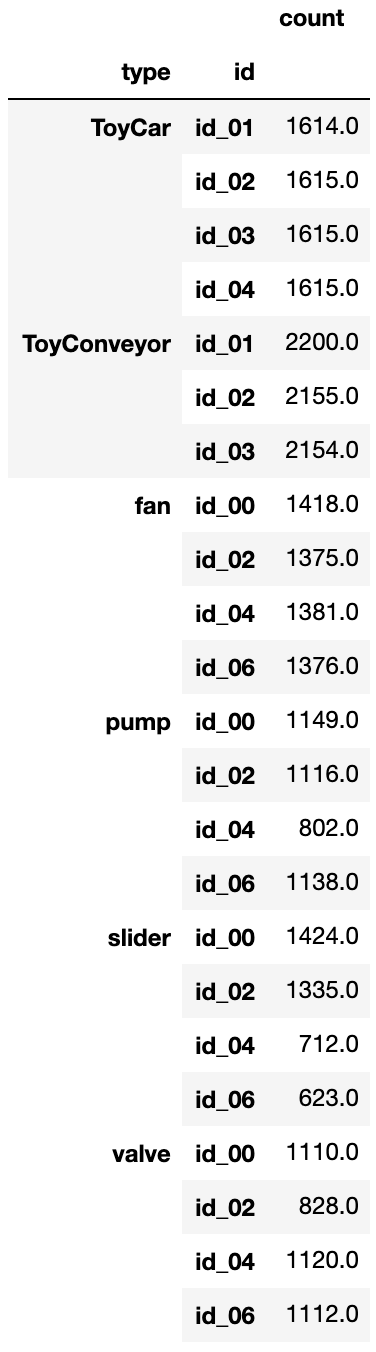

(左:公開済みデータのID別個数 ※train/test合算、右:追加データのID別個数)
Kaggle風に見てみよう - EDA
Kaggleで開催されていたら誰か書いてくれたはずの EDA = Exploratory Data Analysis 探索的にデータを分析してみるノートブック、これを書いてみます。githubに用意しました。
データ数
それぞれの音で学習・テスト別にサンプル数をカウントしてみました。元々ToyADMOSだったデータはテストデータの比率が多いですが、MIMIIだったものは少ないことがわかります。テストの分布、違います。※試験に出るところ
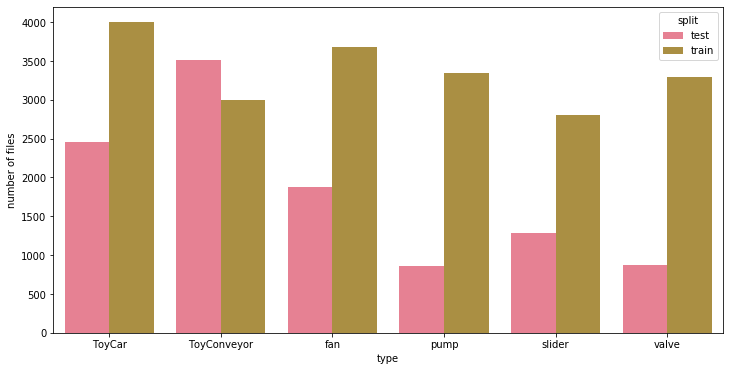
データの一貫性
フォーマットや長さがずれていることはないの? 全てのサンプルを調べてみたところほぼ大丈夫でした。一点だけ注意すべきは、ToyCarだけ長さが11秒でした。他の種類はすべて10秒です。

データの形状
データ長は10秒ありますがその中央1秒を取り出して、FFTをかけた周波数領域・時間領域そのままをプロットしてみました。
一見してはっきりと違いに法則がある様子ではないようです…
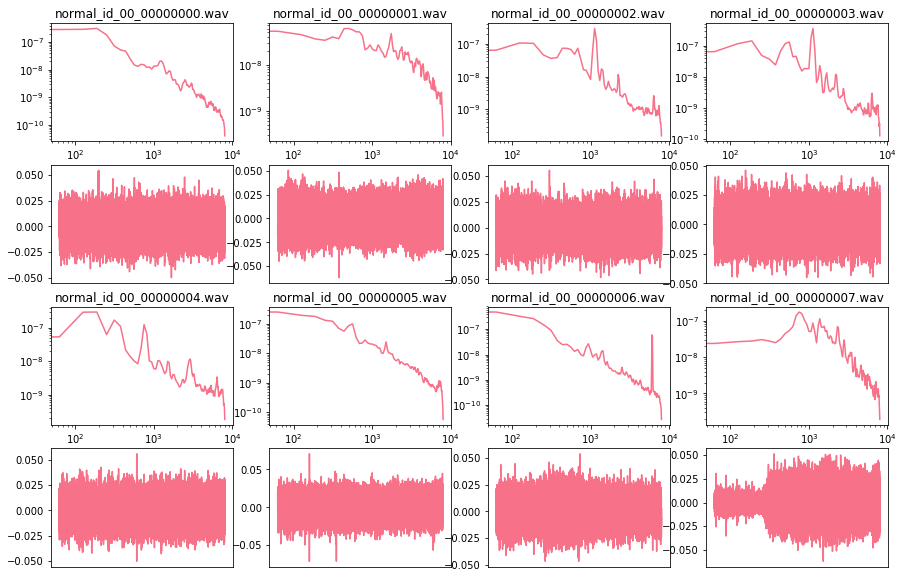
(pumpからのサンプル例 ↑学習セットの正常サンプル ↓テストセットの異常サンプル)
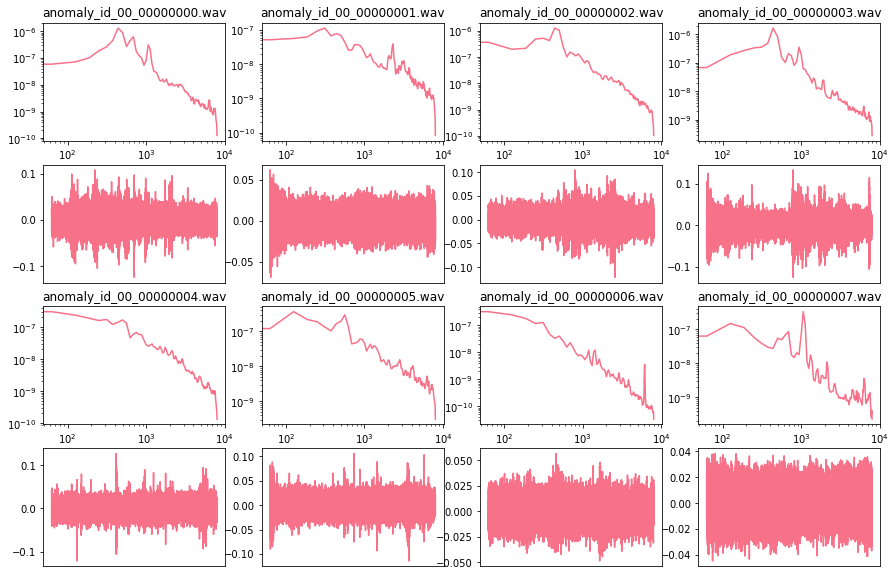
※ githubのノートブックでは全種類の音を表示しています。そちらもチェックしてみてください。
周波数領域の移り変わり(スペクトログラム)の形状
テストセットのデータには筋状の周波数成分が見えます。これが異常を表すのか、それとも環境ノイズに含まれるのか…
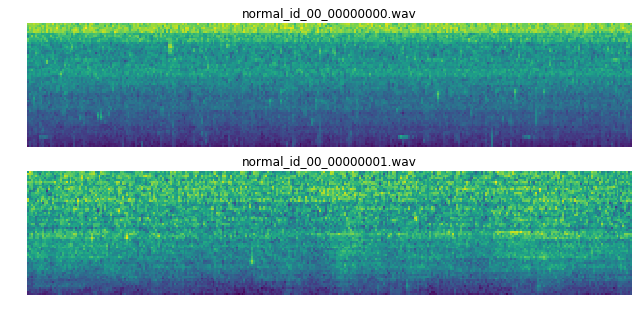
(pumpからのサンプル例 ↑学習セットの正常サンプル ↓テストセットの異常サンプル)
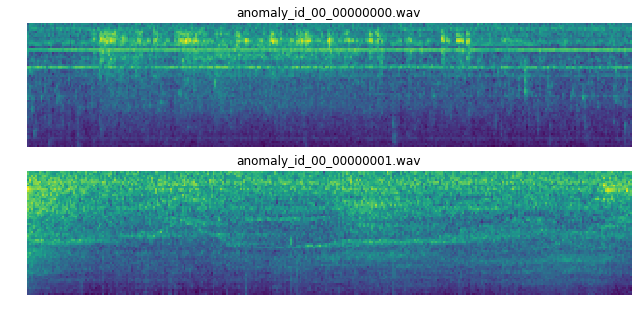
以上データについて見てきました。このデータセット、どのくらい解けるものなのでしょうか…
ベースラインをチェック
ベースラインの実装が公開されていて、元々Kerasで実装されていましたがPyTorch版も早速作られています。加えて私の方ではPyTorch Lightning版を作りました。
- y-kawagu/dcase2020_task2_baseline - オフィシャルなベースライン、Kerasで実装されたAutoencoderの実装。
- tam17aki/dcase2020_task2_baseline - PyTorch版にサクッと追加移植されたもの。
- daisukelab/dcase2020_task2_variants - PyTorch Lightning版で用意したり、VAEやConvolutional AEでの試みも用意。
性能指標には、異常検知で一般的なAUC(AUCのわかりやすい解説)に加えて、pAUC(pAUCのわかりやすい解説)が採用されています。
このpAUC、しきい値設定の難しい部分に着目できる指標になっています。しきい値を下げれば、簡単に検出率は上がります。しかし同時に誤検出率も上がってしまって、その検出器は「どんなものでも狼が来たと警告」して使い物にならなくなります。本当に異常なデータだけを知りたいので、偽陽性の上限を決めて、その範囲内だけのAUCを計算したものです。
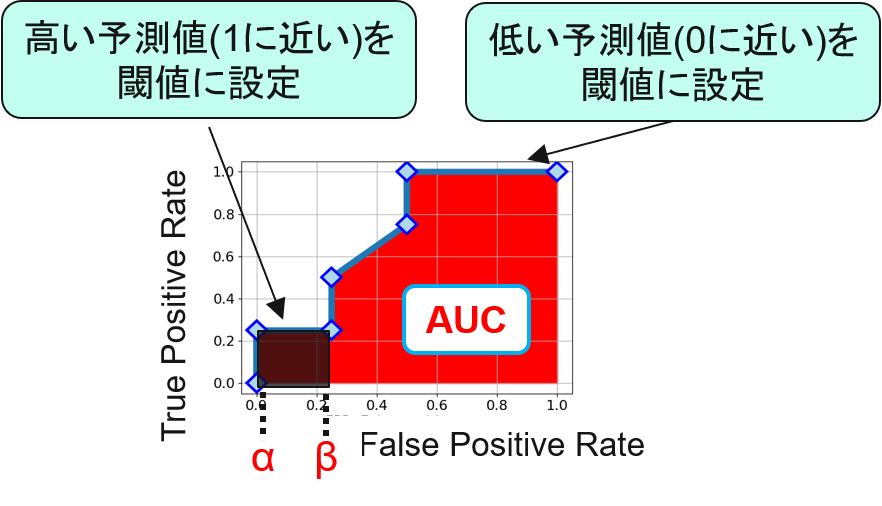 ([クロの制作日記 「二値分類における不均衡データへの対処方法~pAUC(partial AUC)最大化~」](https://www.kuroshum.com/entry/2019/11/13/%E4%BA%8C%E5%80%A4%E5%88%86%E9%A1%9E%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8B%E4%B8%8D%E5%9D%87%E8%A1%A1%E3%83%87%E3%83%BC%E3%82%BF%E3%81%B8%E3%81%AE%E5%AF%BE%E5%87%A6%E6%96%B9%E6%B3%95%EF%BD%9Epartia)より)
([クロの制作日記 「二値分類における不均衡データへの対処方法~pAUC(partial AUC)最大化~」](https://www.kuroshum.com/entry/2019/11/13/%E4%BA%8C%E5%80%A4%E5%88%86%E9%A1%9E%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8B%E4%B8%8D%E5%9D%87%E8%A1%A1%E3%83%87%E3%83%BC%E3%82%BF%E3%81%B8%E3%81%AE%E5%AF%BE%E5%87%A6%E6%96%B9%E6%B3%95%EF%BD%9Epartia)より)
元のベースライン(Autoencoder)の結果
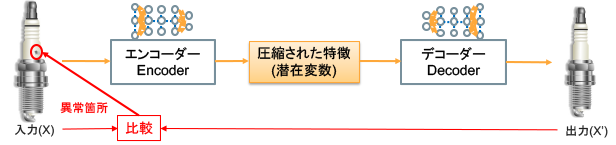 ([AISIA「オートエンコーダー_Auto Encoder (Vol.21)」の「図3:オートエンコーダーによる異常個所特定」](https://products.sint.co.jp/aisia/blog/vol1-21)より)
([AISIA「オートエンコーダー_Auto Encoder (Vol.21)」の「図3:オートエンコーダーによる異常個所特定」](https://products.sint.co.jp/aisia/blog/vol1-21)より)
Autoencoderの結果を見ていきましょう。まずToyCar、idによって随分差があるのに気づきます。
※ idは個体番号です。おもちゃの車を何台も用意されたようで、それぞれ正常なときと、ちょっと壊したときの異常な音が録音されたようです。
しかしこのAUC、やはり難しいことを表しているように思えます… (個人的には0.9くらいでもぎりぎり使い物にならないかも、という印象です)
ToyCar
id AUC pAUC
01 0.791331 0.665015
02 0.843655 0.766151
03 0.615191 0.540928
04 0.851536 0.700667
Average 0.775428 0.668190
次にスライダー、全然物によって結果が変わってきます。00は簡単みたいだけど、06は難しい様子。
ということは、汎化が難しいということでもあるのでしょう。
slider
id AUC pAUC
00 0.970337 0.859551
02 0.769438 0.624483
04 0.915955 0.672383
06 0.674157 0.486103
Average 0.832472 0.660630
バルブを見てみましょう。かなり厳しいです。
※ ランダムに判定したとしても、AUCは0.5に達するんです…
valve
id AUC pAUC
00 0.588571 0.509067
02 0.617083 0.518421
04 0.691250 0.513158
06 0.530583 0.482456
Average 0.606872 0.505775
Autoencoderの出力
AUCが厳しい結果になっていますが、そのときAutoencoderはどのくらい入力の形状を再現できているのでしょうか。
1pytorch/02-visualize-predictions.ipynbに可視化したサンプルを用意してあるので、そちらを見てみましょう。
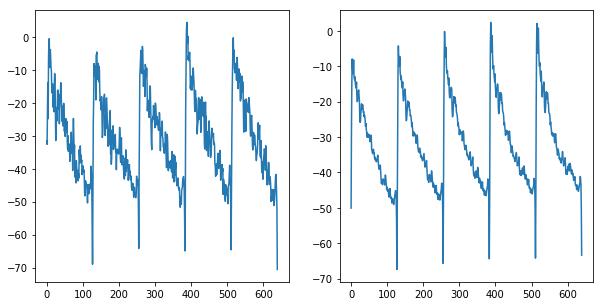
(Autoencoderの入力(左)に対する再構成出力(右)の例 ToyCarの検証セット)
- 細かい形状が似ていない。
- 山の高さもあっていない。
- 個別の波形それぞれでは再現できおらず、5つ全て同じような形になっている。
なるほど…改善の余地はたくさんありますね。
Variational Autoencoder (VAE)を試してみる
VAEならば、なんとかなるのではないのか → なりませんでした。orz
なんと平均顔ならぬ平均信号だけを出力し続けるモデルになってしまいました。
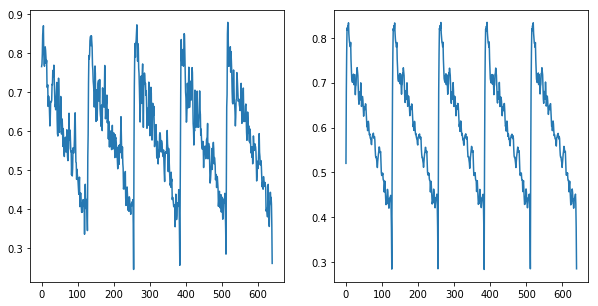
(ナイーブに学習させたVAEの例 入力(左)に対する再構成出力(右))
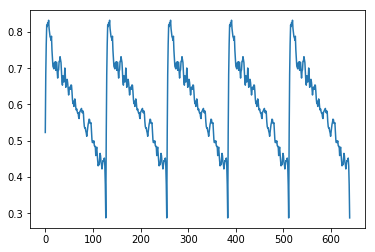
(学習サンプルの平均をとった信号…VAEが出力している信号そっくりです)
性能も悪化しました。だいたいランダムに決めているのと同じ0.5となりました。
ToyConveyor
id AUC pAUC
01 0.507269 0.488997
02 0.538644 0.507468
03 0.541677 0.507116
Average 0.529197 0.501194
VAEのロス関数
まずロス関数を見て見たいのですが、素晴らしい解説記事「Variational Autoencoder徹底解説」から、ロス関数は**変分下限 $L(X,z)$**の逆数($ロス関数=-L(X, z)$)で、その$L(X,z)$は2つの成分で構成されていることがわかります。

(「Variational Autoencoder徹底解説」より)
- KLD項 - 1つ目は信号を中間表現zにencodeして変換する分布と、zからdecodeして再構成するときの分布の差をできるだけ小さくしたい。
- 再構成項 - 式そのものは正解への近さを表すように見えますが、再構成された信号がどれだけ入力に似た形状にうまく復元できているかを表していて、うまく復元して大きくしたい。
そこで、ロスを構成するこの2つの要素がどのくらい影響するのかを実験してみることにしました。
実験: ロスの構成要素の寄与度を変化させたとき
再構成項:KLD項の比率を変えられるよう、ロス関数に手を加えて実験してみます。
return RECONST*a_RECONST + KLD*a_KLD # a_XXが係数
再構成項:KLD項 = 100:1
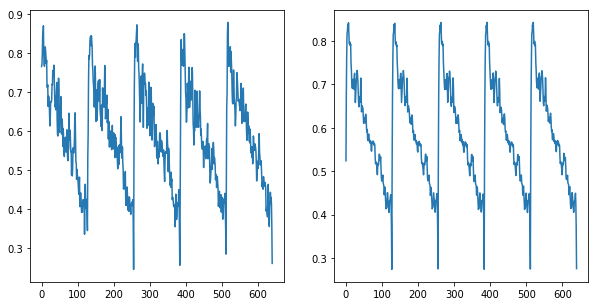
形はだいぶ良くなりましたし、性能も少しだけ良くなりました。
ToyConveyor
id AUC pAUC
01 0.560731 0.511102
02 0.588000 0.499833
03 0.555522 0.511283
Average 0.568084 0.507406
再構成項:KLD項 = 1:0 ∴再構成項だけ = Autoencoderと同じ
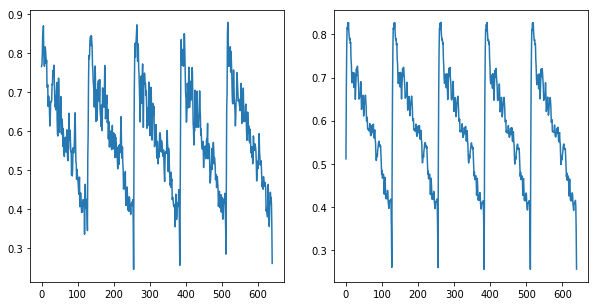
出力も性能もAutoencoder同等になりました。
ToyConveyor
id AUC pAUC
01 0.707922 0.565033
02 0.597817 0.520589
03 0.648035 0.522578
Average 0.651258 0.536067
再構成項:KLD項 = 0:1 ∴KLD項だけ、って??
これはお遊びの類ですが…
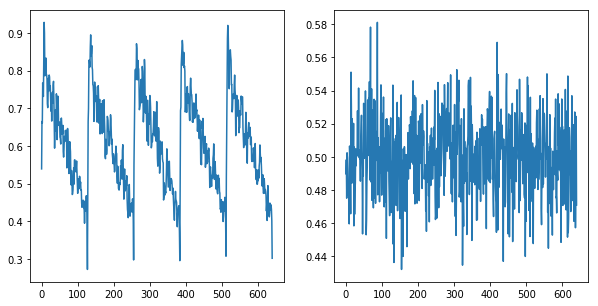
信号が再構成されることをlossに含めないと、やっぱり学習が正しく進むことはありませんでした。さてその時の性能は? 約0.5なので想定どおりです。
ToyConveyor
id AUC pAUC
01 0.563631 0.502253
02 0.497792 0.492976
03 0.490039 0.493231
Average 0.517154 0.496153
VAEがうまく行かない考察
VAEでも学習を進められると思うんですが、今回そのパラメーターを見つけられず諦めることにしました。
今回のデータは、そもそもVAEに適さないのでは、と思いました。
- 画像のデータセットでいろいろな方が試されているが、MNISTクラスではうまくいくものの、複雑なデータになっていくとうまく行かなくなっている。
- KLD項の期待することは、同じクラスの潜在表現zがある分布を形成して、それがエンコーダー・デコーダーで近くなること。だとすると今回のデータは1クラスなのでそもそも…
- とはいえ、個体id毎にデータの差は割とあるようです。この差を学習してほしかった…。でも聴いてわからないくらいなので、その割に環境ノイズの割合が大きすぎてそもそも分散が大きいのでは…。
Convolutional Autoencoderを試してみる
VAEで失敗した失意の中、これまでのコンペでうまく行っていたCNNを使ったAutoencoderのアプローチを最後に試そうと思いました。
結果としてあまり調整していない現状だと、ベースラインのAutoencoder(非CNN)より少し悪い結果で幕を引きました。
再構成の様子を見ると、割といいかも知れない…と期待します。
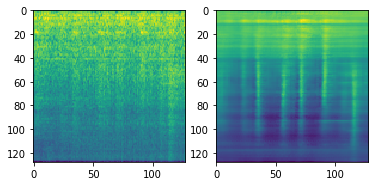
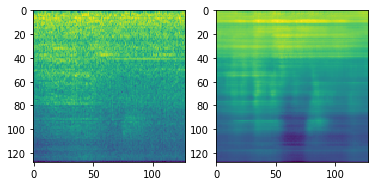
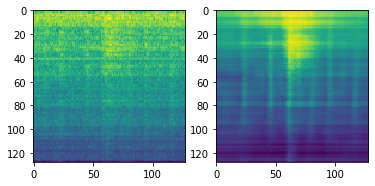
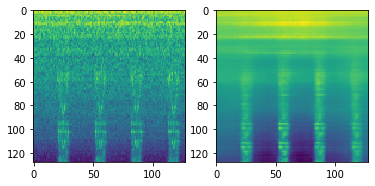
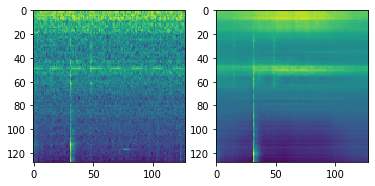
(Convolutional Autoencoderの出力例 入力(左)に対する再構成出力(右))
しかし結果は、元のAutoencoderより悪くなってしまいました。
ToyCar
id AUC pAUC
01 0.609383 0.549612
02 0.722371 0.654759
03 0.712560 0.611405
04 0.801013 0.688579
Average 0.711332 0.626089
(元のAutoencoderの結果は、
Average 0.775428 0.668190)
クイックスタート
ベースライン(y-kawagu/dcase2020_task2_baseline)でトライするときのクイックスタートを残したいと思います。
私の方で拡張したリポジトリも同様です。※ インストールされる内容は拡張されています。
Anacondaで環境を分けるとき
conda create -n task2 python==3.7
conda activate task2
pip install -r requirements.txt
環境を削除したいときはこうなります。
conda remove -n task2 --all
JupyterにAnacondaの環境を追加するとき
新しい環境を作っても、ノートブックで使えなければなりませんね。
こちらを参考に、このようにするとJupyter上でも選べるようになります。
ipython kernel install --user --name=task2 --display-name=task2
データの素早い展開
コピペしてしばらく待てば、データがすぐ使える状態になりますよ。
wget -O dev_data_fan.zip https://zenodo.org/record/3678171/files/dev_data_fan.zip?download=1
wget -O dev_data_pump.zip https://zenodo.org/record/3678171/files/dev_data_pump.zip?download=1
wget -O dev_data_slider.zip https://zenodo.org/record/3678171/files/dev_data_slider.zip?download=1
wget -O dev_data_ToyCar.zip https://zenodo.org/record/3678171/files/dev_data_ToyCar.zip?download=1
wget -O dev_data_ToyConveyor.zip https://zenodo.org/record/3678171/files/dev_data_ToyConveyor.zip?download=1
wget -O dev_data_valve.zip https://zenodo.org/record/3678171/files/dev_data_valve.zip?download=1
mkdir dev_data
cd dev_data
for f in ../dev_*.zip; do unzip $f; done
追加データセット
wget https://zenodo.org/record/3727685/files/eval_data_train_fan.zip?download=1 -O eval_data_train_fan.zip
wget https://zenodo.org/record/3727685/files/eval_data_train_pump.zip?download=1 -O eval_data_train_pump.zip
wget https://zenodo.org/record/3727685/files/eval_data_train_slider.zip?download=1 -O eval_data_train_slider.zip
wget https://zenodo.org/record/3727685/files/eval_data_train_ToyCar.zip?download=1 -O eval_data_train_ToyCar.zip
wget https://zenodo.org/record/3727685/files/eval_data_train_ToyConveyor.zip?download=1 -O eval_data_train_ToyConveyor.zip
wget https://zenodo.org/record/3727685/files/eval_data_train_valve.zip?download=1 -O eval_data_train_valve.zip
mkdir add_dev_data
cd add_dev_data
for f in ../eval_data_train_*.zip; do unzip $f; done
テストデータセット (6/3更新!)
wget https://zenodo.org/record/3841772/files/eval_data_test_fan.zip
wget https://zenodo.org/record/3841772/files/eval_data_test_pump.zip
wget https://zenodo.org/record/3841772/files/eval_data_test_slider.zip
wget https://zenodo.org/record/3841772/files/eval_data_test_ToyCar.zip
wget https://zenodo.org/record/3841772/files/eval_data_test_ToyConveyor.zip
wget https://zenodo.org/record/3841772/files/eval_data_test_valve.zip
mkdir eval_test
cd eval_test
for f in ../eval_data_test_*.zip; do unzip $f; done
Kaggleで取り組む
データセットをKaggleにアップロードしましたので、これを使うことでKaggleの計算リソースで取り組むことができます。
それぞれにスターター/EDAノートブックを用意しました。どうぞご活用ください!
トラブルシューティング
librosaは0.6.0
File "/home/xxx/anaconda3/lib/python3.6/site-packages/librosa/filters.py", line 247, in mel
lower = -ramps[i] / fdiff[i]
ValueError: operands could not be broadcast together with shapes (1,513) (0,)
となる難しいエラーが起こったら、まずは上に書いたようにAnacondaの環境を整えることをお勧めします。
もしくは、librosaのバージョンを下記のようにすると解決するでしょう。残念ながら新しいlibrosaだとエラーになります。
pip install librosa==0.6.0
おわりに〜コンペはこれからです!
ここまでデータセットを見て、ベースラインも見て、色々と試してみた結果を見てみました。
正直そこまで試したわけではありませんし、性能を上げるより基本的なアプローチの例示を目的としていましたので、この結果は全く伸びしろを残したものです。
GANはどうでしょう? 信号の再構成をしないアプローチは? どんなアイデアがこのタスクで試されるのか、とても楽しみです!
みなさんも、ぜひ!!
P.S.
VAEやConvolutional Encoderの試みに間違いなどあると思います。お気づきの方は是非コメントいただけると幸いです(__)