本記事はBrainPad Advent Calendar 2019 https://qiita.com/advent-calendar/2019/brainpad の8日目の記事です。
音声認識でのデータ拡張方法として今年話題となったSpecAugment https://arxiv.org/abs/1904.08779 [1]を紹介します。
1.音声認識って何?
皆さん、音声認識は好きですか?
音声認識とは「音声に含まれる意味内容に関する情報(言語情報)を、コンピュータによって抽出し、判定すること」[2]で、最近は様々な用途で使われるようになりました。Siri以前は音声認識を紹介しても「温泉?」と聞き返されるくらいに聞き馴染みの無い言葉でしたが、最近では「音声認識搭載〇〇」という製品キャッチコピーを見るくらいになってきましたね。
音声認識は人間で例えると耳から脳で行う処理に相当します。具体的には、空気中の圧力変化である音を入力して、日本語や英語などの自然言語情報+感情表現情報を認識します。ちなみに、声を発声する時には頭の中で自然言語を考えて、肺や声帯などの調音機構を絶妙な調整を行って音として出力します。ですので、発声と音声認識は逆問題の関係であるとも言えます。Speech chainの様子を下図に示します。[6]
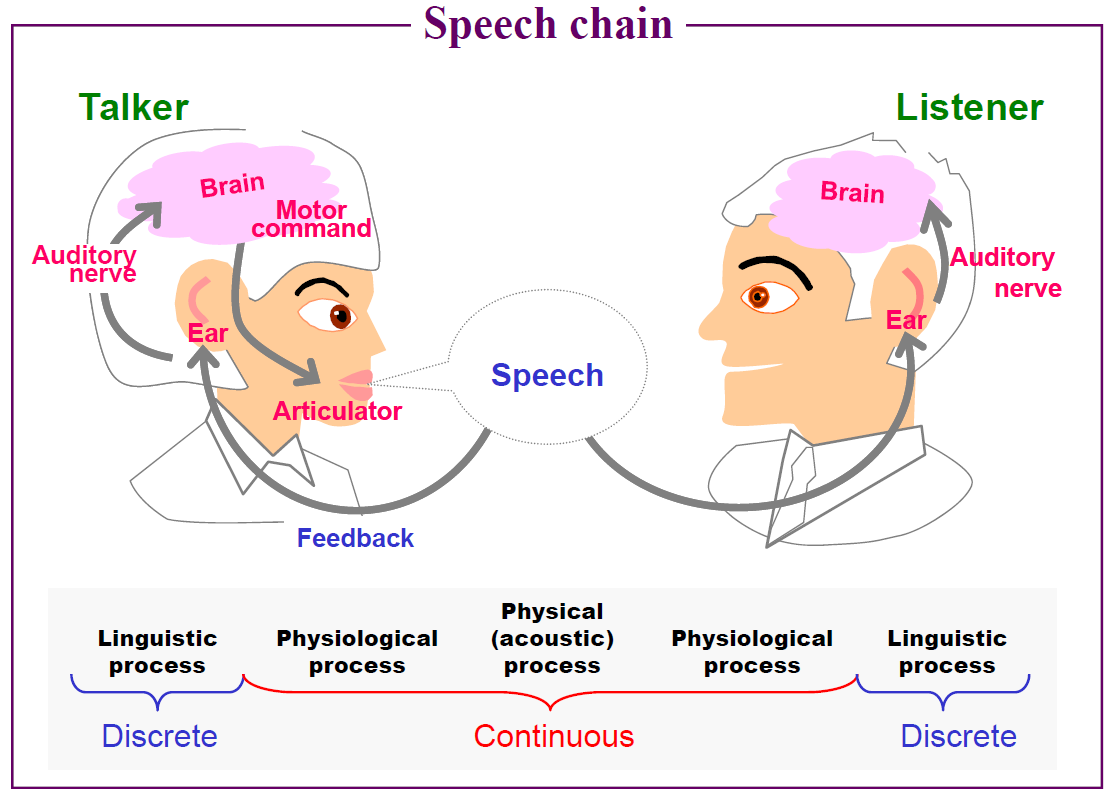
音声認識は音声波形から発声内容のテキストを推測する問題ですので、典型的な逆問題です。テキストを情報源として音声波形に変換されたものが入力となり、音声波形に埋め込まれているテキストを逆問題として推測します。音声波形から音素シンボル(発音記号のようなもの)を推定し、音素シンボル列から自然言語のテキスト列を推定する2段階構造が多いです。前者の音声波形Xから音素シンボルを推定するモデルを音響モデル、後者の自然言語テキストWを推定するモデルを言語モデルと呼びます。この流れを下図に示します。[6] 基本的にはP(W|X)が最大となるWを探す探索問題として定式化され、モデルの学習を行います。最近はモデルを2つに分けずに1つのモデルで音声波形Xから単語列Wを推定するend-to-endモデルも増えてきましたが、さらに大量の学習データが必要となります。
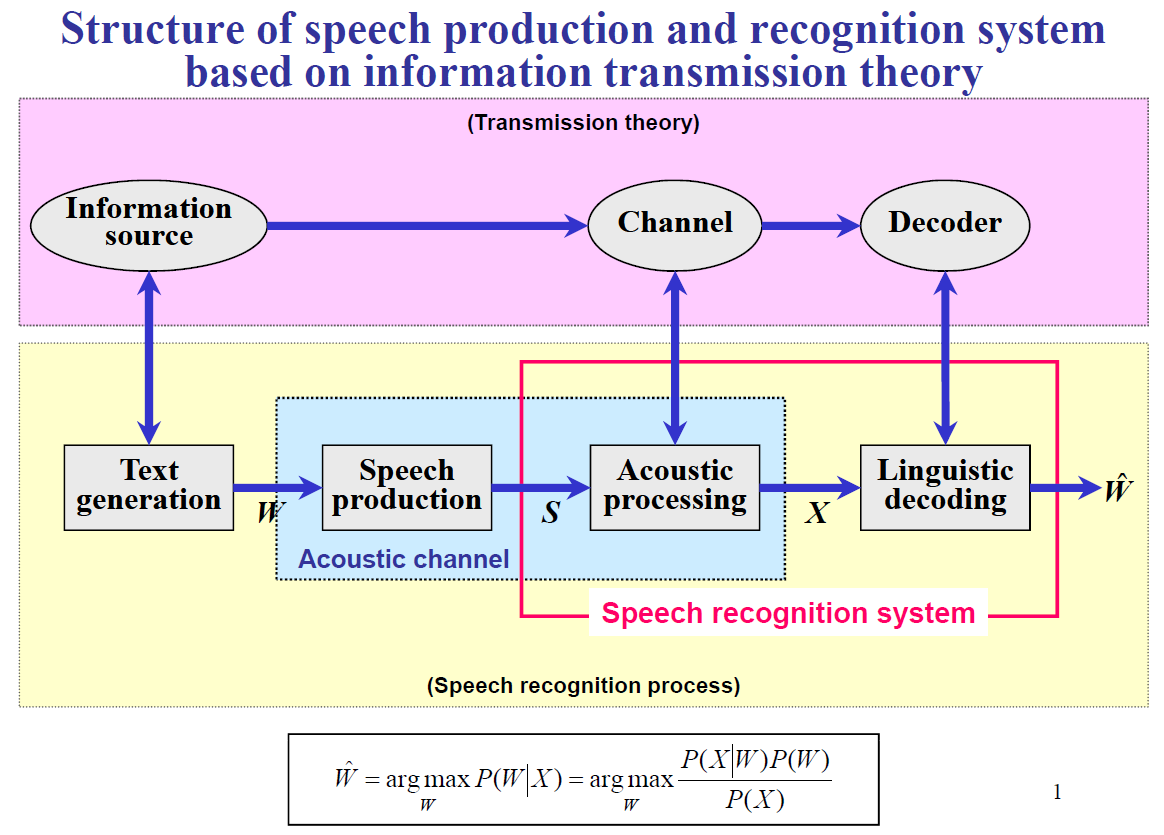
(上2つの図の日本語訳したものを作ろうとしたけど時間切れ)
2.音声認識でのデータ拡張
音声認識タスクで用いられている学習モデルとしてHMMやDNN、n-gramなどが挙げられますが、いずれも大量のデータが必要であるためデータ拡張は以前から行われています。音声認識でのデータ拡張としては以下の方法があります。
- 雑音重畳(雑音を追加する)
- VLTN:Vocal Tract Length Normalization (声道長正規化)
- 音響シミュレーションを用いたもの
これらは基本的に音声波形に対して加工をおこなっています。雑音重畳や音響シミュレーションでは、発声者の声帯から耳に入るまでに加わる音響的変化や外部からの雑音を人工的に再現することで、学習用音声データの増加を狙ったものです。VLTNは周波数ワーピングを行い話者による音響特徴の違いを正規化することで、話者の違いによる認識性能の劣化を防ごうとするものです。(なので、個人的には話者頑健性のイメージがVTLNには強いです)
計算量もそれなりにかかりますが、音声認識性能の向上にも改善の余地が残されていました。
3.SpecAugment
SpecAugmentの大きな特徴はデータ加工をスペクトログラム上で行っていることです。
音声認識にCNNを用いることは2015年あたりから行われていますが、これは入力層にCNNを用いることでスペクトル信号から特徴抽出を行うことが目的です。いわば、スペクトログラムを画像に見立てていると言えます。では、画像認識で用いられているデータ拡張方法は音声スペクトログラムでも使えるのではないか、というのが今回紹介する論文の大きなモチベーションです。下の図は音声波形信号をメル周波数スペクトログラムルに変換したものです。[3] (メル周波数スペクトルは人間の聴覚特性に合わせた尺度であるメル尺度に変換したスペクトログラムです)本記事では基本的に周波数領域は全てメル尺度で述べます。
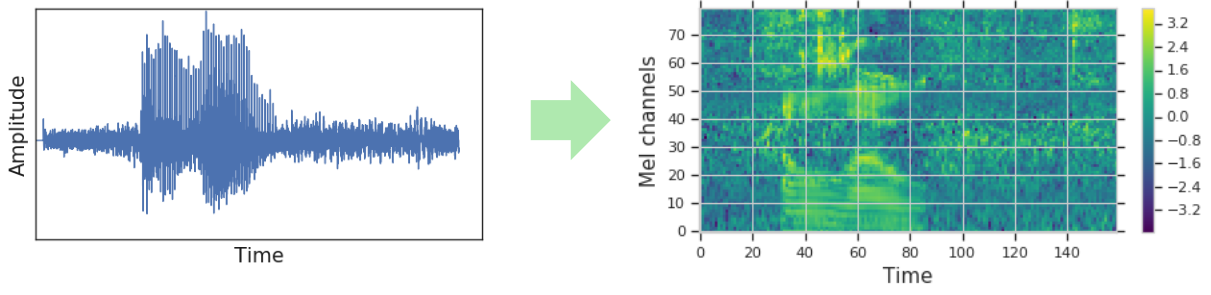
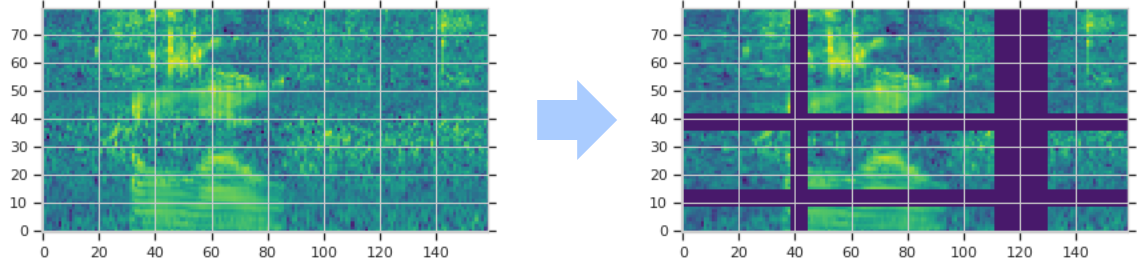
データ拡張は基本的に学習用データの特徴に一部変更を加えることによって、認識を行うときに必要となる情報源を増やすことが目的です。とはいえ、スペクトログラムは画像のように回転や反転をおこなうわけにはいきません。SpecAugmentでは時間方向での伸縮、周波数軸でのマスキング、時間軸でのマスキングの3種類が提案されました。周波数軸と時間軸でのマスキング例を下の図に示します。[3]
行っていることはシンプルで計算量も少ないのですが、認識性能の向上に大きく寄与しました。
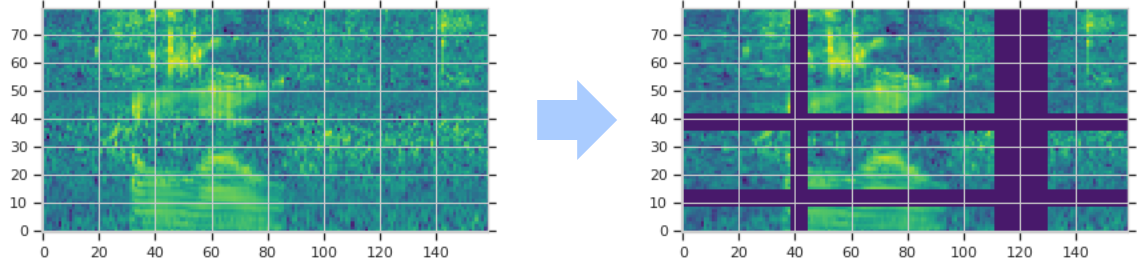
1)時間伸縮
1つ目の拡張方法は時間軸方向での伸縮です。スペクトログラムの時間軸上で1点を制御点として無作為に選択します。最初と最後の幾つかのフレームは使いません。この冒頭と終盤のカット幅Wはパラメータとなり、この論文ではW=80や40が採用されていました。無作為に選んだ制御点が時間軸上で距離wだけ動くように全体を伸縮させれば時間伸縮によるデータ拡張の完成です。距離wは[-W,W]の中から無作為に選びます。
2)周波数マスキング
周波数軸上でのマスキングを行うことによって、一部周波数の音が聞こえない状況を再現しデータ拡張を試みています。具体的には [f0,f0+f) のChannelをマスキングします。fは[0,F]から無作為に選択し、Fはパラメータ(この論文では27や15を選択)です。f0は[0,ν-f)から無作為に選びます。νはメル周波数Channel数(この論文では80)です。
3)時間マスキング
時間軸上でマスキングを行い、一部分の音が聞こえなかった状況を再現することでデータ拡張を行います。具体的には時間フレームの[t0,t0+t)をマスキングします。tは[0,T]から無作為に選択しTはパラメータ(論文では100や70)です。t0は[0,τ-t)から無作為に選びます(τは入力音声のフレーム数)。
4)3種類の加工を組み合わせる
ここまで紹介した3種類の加工方法(時間伸縮、周波数マスキング、時間マスキング)を組み合わせた加工も行います。さらに、周波数マスキングや時間マスキングは複数個所に適用することも可能です。論文では周波数マスクが1~2個、時間マスクが1~2個での評価も行っています。下図は周波数マスキングを2か所、時間マスキングを2か所行った場合のものです。[3]
5)評価実験
評価実験にはLibriSpeech(960時間)とSwitchboard(300時間)を使用し、単語誤り率(WER:Word Error Rate)で評価を行っています。音声認識モデルにはLASモデル(Listen, Attend and Spell)[4] という代表的なend-to-endモデルを使用し、入力層の2層はCNNにしています。実験結果を下図に示します。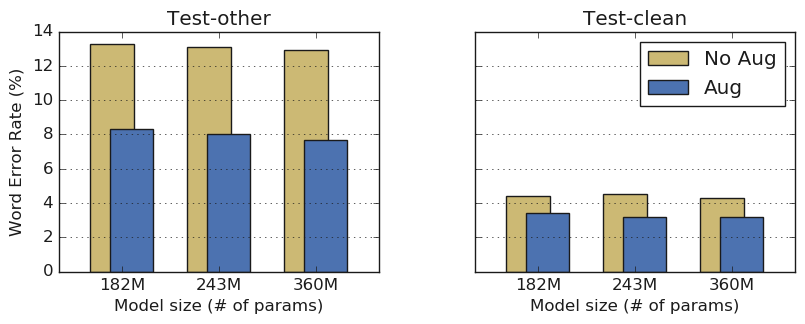
高い認識率が出やすいTest-cleanでもしっかりWERが下がってますし、WERが高くなりやすいTest-otherはWERの改善率が大きいです。このWERがどのくらい凄いのか他の手法と比較してみると、以下のようにLibriSpeechとSwitchboardの両方でSOTAを実現していました。(縦軸がlogスケールのWERであることに注意)
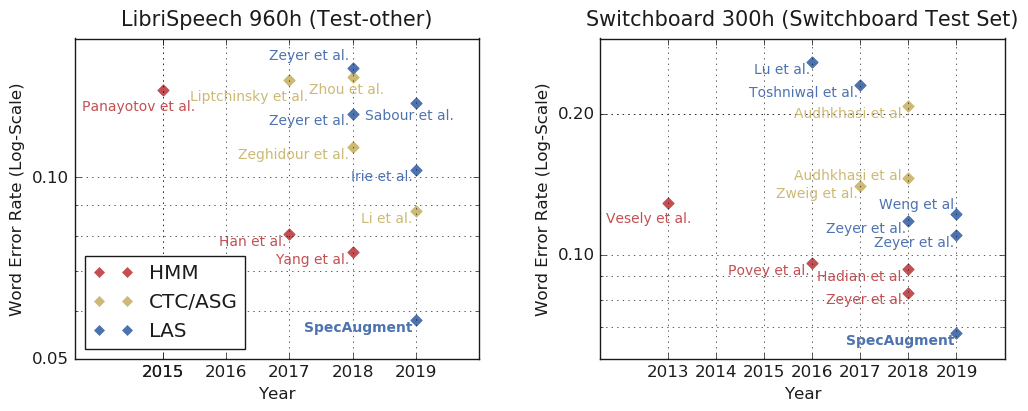
このデータ拡張の効果は言語モデルありなしで影響があるのかも追加で調べられており、以下の結果となったようです。[3]
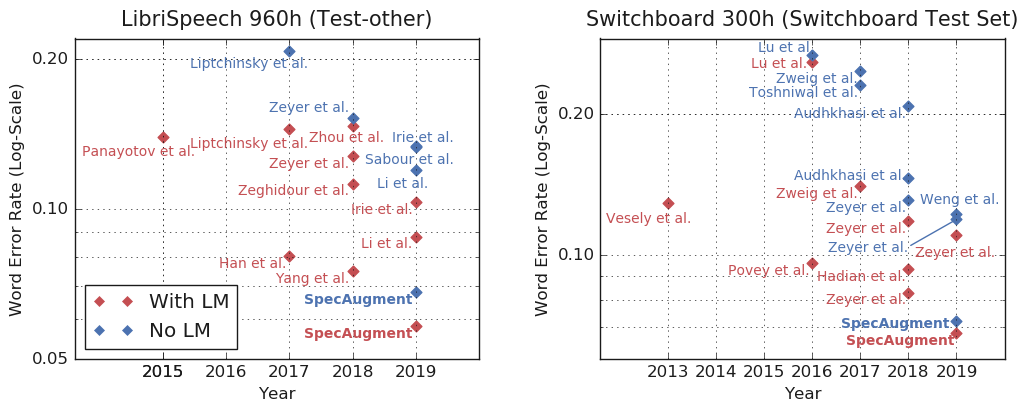
言語モデルなし+データ拡張で言語モデル付きに勝っているのは凄いですね。しかも、データ拡張に言語モデルを加えることでさらに性能も上がっているので、言語モデルありなしに関わらずデータ拡張が有効になっています。このデータ拡張はこれからの音声認識モデル作成のデファクトになっていくのでしょうか。
6)考察
この論文では3種類のデータ拡張法を提案していますが、どの拡張方法が効いているのでしょうか。以下の表は一番上が3種類全て行ったもので、下の3つは上が時間伸縮なし、真ん中は周波数マスキングなし、下が時間マスキングなしとなっています。この数字はWERなので低いほど良い数字です。
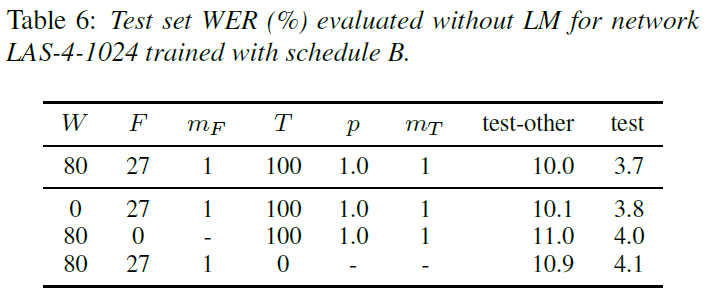
Test-otherの列を見ると、3種類全て行ったものがWER10.0なので一番良いのですが、時間伸縮だけ行っていないものが10.1とほとんど変わっていません。また、周波数マスキングや時間マスキングを行わなかったものはWERが0.9から1.0悪くなっているので、マスキングは周波数も時間も欠かせないようです。このことから、時間伸縮は行わずに周波数マスキングと時間マスキングを行うだけでも良いのかもしれません。
次にモデルの学習曲線を下図に示します。[3]
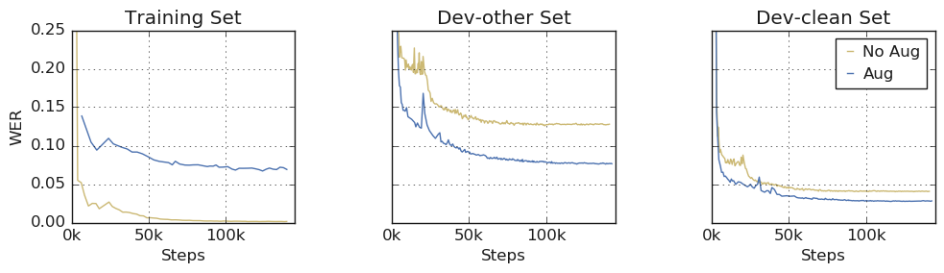
データ拡張なしとありの学習曲線を比べてみると、データ拡張なしではTraing SetのWERが早々に0に近づいているのに評価用のDev-otherでもDev-cleanでもWERがデータ拡張ありにまけています。さらに、データ拡張ありではTraing SetでWERが下げ止まっておらずunder-fitな状態になっています。これはもっと複雑なモデルを試したり、学習回数を増やすことに意味を見出せる状況になっており、さらなる性能向上が可能になりそうです。
4.まとめ
本記事では音声認識における有力なデータ拡張手法としてSpecAugmentを紹介しました。このデータ拡張手法はスペクトログラム上でマスキングを行うだけという少ない計算量で行う事ができますが、音声認識性能に強力な効果をもたらすだけでなく、さらに複雑なモデルを用いる際のデータ不足問題に対する解決策でもあります。今回紹介した論文が発表されたInterSpeech2019では、参加された方によると会場内で最も話題だった論文の1つだそうです[5]。この論文内では数百時間のデータセットを用いてend-to-endタイプのモデルだけで実験が行われていますが、もっと少ないデータセットでの学習での効果も気になるところです。データが少ない場合にはSpecAugmentでもend-to-endモデルどころかHMMDNNベースのモデルでもデータが足りない可能性もあるので、HMMDNNベースのモデルに対して少ないデータセット+SpecAugmentで性能向上が図れるのか気になります。HMMDNNでもデータ量が足らないケース(方言、少数話者言語、非母語話者など)は多いので、HMMDNNでも性能向上するかどうかは音声認識を世界中に広げるために重要な気がしています。
引用文献
[1]Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, Quoc V. Le,”SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition”,https://arxiv.org/abs/1904.08779 ,2019.
[2]古井貞煕,「音声情報処理」,森北出版,1998.
[3]Posted by Daniel S. Park, AI Resident and William Chan, Research Scientist,”SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition”,Google AI Blog,https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html .
[4]W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, Attend and Spell:A Neural Network for Large Vocabulary Conversational Speech Recognition”, (https://arxiv.org/pdf/1508.01211.pdf, in ICASSP, 2016.
[5]Yusuke Shinohar, "Interspeech2019 Yomikai:SpecAugment", https://speakerdeck.com/yusukeshinohara/interspeech2019-yomikai-specaugment, Interspeech2019&サテライト論文読み会 発表資料,2019.
[6]Sadaoki Furui, "Speech Information Processing", Tokyo Tech OCW, http://www.ocw.titech.ac.jp/index.php?module=Archive&action=KougiInfo&GakubuCD=226&GakkaCD=226716&KougiCD=76027&Nendo=2010&Gakki=2&lang=EN&vid=05&tab=7, 2010.