異常検知は、正常データだけで学習できる製造業で人気のある手法です。
そして、異常検知で異常を検出したとして、「異常原因を特定したい」という
要望もよく聞かれます。
そこで、本稿では、複数のセンサが付いた異常検知システムにおいて、
異常が発生した場合に、どのセンサが異常値を示しているのかを特定する
方法を検討します。
※コード全体はこちらに置きました。
※こちらはPythonデータ分析勉強会#17の発表資料です。
きっかけ
以前に、こんな内容をツイートしたところ、皆さん興味をお持ちのようでした。
昨日、JFEスチールの製造ラインで異常検知する話しを聞いた。
— shinmura0 @ 3/14参加者募集中 (@shinmura0) September 28, 2019
・数十個にわたるセンサで常時監視
・異常検知の制約は、異常のみならず異常原因も特定する
・センサは相関が強いものだけを取り出し、主成分分析だけで異常検知
・これによりコストと納期を大幅に削減
ー続くー
製造業では異常を検出するだけではなく、異常の原因を特定しないと異常が頻発する
恐れもありますし、重大欠陥を見逃すリスクもあります。
異常原因の特定は、かなり重要なタスクになることもあります。
結論から
- Permutation Importanceを使うことで、どのセンサが異常値を示しているのか特定できる
- さらに、有効なセンサを絞ることも可能になる
- ただし、センサ数が増えると異常原因を特定するのは難しいかもしれない
Permutation Importanceとは
ある一つの説明変数(特徴量)を混ぜて交換(シャッフル)することで、その説明変数の
影響度を調べる方法です。詳しくは以下の記事をご覧ください。
Permutation Importanceを使って検証データにおける特徴量の有用性を測る
Permutation Importanceの手順は以下のとおりです。
①学習用データを使って学習済モデルを作る
②検証用データで①のモデルのスコアを計測する
③検証用データのある一つの説明変数をシャッフルする
④学習済モデルに③のデータを入れ、性能がどれだけ悪化するのか計測する
⑤全ての説明変数について、③~④を繰り返す。
⑥悪化が大きい説明変数ほど、重要度が高いといえる
この手法は通常、教師あり学習で用いられます。
異常検知への応用
Permutation Importanceを異常検知に適用する場合を考えます。
異常原因を特定する
ここが本稿の主題です。センサで監視中に異常が起きたとして、どのセンサが異常値を
示しているのか、極端に言うと、異常原因は何なのか特定することができます。
教師あり学習の場合、検証用のデータで、ある一つの説明変数をシャッフルすることで
説明変数の影響度を調べることができました。これは、検証用データが複数あるために
シャッフルできる仕組みです。
ところが、監視中に異常を検出した場合、その異常データは一つしかありません。
従って、シャッフルしたくてもシャッフルする相手がいないので、何か別のデータを
用意しなければいけません。
本稿では、学習用データの説明変数を異常データとシャッフルさせ、影響度を調べます。
これは、結果的に「異常データの説明変数に正常データが代入される」ことになり、異常を示す
説明変数と入れ替わった場合、異常スコアが劇的に下がることが期待されます。これにより、
異常値を示しているセンサを特定します。
この手法は、いわゆるテーブルデータであれば、一般的な異常検知手法に適用することは
可能だと思われます。画像や音でもやろうと思えばできますが、CNNを使っていることが
多いと思うので、計算時間が膨大になります。そのため、他の手法(Grad-CAMやAno-GAN)
を活用した方が良いと思われます。
センサ削減
本稿の主題から逸れますが、Permutation Importanceを使うことで**必要なセンサを
絞ることも可能になります。**これはAUCなどを指標にし、AUCが悪化する説明変数が
有効センサであると解釈することで、不要なセンサを削除することも可能です。
必要なセンサを絞ることにより、以下のメリットがあります。
- 前回検討した次元の呪いの影響を緩和でき、より精度よく異常を検出することが可能
- コストダウンにつながる点も大きい
ただし、異常データがあって初めて成立する話しです。異常データがない場合、
あらかじめ必要なセンサを絞ることは難しいです。(当たり前の話しといえば、
当たり前ですが)
ただ、わざわざPermutation Importanceを使わなくても、手持ちの異常データを使って
センサ情報を一つずつ落としていき、AUCを計測することで重要度が分かる気もします。
これは非常に単純な方法です。どちらの手法を使うにしても、異常データが十分ないと
「異常データに過学習」してしまう危険性があるので注意が必要です。
実験
コードは、こちらの記事を参考に実装しました。教師あり学習の場合は、scikit-learnが
使えるので、そちらを使った方が計算時間が早いと思います。
※コード全体はこちらに置きました。
実験条件
前回と同様に以下の条件で実験を行います。
- 異常検知手法はIsolation Forestを使用する
- 異常値を示しているセンサは2つだけ
- 異常値を示していない(関係のない)センサはX個付いている
- このとき、異常値を出しているセンサが特定できるのか?
結果
関係のないセンサが2つの場合
まずは、異常値を出しているセンサ($x_1,x_2$)を乱数を使って生成します。
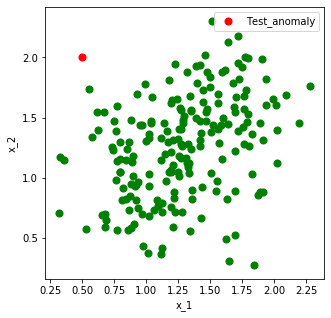
上の図より、$x_1,x_2$に相関があることが分かります。
緑の点が学習データ、赤の点が異常データです。
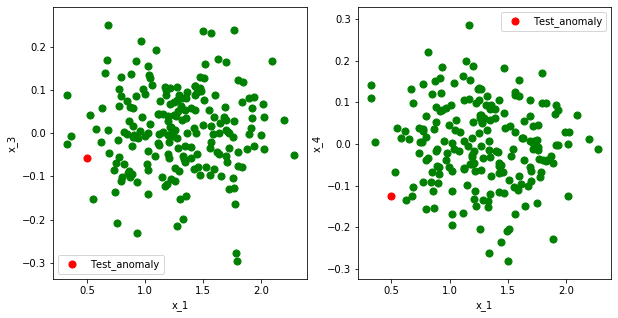
関係のないセンサ($x_3,x_4$)は上の図のように$x_1(,x_2)$と相関がなく、特に、意味のある
値を出していません。ここでは、正規分布を使って適当な値を入れています。
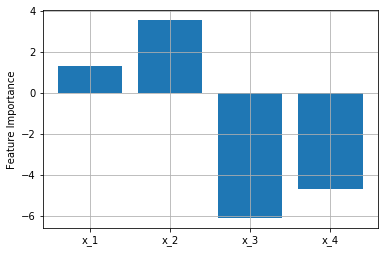
早速、Permutation Importanceを使って説明変数の影響度(Feature Importance)を算出
します。
縦軸の値が大きいほど重要度が高い、つまり異常原因の可能性が高いことを示唆しています。
狙い通り、$x_1,x_2$の値が大きくなりました。成功です。
関係のないセンサが8つの場合
次に関係のないセンサを8つにします。
先ほどの実験の$x_3$を8つに増やしたとお考えください。
うまくいくと、以下のように。
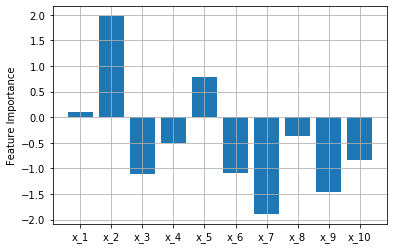
狙い通り、$x_1,x_2$の値が大きくなりました。
うまくいかないと、以下のような結果になります。
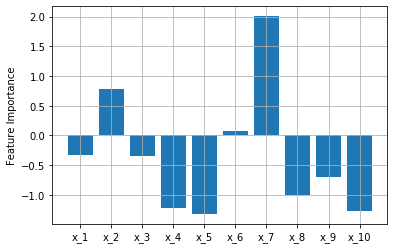
乱数を使っているため、結果が変わります。
$x_1,x_2$の値は比較的大きいですが、一番大きいのは$x_7$となってしまいました。
センサ数が多いと異常原因の特定は難しいかもしれません。
結局、どうすれば良いのか?
異常原因を特定する方法をまとめます。
- Permutation Importanceを使うと、どんな異常検知手法でも異常原因を特定することができるが、センサ数が増えると異常原因を特定するのは難しいかもしれない
- MT法は直交表を使うことで貢献度(異常原因)を調べることができる(こちらの資料のP43参照)
が、データが正規分布になっていないと異常の検出は難しく、精度低下の恐れがある - 冒頭に紹介した主成分分析による異常検知も、正規分布を主体としているため、MT法と同じような分析結果になると思われる
この他にも手法はあるかと思いますが、どの手法も一長一短だと思います。
ただ、個人的に異常原因の特定は、精度100%を求められる状況が少ないと思います。
第一候補から順に異常を検査する形をとれば、精度100%でなくても現場で十分
使えるレベルのところもあります。最後の実験でも、第5候補まで調べれば異常原因を
特定できる結果になっていました。
よって、異常を検出しながら、異常原因を特定したい場合、どの手法を使うかは「異常
検知性能がどれくらい求められているのか?」と「異常原因の特定精度はどれくらい
犠牲にしても大丈夫なのか?」を検討しながら、バランスよく決める必要があると思います。
まとめ
- Permutation Importanceを使うことで、どのセンサが異常値を示しているのか特定できるが、センサ数が多いと難しいかもしれない
- 本稿の主題から逸れるが、有効なセンサを絞ることも可能になる
- 他の手法でも異常原因の特定ができるが、どの手法を使うかは異常検知性能と原因特定精度のバランスを見ながら決める必要がある