前回はLSTMを使って、7月の気温を分析しました。
今回はCNNを使って分析したいと思います。
問題設定など
データの可視化や問題設定、データの整列などは前回の記事を参考にして下さい。
RNN vs CNN
ディープラーニングで時系列データといえば、RNN(LSTM)が有名ですが、
CNNの方がうまくいくという噂もあります。
以下の記事では、RNN(LSTM)よりCNNの方がうまくいっているように見えます。
・【Python】QRNNでカオス時系列データ予測【Keras】
https://qiita.com/yukiB/items/681f68690ffabbf3e1e1#qrnnquasi-recurrent-neural-network%E3%81%A8%E3%81%AF
CNNを使った時系列データの異常検知事例も報告されています。
・異常検知ナイト(再生場所37:00くらい)
https://www.youtube.com/watch?v=mAvRNKi9UEE
以下のサイトでは、Time series dataこそCNNを使うべきと書いてあります。
・When to Use MLP, CNN, and RNN Neural Networks
https://machinelearningmastery.com/when-to-use-mlp-cnn-and-rnn-neural-networks/
CNNモデルの構築
CNNを使って、改善を図ってみます。
kerasを使ってCNNを構築します。
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, Flatten, Add, Input
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
lookback = 5
# データを4次元化
X_train = X_train.reshape((len(X_train),lookback,1,1))
X_val = X_val.reshape((len(X_val),lookback,1,1))
X_test = X_test.reshape((len(X_test),lookback,1,1))
# CNNの学習
input_ = Input(shape=(lookback, 1,1))#横の数、縦の数、RGB
c = Conv2D(8, (3, 1),padding='same',activation='relu')(input_)
c = Dropout(0.2)(c)
c = MaxPooling2D(pool_size=(2, 1))(c)
c = Flatten()(c)
c = Dense(30,activation='relu')(c)
c = Dropout(0.2)(c)
c = Dense(4, activation='softmax')(c)
model = Model(input_, c)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
hist = model.fit(X_train, Y_train, batch_size = 10, epochs=100, verbose=1, shuffle=True,
validation_data = (X_val,Y_val))
# 結果描画
plt.figure()
plt.plot(hist.history['val_loss'],label="val_loss")
plt.plot(hist.history['loss'],label="train_loss")
plt.legend()
plt.show()
plt.figure()
plt.plot(hist.history['val_acc'],label="val_acc")
plt.plot(hist.history['acc'],label="train_acc")
plt.legend(loc="lower right")
plt.show()
学習結果は以下のとおりです。
損失関数の推移↓
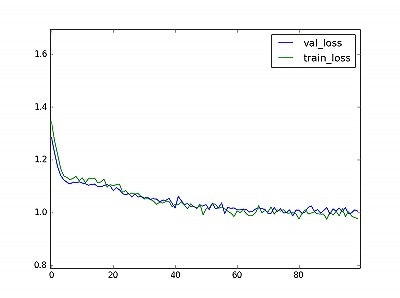
精度の推移↓
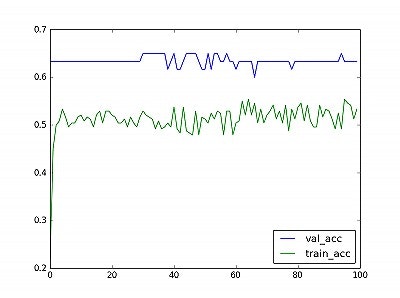
損失関数の推移は、前回のLSTMとほとんど変わっていません。
validationデータの精度は改善が見られますが、今回は確率が重要なので損失関数で
改善が見られなければあまり意味はありません。
※CNNで使ったtrainigデータとvalidationデータは、LSTMと組み合わせが異なります。
もう少しモデルを改善する必要があります。
モデルの改善
現状、私が知る限りの最強CNNモデルを構築してみます。
知識が乏しくていけませんが、以下の項目を取り入れます。
・ResNet(言わずと知れたCNN界の革命児)
・mixup(kaggleでも採用実績があります)
・LeaklyRelu(学習が早くなるらしいです)
・santa(Adamを大きく上回る最適化手法)
(kerasでは標準実装されていないため、諦めました。)
from mixup_generator import MixupGenerator
# mixup
generator1 = MixupGenerator(X_train, Y_train, batch_size=60)()
x, y = next(generator1)
X_train = np.vstack((X_train,x))
Y_train = np.vstack((Y_train,y))
# resnet
def resblock(x, filters, kernel_size):
x_ = Conv2D(filters, kernel_size, padding='same')(x)
x_ = BatchNormalization()(x_)
x_ = Activation(LeakyReLU())(x_)
x_ = Conv2D(filters, kernel_size, padding='same')(x_)
x = Add()([x_, x])
x = BatchNormalization()(x)
x = Activation(LeakyReLU())(x)
return x
# resnetの学習
input_ = Input(shape=(lookback, 1,1))#横の数、縦の数、RGB
c = Conv2D(8, (3, 1),padding='same')(input_)
c = Activation(LeakyReLU())(c)
c = Dropout(0.2)(c)
c = resblock(c,filters=8, kernel_size=(3, 1))
c = MaxPooling2D(pool_size=(2, 1))(c)
c = Flatten()(c)
c = Dense(30)(c)
c = Activation(LeakyReLU())(c)
c = Dropout(0.2)(c)
c = Dense(4, activation='softmax')(c)
model = Model(input_, c)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
hist = model.fit(X_train, Y_train, batch_size = 10, epochs=100, verbose=1, shuffle=True,
validation_data = (X_val,Y_val))
# 結果描画
plt.figure()
plt.plot(hist.history['val_loss'],label="val_loss")
plt.plot(hist.history['loss'],label="train_loss")
plt.legend()
plt.show()
plt.figure()
plt.plot(hist.history['val_acc'],label="val_acc")
plt.plot(hist.history['acc'],label="train_acc")
plt.legend(loc="lower right")
plt.show()
本当は、Dropoutの数字やAdamのパラメータをいじらないといけないのですが
時間の都合上デフォルト値でやっています。
学習結果は以下のとおりです。
損失関数の推移↓
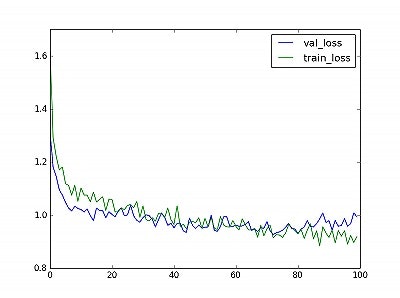
精度の推移↓
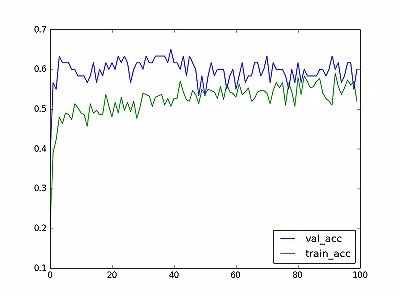
精度の推移はほぼ変わりませんが、validationデータの損失関数は少し改善しました!
LSTMの損失関数と比べても、こちらの方が優位です。
何が一番効いたのか検証していませんが、mixupが一番効いたと思われます。
評価
前回同様、テストデータで確率を出してみます。
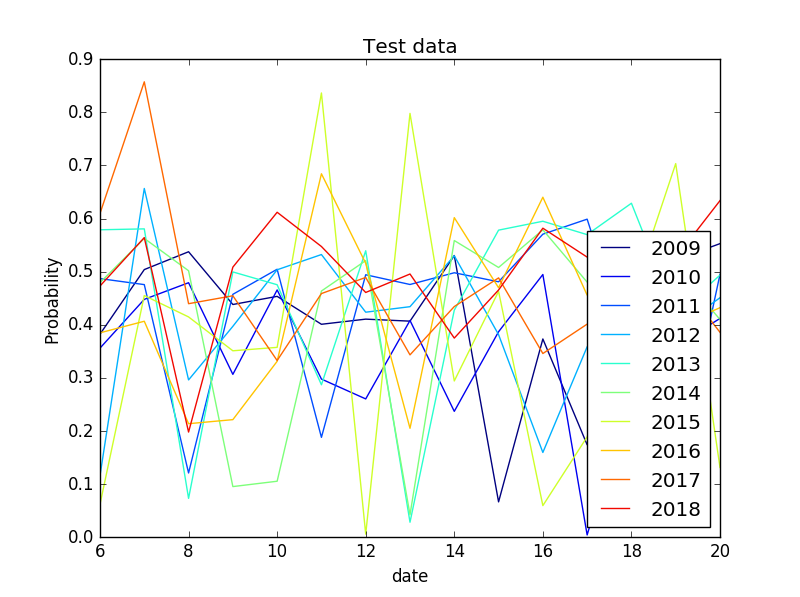
上のグラフは、その日の最高気温が確率的にどのくらいあり得るのかを示したものです。
次に気温データの推移と共に可視化します。
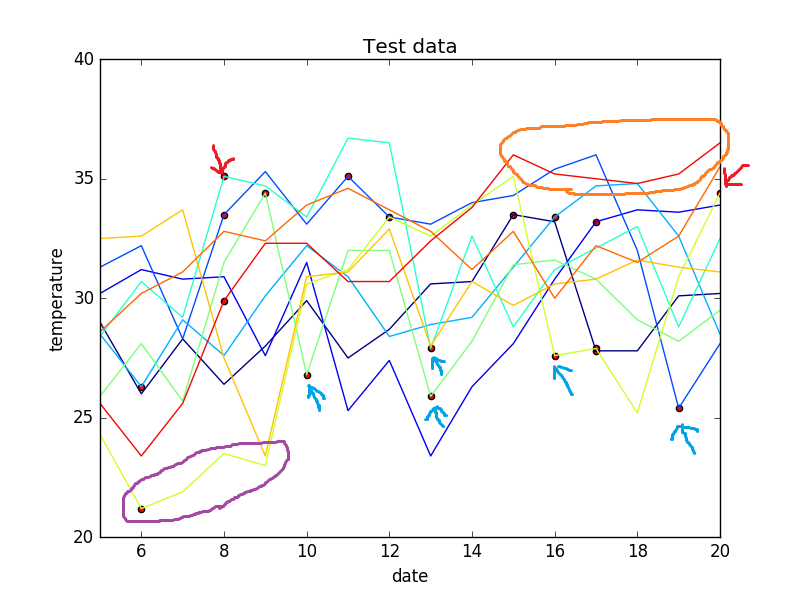
下のグラフの縦軸は気温(℃)、横軸は日付(左端は7/5、右端は7/20)です。
・赤い丸はCNNの確率が20%を下回るものをプロットしています。
つまり、異常と認識している点です。
以下、考察を示します。
(良かったところ)
・前回同様、最高気温の急上昇(赤い矢印)・急降下(青い矢印)は
確率が低く出ています。
・前回は、余分な赤いプロットが散見されました。今回は赤いプロットが少なく
なっています。損失関数も改善していることから、より異常認識の精度が
高くなったと見てよいでしょう。
(悪かったところ)
・低温が続く箇所は検知できませんでした。(紫の丸)
・2018年の高温も検出できませんでした。(オレンジの丸)
悪かったところは、温度クラスを見直したり(35℃以上のクラスを増やす等)、
学習データを増やしたりすれば改善するものと思われます。
次回はCNNを使って回帰をやりたいと思います。