前回の記事で関数を回帰させるとき、誤差について2乗の和にするか絶対値の和にするかで性能の差があることが分かりました。特に、絶対値の和とした時は外れ値に対して頑健であることを確認しました。
ここで、誤差の2乗和を取るとか、絶対値にするとかは数学的にどういうことかを確認してみます。
免責
現在確率モデルに関するいろいろなものを独学しておりまして、調べた内容をメモする目的もあります。
そこを踏まえた上でお付き合いいただけたらと思います。
状況設定
データ点の群 $X = \left\{ z_1, z_2, \cdots, z_N\right\}, z_i = (\vec{x}_i, y_i)$ (サンプルサイズ $N$ のサンプル)が与えられて、これにパラメータ群 $\theta$ を用いた関数でフィットすることを考えます。
y_i = f(\vec{x}_i; \theta)
与えられたデータ点群の上で適切な $\theta$ を求める方法を考えてみます。
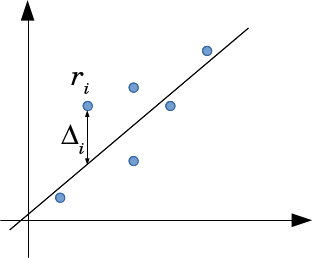
直線フィットの場合。
曲線フィットの場合。

どちらも差分はy軸方向で考えます。
これは与えられたデータ群に対して誤差
\Delta_i = y_i - f(\vec{x}_i; \theta)
をできるだけ小さくしたいというものですが、その実現方法がいくつか考えられます。
2乗和での確率モデル
モデル関数$f$から正規分布に基づいた誤差が乗って観測されるとします。つまり $\Delta_i$ は(1次元の)正規分布
\Delta_i \sim {\cal N}\left(0, \sigma\right)
に従うとします。このとき、$i$番目のサンプルが与えられた座標である確率は、
p_i = C\exp\left(-\frac{\Delta_i^2}{2\sigma^2}\right)= C\exp\left(-\frac{\left( y_i - f(\vec{x}_i; \theta)\right)^2}{2\sigma^2}\right)
となります。ここで $C=\frac{1}{\sqrt{2\pi\sigma^2}}$は正規化のための係数。
サンプル全体 $\left\{ z_1, z_2, \cdots, z_N\right\}$ を得る確率はこれらの同時確率なので、
P = \prod_i p_i
となります。
ここで、$P$ は関数のパラメータ$\theta$が与えられた時にサンプル$X$が得られる確率だと考えることができますので、改めて $P(X|\theta)$ と書きます。
さて、この $P$ が一番大きくなる状況を考えてみると一番有り得そうな感じです。ここまでで出てきた変数 $x, y, \theta, \sigma$ のうち動かせそうなのは $\theta$ だけですね。よって、 $\theta$ をいろいろ動かして $P(X|\theta)$ を最大化する問題だと考えましょう。
$P$ は $X = \left\{ z_1, z_2, \cdots, z_N\right\}$ の関数だと思うと確率ですが、$\theta$ の関数だと思うと 尤度 となります。$X$ を動かしているときは「確率を最小にするまだ見ぬデータ $x$ 」を探しているのに対し、$\theta$を動かしているときは「既に与えられているデータ $X$ に対して妥当な $\theta$ 」を探している感じでしょうか。
ということで$\theta$ を動かして尤度 $P$ を最大にする今回の問題は __最尤推定法__になります。
ここで、$P$ を最大にするということは、 $L(\theta) = -\log P(X|\theta)$ を最小にするということと同値です。なんで$\log$が出てきたかですが、計算が楽だからではないでしょうか。以降の計算を見ていると察することができるかと思います。
愚直に計算してみましょう。
\begin{array}{lll}
L(\theta) & = & -\log P = -\log\left(\prod_i p_i\right)\\
&=& - \sum_i \log p_i \\
&=& - \sum_i \log \left(C\exp\left(-\frac{\left( y_i - f(\vec{x}_i; \theta)\right)^2}{2\sigma^2}\right)\right) \\
&=& \left(- \sum_i \log C \right) - \sum_i \log \left(\exp\left(-\frac{\left( y_i - f(\vec{x}_i; \theta)\right)^2}{2\sigma^2}\right)\right)\\
&=& - N\log C + \sum_i\frac{\left( y_i - f(\vec{x}_i; \theta)\right)^2}{2\sigma^2}
\end{array}
まあ、指数関数の積の対数を取ったら、eの肩に乗っているものの和になりますね。
するとこれを最小にする$\theta$というのは
\theta_0 = \arg\min_\theta L(\theta)
であるので、$\theta$と関係ない定数を無視するなどしたら
L(\theta) = \frac{1}{2\sigma}\sum_i\left( y_i - f(\vec{x}_i; \theta)\right)^2
となり、最小二乗法で最小化していた2乗誤差の和の式になりました。
つまり、最小二乗法というのは、誤差が正規分布で乗ってくるという仮定を考えているときの最尤推定法になります。
絶対値の誤差
ここで、誤差をラプラス分布(または指数分布)
p_i = C\exp\left(-\alpha\left|\Delta_i\right|\right)= C\exp\left(-\alpha\left|y_i - f(\vec{x}_i; \theta)\right|\right)
としてみます。これについて同時確率 $P = \prod p_i$ を考え、損失関数 $L(\theta) = -\log P$ を求めてみると、これもまた$\exp$の方に乗っているのを降ろして足し算にするだけなので、
L(\theta) = \alpha\sum_i \left|y_i - f(\vec{x}_i; \theta)\right|
となります。つまり、誤差として絶対値の和を最小化するというのは、誤差がラプラス分布であると仮定していることになります。
補足
それで、なぜ最小二乗法が外れ値に弱く、また絶対値誤差が外れ値に強いというのは、この誤差の確率密度関数の性質にも依るところがあります。
外れ値が再現される確率が、ラプラス分布でも指数的に減るのですが、正規分布だともっと激しく減ってしまいます。この差のため、ラプラス分布だとまあええかあり得るだろう、てなるような外れ値でも正規分布では絶対ないとばかりに中心を外れ値に寄せている感じですね。
補足2
最尤推定においてはもうひとつの仮定として、データが正当に得られたものだと言う仮定と、サンプル同士が独立(i.i.d.)であるということがあります。
また、今回の絶対値誤差のように誤差(残差)が正規分布以外の誤差での回帰については、Wikipediaによると__一般化線形モデル__というそうです。
おまけ
ただの平面フィットを考えます。
なんか適当な $D$ 次元の空間での点群 $X$
X = \{r_1, r_2, \cdots, r_N\}\\
\vec{r}_i = \left(x_i, y_i, z_i, \cdots \right)
が与えられたら、これに平面をフィットさせます。つまり、$D$ 次元の法線ベクトル $\vec{n} = (a, b, c, \cdots)$として、
\vec{n}\cdot\vec{r} + d = ax + by + cz + \cdots + d= 0
が平面の式ですが、与えられた点群に最もフィットした $\vec{n}$ を得たいということを考えます。
結論を言えば点群から計算される行列の対角化、または特異値分解で得ることができます。$D = 3$ 次元の場合を以前にも記事にしました。
誤差の定義
平面パラメータ $\vec{n}$ が決まっていた時、そこから与えられた点 $\vec{r}_i$ までの距離は、
\Delta_i = \frac{\left|\vec{n}\cdot\vec{r}_i + d\right|}{\sqrt{\vec{n}\cdot\vec{n}}}
となります。ここで $\left|\vec{n}\right| = 1$と正規化したものを考えると、
\Delta_i = \left|\vec{n}\cdot\vec{r}_i + d\right|
です。ちょっと式いじってて気づいたのですが、$+d$ の項が邪魔になります。これを除く方法として、
- $\vec{r}_i$ の最後に $1$ を、 $\vec{n}$ の最後に $d$ を追加。最後の $d$ を除いて$\left|\vec{n}\right| = 1$ となるようにスケールしなおす。
- $\vec{r}_i$ を $\vec{c} = \frac{1}{N}\sum_i\vec{r}_i$ で平行移動して平面が原点を通るようにして $d=0$ とする
が考えられます。 以前書いたSVDで平面フィットでは、後者を使いました。とにかく、どちらかの方法で調整して
\Delta_i = \left|\vec{n}\cdot\vec{r}_i\right|
と書きます。

誤差は上の図のように考えます。前の節の導入で出てきたものに比べて、矢印の角度が違いますね。
この角度も含めた最短距離というのが一般の曲線ではどうも難しいので、今回は直線フィットを考えます。
最小二乗法
さて、この誤差が同様に正規分布しているとすると、与えられた点群がそのような座標になる確率は
P\left(X\right|\left.\vec{n}\right) = \prod_i C\exp\left(-\frac{\Delta_i^2}{2\sigma^2}\right)
ですので、この対数尤度は
L(\vec{n}) = \frac{1}{2\sigma^2}\sum_i\left(\Delta_i\right)^2 + const.\\
=\frac{1}{2\sigma^2}\sum_i\left(\vec{n}\cdot\vec{r}_i\right)^2 + const.
というものになります。これを最小化させるというのは、 $\vec{n}$ の各成分で微分したものがすべて0になる点を求めたらいいです。
とりあえず $\vec{n}$ の変数の代表として、$a$ で微分してみます。
\frac{\partial L}{\partial a} = \frac{1}{\sigma}\sum_ix_i\left(\vec{n}\cdot\vec{r}_i\right) = 0
ここで出てくる項のうち、 $\sigma$ は定数、$x_i$ は与えられた数なので、この式を0にしようと思うと $\vec{n}\cdot\vec{r}_i$ を0にするしかなさそうですね。
この事情は $\vec{n}$ の他の次元、$b$ とか $c$ とかでも同じになりそうです。
すると、$\vec{n} = 0$という自明な解を除くとして、$\vec{r}_i$を並べた行列 $R$ を考えると、$\vec{n}\cdot\vec{r}_i$ の順番をちょっと入れ替えますが、
R\vec{n} = 0
とかけます。すると $\vec{n}$ は $R$ の固有値 $0$ に対する固有ベクトルとすれば良さそうですね。
これは以前書いたSVDで平面フィットでの数学の話の結論と同じです。
絶対値
誤差の分布がラプラス分布とした時、
L(\vec{n}) = \alpha\sum_i\left|\vec{n}\cdot\vec{r}_i\right| + const.
となります。これは $\vec{n}$ で微分しようとした時、ところどころに微分できない場合がありますので、最小二乗法の時のように解析的に求められません。なので、数値的に最小化していく必要があります。
この場合はこれ以上数式を弄ることはせず、直接この損失関数を数値的に最小化してくこととします。そのうちそれをやってみた記事でも書こうかな、と思います書きました。
その他
今回はプログラムがありませんね。前回の記事の補足ということでご容赦ください。