ウィルコクソンの順位符号検定のしたいです。
pythons初心者です。
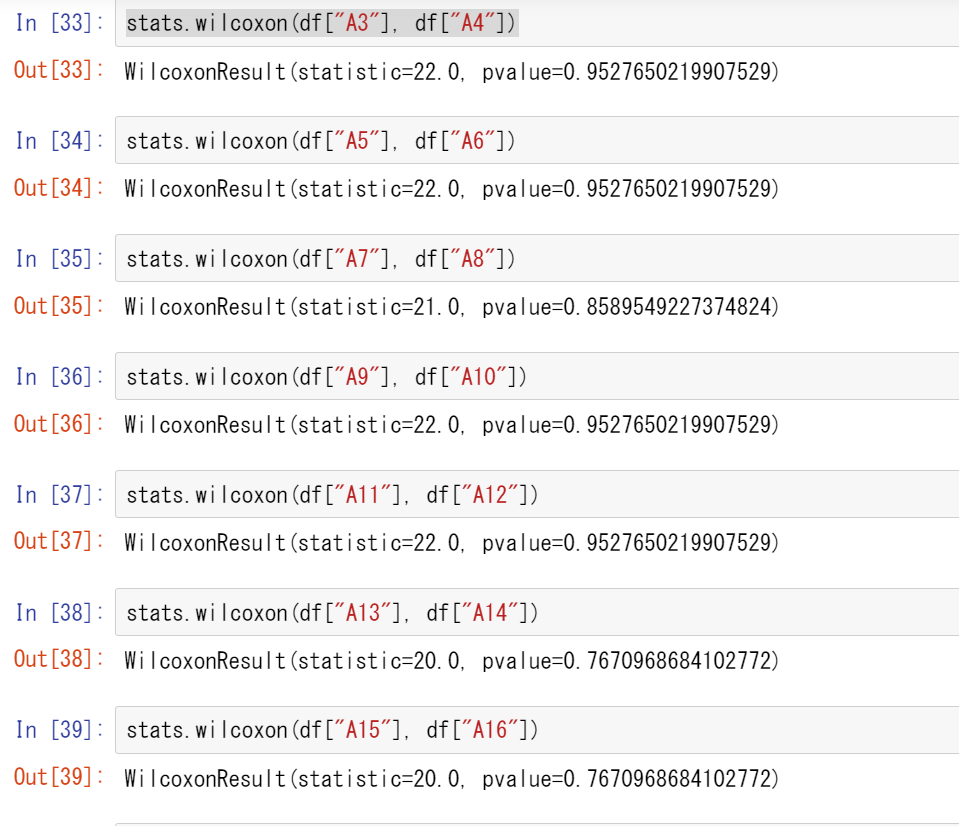
ウィルコクソンの順位符号検定を自分なりに調べて行ってみたのですが、同じ値ばかり出てしまい値が間違っていそうです。
またいまいち正しい方法でやれていると思えません。
このコード、やり方は間違っているのでしょうか。
間違っていれば解決策を教えてください。
やりたいこと
2つの列同士(例:A1とA2)で有意差があるのかを調べたいです。
コード(余計なimportも含まれています)
import
import numpy as np
import numpy.random as random
import scipy as sp
import pandas as pd
from pandas import Series,DataFrame
from scipy import stats
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
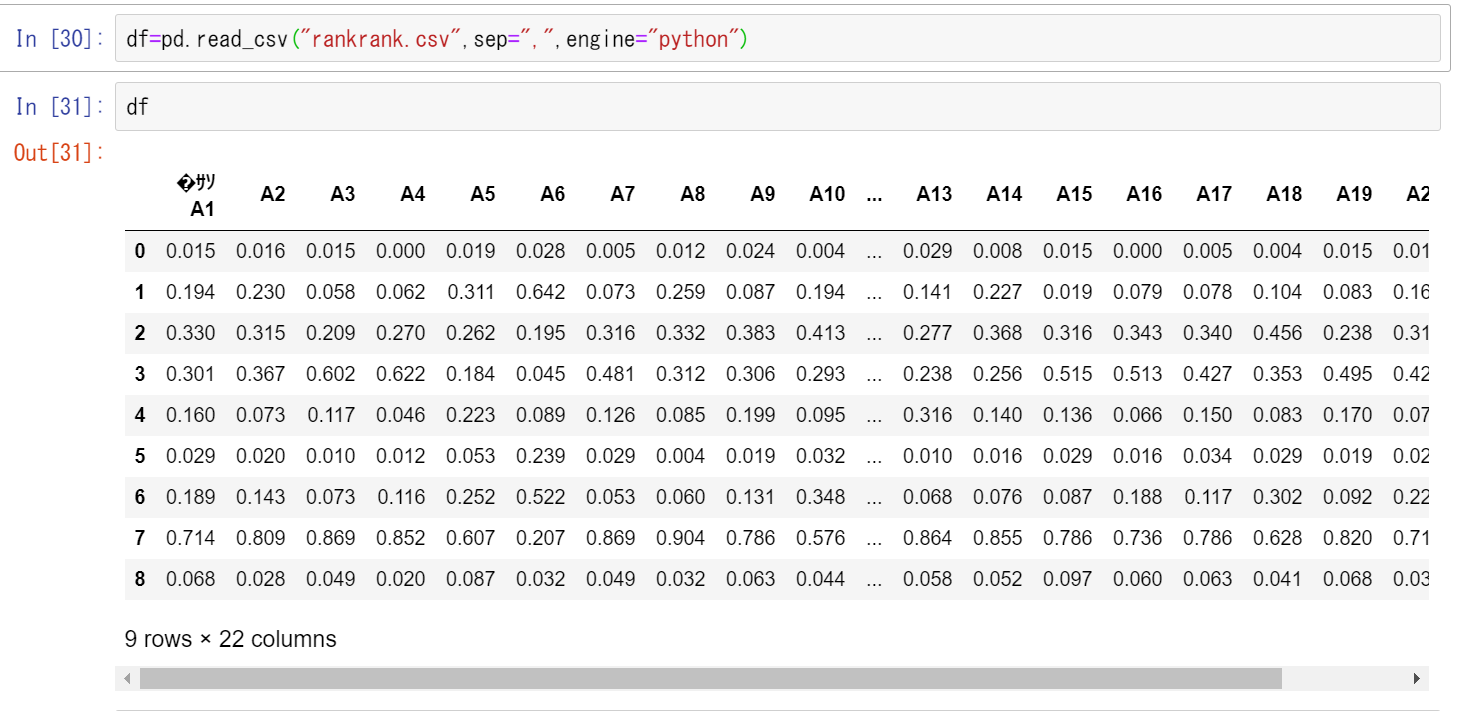
csvファイルの読み込み
df=pd.read_csv("rankrank.csv",sep=",",engine="python")
csvファイル出力
df
検定実行
stats.wilcoxon(df["①"], df["②"]) ※①②にはそれぞれ対応する列名が入ります(例:A1,A2)
画像はcsvファイルと検定の出力結果です(列名A1が文字化けしているのは気にしないでください)
よろしくお願いします。
0 likes