はじめに
PythonもOpenCVもこれまでまったく触れてこなかったけど、ちょっとやってみたいと思ってはじめたので、色々と試しているという状況です。
前回『(2017年12月) PythonとOpenCVをこれからやってみる - 3 - 文字認識(1) - Qiita』はOCR的な事を行ないました。
前々回と合わせて、画像上の読み取り位置を指定する座標設定をする方法が必要な状況なので、今回は簡単なツールを用意する事にしました。
環境はWindows7 64bitです。
座標設定
当初Excelに画像を貼り付けて、その上に図形を置いて、VBAで図形の座標を出力しようと思いましたが、そう言えば、Excelの図形はピクセルで座標を指定できないため、厄介です。
そこで、PowerPointで、その様にすることにしました。
使用するバージョンは2016版です。
まずは、PowerPointに元画像を配置します。
もし、画像が大きい場合、[デザイン]-[スライドのサイズ]でサイズ変更します。
イメージや図形はShapesで参照します。
Presentations(1).Slides(1).Shapes
とりあえず、今回は簡単に済ますため、最初にイメージを貼り付けて、その後に読み取り位置の図形を配置する事にしますので、Shapes(1)が元画像、Shapes(2)以降が読み取り位置の図形として座標設定を出力する形にします。
まずは、座標情報を処理しやすいように簡単なクラスを用意します。
Const vbDq As String = """"
Public x As Long
Public y As Long
Public width As Long
Public height As Long
Public Sub SetData(ByRef s As Shape)
x = WorksheetFunction.Round(s.Left, 0)
y = WorksheetFunction.Round(s.Top, 0)
width = WorksheetFunction.Round(s.width, 0)
height = WorksheetFunction.Round(s.height, 0)
End Sub
Public Sub SubtractPosition(ByRef r As Rectangle)
x = x - r.x
y = y - r.y
End Sub
Public Function GetJsonString() As String
Dim fields As Variant
Dim values As Variant
Dim list(3) As String
Dim i As Long
fields = Array("x", "y", "width", "height")
values = Array(x, y, width, height)
For i = 0 To UBound(fields)
list(i) = vbDq & fields(i) & vbDq & ":" & values(i)
Next
GetJsonString = "{" & Join(list, ",") & "}"
End Function
Shapesから得られる値が小数点以下の値でしたので、WorksheetFunction.Roundを利用しています。
JSON形式の操作については、今回は構造が単純ですので、そのまま出力するようにしました。
続いて、標準モジュールにJSON形式でファイル出力するSubプロシージャを作成します。
Sub OutputJsonFile(ByRef Shapes As Shapes, ByVal FileName As String)
Dim i As Long
Dim list() As String
Dim rect As Rectangle
Dim img As New Rectangle
Dim fs As New FileSystemObject
ReDim list(Shapes.Count - 2)
img.SetData Shapes(1)
For i = 2 To Shapes.Count
Set rect = New Rectangle
rect.SetData Shapes(i)
rect.SubtractPosition img
list(i - 2) = rect.GetJsonString
Next
With CreateObject("ADODB.Stream")
.Charset = "UTF-8"
.Open
.WriteText "[" & Join(list, ",") & "]"
.SaveToFile FileName, 2
.Close
End With
End Sub
次のような感じで実行します。
OutputJsonFile Presentations(1).Slides(1).Shapes,"c:\hoge.json"
[{"x":19,"y":10,"width":785,"height":94},{"x":19,"y":127,"width":57,"height":25},{"x":89,"y":127,"width":65,"height":25},{"x":19,"y":228,"width":117,"height":31},{"x":19,"y":297,"width":747,"height":79}]
座標設定ファイルを読込んで読み取りを行なう
前回のコードを修正して、引数を指定するようにしました。
from PIL import Image
import sys
import pyocr
import pyocr.builders
import cv2
import numpy as np
import json
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
args = sys.argv
img = cv2.imread(args[1], cv2.IMREAD_GRAYSCALE)
# 座標の指定は x, y, width, Height
file = open(args[2], "r", encoding="utf-8_sig")
boxs = json.load(file)
for box in boxs:
#イメージは OpenCV -> PIL に変換する
txt = tool.image_to_string(Image.fromarray(img[box["y"]:box["y"]+box["height"], box["x"]:box["x"]+box["width"]]), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(txt)
>ocr.py hoge.png hoge.json
(②0①⑦ 年 ⑫ 月 ) Python と OpenCV を こ れ か ら
や っ て み る - ① - は じ め の 一 歩
pwhon
ocpancy
は じ め に
Python0 バ イ ソン ) を 中 々 使 う 機 会 が 無 く 、OpenC/ オ ー プ ン シ ー プ
イ ) も 気 に は な り つ つ 使 う 橋 会 が 無 く 。
そ ん な 承 、 ち ょ っ と や っ て み よ う と 思 っ た の で 、 う か ら や る
に あ た っ て の 導 入 や は じ め の 一 歩 な ど 。
邉 境 は Windows⑦ ⑥bt で や り ま す 。
座標設定をExcelへ出力する
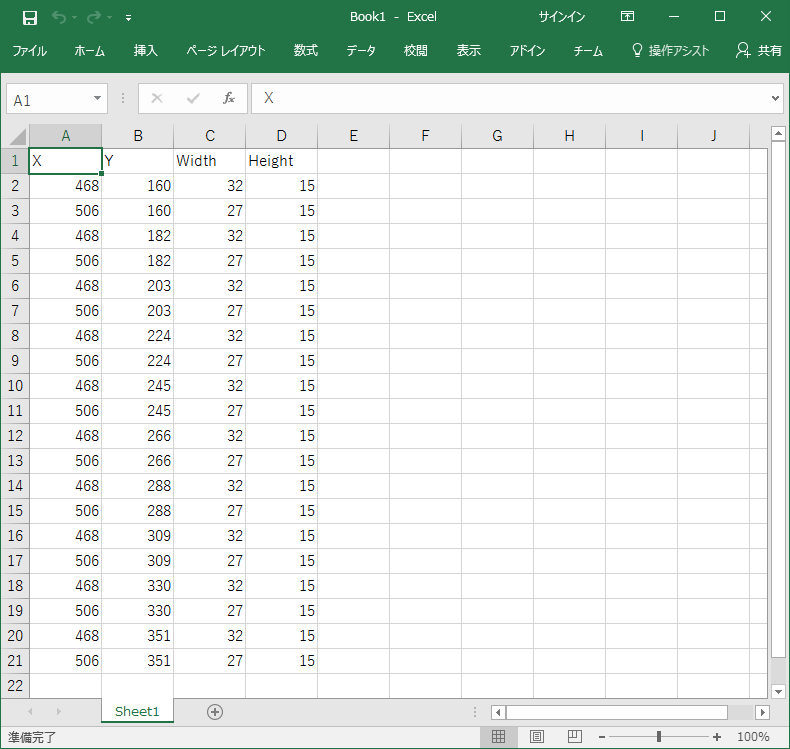
前々回のOMRについては、座標情報だけでなく、マーク有無を判断する閾値と、マーク読み取り時の出力設定なども必要になります。
このため、座標情報をExcel側に出力して、追加の情報をExcelで管理し、Excel側でJSONファイルを出力する事にします。
まずは、PowerPoint側の標準モジュールにExcelへ出力する処理を追加します。
(※参照設定で"Microsoft Excel 16.0 Object Library"を追加しています)
Sub OutputExcel(ByRef Shapes As Shapes)
Dim s As Shape
Dim book As Workbook
Dim sheet As Worksheet
Dim r As Range
Dim i As Long
Dim list As New Collection
Dim img As New Rectangle
Dim rect As Rectangle
img.SetData Shapes(1)
Set book = Workbooks.Add
book.Application.Visible = True
Set sheet = book.Worksheets(1)
sheet.Visible = xlSheetVisible
sheet.Range("A1:D1") = Array("X", "Y", "Width", "Height")
Set r = sheet.Range("A2")
For i = 2 To Shapes.Count
Set rect = New Rectangle
rect.SetData Shapes(i)
rect.SubtractPosition img
r.Offset(, 0) = rect.x
r.Offset(, 1) = rect.y
r.Offset(, 2) = rect.width
r.Offset(, 3) = rect.height
Set r = r.Offset(1)
Next
End Sub
次のように設定してExcelへ出力します。
なお、原因がよくわかっていませんが、画像を挿入した際に元のサイズと変わって挿入されてしまいましたので、次のようにイミディエイトウィンドウでサイズを直接打ち込んで調整しました
Presentations(1).Slides(2).Shapes(1).Width = 699
そして、次のように実行
OutputExcel Presentations(1).Slides(2).Shapes
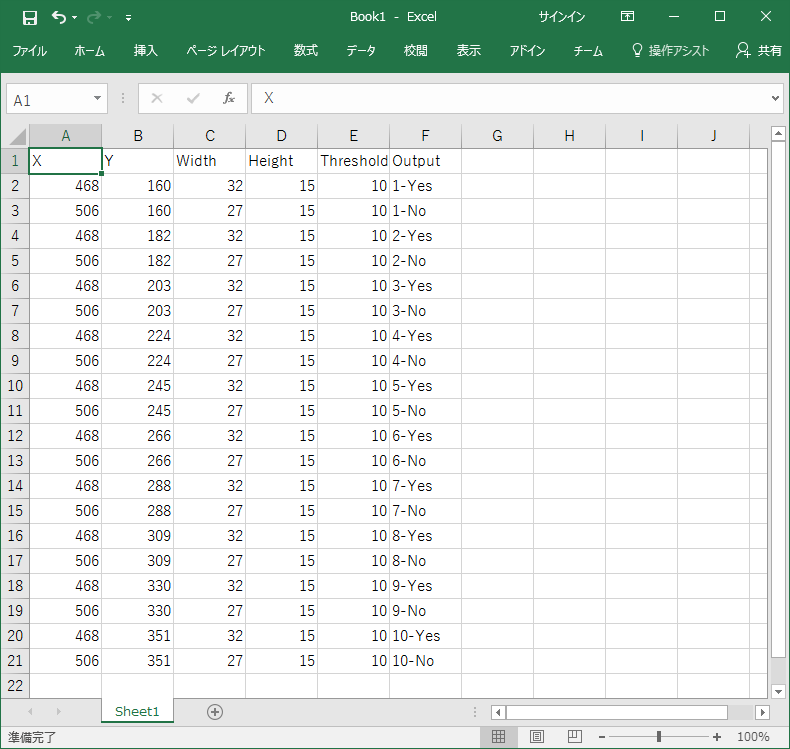
作成されたExcelのシートに閾値の設定と出力する内容の設定を次のようにしました。
そして、出力用の処理を追加して、jsonファイルを出力します。
Const vbDq As String = """"
Sub OutputOMRJsonFile(ByRef ws As Worksheet, ByVal FileName As String)
Dim UsedRange As Range
Dim Caption As Range
Dim i As Long
Dim j As Long
Dim list1() As String
Dim list2() As String
Set UsedRange = ws.UsedRange
Set Caption = UsedRange.Rows(1)
ReDim list1(UsedRange.Columns.Count - 1)
ReDim list2(UsedRange.Rows.Count - 2)
For i = 2 To UsedRange.Rows.Count
For j = 1 To UsedRange.Columns.Count
If Caption.Cells(, j) = "Output" Then
list1(j - 1) = vbDq & Caption.Cells(, j) & vbDq & ":" & vbDq & UsedRange(i, j) & vbDq
Else
list1(j - 1) = vbDq & Caption.Cells(, j) & vbDq & ":" & UsedRange(i, j)
End If
Next
list2(i - 2) = "{" & Join(list1, ",") & "}"
Next
With CreateObject("ADODB.Stream")
.Charset = "UTF-8"
.Open
.WriteText "[" & Join(list2, ",") & "]"
.SaveToFile FileName, 2
.Close
End With
End Sub
OutputOMRJsonFile ActiveSheet, "c:\omr.json"
[{"X":468,"Y":160,"Width":32,"Height":15,"Threshold":10,"Output":"1-Yes"},{"X":506,"Y":160,"Width":27,"Height":15,"Threshold":10,"Output":"1-No"},{"X":468,"Y":182,"Width":32,"Height":15,"Threshold":10,"Output":"2-Yes"},{"X":506,"Y":182,"Width":27,"Height":15,"Threshold":10,"Output":"2-No"},{"X":468,"Y":203,"Width":32,"Height":15,"Threshold":10,"Output":"3-Yes"},{"X":506,"Y":203,"Width":27,"Height":15,"Threshold":10,"Output":"3-No"},{"X":468,"Y":224,"Width":32,"Height":15,"Threshold":10,"Output":"4-Yes"},{"X":506,"Y":224,"Width":27,"Height":15,"Threshold":10,"Output":"4-No"},{"X":468,"Y":245,"Width":32,"Height":15,"Threshold":10,"Output":"5-Yes"},{"X":506,"Y":245,"Width":27,"Height":15,"Threshold":10,"Output":"5-No"},{"X":468,"Y":266,"Width":32,"Height":15,"Threshold":10,"Output":"6-Yes"},{"X":506,"Y":266,"Width":27,"Height":15,"Threshold":10,"Output":"6-No"},{"X":468,"Y":288,"Width":32,"Height":15,"Threshold":10,"Output":"7-Yes"},{"X":506,"Y":288,"Width":27,"Height":15,"Threshold":10,"Output":"7-No"},{"X":468,"Y":309,"Width":32,"Height":15,"Threshold":10,"Output":"8-Yes"},{"X":506,"Y":309,"Width":27,"Height":15,"Threshold":10,"Output":"8-No"},{"X":468,"Y":330,"Width":32,"Height":15,"Threshold":10,"Output":"9-Yes"},{"X":506,"Y":330,"Width":27,"Height":15,"Threshold":10,"Output":"9-No"},{"X":468,"Y":351,"Width":32,"Height":15,"Threshold":10,"Output":"10-Yes"},{"X":506,"Y":351,"Width":27,"Height":15,"Threshold":10,"Output":"10-No"}]
マークを読み取る処理の改善
前々回『(2017年12月) PythonとOpenCVをこれからやってみる - 2 - マークを読取る - Qiita』で作成したコードを次のように修正します。
import sys
import cv2
import numpy as np
import json
args = sys.argv
img1 = cv2.imread(args[1], cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(args[2], cv2.IMREAD_GRAYSCALE)
boxs = json.load(open(args[3], "r", encoding="utf-8_sig"))
for box in boxs:
img1_2 = img1[box["Y"]:box["Y"]+box["Height"], box["X"]:box["X"]+box["Width"]]
img2_2 = img2[box["Y"]:box["Y"]+box["Height"], box["X"]:box["X"]+box["Width"]]
if box["Threshold"] < np.mean(img1_2) - np.mean(img2_2):
print(box["Output"])
次の画像を読み取ってみます。


>omr.py cs1.png cs2.png omr.json
1-Yes
2-No
5-Yes
8-Yes
9-Yes
9-No
10-No
4行目のNoに丸をつけたつもりでしたが、記入の判断がされませんでした。
数値としては4-No : 9.42716049383となっていましたので、こうした部分について閾値で調整する事になってくるかとおもいます。
今回テストで使用している帳票は、本来は☐の部分を塗りつぶす形ですが、上から〇を付ける様なオーバーライトチェックマークを想定した帳票は、なぞるように薄く印刷されていたりするかと思います。
そうした場合、2階調にすればより精度が高くなるのではとも思います。
以上
参考にした記事など
- Office TANAKA - Excel VBA講座:ファイルの操作[UTF-8形式のテキストファイルに書き込む]
- PythonにおいてのJSONファイルの取扱いあれこれ - Qiita
- WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話 - Qiita
- コマンドライン引数 - Python入門から応用までの学習サイト
これまでの記事
| 前回 | 一覧 | 次回 |
|---|---|---|
| 3 - 文字認識(1) | 一覧 | 5 - 学習(1) |