はじめに
Python(パイソン)もOpenCV(オープンシーブイ)もこれまでまったく触れてこなかったけど、ちょっとやってみたいと思ってはじめたので、色々と試しているという状況です。
前回((2017年12月) PythonとOpenCVをこれからやってみる - 2 - マークを読取る - Qiita)はOMR的な事を行ないましたので、今回はOCR的な事をしてみます。
環境はWindows7 64bitです。
Tesseract(テッセラクト)
PythonとOpenCVを使って文字認識するなら、tesseractを使うのが定番のようですね。記事も多いです。
単語そのものは正八胞体(または四次元超立方体)という意味合いのもののようですね。
基本的な説明はWikiなどがありますので、早速インストールを行なっていきます。
GitHubで公開されていますので、基本はそこからソースコードを落としてそこのWikiを参照してビルドしてインストールするようですね。
今回はWindows環境にそのまま入れちゃいますので、インストーラーを利用します。
Wikiの説明をGoogle翻訳にかけると非公式のインストーラーがあるとのこと。
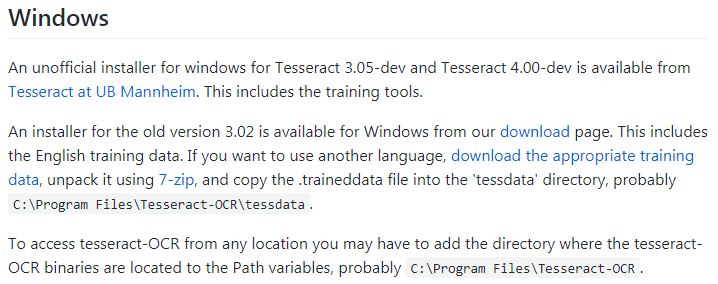
なので、示されているリンク先に行きます。
Home · UB-Mannheim/tesseract Wiki
すると、『tesseract-ocr-setup-4.0.0-alpha.20170804.exe』へのリンクがありますので、そちらからダウンロードします。
インストーラーを実行。
基本は次へをクリックしていくだけですので、コンポーネントの指定のところだけ。
言語データの追加が指定できるようなので、日本語を探してチェックを付けておきます。
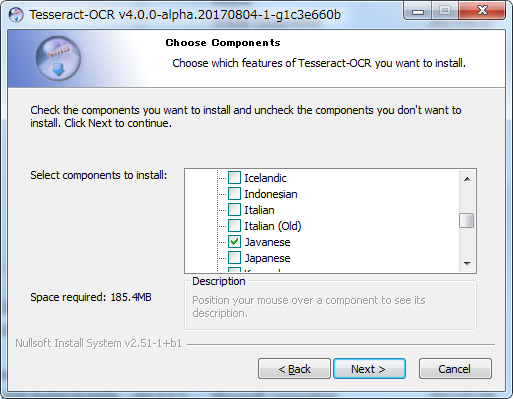
後はまた、指示に従って進めて行きます。
特に問題が無ければエラー無く完了するかと思います。
「Tesseract-OCR」のプログラムのグループに「Console」が追加されていますので、一応そこからコンソールを起動し、バージョン表示を確認してみます。
c:\Program Files (x86)\Tesseract-OCR>tesseract -v
tesseract 4.0.0-alpha.20170804
leptonica-1.74.4
libgif 4.1.6(?) : libjpeg 8d (libjpeg-turbo 1.5.0) : libpng 1.6.20 : libtiff 4
.0.6 : zlib 1.2.8 : libwebp 0.4.3 : libopenjp2 2.1.0
必要ならインストール先のフォルダのパスを通しておきます。
日本語のデータもちゃんとあるか確認してみます。
c:\Program Files (x86)\Tesseract-OCR>tesseract --list-langs
List of available languages (4):
eng
enm
jav
osd
jav?(※チェックする際に"Japanese"ではなく、"Javanese"にチェックをつけていたためです)
しょうがないので、Wiki内の「Other Languages」の項目から、「tesseract-ocr/tessdata」へ行き、jpn.traineddataをダウンロードして、tessdataのフォルダに入れます。
そして、日本語指定で、読み取りを試してみます。
c:\Program Files (x86)\Tesseract-OCR>tesseract hoge.png out -l jpn
Tesseract Open Source OCR Engine v4.0.0-alpha.20170804 with Leptonica
出力されたout.txtを表示してみる、文字の間に半角スペースが挟まっていましたが、大体読み取れていました。
Python + OpenCV + pyocr で特定の範囲を読み取ってみる
pyocr の読み方は パイオーシーアール でしょうか。tesseractをPythonから使えるようにしたラッパーライブラリとのことです。
> pip install pyocr
Collecting pyocr
Downloading pyocr-0.4.7.tar.gz
:
Successfully installed olefile-0.44 pyocr-0.4.7
特に問題なくインストールできました。
pyocrのREADME.markdownに以下のように確認用のコードがありますので、そのまま試してみます。
openpaperwork/pyocr: A Python wrapper for Tesseract and Cuneiform
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[0]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
Will use tool 'Tesseract (sh)'
Available languages: eng, enm, jav, jpn, osd
Will use lang 'eng'
問題ないようですね。
では、次の画像を読み取ってみます。

from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
txt = tool.image_to_string(Image.open("hoge.png"), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(txt)
(②0①⑦ 年 ⑫ 月 ) Python と OpenCV を こ れ か ら
や つっ て み る - ① - は じ め の 一 武
gwhon Opacy
は じ め に
Pthon ひ R イ ソ ン ) を 中 々 使 う 機 会 が 無 く 、OpenC/( オ ー プ ン シ ー
ブ イ ) も 気 に は な り つ つ 使 う 槌 会 無 く 。
そ ん な 折 、 ち ょ っ と や っ て み よ う と 思 っ た の で 、 今 か ら や る
に あ た っ て の 導 入 や は じ め の 一 歩 な ど 。
瑛 境 は Windows⑦ ⑥bt で や り ま す 。
う~ん。なるほど・・・
では、今度は、個別に領域指定して、その範囲を切り抜いた画像を読み取ってみるようにします。
手作業で、次の範囲について座標を調べて、とりあえず直接座標を書き込みます。
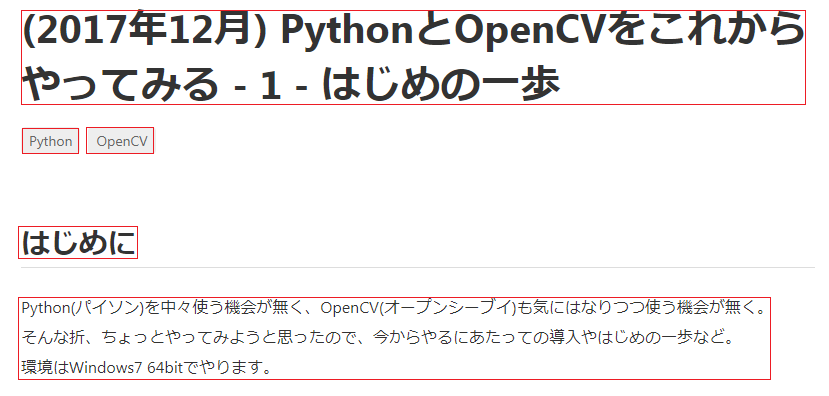
from PIL import Image
import sys
import pyocr
import pyocr.builders
import cv2
import numpy as np
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
img = cv2.imread("hoge.png", cv2.IMREAD_GRAYSCALE)
# 座標の指定は x, y, width, Height
box_area = np.array([[18, 7, 792, 100],
[23, 128, 53, 27],
[90, 128, 65, 23],
[18, 221, 122, 43],
[18, 294, 751, 87]])
for box in box_area:
#イメージは OpenCV -> PIL に変換する
txt = tool.image_to_string(Image.fromarray(img[box[1]:box[1]+box[3], box[0]:box[0]+box[2]]), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(txt)
(②0①⑦ 年 ⑫ 月 ) Python と OpenCV を こ れ か ら
や っ て み る - ① - は じ め の 一 歩
pxhon
ccancy
は じ め に
Python0 バ イ ソ ン ) を 中 々 使 う 機 会 無 く 、OpenC/ オ ー プ ン シ ー ブ
イ も 気 に は な り つ つ 使 う 橋 会 が 無 く 。
そ ん な 折 、 ち ょ っ と や っ て み よ う と 思 っ た の で 、 今 か ら や る
に あ た っ て の 導 入 や は じ め の 一 歩 な ど 。
玲 堤 は Vindows⑦ ⑥④bt で や り ま す 。
多少改善されたようです。
学習させることで精度は上がるようなので、本格的に使うとなると、学習部分について色々とやる必要がありますね。
今回は以上です。
参考
これまでの記事
| 前回 | 一覧 | 次回 |
|---|---|---|
| 2 - マークを読取る | 一覧 | 4 - 座標設定 |