はじめに
Python(パイソン)もOpenCV(オープンシーブイ)もこれまでまったく触れてこなかったけど、ちょっとやってみたいと思ってはじめたので、色々と試しているという状況です。
前回((2017年12月) PythonとOpenCVをこれからやってみる - 1 - Qiita)はとにかくOpenCVで画像を読取って表示するまでをやってみました。
今度は、試しにOCR(オーシーアール)的に文字認識をやってみようと思いましたが、その前にもっと簡単そうなマークを読取るOMR(オーエムアール)的なものを試してみます。
OMRについて
OCR(Optical character recognition)(光学文字認識)に対して、OMR(Optical Mark RecognitionもしくはOptical Mark Reading)(光学式マーク認識)ですね。
マークシートや、アンケートなんかで、「はい・いいえ」でどちらかに○を付けるとかのアレの読み取りですね。
前回、画像の切抜きができましたから、用は、あらかじめ決めた範囲の領域について、グレースケールで考えれば、記入前の数値と記入後の数値が異なれば、指定されていると判断できと考えていいのでしょう。
では、その観点から試してみます。
チェックシートのチェックを読取ってみる
とりあえず、適当に「チェックシート」で検索をかけて目に付いた画像をダウンロードしてきます。(一応その画像のうちのチェック部分のみ抜粋)

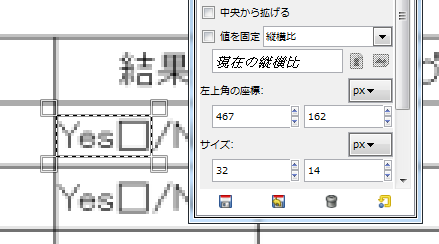
GIMPにて、チェック部分の座標を調べます。
続いて、手書きで丸をしたかのように、○を付けます。

ちなみに、あらかじめ何か書かれてる上にチェックするようなものを、OCR業界?では「オーバライトチェックマーク」とか言ったりするみたいですね。
では、そのオーバーライトチェックマークを読取ってみるプログラムを作ってみます。
オーバーライトチェックマークの判断(画像の塗りつぶれ度合いを判断する)
import cv2
import numpy as np
file1 = "hoge1.png"
file2 = "hoge2.png"
img1 = cv2.imread(file1, cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread(file2, cv2.IMREAD_GRAYSCALE)
img1_2 = img1[162:162+14, 467:467+32]
img2_2 = img2[162:162+14, 467:467+32]
print(np.mean(img1_2))
print(np.mean(img2_2))
> python hoge.py
224.147321429
202.017857143
最初の画像がテンプレート、次が記入したものとなります。
白が255、黒が0なので、何か記入されていれば、その分黒の領域が多くなる事で、元の画像よりも数値が低くなります。
後は閾値を考えて、どの程度の差異でもって記入があったかを判断するようにすればいいでしょう。
座標の入力など、実際にちゃんと作るとなると次のような感じになるでしょうか。
- Excelなどで枠を書いて、VBAでそのシェイプの座標を出力できるようにする
- Pythonで作るプログラムで、その情報を読み取れるようにする
- テンプレートの各座標のグレースケールの合計なり平均値を出力する
- 閾値を決める
- 実際の記入された画像を読込み、テンプレートとの差異を比べて、閾値を超える場合(下回る場合)、記入有りと判断して、何らかのデータを出力する
とすれば、単純なものなら、自動化できそうな気がします。
記入したものをスキャンするなりの工程で座標ズレが出てくる場合、ずれたことで影響する値を考慮して閾値を設定するか、座標ズレを補正する仕組みづくりも必要になってくるかもしれません。
う~ん、何か間違えているかもしれないと怖くなるくらいに、簡単にできてしまうものですね。
以上
参考にした記事など
これまでの記事
| 前回 | 一覧 | 次回 |
|---|---|---|
| 1 - はじめの一歩 | 一覧 | 3 - 文字認識(1) |