【はじめに】
本記事は 「機械学習をどう学んだか by 日経 xTECH ビジネスAI② Advent Calendar 2019」 の19日目になります。
おじさんSEの私がどうやって機械学習を勉強したかを記します。
きっかけは当時抱えていた分類課題において、「機械学習が使えるんじゃね?」というところから始まりました。
闇雲にやっていたので正直記憶は曖昧です。
経歴
プログラム歴は30年近くあります。
小学生の時に覚えたMS BASICから始まり、Z80アセンブラ、MC68000アセンブラ、FORTRAN、C(UNIX)、C++(Mac)、VB、Java(Android)、VB.NET、C#と触ってきました。
いろいろな言語に触れてきましたが、どれも極めるほどガッツリやっていたわけではありません。
機械学習に関しては20年以上前、いわゆる第二次AIブームの終わり頃に卒論のテーマでニューラルネットワークを扱いました。
ただ、ロジック部分は他の者が担っており、私は実装担当だったので、どういうものかはよくわかっていませんでした。
今考えると、このときもっとしっかり勉強しておけばよかったなと思いますが、後の祭りですね。
ちなみに当時は機械学習のライブラリなど皆無でしたので、C言語でゴリゴリ実装していました。
【Pythonの勉強 - 2017年冬】
機械学習を勉強する前に、独学でPythonの勉強をしていました。
きっかけはRaspberry Piで自宅監視をしてみようと思い、その実装にPyhtonを使いました。
とはいえ、コピペして改変できる程度で詳しくはわかっていませんでした。
当時参考にしたのは下記の書籍です。
【カラー図解 最新 Raspberry Piで学ぶ電子工作 作って動かしてしくみがわかる】- Amazon Japan
Raspberry PiはデフォルトでPythonが使えるようになっていたので、Pythonのパの字も知らなかった私にとって、取っ掛かりには良かったです。
ただ、PythonのためだけにRaspberry Piを買うのは現実的ではないので、今ならオンライン学習サイトがおすすめです。
私の周りでは「Paizaラーニング」や「Progate」が無料で評判良かったです。
【「てか、機械学習ってなんだ?」まずは書籍を買ってみた - 2017年春~秋】
当時抱えていた分類課題において、ルールベースでの実装に限界を感じていたのが事の始まりでした。
AIなら何とかしてくれるかも、という幻想を抱きつつも、取っ掛かりをつかめずにいたところ、Pythonのライブラリであるscikit-learnを使えば機械学習を実装できるということを知りました。
そこで、当時新刊で発売された下記の書籍を買ってみました。
【Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎】- Amazon Japan
単純に Python scikit-learn 機械学習 の文字が入っていたからと言うのと、以前から何かとお世話になっているオライリー本だったと言うだけの理由で購入しました。
正直チンプンカンプンで1章と2章の一部しか読めませんでした。
その中で学んだことは以下の通りです。
【1章 はじめに】
・Pythonの文法
・各種ライブラリの存在(scikit-learn、NumPy、pandas、matplotlib)
・Iris Dataset
【2章 教師あり学習】
・k近傍法
・SVM
アウトプット その1 - 業務への適用
この時点では本の内容の10%も理解していなかったと思います。
それでも、とにかく当時抱えていた課題で使えるか、実際に実装してみました。
内容としては多数のパラメータを持つデータの多値分類でした。
当時はルールベースで実装していましたが、精度不足に悩んでいました。
経験的にデータを可視化して俯瞰して見るところまでは出来ていましたが、ほとんどノイズのようなデータに規則性を見いだせず、ルールベースではこれ以上の精度向上は不可能だと感じていました。
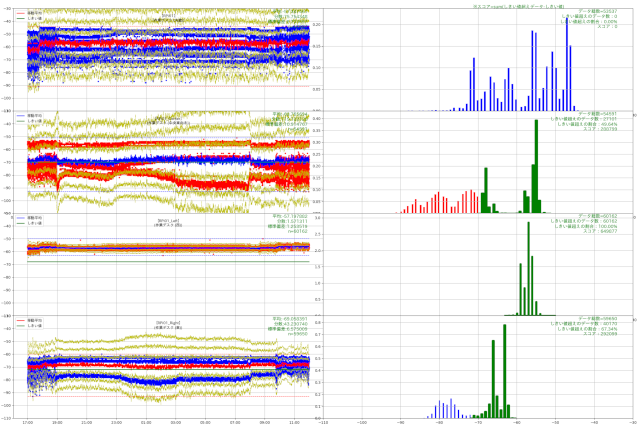
上図は当時扱っていたデータの解析中のイメージです。
このようなデータが数十件ある状態の中での多値分類問題でした。
今なら間違いなく機械学習でやろうと言う話になるのですが、当時は私も含めて社内の人間は全くその発想に行き着かず、必死でルールベースで実装しようとしていました。
このデータをSVMやk近傍法に突っ込んでみたところ、何となく分類されました。
特にk近傍法でハイパーパラメータを総当りで回したところ、ルールベースの時より若干精度が低いものの、ある程度の精度が認められました。
ルールベースで四苦八苦していたのに、データを入れてわずか数分で、そこそこの精度で分類できるモデルが完成したことに対して可能性を感じました。
しかし、当時は精度を上げる術を知りませんでしたし、これ以上時間をかけられないという判断で、手応えを感じつつも機械学習の採用は見送られました。
習得したもの
- Pythonコードを読み/書きできるようになった
- pandas, matplotlibによるデータの可視化
- 「データ準備 > model定義 > fit(学習) > predict(推論)」 の一連の流れ (モデルが変わってもこの流れは一緒)
- 初めて触るプラットフォームではとりあえずアヤメの分類をやってみる
- 結果を恐れずとにかくやってみる
ちなみにこの試みの終盤で長期入院をすることになり、病室でオライリー本を再読しました。
前回よりは読み進める事ができましたが、病室にPCが持ち込めずコーディングが出来なかったせいか、あまり頭には残りませんでした。
やはり手を動かさないと身につかないと痛感しました。
【ディープラーニングに挑戦 - 2018年春~夏】
上記の試みから半年ほどは機械学習から離れていましたが、機械学習に手応えを感じたのでディープラーニングをやってみることにしました。
その際にやったのはTensorFlowのチュートリアルです。

【TensorFlow 2 quickstart for beginners】 - Tensorflow
チュートリアルの内容はMNIST(手書き数字)の分類問題でしたが、当時はTensorFlowのAPIを直接叩く形で読み解けませんでした。
読み解けないながらも、なんとかアヤメの分類を実装してみましたが、全く精度が出せずに一旦は挫折しました。
その後、Kerasの存在を知り、サンプルプログラムを見ながらシーケンシャルモデルを使って画像をCNNにかけて分類する手法を学びました。

【keras-team/keras/examples】- Github
【keras-team/keras/examples/mnist_cnn】- Github
現在はTensorFlowのチュートリアルはKeras(tf.keras)を使う形になっているので、だいぶやりやすくなっていると思います。
なお、当時Raspberry PiやWindows端末で機械学習やTensorFlowを使えるようにしたノウハウを記事にしたものを下記注1にまとめておきます。
Google Colaboratoryを知る
ディープラーニングの勉強をしていた中で一番大きかったのはGoogle Colaboratory(以下、GoogleColab)の存在を知ったことです。
GoogleColabを使うことで、起動するだけでTensorFlowやKerasが使えるようにり、無償でGPUを使って高速に学習できるので、時間的なリソースが一気に減りました。

ここが一つのブレイクスルーで、GoogleColabがなければ私の機械学習の勉強は進まなかったと思います。
今ではTensorFlowのチュートリアルからもGoogleColabに誘導するようになってますし、非常に有用なツールです。
Googleアカウントさえ作ってしまえば無料で使えますので、環境構築や処理速度の遅さに悩んでいる人は是非使いましょう。
アウトプット その2 - 画像分類アプリの試作
この時期はGoogleColab上でMNISTの精度を上げることに繰り返し挑戦していました。
今思えばKaggle内でもMNISTへの挑戦(Digit Recognizer)はできるので、もっと早めにKaggleに参加しておけばよかったなと思います。
この挑戦で取得した技術を使って業務に使えそうな画像分類モデルを実装し、PythonでWebAPI(Flask)を実装し、画像を投げると結果を返す簡易アプリを作りました。
精度は97.5%ぐらいだったと思います。
下図は試作アプリを作る前に行ったPoCイメージです。
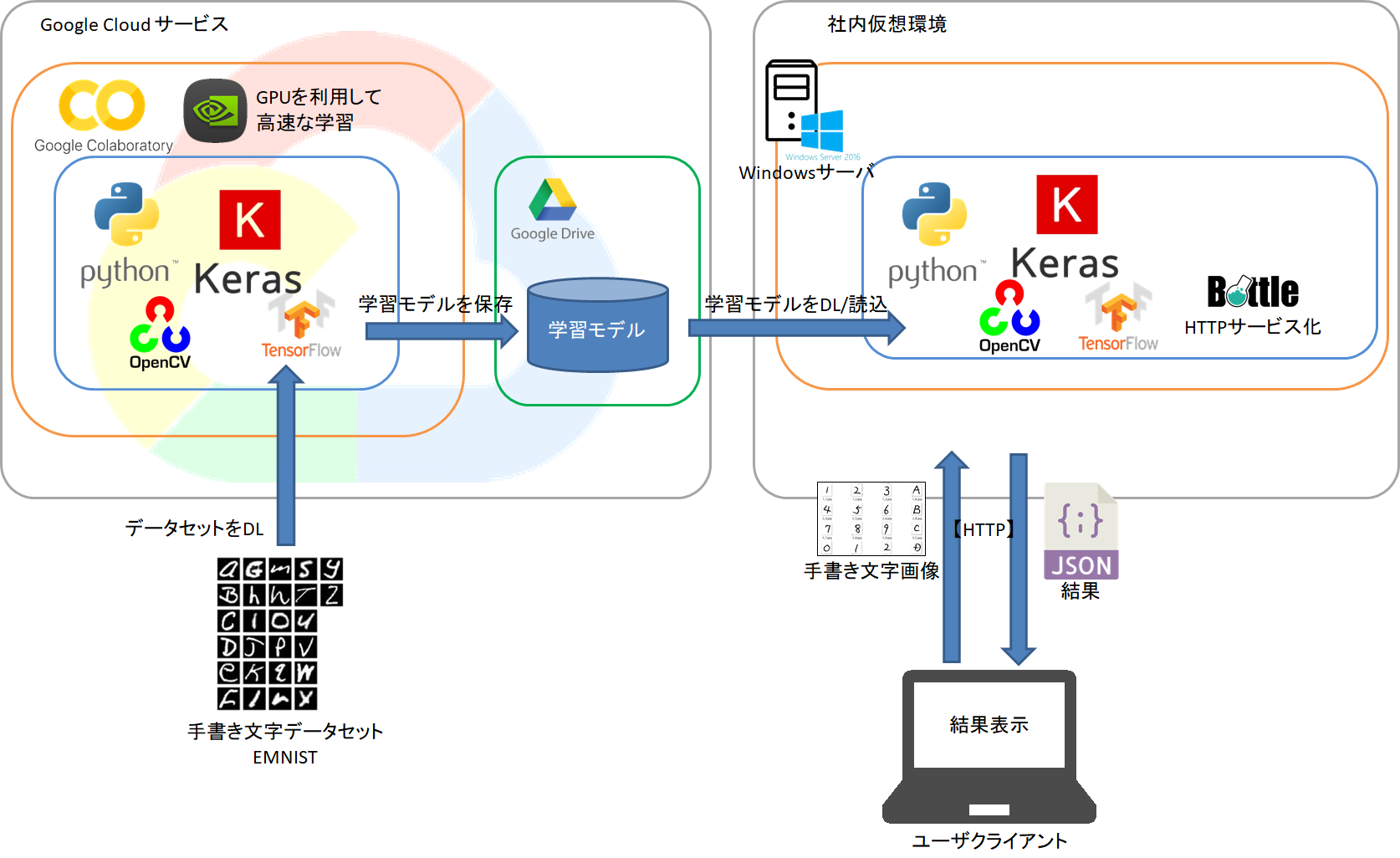
社内でレビューしたところ「1000件で25件間違うとか無いわ」と却下されました。
当時は私も含めてAIリテラシーが低かったので、何の反論もできませんでした…
また、このタイミングでPythonで実装する案件を引き受けました。
機械学習とは直接関連はありませんでしたが、DBやCSVファイルで大量データを扱う案件だったため、Pandasの使い方はここで色々勉強しました。
習得したもの
- Githubの使い方
- KerasによるCNNの実装
- Data Augmentation
- GoogleColabの使い方
- Pythonスキルの習熟
【G検定への挑戦 - 2019年冬】
アウトプット その3 - 社内勉強会の開催
CNNが何なのか少しわかってきたところで、私が講師となり、機械学習やディープラーニングについての社内向けの勉強会を行いました。
ここも大きなターニングポイントとなりました。
社内の機械学習に対する知識がある程度広まったところで、課内全体で機械学習を推し進めようという動きになりました。
これがこの後に続く行動に繋がりました。
アウトプット その4 - G検定取得

上記の勉強会の参加メンバーとともに、G検定に挑戦することにしました。
その際に使った書籍は以下になります。
【深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト】
【AI白書 2019】
同時期に複数の社員がG検定を受けることになったため、社内のAIリテラシーが向上しました。
そのおかげで今まで誰にも相談できなかった機械学習に関する話題を社内で話す機会が増え、私自身かなりストレスが解消しました。
G検定については正直実務で使えるものではないと思っていますが、社員が共通の用語を使って話せるようになったことは非常に有益だったと思います。
やはり一人でやっていては駄目で、仲間を募って切磋琢磨する必要があると感じました。
習得したもの
- アウトプットの重要性の再認識
- 機械学習、AIに関する用語
- 社内のAIリテラシーの向上
- 同じ目的を持った仲間たち (社内)
【ハンズオンセミナーへの参加】
G検定合格後、GoogleやMicrosftが主催する各種の無料ハンズオンセミナーに参加しました。
色々参加しましたが、当時の私にとってはそこまでインパクトはありませんでした。
初心者向けセミナーでは物足りない体になっていたのかも知れません。
長期セミナーへの参加 - 2019年春~秋
そんな中、半年間の長期セミナーに参加する機会を得ました。
その際に、事前学習動画として提供されたのが、下記の動画です。
【【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編 -】- Udemy
【【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 中級編 -】- Udemy
この動画を見て、これまで何となくわかった風で使っていた機械学習を深堀りすることができました。
長期セミナーについては手前味噌になってしまいますのでここでは割愛しますが、セミナーの内容はもとより、他の受講生の方たちと半年間一緒に頑張ったことが得難い経験となりました。

アウトプット その5 - 受講生へのメンタリング
上記セミナーでは受講生として参加しつつ、講師の方にドメイン知識と技術的な支援を行っていました。
セミナー後半は実習メインとなっていたため、受講生ではなくメンターとして参加しました。
初めての機会でうまく出来たかは疑問ですが、自己学習の場としてはとても良かったと思います。
習得したもの
- 機械学習やディープラーニングの数学的な仕組み
- データの前処理の習熟
- ハイパーパラメータチューニング
- 生成モデル
- Function API
- 同じ目的を持った仲間たち (社外)
【これから】
アウトプット その6 - もくもく会などのコミュニティーの形成
現在は機械学習系の「もくもく会」を開催しています。
当初は社内向けでしたが、セミナーの参加メンバーや卒業生が集える場にしつつ、新規で機械学習をやってみようという方のサポートをしています。
また「DEEP LEARNING LAB」にも関わる事になりましたので、そちらにも積極的に絡んでいきます。
狭い地域でもいいので機械学習やAIを通して人がつながるコミュニティを形成して、一人で悩んで諦めてしまう人を少しでも減らしたいと思っています。

【まとめ】
とにかく手を動かそう
色々書きましたが、間違いなく言えることがあります。
それは手を動かしているときが一番伸びるということです。
本やWebの記事を読んでわかった風になったとしても、実際に動かそうとするとつまづきます。
書いてあることを実際に動かしたときに、深く理解できると思います。
可能であればコードをコピペするのではなく、自分で考えて実装してみるのが一番いいです。
十中八九、実装時に躓きます。
実装中にいろいろな課題に直面し、それを乗り越えたことが身につくと思います。
データセットに対する取り組み
とにかく手を動かそうと、アヤメやMNISTなどの既存のデータセット使ってみても、スキルアップの期待値は低いです。
有名なタイタニックのデータセットなども、チュートリアル的に一通り使ってみるのにはいいのですが、正直これらのデータセットではモチベーションが上がらないので、本気で取り組めません。
実際の業務課題など、やりたいことにまつわるデータをなんとかしようとした時に、いろいろな問題にぶつかり、それを解決するために行動したことが、スキルとして身につきます。
業務に直結しなくてもKaggleなどで自分の興味のあるデータセットを探して、そこに対して取り組むのも良いでしょう。
データセットに対する興味でも、賞金に対する興味でもどちらでも良いですが、とにかくモチベーションが上がる課題でないと問題にぶつかった時にすぐに妥協してしまいます。
Kaggleの場合、結果がランクに直結するので成果がわかりやすく、高ランクの人のコードを見ながら、自分の手法と比較できるのでオススメです。
話せる相手を見つける
機械学習という未知の領域に取り組んでいて一番つらかったのは、話せる相手がいなかったということです。
コツコツ一人で取り組むのは行き詰まった時に止まってしまいますし、精神的にも良くないです。
セミナーで出会った多くの方も、社内で話せる人がいないということで、色々と相談を受けました。
お話を伺いながら解決に導いていくのですが、お互い議論しながら解決する方、話しながら自分で解決してしまう方、「もくもく会」に同僚を連れてきて社内に仲間を増やして一緒に解決する方など、いろいろな人がいました。
いずれにしても、他の人と話すことで問題解決に近づく傾向にあります。
話すことも一種のアウトプットなので、頭の中を整理する意味でも話すことは非常に大事だと思います。
社内はもとよりセミナーやもくもく会などのイベントでリアルで話せる相手を見つけるのが理想です。
そうでなくてもKaggleのフォーラムなどオンラインでやり取りするのもありかと思います。
【おわりに」
機械学習やAIに関しては、日本はまだまだ未成熟です。
情報も英語が多く、目的の情報を探し出せずに壁にぶち当たるシーンも多々あります。
そんな時一人で悩むのはやめましょう。
悩むぐらいなら上司でも同僚でも誰でもいいので、他人を巻き込みましょう。
周りにいないなら、更に外に目を向けましょう。
世の中には同じように悩んでいる方がたくさんいます。
ネット社会の今なら同じ境遇の人たちをすぐ見つけることが出来ます。
私も皆さんのお手伝いができるよう勉強を続けていきますので、一緒に頑張っていきましょう。