はじめに
以前、構造化データで教師データが少ない時の学習について記事を書きましたが、画像認識でも教師データ不足はよくあることで、その場合、データ拡張と転移学習を使うのが一般的です。
そこで今回は、画像認識でよく使われるVGG16の転移学習をKerasで試してみます。
特に転移学習のファインチューニングの有無でどのくらい精度が変わるか、比較をしてみようと思います。
転移学習とは
転移学習は、あるタスクに対して訓練されたモデルを他の関連するドメインやタスクに応用する手法です。
画像認識や自然言語処理で発展した手法で、オリジナルモデルの高い認識能力を利用して、より少ないデータ、より短い時間で学習できる点が魅力です。
既存の学習済みモデルを利用しますが、重みデータを更新せずに特徴抽出器として利用する方法と、重みの一部を更新するファインチューニングと呼ばれる方法があります。
ファインチューニングでは、畳み込みニューラルネットワークが浅い層ほどエッジなどの汎用的な特徴を、深い層ほど教師データに特化した特徴を抽出する傾向があることを利用し、再調整が必要な層を学習します。
今回使用するVGG16は、オックスフォード大学の研究グループが2014年に発表したCNNモデルです。
シンプルな構造ながらImagenetの画像認識コンペで2位を取った高精度なモデルで、今もKerasやPytorchに学習済みモデルが用意されています。構成図はこちらです。
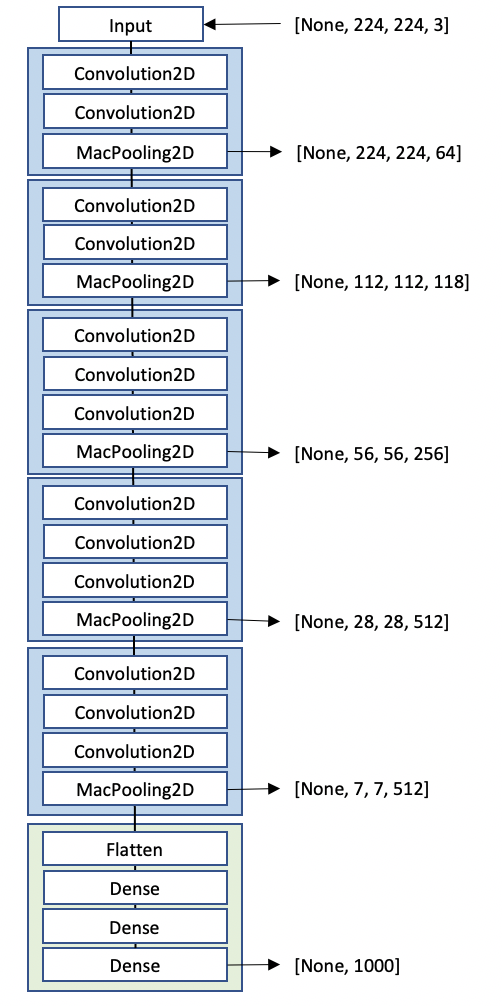
畳み込み層13層、全結合層3層の計16層から構成されています。
VGG16で転移学習を行う場合、モデルから全結合層を外して新たに追加するのが一般的です。その際、VGG16の重みを更新するかどうかを選べるので、今回は、
- VGG16が抽出する特徴を使って、全結合層のみ学習する
- 今回の分類に合うように、VGG16の全結合層一つ前の重みと全結合層を学習する
以上2つを試し、重みの更新の有無によって精度がどう変わるのか、比較してみます。
教師データ
教師データは、画像認識でベンチマークに使用されるCIFAR-10 datasetを使いました。
物体カラー写真の画像データセットで、乗り物や動物など10種のクラスからなり、各クラス1300枚前後の画像が含まれます。VGG16が学習したImagenetのデータセットにも乗り物や動物が含まれるので、ドメインは近そうです。

今回はそのうち、学習データ10000枚、検証データ2500枚を使用しました。
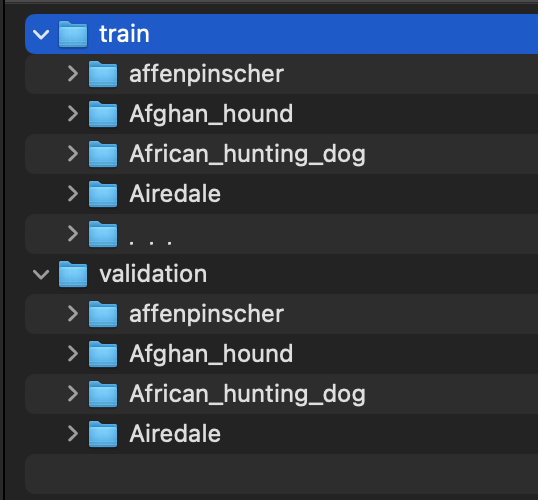
なお、Kerasの学習では、trainとvalidationのデータセットは下記の構造にする必要があります。
サイトからCIFAR-10 python versionというバイナリファイルをダウンロードして、下記コードを使って画像ファイルとして保存しました。
バイナリファイルと処理ファイルは同じ階層にある前提です
CIFAR-10を保存するコード
import pickle, os
import numpy as np
from PIL import Image
train = {}
base_dir = "cifar-10-python/"
train_file_list = [c for c in os.listdir(base_dir) if 'data_batch' in c]
def unpickle(f):
fo = open(f, 'rb')
d = pickle.load(fo, encoding="latin-1")
fo.close()
return d
def parse_pickle(rawdata, rootdir):
for label_name in label_names:
label_dir = rootdir + "/" + label_name
if not os.path.exists(label_dir):
os.mkdir(label_dir)
m = len(rawdata["filenames"])
for i in range(m):
if i % 100 == 0:
print(i)
filename = rawdata["filenames"][i]
label = label_names[rawdata["labels"][i]]
data = rawdata["data"][i]
data = data.reshape(3, 32, 32)
data = np.swapaxes(data, 0, 2)
data = np.swapaxes(data, 0, 1)
with Image.fromarray(data) as img:
img.save(f"{rootdir}/{label}/{filename}")
label_names = unpickle(os.path.join(base_dir, "batches.meta"))["label_names"]
for train_file in train_file_list:
train = unpickle(os.path.join(base_dir, train_file))
parse_pickle(train, "cifar-10-raw/train")
test = unpickle(os.path.join(base_dir, 'test_batch'))
parse_pickle(test, "cifar-10-raw/test")
実験
全結合層のみ学習
はじめに、全結合層のみの学習を試してみます。
まず画像ファイルを読み込み、データ拡張を行います。パラメータはVGG16の preprocess_input を使用します。
from keras.layers import Dense, Input, GlobalAveragePooling2D, Dropout
from tensorflow.keras.optimizers import Adam
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import CSVLogger
from keras.models import Model
# path
TRAIN_DATA_PATH = "/Users/myname/src/vgg16/dataset/train/"
VALIDATION_DATA_PATH = "/Users/myname/src/vgg16/dataset/validation/"
# ハイパーパラメータ
image_resize = 224
num_classes = 10
batch_size = 32
epochs = 50
## training dataの読み込みとデータ拡張
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
train_generator = train_datagen.flow_from_directory(
TRAIN_DATA_PATH,
target_size=(image_resize, image_resize),
batch_size=batch_size,
class_mode='categorical',
shuffle=False
)
## validation dataの読み込みとデータ拡張
validation_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
validation_generator = validation_datagen.flow_from_directory(
VALIDATION_DATA_PATH,
target_size=(image_resize, image_resize),
batch_size=batch_size,
class_mode='categorical',
shuffle=False
)
次に、モデルの構築です。
VGG16を読み込んで新たな全結合層を構築し、VGG16のモデルと結合します。その際、
# 重みを固定
for layer in vgg16_model.layers:
layer.trainable = False
と、重みの更新を止めてしまいます。モデルの設定は以下の通り。
# VGG16のモデルと重みをインポート
input_tensor = Input(shape=(image_resize, image_resize, 3))
vgg16_model = VGG16(
include_top=False, #全結合層を除外
weights='imagenet',
input_tensor=input_tensor
)
# 重みを固定
for layer in vgg16_model.layers:
layer.trainable = False
# 全結合層の構築
x = vgg16_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(num_classes, activation="softmax")(x)
# VGG16と構築した全結合層を結合
model = Model(inputs=vgg16_model.input, outputs=predictions)
csvlogger_cb = CSVLogger('./history.csv')
optimizer = Adam(lr=0.0001)
model.compile(loss="categorical_crossentropy",
optimizer=optimizer,
metrics=["accuracy"])
# 構築したモデルを確認
model.summary()
# 訓練実行
history = model.fit(
train_generator,
validation_data=validation_generator,
epochs=epochs,
batch_size=batch_size,
callbacks=[csvlogger_cb]
)
# モデルを保存
model.save_weights("bottleneck_fc_model.h5")
モデルのglobal_average_pooling2d_5 以降が新たに結合した層です。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
global_average_pooling2d_5 ( (None, 512) 0
_________________________________________________________________
dense_10 (Dense) (None, 1024) 525312
_________________________________________________________________
dropout_5 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_11 (Dense) (None, 10) 10250
=================================================================
一部の重みと全結合層を学習(ファインチューニング)
次にファインチューニングです。
全結合層一つ前のblock5_conv1 (Conv2D)以降の重みを更新します。重みを固定する層を指定すれば、設定完了です。
# block5_conv1 (Conv2D)より前の重みを固定
for layer in vgg16_model.layers[:15]:
layer.trainable = False
trainableの設定をみると、block5_conv1以降がTrueになっているのが確認できます。
for i in model.layers:
print(i.name, i.trainable)
input_1 False
block1_conv1 False
block1_conv2 False
block1_pool False
block2_conv1 False
block2_conv2 False
block2_pool False
block3_conv1 False
block3_conv2 False
block3_conv3 False
block3_pool False
block4_conv1 False
block4_conv2 False
block4_conv3 False
block4_pool False
block5_conv1 True
block5_conv2 True
block5_conv3 True
block5_pool True
global_average_pooling2d True
dense True
dropout True
dense_1 True
訓練結果
それでは、二つのモデルの訓練結果を比較してみましょう。
全結合層のみ学習
(結果)
- accuracy: train=0.8407 / validation=0.6920

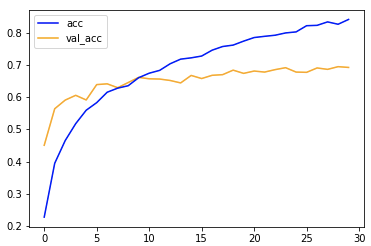
accuracyは0.692であまり伸びませんでした。
trainと比べるとvalidationは10エポック以降の学習の進みがよくありません。
一部の重みと全結合層を学習(ファインチューニング)
(結果)
- accuracy: train=0.9995 / validation=0.8004
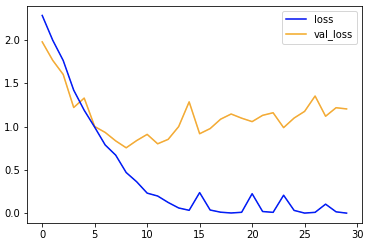

過学習気味なのは変わりませんが、結果は0.8004と+0.108上昇しました。
全結合層のみと比べると、trainとvalidationの初期の学習傾向が近く、10エポックで精度0.8付近まで向上しています。
まとめ
今回は、ファインチューニンの有無による転移学習の精度の違いを比べました。
実験の結果、精度は0.108向上し、ファインチューニングが精度向上に寄与することがわかりました。今回のタスクに合わせて全結合層一つ前の重みを再調整したことが功を奏したようです。
一方、今回のモデルは10エポック以降のvalidationの学習の進みが良くありませんでした。
最適化や汎化性能、ハイパーパラメータのチューニングに工夫の余地がありそうです。
参考
畳込みニューラルネットワークの基本技術を比較する ーResnetを題材にー
機械学習における転移学習・ドメイン適応 | AIdrops
Keras / Tensorflowで転移学習を行う
Deep learningで画像認識⑧〜Kerasで畳み込みニューラルネットワーク vol.4〜
VGG16のFine-tuningによる犬猫認識 (2) - 人工知能に関する断創録
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける