概要
Keras(Tensorflowバックエンド)で、画像認識の分野で有名なモデルVGG16を用いた転移学習を行いました。
そもそもディープラーニングとは?Kerasって何?という方は、こちらの記事をご参照下さい。
転移学習とファインチューニングの違い
転移学習とファインチューニングは、どちらも既存のモデル(今回はVGG16)を応用したディープラーニングの学習方法です。その為この2つはよく混同されていますが、厳密には異なります。
参考:Quora: What is the difference between transfer learning and fine tuning?
ざっくりと説明すると、違いは以下になります。
- 転移学習:既存の学習済モデル(出力層以外の部分)を、重みデータは変更せずに特徴量抽出機として利用する。
- ファインチューニング:既存の学習済モデル(出力層以外の部分)を、重みデータを一部再学習して特徴量抽出機として利用する。
本記事では、転移学習について説明していきます。
転移学習のプロセス
転移学習のプロセスは、二段階に分かれます。
- 第一段:入力画像から、特徴量(ボトルネック特徴量)を抽出する
- 第二段:ボトルネック特徴量を用いて、クラス分類をする
まず第一段では、ImageNetなどのコンテスト向けに作成されたディープラーニングのモデル(及び学習済みの重み含む)を、最終層(フル結合層:FC。ImageNetでは1000クラスに分類)以外の部分を利用して、入力画像を特徴量に変換します。この変換後の特徴量を、ボトルネック特徴量とも言います。
次に第二段では、新規に作成した任意のアウトプットを出力する簡単なモデル(今回は2クラスに分類する)に対して、上記のボトルネック特徴量を入力として学習、予測を行います。
ここで重要なのは、「第一段で利用した利用元のモデルでは一切学習を行なっていない」という点です。
つまり転移学習では、VGG16など大規模なデータを用いて学習した強力なモデルを特徴抽出器として利用し(多数の対象を分類できる為、画像の特徴を捉えるのが非常に上手い)、任意のクラスの分類する為の特徴量の圧縮器として利用しています。
実装
今回、参考記事を参考に実装を行いました。
Jupyter Notebookのソースコードはこちら(Github)を参照下さい。
1. データの準備
今回は、データ解析のコンペティションサイトのKaggleよりこちらのデータを使用します。
下記プログラムで2000枚の犬と猫の画像を適切なフォルダに格納します。
import urllib.request
import zipfile
source_dir = "./tmp/trainData"
train_dir = "./dataset/trainData"
valid_dir = "./dataset/validationData"
os.makedirs("%s/dogs" % train_dir)
os.makedirs("%s/cats" % train_dir)
os.makedirs("%s/dogs" % valid_dir)
os.makedirs("%s/cats" % valid_dir)
# Kaggleよりデータをダウンロードする
url = "https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/download/train.zip"
urllib.request.urlretrieve(url, './tmp/trainData.zip')
# データの解凍
with zipfile.ZipFile('./tmp/trainData.zip', 'r') as f:
f.extractall('./train/')
# 訓練用データの格納
for i in range(1000):
os.rename("%s/dog.%d.jpg" % (source_dir, i + 1), "%s/dogs/dog%04d.jpg" % (train_dir, i + 1))
os.rename("%s/cat.%d.jpg" % (source_dir, i + 1), "%s/cats/cat%04d.jpg" % (train_dir, i + 1))
# 検証用データの格納
for i in range(400):
os.rename("%s/dog.%d.jpg" % (source_dir, 1000 + i + 1), "%s/dogs/dog%04d.jpg" % (valid_dir, i + 1))
os.rename("%s/cat.%d.jpg" % (source_dir, 1000 + i + 1), "%s/cats/cat%04d.jpg" % (valid_dir, i + 1))
2.ボトルネック特徴量データの作成
次に、上記で説明した転移学習プロセスの第一段、「入力画像から、特徴量(ボトルネック特徴量)を抽出する」を行います。
既存モデルとして、VGG16を使用します。
VGG16は、畳み込み層13層、全結合層3層、1000クラスを分類するニューラルネットワークです。Oxford大学のVisual Geometry Groupによる、2014年のILSVRCコンペティションで優勝したモデルです。
Kerasのkeras.applications.vgg16クラスにより、既存モデルを簡単にimportすることができます。今回は、出力層を除いて使用します。
# VGG16(model & weight)をインポート
model = VGG16(include_top=False, weights='imagenet')
model.summary()
# 画像データをnumpy arrayに変換
## training dataの読み込み
image_data_generator = ImageDataGenerator(rescale=1.0/255)
train_data = image_data_generator.flow_from_directory(
'dataset/train',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
## validation dataの読み込み
image_data_generator = ImageDataGenerator(rescale=1.0/255)
validation_data = image_data_generator.flow_from_directory(
'dataset/validation',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False
)
# VGG16を使用してボトルネック特徴量データを生成する
## training data
bottleneck_feature_train = model.predict_generator(train_data, n_train_samples, verbose=1)
## validation data
bottleneck_feature_validation = model.predict_generator(validation_data, n_validation_samples, verbose=1)
# bottleneck featuresの保存
## traning data
np.save(base_dir + prefix + train_file_name, bottleneck_feature_train)
## validation data
np.save(base_dir + prefix + validation_file_name, bottleneck_feature_validation)
# Bottleneck featuresの読み込み
train_data = np.load(base_dir + prefix + train_file_name)
len_input_samples = len(train_data)
train_labels = np.array([0] * int(len_input_samples/2) + [1] * int(len_input_samples / 2))
validation_data = np.load(base_dir + prefix + validation_file_name)
validation_labels = np.array([0] * int(n_validation_samples / 2 *32) + [1] * int(n_validation_samples / 2 * 32))
次に、今回の犬猫を判定する全結合層のモデルを作成します。
# 全結合層の作成
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras import optimizers
input_shape = train_data.shape[1:]
model = Sequential()
model.add(Flatten(input_shape=input_shape))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
最後に、モデルを学習させます。
# モデルの学習
result_dir = './out/history_vgg16_transfer_learning.txt'
# callbacks
callbacks = keras.callbacks.TensorBoard(log_dir='./out/tensorBoard', histogram_freq=0)
# 学習の実施
history = model.fit(train_data, train_labels, epochs=20, batch_size=32, callbacks=[callbacks], validation_data=(validation_data, validation_labels))
# 重みの保存
model.save_weights('./out/vgg16_transferlearning_weights.h5')
# 学習履歴の保存
loss = history.history['loss']
acc = history.history['acc']
val_loss = history.history['val_loss']
val_acc = history.history['val_acc']
with open(result_dir, "w") as fp:
fp.write("epoch\tloss\tacc\tval_loss\tval_acc\n")
for i in range(len(acc)):
fp.write("%d\t%f\t%f\t%f\t%f\n" % (i, loss[i], acc[i], val_loss[i], val_acc[i]))
今回作成した全結合層のモデルイメージはこちらです。
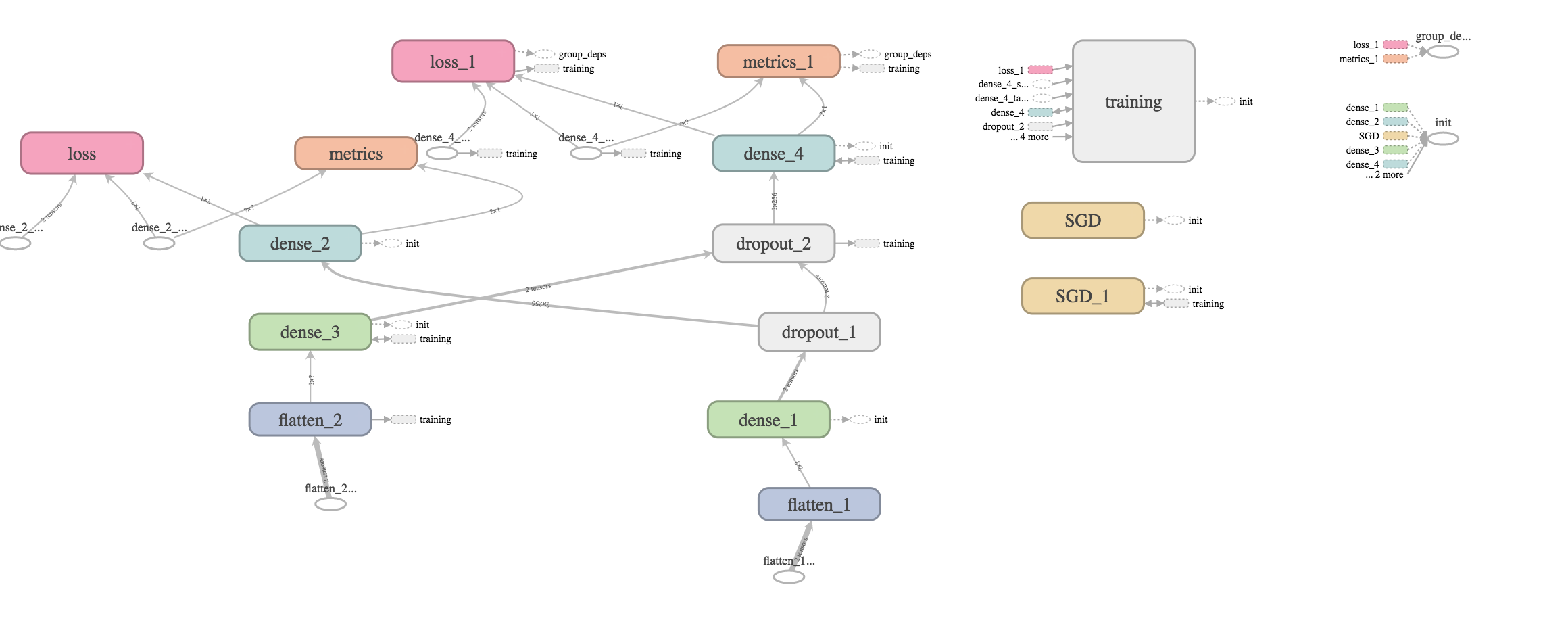
まとめ
今回はVGG16を使用した転移学習を行いました。
上記を見てわかるように、独自で作成するのは出力を行う全結合層のみとなっております。特徴量抽出に用いるVGG16は1000クラスを分類することのできるモデルである為、かなり汎用的な特徴検出器と言えますが、学習に使っていない個別のモデルを認識
するにはVGG16の重みも含めた学習を行うファインチューニングが必要となります。
次回は、VGG16の部分も学習するファインチューニングを行っていきます。VGG16のモデル部分も含めて学習することになりローカルPCでは学習に数日かかってしまう為、AWS AMIを用いて学習を実施していきます。