LSTMの挙動の理解です。
マニアックな処理をしたい場合の調査用です。(元はR2D2のburninの実装用)
import
以下のimportはすでにされてるとして省略します。
import random
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import layers as kl
import pandas as pd
import matplotlib.pyplot as plt
1.基本的なLSTM
0または1の時系列に対して合計を求めるデータセットを考えます。
データセットを生成するコードは以下です。
def create_data(data_num, sequence_len):
x = np.random.randint(0, 2, (data_num, sequence_len)).astype(np.float32)
y = np.sum(x, axis=1).reshape((data_num, 1))
return x[..., np.newaxis], y
x, y = create_data(1, 5)
print(x.shape) # (1, 5, 1)
print(x) # [[[0.] [1.] [0.] [1.] [1.]]]
print(y.shape) # (1, 1)
print(y) # [[3.]]
create_dataはデータ数と長さを引数に取り、入力データと正解データを返します。
モデルは以下です。
model = keras.models.Sequential([
kl.Input(shape=(None, 1)), # ※1
kl.TimeDistributed(kl.Dense(32)), # ※2
kl.LSTM(32),
kl.Dense(1),
])
model.summary()
※1 入力は(時系列の数, shape)
※2 LSTMまでは時系列を保持する必要があるので、入力~LSTMまでの間にLayerをはさむ場合は、TimeDistributed を使用して時系列の次元を保持する
学習は以下です。
時系列の長さは20です。
# データセット作成
x_train, y_train = create_data(1000, 20)
x_valid, y_valid = create_data(100, 20)
# 学習
model.compile(loss="mse", optimizer="adam")
history = model.fit(x_train, y_train, batch_size=32, epochs=100, validation_data=(x_valid, y_valid))
# 学習過程
df_hist = pd.DataFrame(history.history)
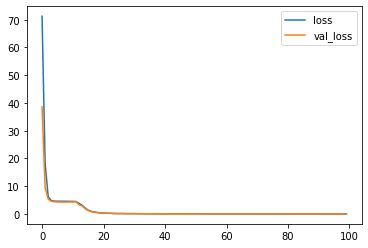
df_hist[["loss", "val_loss"]].plot()
plt.show()
・学習過程
学習結果の一部を見てみると以下です。
x_test, y_test = create_data(1, 20)
y_pred = model(x_test) # 予測
print(x_test.flatten()) # [1. 1. 1. 0. 0. 1. 1. 1. 0. 1. 1. 1. 0. 0. 1. 0. 0. 0. 0. 1.]
print(y_test) # [[11.]]
print(y_pred.numpy()) # [[11.001144]]
ちゃんと学習できていますね。
調査1. 時系列の長さを変えた場合の予測
学習は時系列の長さが20でしたが、1~40まで変えた場合の予測結果を見てみます。
plot_x = []
plot_y = []
for i in range(1, 40):
x_valid, y_valid = create_data(100, i)
y_pred = model(x_valid)
mse = keras.metrics.MeanSquaredError()(y_valid, y_pred).numpy()
plot_x.append(i)
plot_y.append(mse)
plt.plot(plot_x, plot_y)
plt.xlabel("sequence len")
plt.ylabel("MSE")
plt.show()
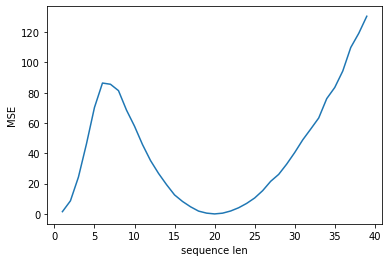
20ではちゃんと予測できていますが、それ以外は20から離れるほど精度が落ちています。
これはLSTMが途中経過は学習しておらず、最後結果のみを学習していることが原因です。
2.計算過程を含めて学習
0または1の時系列に対して合計を求める所は同じですが、今度は途中経過も教師データとして学習させます。
データセットの生成コードは以下です。
def create_data_timesteps(data_num, sequence_len):
x_list = []
y_list = []
for _ in range(data_num):
n = 0
for _ in range(sequence_len):
x = random.randint(0, 1)
n += x
x_list.append(x)
y_list.append(n)
x_list = np.array(x_list).reshape((data_num, sequence_len, 1))
y_list = np.array(y_list).reshape((data_num, sequence_len, 1))
return x_list, y_list
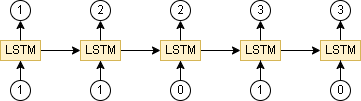
x, y = create_data_timesteps(1, 5)
print(x.shape) # (1, 5, 1)
print(x) # [[[1] [1] [1] [0] [0]]]
print(y.shape) # (1, 5, 1)
print(y) # [[[1] [2] [3] [3] [3]]]
モデルは以下です。
model = keras.models.Sequential([
kl.Input(shape=(None, 1)),
kl.TimeDistributed(kl.Dense(32)),
kl.LSTM(32, return_sequences=True), # ※3
kl.TimeDistributed(kl.Dense(1)), # ※4
])
model.summary()
※3 return_sequences=Trueにすると最後の出力だけでなく、全出力を返します。
※4 出力層にも時系列がほしいので、TimeDistributed を追加しています。
同様に長さ20で学習します。
# データセット作成
x_train, y_train = create_data_timesteps(1000, 20)
x_valid, y_valid = create_data_timesteps(100, 20)
# 学習
model.compile(loss="mse", optimizer="adam")
history = model.fit(x_train, y_train, batch_size=32, epochs=100, validation_data=(x_valid, y_valid))
# 学習結果
df_hist = pd.DataFrame(history.history)
df_hist[["loss", "val_loss"]].plot()
plt.show()
・学習過程
・学習結果の一部
x_test, y_test = create_data_timesteps(1, 20)
y_pred = model(x_test) # 予測
print(x_test.flatten()) # [1 0 0 0 1 1 1 1 0 1 1 1 1 0 0 0 1 1 0 1]
print(y_test.flatten()) # [ 1 1 1 1 2 3 4 5 5 6 7 8 9 9 9 9 10 11 11 12]
print(y_pred.numpy().flatten())
# [ 1.0127519 0.9785429 0.9656553 0.96232927 1.9568805 2.9836545
# 3.9930987 4.982367 4.981758 5.9777784 6.9905696 8.007053
# 9.018621 9.0236225 9.002367 8.9889345 10.002424 10.991257
# 10.980751 11.983499 ]
途中経過も含めてちゃんと学習できていますね。
調査2. 時系列の長さを変えた場合の予測(途中経過学習済み)
同様に時系列の長さを1~40まで変えた場合の結果を見てみます。
plot_x = []
plot_y = []
for i in range(1, 40):
x_valid, y_valid = create_data_timesteps(100, i)
y_pred = model(x_valid)
mse = keras.metrics.MeanSquaredError()(y_valid, y_pred).numpy()
plot_x.append(i)
plot_y.append(mse)
plt.plot(plot_x, plot_y)
plt.xlabel("sequence len")
plt.ylabel("MSE")
plt.show()
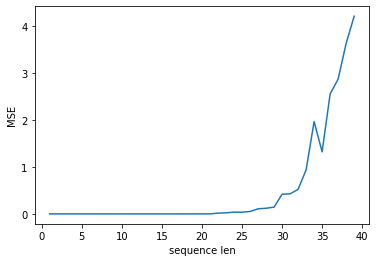
学習は長さ20のデータしか使っていませんが、20以下のデータでもちゃんと予測できていますね。
20以降は学習データがないので予測精度は悪くなっています。
3.隠れ状態を用いた途中経過の保存
隠れ状態を用いて途中経過の保存をしたいと思います。
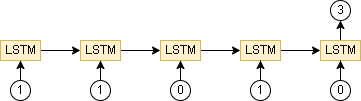
例えば [1, 1] というデータをいれた後に [0, 1, 0] をいれたら 3 と出力するモデルです。
(入力を2回に分ける)
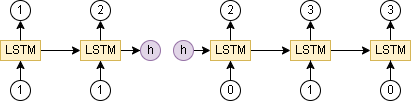
これを可能にするにはLSTMが内部で持っている隠れ状態を使う必要があります。
モデルは以下です。
多分カスタムモデルで作成するのが一番簡単だと思います。
class MyModel(keras.Model):
def __init__(self):
super().__init__()
self.in_layer = kl.TimeDistributed(kl.Dense(32))
self.lstm_layer = kl.LSTM(32, return_sequences=True, return_state=True) # ※5
self.out_layer = kl.TimeDistributed(kl.Dense(1))
# 学習では hidden_state は入力せず、時系列全体のデータをいれる
def call(self, x, training=False):
x, h = self.predict(x, None, training)
return x
# 予測は hidden_state を入力し、途中から始める
def predict(self, x, hidden_state, training=False):
x = self.in_layer(x, training=training)
x, h, c = self.lstm_layer(x, initial_state=hidden_state, training=training) # ※6 ※7
x = self.out_layer(x, training=training)
return x, [h, c]
# 初期隠れ状態を取得する用の関数
def get_initial_state(self):
return self.lstm_layer.cell.get_initial_state(batch_size=1, dtype=tf.float32)
model = MyModel()
# 学習
x_train, y_train = create_data_timesteps(1000, 20)
x_valid, y_valid = create_data_timesteps(100, 20)
model.compile(loss="mse", optimizer="adam")
history = model.fit(x_train, y_train, batch_size=32, epochs=100, validation_data=(x_valid, y_valid))
df_hist = pd.DataFrame(history.history)
df_hist[["loss", "val_loss"]].plot()
plt.show()
※5 return_state=True にすると隠れ状態が返るようになります
※6 return_state=Trueの場合は戻り値が2つ増え、後ろ2つが隠れ状態です。(短期記憶部と長期記憶部)
※7 引数でinitial_stateを与えると隠れ状態を指定する事ができます。
学習結果は2のモデルと同じなので省略します。
調査3.途中経過を保存して計算
[1,1,1] を入力させ、その後に [1,0,1] → 5 になるパターンと、[0,1,0,1,1] → 6 になるパターンを見てみました。
h0 = model.get_initial_state() # 初期隠れ状態
# --- [1,1,1] を入力
x_test1 = np.array([1, 1, 1], dtype="float32").reshape((1, -1, 1))
y_pred1, h_3 = model.predict(x_test1, h0)
print(y_pred1.numpy().flatten()) # [1.0058864 2.0119507 3.0231385]
# h_3 は内部的には3の情報を持っているはず
# --- h_3 + [1,0,1] を入力
x_test2 = np.array([1, 0, 1], dtype="float32").reshape((1, -1, 1))
y_pred2, _ = model.predict(x_test2, h_3)
print(y_pred2.numpy().flatten()) # [4.0048146 4.005358 5.0157046]
# --- [1,0,1] のみを入力
x_test3 = np.array([1, 0, 1], dtype="float32").reshape((1, -1, 1))
y_pred3, _ = model.predict(x_test3, h0) # h0の代わりにNoneでも同じ
print(y_pred3.numpy().flatten()) # [1.0058864 0.9834154 2.0015857]
# --- h_3 + [0,1,0,1,1] を入力
x_test4 = np.array([0,1,0,1,1], dtype="float32").reshape((1, -1, 1))
y_pred4, h_6 = model.predict(x_test4, h_3)
print(y_pred4.numpy().flatten()) # [3.0191178 4.0374146 4.0218706 5.0195336 5.9959307]
# h_6 は内部的には6の情報を持っているはず
# --- h_6 + [0,1,1,1] を入力
x_test5 = np.array([0,1,1,1], dtype="float32").reshape((1, -1, 1))
y_pred5, _ = model.predict(x_test5, h_6)
print(y_pred5.numpy().flatten()) # [5.9741497 6.9924216 7.9924083 8.983709 ]
ちゃんと計算できていますね。